참고
https://os2024.jeju.ai/week10/dialogue.html
https://os2024.jeju.ai/week10/threads-intro.html#
https://os2024.jeju.ai/week10/threads-api.html
목적
쓰레드들이 메모리에 접근하는 것을 조정하지 않으면 프로그램이 예상처럼 동작하지 않을 수도 있고, 운영체제는 그 자체로 최초의 동시 프로그램이기 때문이다.
병행성이란?
여러 사람이 복숭아를 먹고 싶어 한다고 해보자꾸나.
다른 사람이 보고 있는 복숭아를 나도 같이 보고 있는 경우가 존재. 내가 집으려고 할 때 상대가 나보다 먼저 집게 되면 어떻게 되는가?
줄을 세운 후에 자기 차례가 되면 복숭아를 집어 먹도록 하는 방법을 사용하면?
문제는 뭔지 알고 있나? 줄을 직접 다 세워줘야 한다. 하지만 한 번에 한 명씩 복숭아를 집기 때문에 느리지만 정확하다.
여기서 복숭아 == 쓰레드 이다.
쓰레드들이 메모리를 접근하는 것을 조정하지 않으면 프로그램이 예상처럼 동작하지 않을 수도 있다.
이번 시간의 목표는 락(lock)과 컨디션 변수(conditional variables)와 같은 기본 동작으로 멀티쓰레드 프로그램을 지원하는 방법을 공부한다.
이유는 운영체제는 그 자체로 최초의 동시 프로그램이기 때문이야.
쓰레드 생성(예제)
#include <stdio.h>
#include <assert.h>
#include <pthread.h>
void *mythread(void *arg) {
printf("%s\n", (char *) arg);
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
int rc;
printf("main: begin\n");
rc = pthread_create(&p1, NULL, mythread, "A");
assert(rc == 0);
rc = pthread_create(&p2, NULL, mythread, "B");
assert(rc == 0);
// 쓰레드가 종료될 때까지 대기하기 위해 join 사용
rc = pthread_join(p1, NULL); assert(rc == 0);
rc = pthread_join(p2, NULL); assert(rc == 0);
printf("main: end\n");
return 0;
}위에서 쓰레드 A가 먼저 생성될 수도 있고, B가 먼저 생성될 수도 있다.
main: begin
A
B
main: endmain: begin
B
A
main: end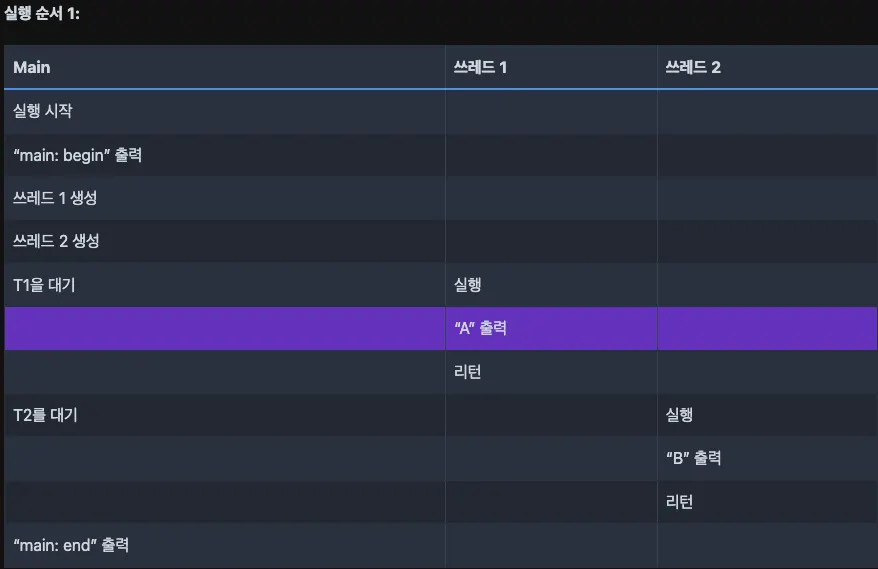
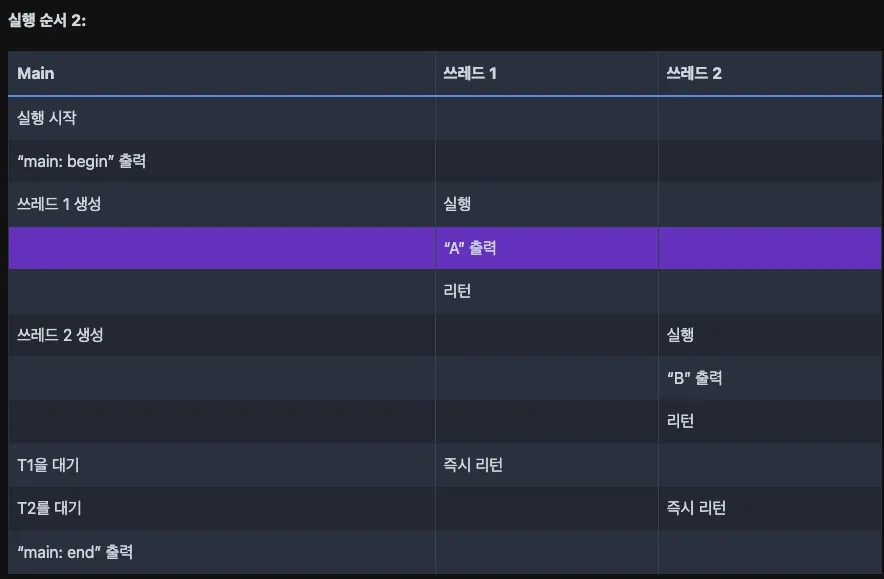
위의 실행 순서는 쓰레드 실행의 다양한 가능성 중 일부일 뿐, 유일한 실행 순서는 아닙니다. 스케줄러가 특정 시점에 어떤 쓰레드를 실행하느냐에 따라 다양한 순서가 나올 수 있습니다.
쓰레드 1이 쓰레드 2보다 먼저 생성되었더라도 스케줄러가 쓰레드 2를 먼저 실행한다면 “B”가 “A”보다 먼저 출력될 수 있다.
쓰레드의 동작을 예측하는 방법은 없을까?
쓰레드의 생성은 함수 호출과 유사해 보이지만, 함수 호출에서는 함수가 실행을 마치면 호출자(caller)에게 리턴하는 반면, 쓰레드 생성에서는 새로운 쓰레드가 생성되어 호출자와는 독립적으로 실행됩니다.
따라서 쓰레드는 생성 함수가 리턴되기 전에 실행될 수 있다.
쓰레드는 프로그램의 실행 흐름을 복잡하게 만든다. 어떤 쓰레드가 언제 실행될지 정확히 예측이 불가능하기 때문이다.
데이터 공유
전역 공유 변수를 갱신하는 두 개의 쓰레드를 사용한 간단한 예제
#include <stdio.h>
#include <pthread.h>
#include "mythreads.h"
static volatile int counter = 0;
// mythread()
// 인자로 전달된 문자열을 출력하고
// 10000000번 반복하며 counter에 1을 더하는 함수
// 끝나면 다시 인자 문자열을 출력
void *mythread(void *arg) {
printf("%s: begin\n", (char *) arg);
for (int i = 0; i < 1e7; i++) {
counter = counter + 1;
}
printf("%s: done\n", (char *) arg);
return NULL;
}
// main()
// 두 개의 쓰레드를 생성하고 (pthread_create)
// 기다린다 (pthread_join)
int main(int argc, char *argv[]) {
pthread_t p1, p2;
printf("main: begin (counter = %d)\n", counter);
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
// 쓰레드가 종료될 때까지 기다리기 위해 join 사용
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("main: done with both (counter = %d)\n", counter);
return 0;
}쓰레드 간의 상호작용, 특히 공유 데이터에 대한 접근을 다뤘음.
따라서 최종 결과는 20,000,000이 되어야 한다. 각 작업자 쓰레드는 공유 변수 counter에 1,000만 번(1e7) 1을 더했음.
main: begin (counter = 0)
A: begin
B: begin
A: done
B: done
main: done with both (counter = 20000000)main: begin (counter = 0)
A: begin
B: begin
A: done
B: done
main: done with both (counter = 19345221)main: begin (counter = 0)
A: begin
B: begin
A: done
B: done
main: done with both (counter = 19221041)여기서 잠깐….왜 결과값이 바뀌는거지?
일단 mythread 함수를 살펴보면 20000000이 당연히 나와야할 것처럼 보인다…
힌트가 될만한 말이 없을까?
쓰레드 간의 상호작용, 특히 공유 데이터에 대한 접근
공유 데이터… 어디서 많이 들어본 말이다…
만약 스레드 A와 B가 동시에 공유 데이터에 접근해서 1을 더한다면?
즉, A가 접근해서 counter를 증가시키기 전에 B가 접근하게 되면 A의 연산과정이 무시되면서 잘못된 결과가 나온 것 같다.
스케줄링
목적 : 왜 결과값이 ‘20000000’이 아니라 다른 값이 나올 수 가 있는가?
핵심은 counter 갱신을 위해 컴파일러가 생성한 코드의 실행 순서이다.
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c이 예제에서 counter 변수의 주소는 0x8049a1c라고 가정합니다.
- x86의
mov명령어가 지정된 메모리 주소의 값을 읽어eax레지스터에 저장합니다. eax레지스터의 값에 1(0x1)을 더합니다.eax에 저장된 값을 메모리의 원래 주소에 다시 저장합니다.
타이머 인터럽트가 발생하여 운영체제가 실행 중인 쓰레드의 PC 값과 eax를 포함한 레지스터들의 현재 상태를 쓰레드의 TCB(Thread Control Block)에 저장합니다.
쓰레드 2가 선택되고 counter 값을 증가시키는 동일한 코드 영역에 진입합니다. 첫 번째 명령어를 실행하여 counter 값을 읽어 eax에 저장합니다.
각 쓰레드는 개별적인 쓰레드 전용 레지스터를 가지고 있습니다. 사용 중이던 레지스터들을 저장하고 복구하는 문맥 교환 코드에 의해 이 레지스터들은 가상화됩니다.
counter 값은 아직 50이므로 쓰레드 2의 eax 값은 50입니다. 쓰레드 2가 다음 두 문장을 실행하면 eax 값을 1 증가시켜 eax는 51이 되고, eax 값을 counter(주소 0x8049a1c)에 저장합니다. 전역 변수 counter는 이제 51이 됩니다.
문맥 교환이 발생하면 쓰레드 1이 다시 실행됩니다. 이전 상황을 떠올려 보면 쓰레드 1은 mov와 add 동작을 실행했고 이제 마지막 mov 명령어를 수행하려는 중입니다. 그리고 eax는 51입니다.
따라서 mov 명령어가 실행되면 레지스터의 값을 메모리에 저장하여 counter의 값은 다시 51이 됩니다. 따라서 counter의 값을 증가시키는 코드가 두 번 수행 → 50에서 시작한 counter의 값은 1만 증가하여 51이 되는 문제가 발생됨.
예제 코드
운영체제가 쓰레드를 생성하고 제어하는 데 어떤 인터페이스를 제공해야 할까? 어떻게 이 인터페이스를 설계해야 쉽고 유용하게 사용할 수 있을까?
쓰레드 생성
#include <pthread.h>
int pthread_create(
pthread_t * thread,
const pthread_attr_t * attr,
void * (*start_routine)(void*),
void * arg
);#include <pthread.h>
typedef struct __myarg_t {
int a;
int b;
} myarg_t;
void *mythread(void *arg) {
myarg_t *m = (myarg_t *) arg;
printf(“%d %d\n ”, m−>a, m−>b);
return NULL;
}
int
main(int argc, char *argv[]) {
pthread_t p;
int rc;
myarg_t args;
args.a = 10;
args.b = 20;
rc = pthread_create(&p, NULL, mythread, &args);
...
}쓰레드를 생성하고 나면, 실행 중인 모든 쓰레드와 같은 주소 공간에서 실행되는 또 하나의 실행 개체를 보유하게 된다.
쓰레드 종료
int pthread_join(pthread_t thread, void **value_ptr);thread: 기다릴 쓰레드의 ID입니다. 이 값은pthread_create()호출 시 초기화됩니다.value_ptr: 쓰레드의 반환값을 받을 포인터의 포인터입니다. 쓰레드 함수가void *를 반환하므로, 이를 받기 위해 이중 포인터가 사용됩니다.
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
typedef struct {
int a;
int b;
} myarg_t;
typedef struct {
int x;
int y;
} myret_t;
void *mythread(void *arg) {
myarg_t *m = (myarg_t *) arg;
printf("%d %d\n", m->a, m->b);
myret_t *r = malloc(sizeof(myret_t));
r->x = 1;
r->y = 2;
return (void *) r;
}
int main() {
pthread_t p;
myarg_t args = { 10, 20 };
myret_t *retval;
pthread_create(&p, NULL, mythread, &args);
pthread_join(p, (void **) &retval);
printf("returned %d %d\n", retval->x, retval->y);
free(retval);
return 0;
}이 예제에서는 myarg_t를 통해 쓰레드 함수에 인자를 전달하고, myret_t를 통해 반환값을 받습니다. main 함수에서는 pthread_join()을 호출하여 쓰레드가 종료될 때까지 기다립니다. 쓰레드가 종료되면 반환값을 retval을 통해 받고, 이를 출력합니다.
락
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);이 함수들은 사용하기 쉽습니다. 공유 자원에 접근하기 전에 pthread_mutex_lock()을 호출하여 락을 획득하고, 접근이 끝나면 pthread_mutex_unlock()을 호출하여 락을 해제합니다.
pthread_mutex_t lock;
pthread_mutex_lock(&lock);
// 공유 자원 접근
x = x + 1;
pthread_mutex_unlock(&lock);pthread_mutex_lock()이 호출되었을 때, 다른 쓰레드가 이미 락을 획득한 상태라면 해당 쓰레드는 락이 해제될 때까지 대기합니다. 락을 획득한 쓰레드만이 pthread_mutex_unlock()을 호출할 수 있습니다.
질문 3가지
- 데이터 공유 파트에서 총 결과값이 20000000이 나와야 하는데 그렇지 않은 결과값이 존재했다. 원인은 무엇이였고, 어떻게 해결할 수 있을까?
- 예제에서 스레드 생성 순서와 결과 출력 순서가 달랐다. 이유가 무엇이였는가?
- 스레드의 문맥 교환과 프로세스의 문맥 교환에는 차이점이 있다. 어떤 차이가 있는가?
