🧷Linked list
Linked list와 Array list
Array list는 모든 원소가 한 곳에 모여있다는 특징이 있다. 반면에 Linked list는 아래 그림처럼 원소(node, vertex)가 한 곳에 있지 않고 흩어져있다.
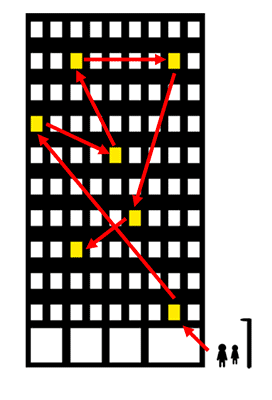
위 그림(출처 : 생활코딩)은 linked list의 데이터 구조를 표현해주는 그림이다. 한 회사에서 같이 일하는 사람이 건물 어떤 사무실이든 상관없이 들어가있는 모습을 통해 링크드 리스트를 쉽게 이해할 수 있을 것이다.
연결
linked list는 array와 다르게 위치가 흩어져있기 때문에 "연결"되어있어야 한다.
용어
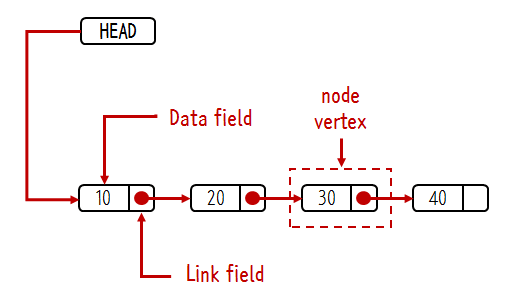
[사진 출처 : 생활코딩 유튜브]
- node : 마디, 교점
- vertex : 교점, 꼭짓점
위 표현들은 연결성이 강조된 표현이라고 생각하면 이해하기 쉽다. array에서는 엘리먼트, linked list에서는 위 단어들을 사용한다.
구조
리스트는 노드들의 모임 -> 내부적으로 노드를 가지고 있어야 한다.
Data field와 Link field
- 노드는 최소한 두 가지 정보가 필요하다.
-
노드의 값과
-
다음 노드이다.
이 두 가지 데이터는 각각 노드의 Data field와 Link field에 저장이 되어있다. 이게 linked list에서 노드의 최소한의 구성이라고 할 수 있다.
HEAD
앞에 연결된 노드가 없기 때문에 가장 첫번째 노드에 대한 정보는 따로 저장할 필요가 있는데, HEAD field에 이를 저장한다. 위에서 사용한 건물 비유를 다시 사용하자면, HEAD는 건물의 출입구가 되는 셈이다.
데이터의 추가
시작 부분에 추가
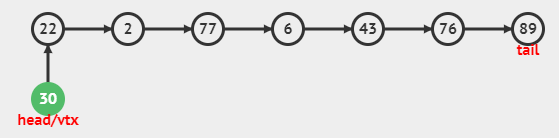
과정
-
새로운 노드 생성
-
새로운 노드의 다음 노드로 첫번째 노드를 지정
-
새로 만들어진 노드가 첫번째 노드가 되도록 head의 값 변경

중간에 추가
4번째 노드와 5번째 노드 사이에 데이터(53)를 추가해보자.
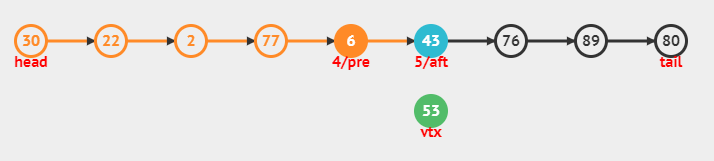
과정
-
head를 참조해서 첫번째 노드 조회
-
5번째 노드의 자리에 53이 들어가야 하기 때문에, 5번째 노드(43)까지 계속해서 조회
-
4번째 노드와 5번째 노드를 각각 pre, aft에 지정해준다.
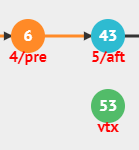
- 4번째 노드의 다음 노드에 새 노드 지정, 새 노드의 다음 노드에 aft 노드 지정

array list와 차이점
array list의 경우, 중간에 있는 데이터를 삭제하거나 추가할 경우 해당 원소 뒤에 있는 모든 원소들의 자리 이동이 필요했다(속도가 느린 원인). 하지만 linked list는 참조값을 통해 전, 후 노드를 조정할 수 있기 때문에 중간 노드의 추가/삭제 소요시간이 array list에 비해 월등히 빠르다.
데이터의 제거
리스트에서 세번째 노드를 제거해보자.
과정
-
HEAD를 통해 첫번째 노드 조회
-
두번째 노드와 세번째 노드, 세번째 노드를 찾는다.
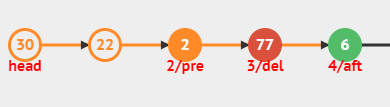
-
두번째 노드의 다음 참조값을 네번째 노드로 바꿔주고 90을 세번째 노드를 메모리에서 제거한다.
데이터 조회
array list의 경우에는 인덱스로 즉각적인 접근이 가능하지만, linked list의 경우에는 HEAD 노드부터 시작해서 순차적으로 원하는 노드까지 찾아가야한다. 최악의 경우 리스트를 끝까지 모두 순회해야될 수도 있다.
이로 인해 array list와 linked list간에는 trade off가 발생하게 된다. 자료구조를 공부하는 이유가 여기에 있으며, 이를 정확히 이해하고 자료구조를 적용할 수 있어야 할 것이다.
