참고
https://os2024.jeju.ai/week07/vm-freespace.html
이번 회차 목표
페이지 단편화를 알고 메모리 공간을 효율적으로 사용하는 방법
- 외부 단편화(External Fragmentation): 메모리에 할당되지 않은 작은 빈 공간들이 여러 곳에 산재해 있는 현상을 말합니다. 이러한 작은 빈 공간들은 새로운 메모리 할당 요청을 만족시키기에는 충분히 크지 않아서 메모리 낭비를 초래합니다.
- 내부 단편화(Internal Fragmentation): 할당된 메모리 블록 내부에서 발생하는 낭비를 말합니다. 할당된 블록의 크기가 요청된 크기보다 클 경우, 사용되지 않는 공간이 블록 내부에 존재하게 되는데 이를 내부 단편화라고 합니다.
버디 할당
빈 공간의 합병을 간단히 하는 방법을 버디 할당이라고 합니다.
이진 버디 할당기
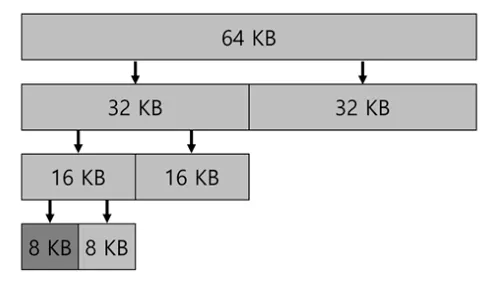
빈 메모리는 처음에 개념적으로 2ⁿ인 하나의 큰 공간으로 생각하면, 메모리 요청이 발생해 그 요청을 충족시키기에 충분한 공간이 발견될 때까지 분할하고, 더 분할하면 공간이 너무 작아져서 요청을 만족시킬 수 없을 때까지 빈 공간을 2개로 계속 분할합니다.
예시로 7KB 크기의 요청이 들어오면 가장 왼쪽의 8KB 블록이 될 때까지 분할하고, 사용자에게 반환됩니다.
블록 해제 시에는 해제한 블록 옆의 ‘buddy’블록을 확인합니다. 만약 비어있다면 두 블록을 병합하고, 이 재귀 합병 과정은 트리를 따라 전체 빈 공간이 복원되거나 버디가 사용 중이라는 것이 밝혀질 때까지 계속 올라갑니다.
• 버디(Buddy): 버디 할당에서 인접한 두 개의 블록을 버디라고 합니다. 버디는 항상 동일한 크기를 가지며, 주소가 인접해 있습니다. 버디 블록은 병합과 분할 과정에서 함께 처리됩니다.
슬랩 할당기
위의 문제는 특수 목적 할당기인 슬랩 할당기가 더 나은 방법으로 해결했습니다. 커널이 부팅될 때 커널 객체를 위한 여러 객체 캐시(object cache)를 할당합니다.
여기서 커널 객체란 락, 파일 시스템 아이노드 등 자주 요청되는 자료 구조들을 일컫습니다. 객체 캐시는 지정된 크기의 객체들로 구성된 빈 공간 리스트이고, 메모리 할당 및 해제 요청을 빠르게 하기 위해 사용됩니다.
기존에 할당된 캐시 공간이 부족하면 상위 메모리 할당기에게 추가 슬랩을 요청합니다. 슬랩 내 객체들에 대한 참조 횟수가 0이 되면 상위 메모리 할당기는 이 슬랩을 회수할 수 있습니다.
슬랩 할당 방식은 빈 객체들을 사전에 초기화된 상태로 유지한다는 점에서 개별 리스트 방식보다 우수합니다. 반납된 객체들을 초기화된 상태로 리스트에 유지하여 슬랩 할당기는 객체당 잦은 초기화와 반납의 작업을 피할 수 있어서 오버헤드를 현저히 감소시킵니다.
- 슬랩(Slab): 커널 객체를 저장하기 위해 할당된 연속적인 메모리 블록입니다. 슬랩은 동일한 크기의 객체들로 구성되며, 각 객체는 미리 초기화된 상태로 유지됩니다.
- 객체 캐시(Object Cache): 동일한 크기와 타입의 객체들을 관리하는 캐시입니다. 각 객체 캐시는 해당 객체의 할당과 해제 요청을 처리합니다. 객체 캐시는 여러 개의 슬랩으로 구성될 수 있습니다.
이거 뭔 말임?
개별 리스트(Segregated List)
특정 응용 프로그램이 자주 요청하는 크기의 객체를 관리하기 위해 별도의 리스트를 유지하는 것을 개별 리스트라고 합니다.
이 방법의 장점은 특정 크기의 요청을 위한 메모리 청크를 유지하기 때문에 단편화 가능성을 상당히 줄일 수 있다는 것입니다. 요청된 크기의 청크만이 존재하기 때문에 복잡한 리스트 검색이 필요하지 않으므로 할당과 해제 요청을 신속히 처리할 수 있습니다.
잘 모르겠다 ㅎㅎ…
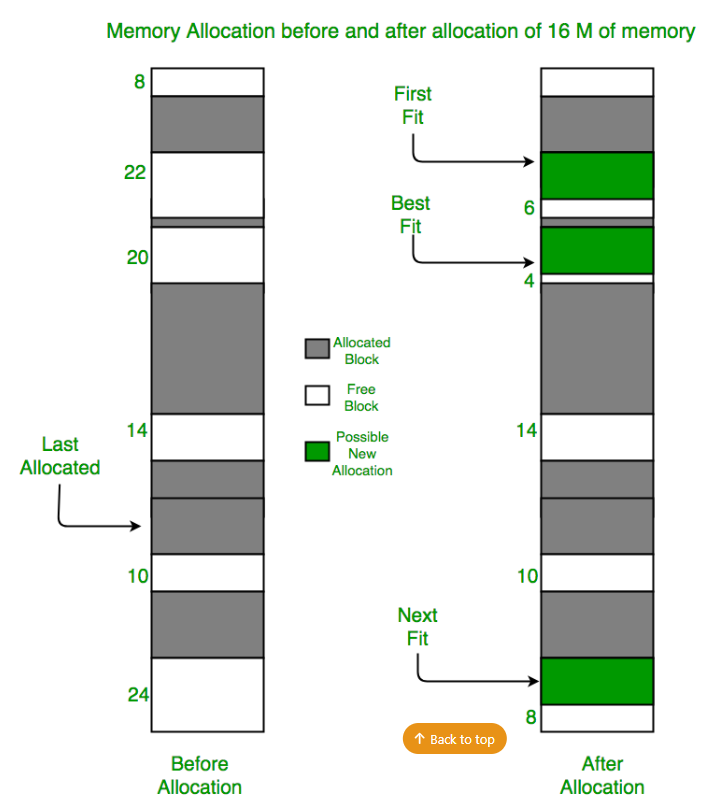
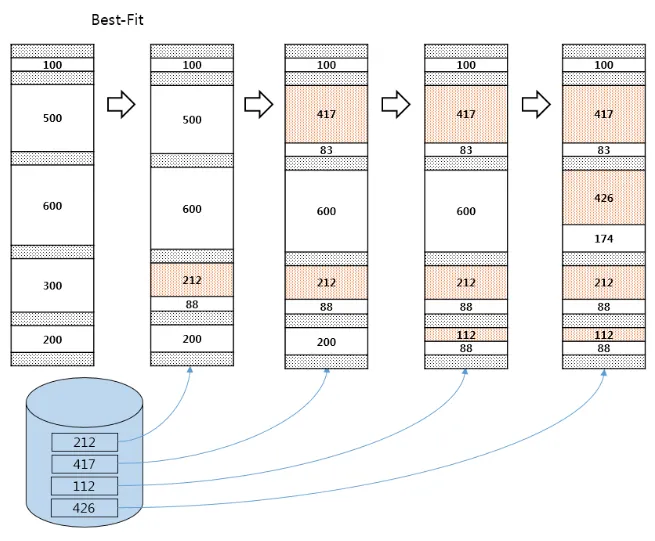
Best Fit(최적 적합)
가장 작은 남는 공간에 할당합니다.
이거 빈 공간 리스트를 만들어야 한다. 그리고 리스트를 조회해서 요청한 크기와 같거나 더 큰 빈 메모리 청크를 찾는다. 그 후, 후보자 그룹 중에서 가장 작은 크기의 청크를 반환합니다. Best fit은 빈 공간 리스트를 한 번만 순회하면 반환할 블록을 찾을 수 있지만 요청이 들어올 때마다 리스트를 순회해야 되는 비용이 발생한다.
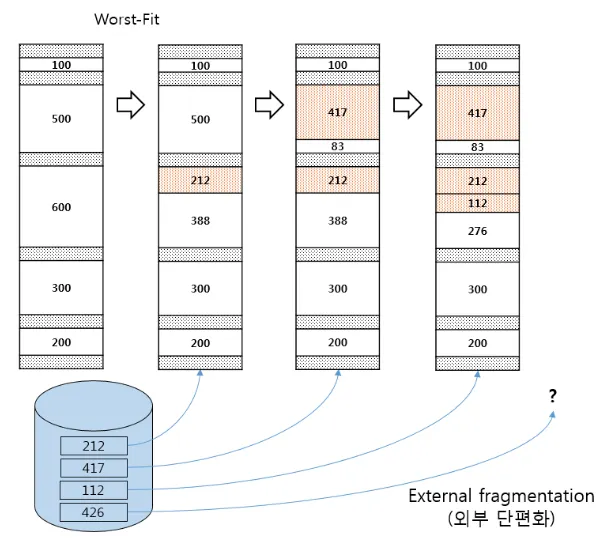
Worst Fit(최악 적합)
가장 큰 남는 공간에 할당합니다.
최적 적합의 반대 방식입니다. 가장 큰 빈 청크를 찾아 요청된 크기만큼만 반환하고 남는 부분은 빈 공간 리스트에 계속 유지됩니다. 최적 적합 방식에서 발생할 수 있는 수많은 작은 청크 대신에 커다란 빈 청크를 남기려고 시도합니다. 그러나 다시 한번 항상 빈 공간 전체를 탐색해야 하기 때문에 역시 높은 비용을 지불해야 합니다.
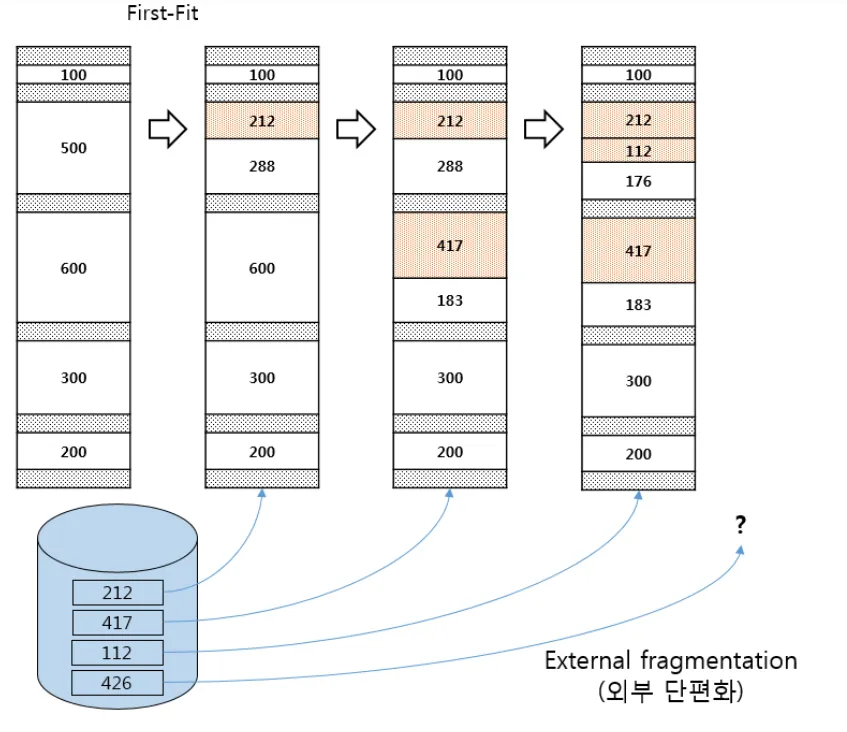
First Fit(최초 적합)
첫 번째로 충분히 큰 공간에 할당합니다.
간단하게 요청보다 큰 첫 번째 블록을 찾아서 요청만큼 반환합니다. 남은 빈 공간은 후속 요청을 위해 계속 유지됩니다. 속도가 빠르다는 것이 장점입니다. 원하는 블록을 찾기 위해 항상 빈 공간 리스트 전체를 탐색할 필요가 없습니다.
Next Fit(다음 적합)
마지막으로 할당된 공간의 다음부터 충분히 큰 공간을 찾아 할당합니다.
항상 리스트의 처음부터 탐색하는 대신 다음 적합 알고리즘은 마지막으로 찾았던 원소를 가리키는 추가의 포인터를 유지합니다. 아이디어는 빈 공간 탐색을 리스트 전체에 더 균등하게 분산시키는 것입니다. 리스트의 첫 부분에만 단편화가 집중적으로 발생하는 것을 방지합니다. 전체 탐색을 하지 않기 때문에 최초 적합의 성능과 비슷합니다.
이거 구현해봤는데 현재 할당 할당된 공간을 가리키는 포인터를 두고, 다음 할당할 공간을 찾을 때는 현재 위치부터 탐색을 시작했던 것 같다. 만약 탐색이 되지 않는다면 first fit처럼 처음부터 탐색을 했던 것 같은데 내 정확하지는 않다.