
공부하게 된 계기
사이드 프로젝트로 클라이언트 + WAS(AWS EC2) - DB(AWS RDS)의 2-tier 아키텍처를 주로 가져가면서, WAS - DB간 통신은 대부분 JPA와 Querydsl을 활용했다. 복잡한 통계 쿼리나 N+1 문제를 방지하기 위한 쿼리는 Querydsl로 작성하고, 간단한 쿼리들은 모두 JPA Repository를 활용해서 처리했었다.
개발을 배워가는 단계에서 JPA는 매우 유용하다. RDBMS 별 특성이나 SQL을 잘 몰라도 JPA를 통해 자바, 객체 중심으로 DB와의 통신을 처리할 수 있었기 때문이다. DB에서 읽어온 데이터를 조합해서 객체를 생성하는 등의 번거로움 없이 목표하는 제품을 빠르게 개발할 수 있었다.
사이드 프로젝트에서 JPA가 성능 이슈를 일으킨 적은 한번도 없다. 애초에 사용하는 사람이 없기 때문에 문제상황에 대한 인지 자체가 불가능하기 때문이다. 테이블 크기 또한 매우 작아서, API 요청으로 발생하는 한 번의 트랜잭션에 4~5개의 SQL이 실행되거나, 객체 테이블의 컬럼을 몽땅 긁어와도 간단한 API들은 응답 시간이 100ms 미만인 경우가 대부분이였다.
하지만 실무 환경을 감히 예상해보면, 이런 방식으로 JPA를 활용했을 때 문제가 생길 여지는 충분하다고 생각했기 때문에 JPA Projection에 대해 관심을 갖게 되었다.
나는 그동안 알게 모르게 클래스 기반 프로젝션(DTO)을 사용하고 있었다. 하지만 이를 제대로 알고 사용한 것이 아니기 때문에 제대로 살펴볼 필요가 있다. 서론이 길었는데, 이번 포스팅에서는 JPA Projection에 대해 이해하고, 내 사이드 프로젝트에 이를 적용하는 리팩토링을 진행해보고자 한다.
JPA Projection
프로젝션이란, DB에서 필요한 값만 조회하는 것을 말한다. Spring Data JPA에서는 Projection을 어떻게 진행하는지 알아보자.
공식문서에서 Spring Data JPA가 프로젝션을 지원한다는 내용이다.
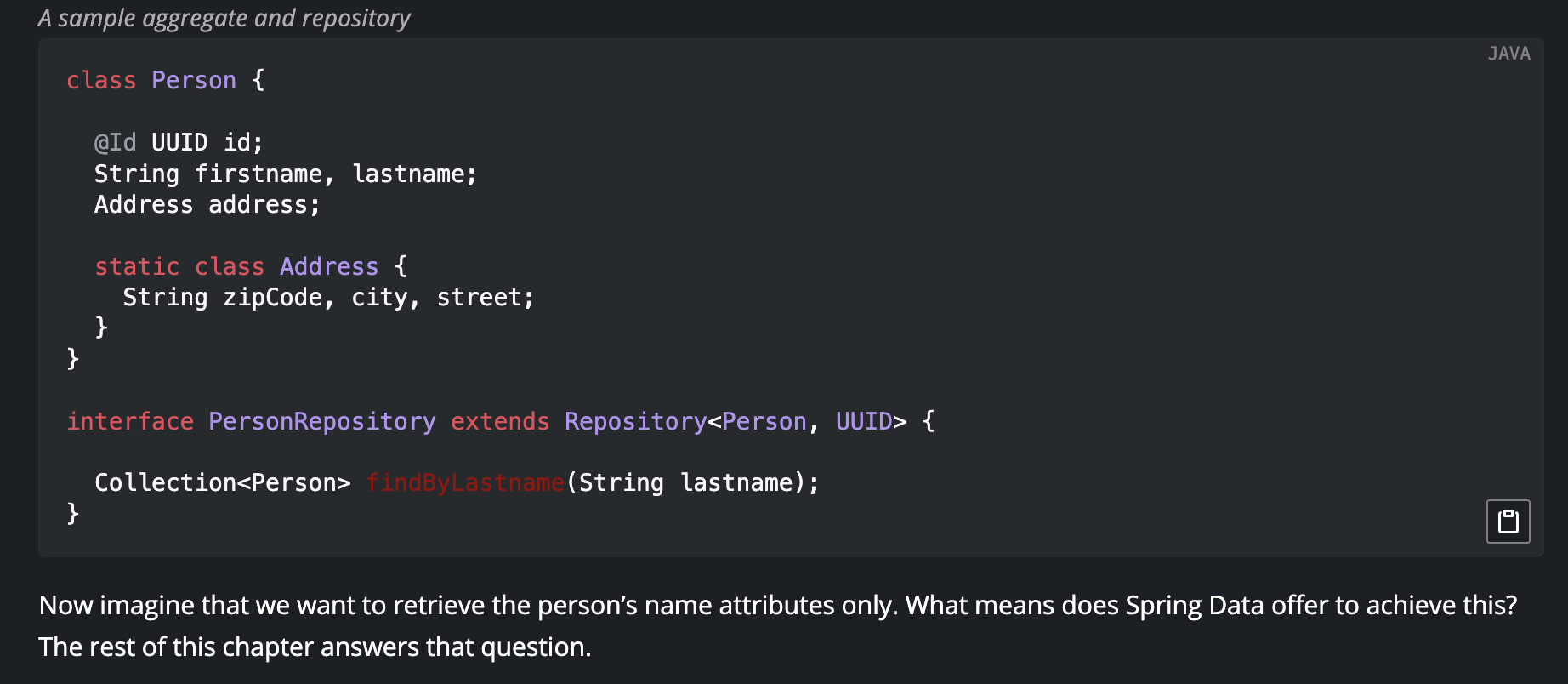
아래 Person 의 firstname, lastname 필드만 필요할 경우에 PersonRepository의 findByLastName 메서드를 호출하면 필요 없는 필드까지 조회하게 된다. 이를 해결하기 위해 몇 가지 Projection 방법들을 알아보겠다.
인터페이스 기반 프로젝션
Closed Projections
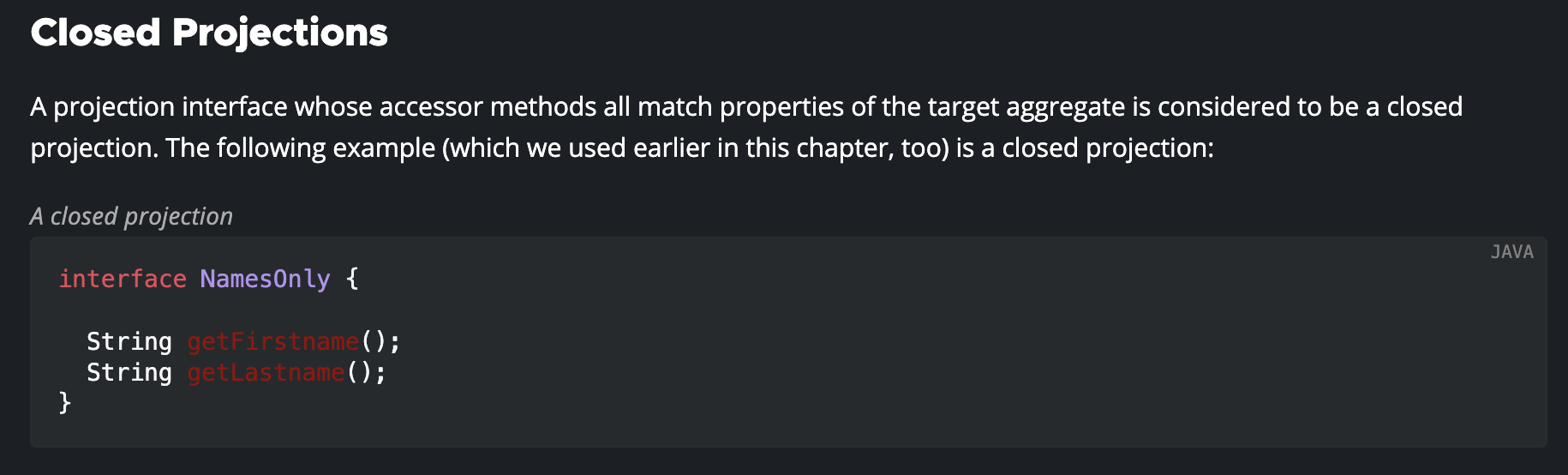
Closed Projection은 객체의 특정 필드만을 선택하여 인터페이스로 정의하는 방식이다. 위 예시처럼 필요한 필드에 대한 get 키워드와 함께 정확한 필드명을 메서드로 선언하여 인터페이스로 정의한다.
또한, 인터페이스를 위한 프록시 인스턴스를 생성하는 데 필요한 모든 자원이 무엇인지 Spring Data에서 이미 알고 있기 때문에, Spring Data가 쿼리 실행을 최적화할 수 있다고 한다. 즉, 필요한 속성만을 조회하기 위한 쿼리를 더 효율적으로 생성할 수 있는 것이다.
이제 Closed Projection을 활용해서 리팩토링을 진행해보자.
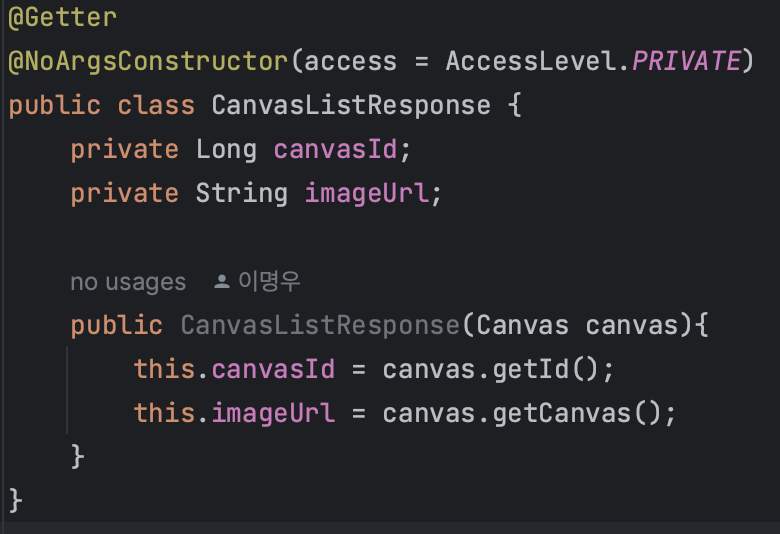
Canvas라는 객체에서 Id와 canvas라는 속성값이 필요할 경우 Closed Projection을 활용하게 되면, 다음과 같이 코드를 작성한다.
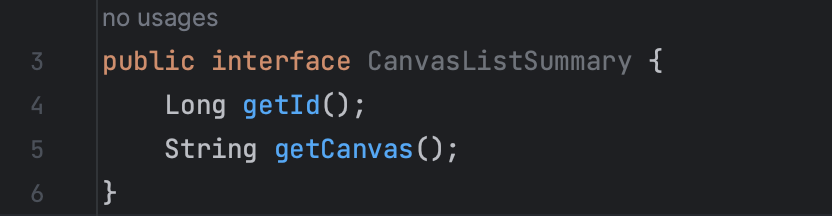
먼저, 필요한 필드에 대한 get 메서드가 담긴 인터페이스를 하나 만든다. 그 다음, JPA Repository를 상속받은 인터페이스에서 아래와 같이 코드를 작성해준다.

프로젝션 인터페이스를 반환 타입으로 지정해준다.
여러 개의 결과가 반환되는 쿼리의 경우, Collection의 구현체를 메서드 반환 타입으로 지정해주면 된다.
이제 해당 메서드를 테스트해볼 차례다. 하이버네이트의 SQL 로깅 옵션을 활성화하고, 테스트 코드를 작성해서 로그를 확인해보겠다.
로그 활성화 yml
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=true테스트 코드
테스트 결과
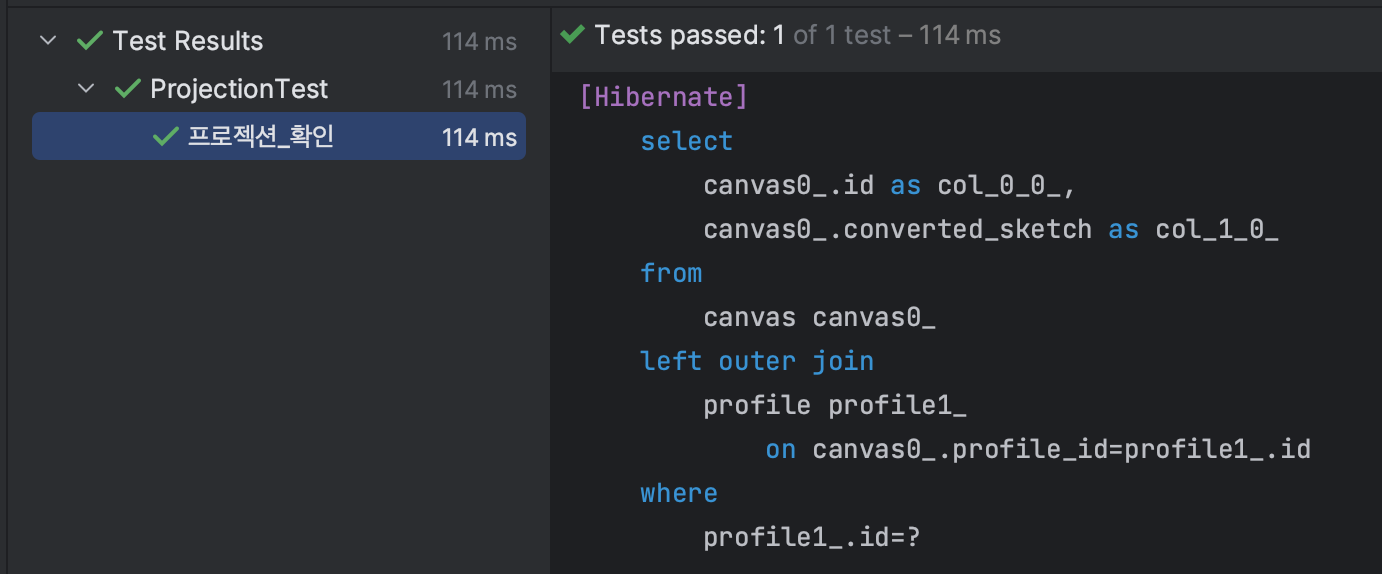
테스트는 통과했고, canvas테이블의 Id, converted_sketch(canvas) 컬럼만 조회하고 있는 것을 확인했다.
양방향 관계 -> 단방향 관계 수정을 통한 쿼리 수정
그런데 Canvas 테이블의 profile_id(FK)로 테이블 액세스를 시도하는 것이 아니라, profile 테이블이 드라이빙 테이블이 되어 canvas 테이블과 join하여 테이블에 접근하고 있다. 굳이 profile 테이블을 스캔한 다음, Join할 필요가 없기 때문에 곧바로 canvas 테이블의 profile_id 컬럼을 통해 canvas 테이블을 탐색하는 것이 바람직해 보인다.
이를 해결하기 위해서 @Query 어노테이션을 사용할 수도 있지만, 이는 밑에서 설명할 클래스 기반 프로젝션에서 활용할 것이기 때문에, 최대한 인터페이스 기반 프로젝션을 활용해서 해결을 시도해보았다.

그래서 Profile 필드 타입을 Long으로 바꾸고 참조 관계를 양방향에서 단방향으로 바꿔주었다.(Profile <-> Canvas 에서 Profile -> Canvas)
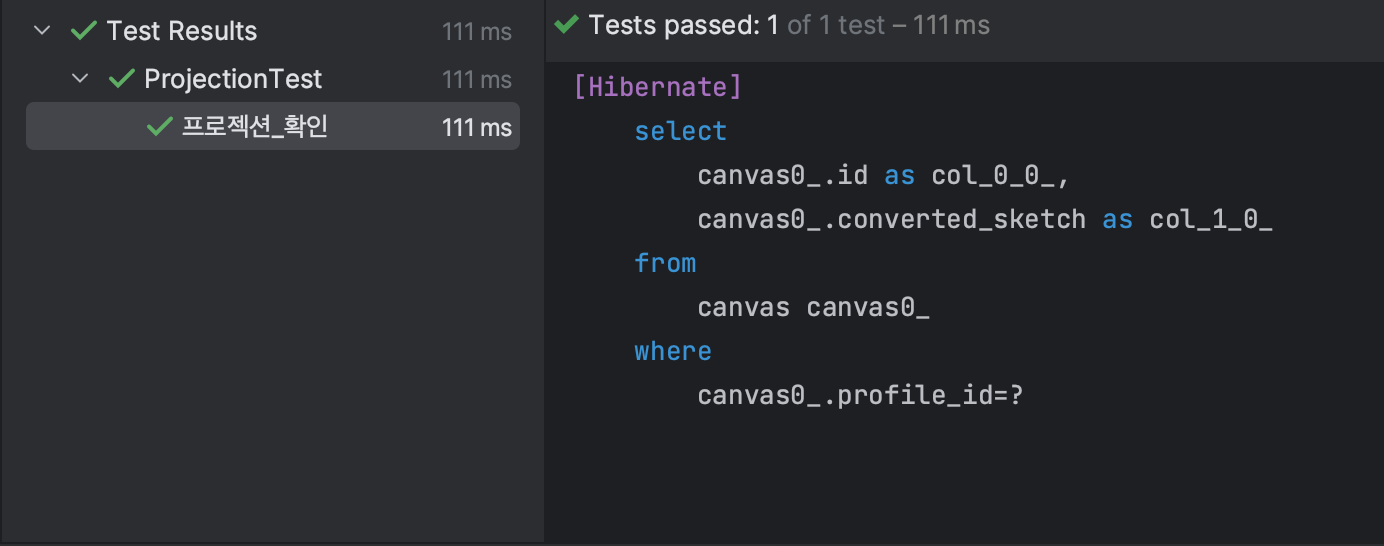
테스트 결과, 의도한대로 SQL이 실행되는 것을 확인할 수 있었다. 부모 객체(Profile)에서만 Canvas 객체를 참조하도록 했을 때, Canvas객체의 profile_id는 Long 타입이기 때문에 더 이상 join이 발생하지 않았다.
Canvas의 Profile 참조를 삭제했을 때, 컴파일 오류가 발생하는 코드가 몇 개 있었는데, 모두 canvas.getProfile().getId()로 profile_id를 참조하던 것들이었다.
이를 모두 canvas.getProfileId()로 바꾸는 리팩토링을 진행하면서 한 가지 깨달은게 있다. 이번 포스팅의 주제와는 거리가 있지만 엔티티 객체, 특히 참조 관계가 있는 객체 설계 시에는 양방향, 단뱡항 참조 관계를 요구사항에 맞게 설계할 수 있어야 된다.
기존 코드처럼 단순히 테이블 내 FK만 사용함에도 불구하고 연관관계 매핑된 객체를 참조해서 추가적인 쿼리가 실행되거나, 자식 객체가 부모 객체를 참조하게되는 객체지향적인 면에서도 책임 분배가 잘 이루어지지 않았던 부분을 확인할 수 있었다. 또한, 객체 내의 get 메소드를 통해 다른 객체를 얻고 거기서 또 다시 get 메소드를 호출하는 방식 자체도 객체지향과 어긋나는 부분이다.
JPA + 엔티티 객체 설계시에는 양방향인지, 단방향인지 고려하는 단계가 필요해보인다.
Open Projections
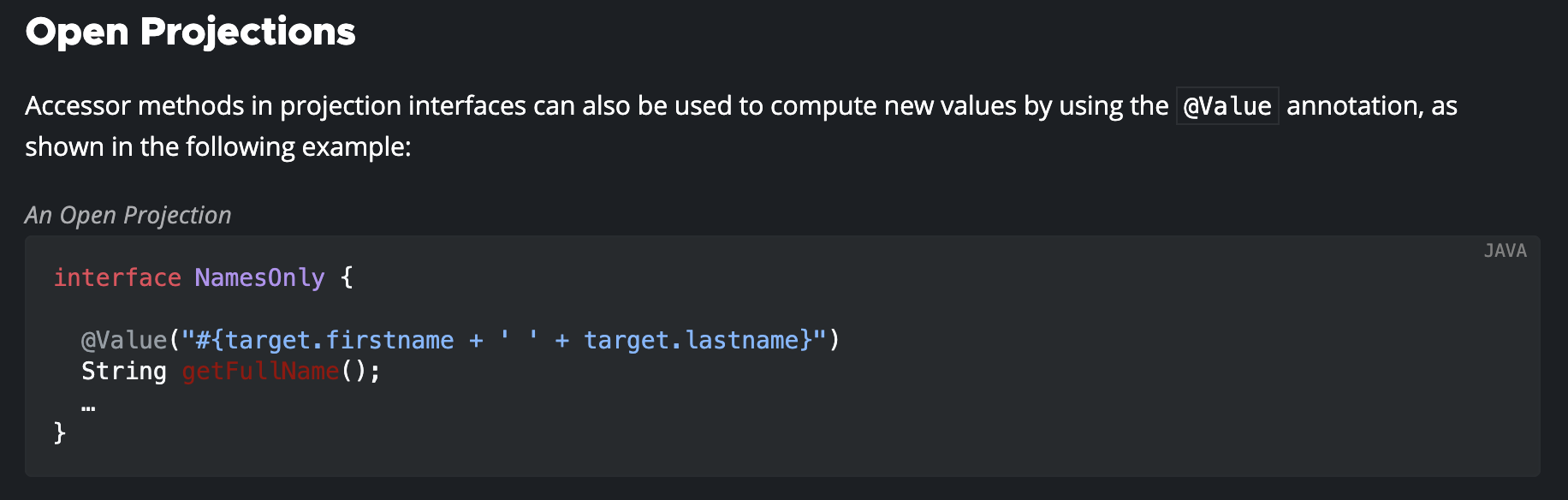
Open Projection은 @Value 어노테이션을 활용하여 새로운 값을 계산할 때 활용할 수 있다.
주로 String 인스턴스에 대한 수정 연산이 꺼려질 때(String은 value 필드가 final 키워드로 선언되어있으며, + 연산을 통해 수정을 가할 경우 새로운 String 인스턴스가 생성된다)와 같은 경우에 활용하면 좋다고 한다.
Open Projections는 사이드 프로젝트 코드에 적용해볼만한 부분이 없는 관계로 예시 코드를 통해서 이해하고 넘어가겠다.
예시
public interface UserSummary {
String getUsername();
@Value("#{target.username + ' ' + target.email}")
String getUsernameAndEmail();
}
public interface UserRepository extends JpaRepository<User, Long> {
List<UserSummary> findByUsername(String username);
}
class User{
Long id;
String phoneNumber;
String username;
String email;
}
User과 같은 객체가 있을 때, @Value 어노테이션으로 username + email 형태의 새로운 값을 UserSummary 인터페이스의 getUsernameAndEmail 메서드를 통해서 제공한다.
@Value 어노테이션은 SpEL(Spring Expression Language)를 사용하여 필드를 조합한다.
클래스 기반 프로젝션(Class-based Projections)
마지막 클래스 기반 프로젝션을 알아보자. 클래스 기반 프로젝션은 DTO를 활용한 프로젝션으로 이해하면 된다.
일반 클래스를 활용할 경우
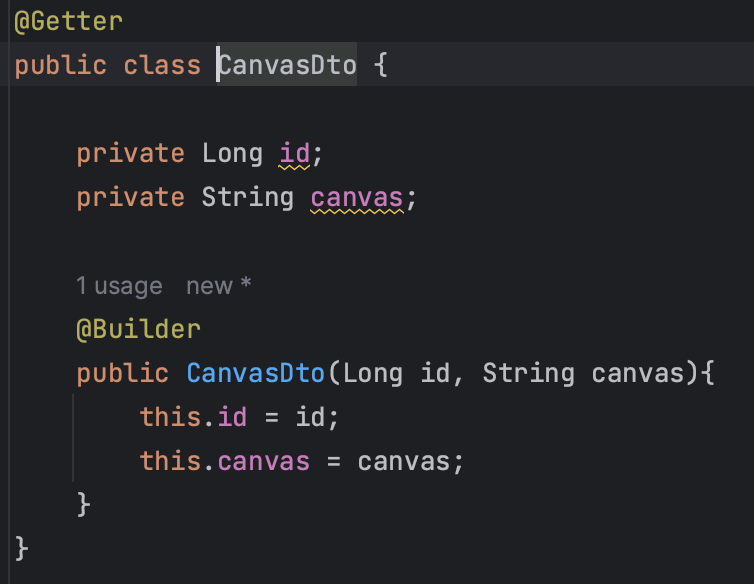
먼저 프로젝션 인터페이스 역할을 할 DTO 클래스를 작성해준다.
@Getter
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public class CanvasDto {
private Long canvasId;
private String canvasUrl;
@Builder
public CanvasDto(Long canvasId, String canvasUrl){
this.canvasId = canvasId;
this.canvasUrl = canvasUrl;
}
}
이제 리포지터리 인터페이스로 가서 @Query 어노테이션과 JPQL을 활용해 메서드를 정의한다. JPQL에서 생성자 표현식으로 프로젝션 인터페이스가 되는 DTO 클래스를 지정해준 다음, 문법에 맞게 쿼리를 작성하면 된다.
public interface CanvasRepository extends JpaRepository<Canvas, Long> {
@Query("SELECT new com.siliconvalley.domain.canvas.dto.CanvasDto(c.id, c.canvas) FROM Canvas c WHERE c.profileId = ?1")
List<CanvasDto> findCanvasByProfileId(Long profileId);
테스트 코드
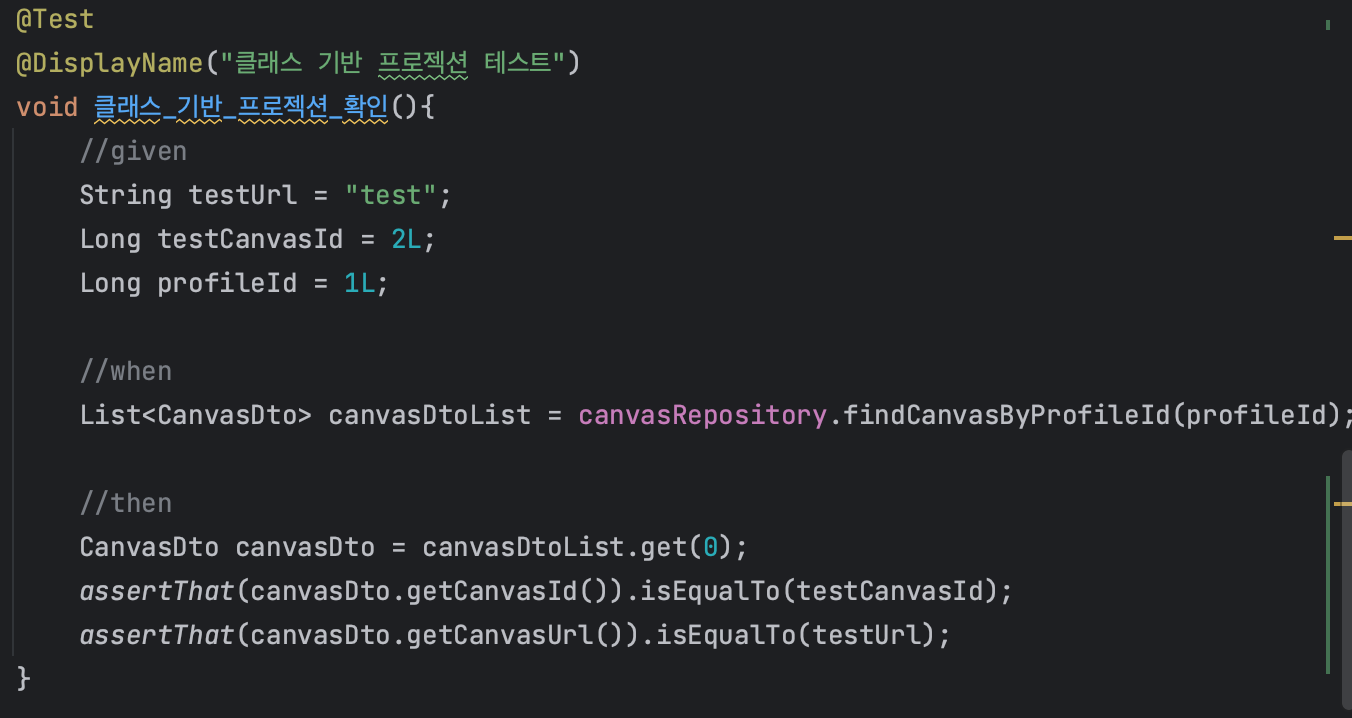
하이버네이트 로그
테스트 코드를 실행해서 로그를 살펴보면 의도한대로 쿼리를 날리고 있는 것을 확인할 수 있다.
Record를 활용할 경우(Java 17 이상)
Java 17부터 추가된 record를 DTO로 활용할 경우에도, Projection 이 가능하다. 예시를 통해 알아보자.
Region이라는 엔티티 객체의 테이블에서 regionName과 regionCode라는 값만 필요할 때 다음과 같이 Record 클래스를 만들어준다.
@Getter
@Entity
@Table(name = "REGION")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Region {
@Id
@Column(name = "REGION_CD")
private String regionCode;
@Column(name = "REGION_NM", nullable = false)
private String regionName;
@OneToMany(mappedBy = "region", orphanRemoval = true, cascade = CascadeType.PERSIST, fetch = FetchType.LAZY)
private List<Pnu> pnuData = new ArrayList<>();
@OneToMany(mappedBy = "region", orphanRemoval = true, cascade = CascadeType.PERSIST, fetch = FetchType.LAZY)
private List<User> users = new ArrayList<>();
@ManyToOne
@JoinColumn(name = "observatory_cd", nullable = false)
private Observatory observatory;
@Builder
public Region(Observatory observatory, String regionCode, String regionName){
this.observatory = observatory;
this.regionName = regionName;
this.regionCode = regionCode;
}
public void addPnu(String pnuCode, String pnuAdress){
this.pnuData.add(buildPnu(pnuCode, pnuAdress));
}
private Pnu buildPnu(String pnuCode, String pnuAddress){
return Pnu.builder()
.pnuAddress(pnuAddress)
.region(this)
.pnuCode(pnuCode)
.build();
}
}public record RegionRecord(String regionName, String regionCode) {}일반 DTO 클래스와 마찬가지로 JPQL에서 생성자 표현식을 통해 record 클래스를 지정해주고, 쿼리문을 작성해준다.

테스트 및 로그 확인
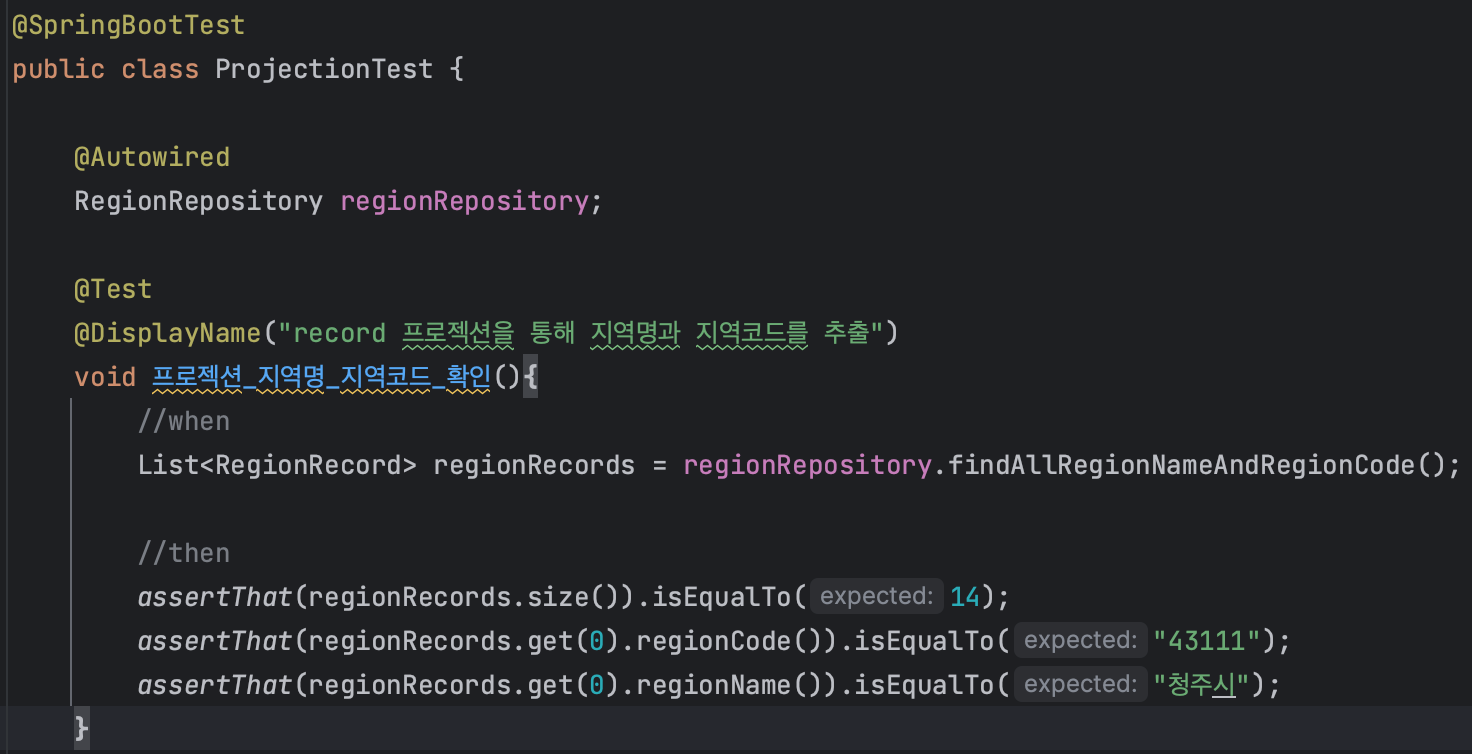
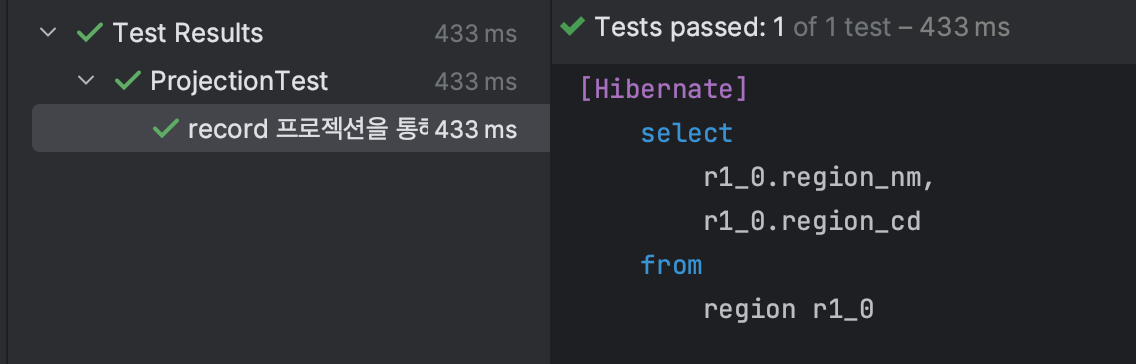
의도한대로 regionName과 regionCode만 SELECT 해오는 것을 확인할 수 있다. 이러한 방식으로 JPA + java 17이상의 환경이라면 record 기반 Projection 또한 고려해볼 수 있을 것 같다.
동적 프로젝션(Dynamic Projections)
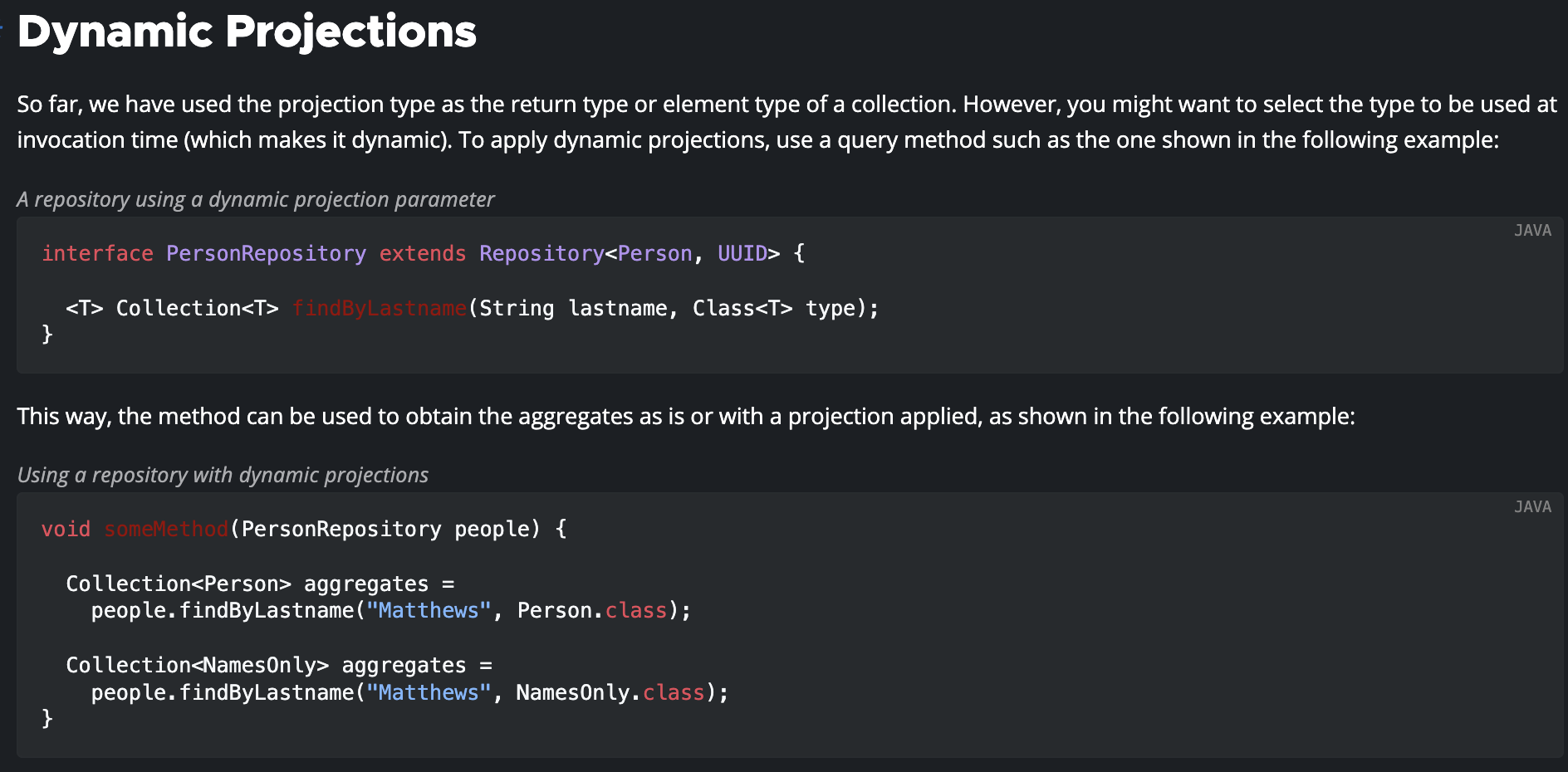
마지막으로 살펴볼 프로젝션은 동적 프로젝션이다.
동적 프로젝션은 쿼리 결과를 다양한 타입으로 반환할 수 있게 해주는 프로젝션이다. 공식문서의 예시 사진처럼 제너릭 타입인 <T>를 반환 타입으로 지정하고, 메서드 파라미터에 반환 타입을 전달하여 호출시에 구체적인 반환 타입을 정할 수 있다.
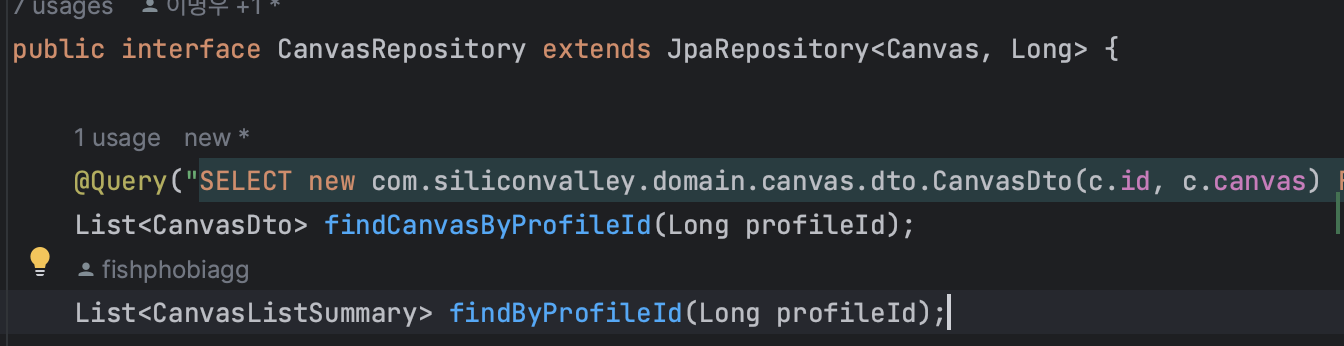
동적 프로젝션을 활용해서 위 예시에서 사용한 두 메서드를 유연하게 사용할 수 있도록 바꿔보겠다.
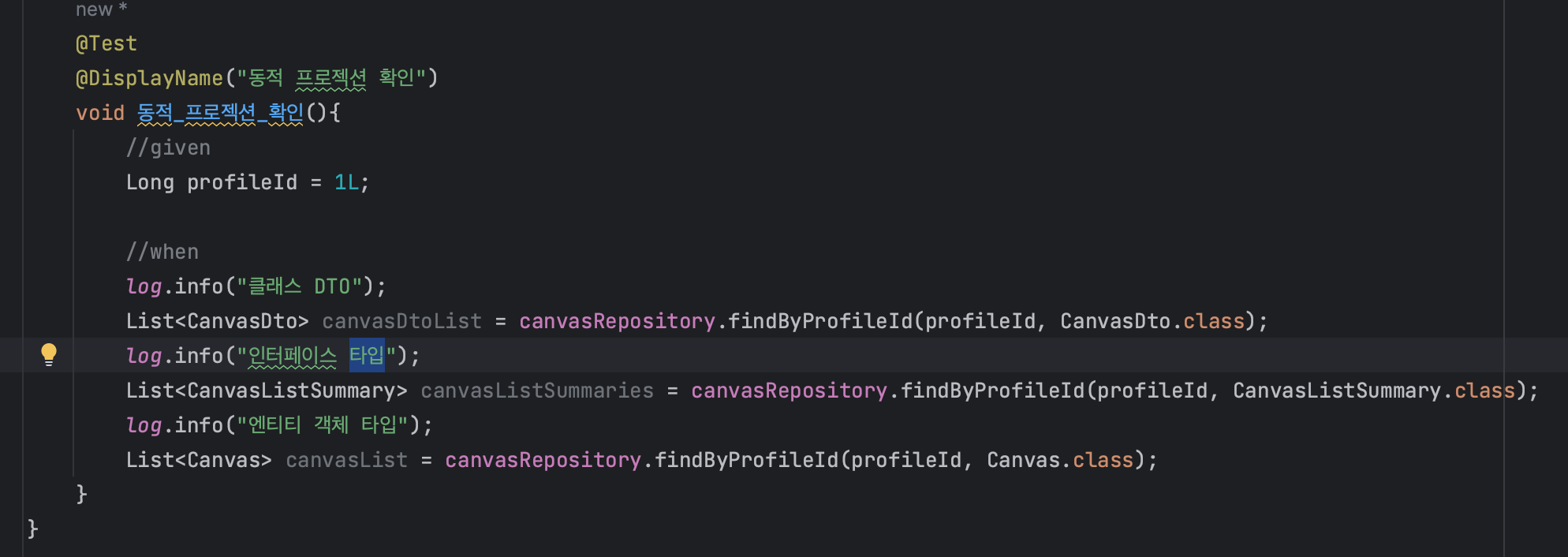
두 메서드에 엔티티 객체까지 각각 반환 타입으로 지정해서 테스트를 실행하면?

여기서 한가지 문제가 발생한다. 위 예시에서 활용햇던 CanvasDto의 경우, 클래스 기반 프로젝션에서는 JPQL 생성자 표현식을 통해서 객체 필드에 값을 올바르게 넣어줄 수 있었지만, 동적 프로젝션에서 해당 필드를 그대로 사용하게 될 경우 이런 에러를 마주하게 된다.
동적 프로젝션을 활용할 경우에는 엔티티 객체와 SELECT 해올 필드 명을 통일 시켜야하는 것을 잊으면 안된다. 인터페이스 프로젝션에서 활용했던 CanvasListSummary는 필드명과 get 메소드명을 통일시켜주었기 때문에 문제가 발생하지 않았다.
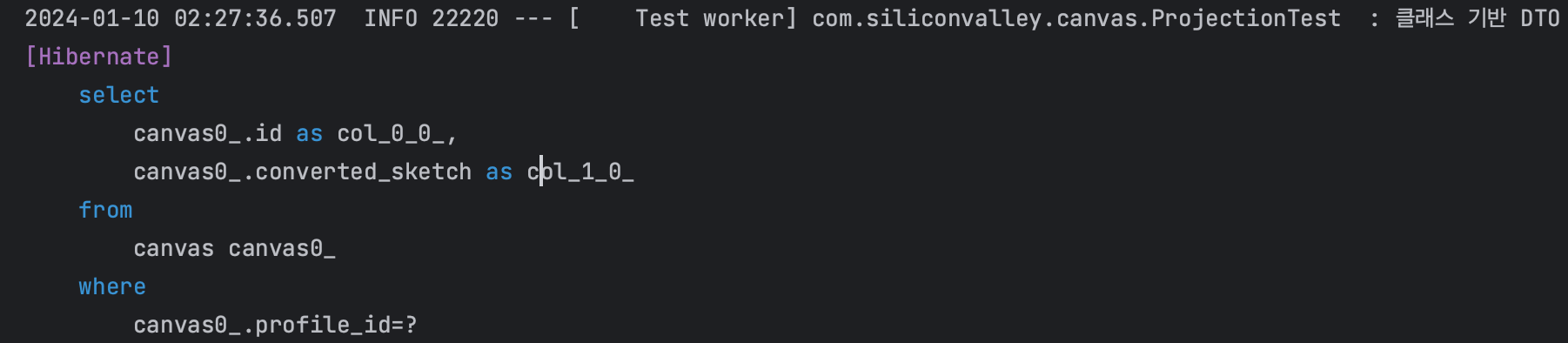
CanvasDto를 다음과 같이 수정하고 테스트를 실행해보면
테스트 결과

CanvasDto를 반환 타입으로 지정했을 때 동적 프로젝션 하이버네이트 쿼리 로그(클래스 DTO)
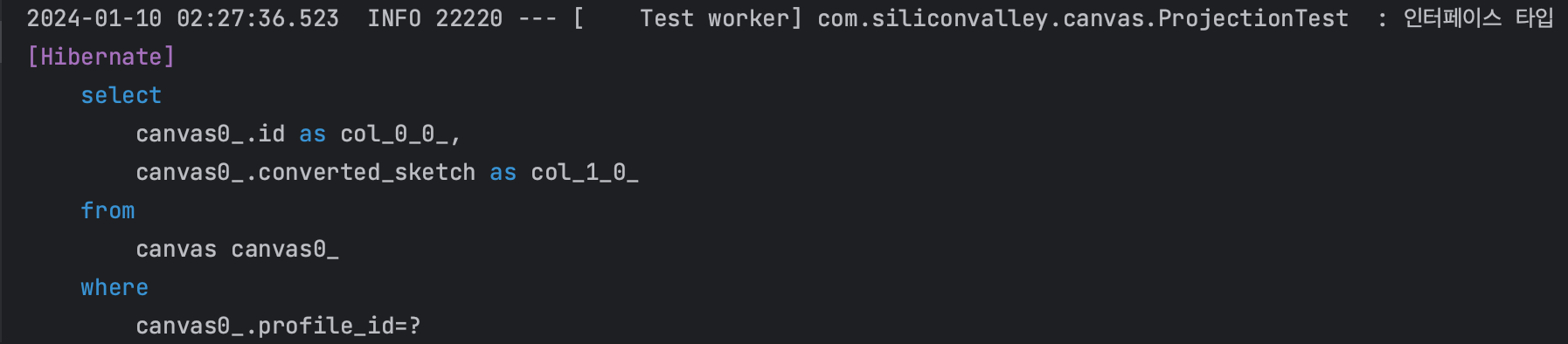
CanvasListSummary를 반환 타입으로 지정했을 때 동적 프로젝션 하이버네이트 쿼리 로그(인터페이스 DTO)
Canvas를 반환 타입으로 지정했을 때 동적 프로젝션 하이버네이트 쿼리 로그(엔티티 객체)
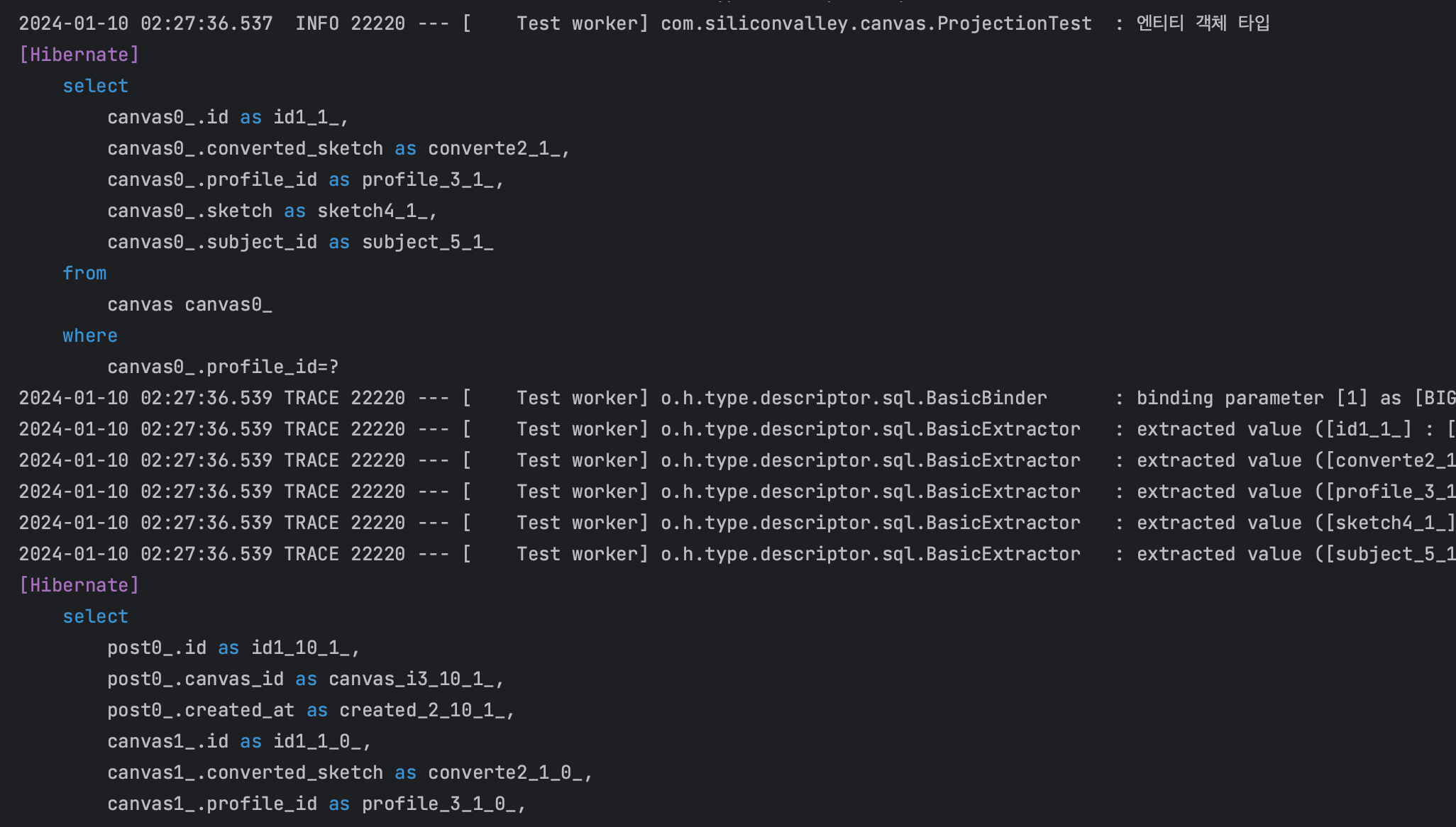
각각의 반환 타입에 맞게 동적 프로젝션이 되는 것을 확인할 수 있다!
record 클래스의 경우에도 마찬가지로, 엔티티 객체의 필드명과 동일하게 필드명을 통일해주면 된다.
마무리
이번 포스팅에서는 JPA Projection에 대해서 알아봤다. 사실 Querydsl을 사용해도 같은 문제를 해결할 수 있다. 여러 테이블이 JOIN하게 되는 복잡한 쿼리라면 정신 건강을 위해서 Querydsl을 활용하는게 좋아보이지만, 비교적 간단한 쿼리일 경우 JPA Projection을 통해서 필요한 컬럼을 조회할 수 있도록 하는 게 좋을 것 같다. 다음 포스팅에서는 Projection 간 성능 비교를 해보겠다.
참고
