JAVA의 장단점
장점
- JVM 위에서 동작하기에 운영체제에 독립적
- 가비지 컬렉터가 메모리를 관리해 편함
단점
- JVM 위에서 동작하기에 실행 속도가 상대적으로 느림
- 다중 상속 등 제약이 존재
원시 타입과 참조 타입
원시 타입
- 실제 값이 스택 영역에 저장
참조 타입
- 기본 타입을 제외한 모든 타입
- 스택에 참조 값이 저장
- 힙 영역에 실제 객체가 저장
- 미사용시 GC의 대상
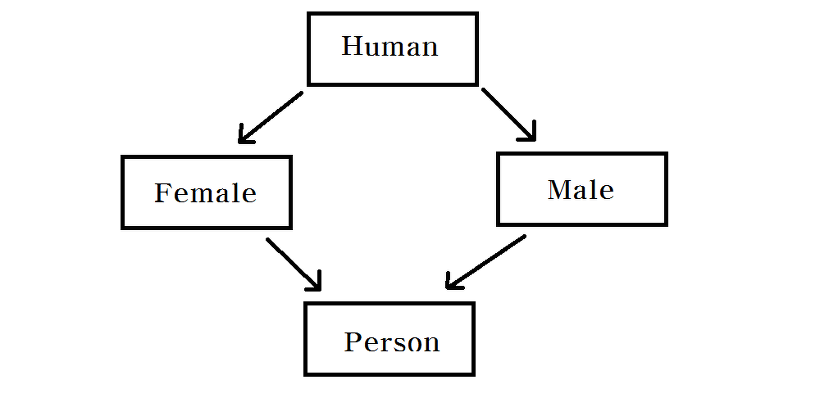
다중 상속과 다이아몬드 문제
- 다중 상속 지원시 다이아몬드 문제가 발생
Ex) Human 클래스에 있는 walk() 메서드를 Female, Male 두 클래스가 모두 구현 후, Person 클래스가 Female, Male을 다중 상속시 walk() 메서드에 대한 코드 충돌 발생
오버라이딩과 오버로딩
- 오버라이딩 : 상위 클래스 메서드를 하위 클래스가 재정의해 사용하는 기술
- 오버로딩 : 메서드의 파라미터의 타입, 개수를 변경해 같은 이름의 메서드를 여러 개 작성하는 기술
클래스, 객체, 인스턴스
- 클래스 : 객체를 만들기 위한 설계도
- 객체 : 클래스를 기반으로 선언된 대상, 클래스의 인스턴스라고도 부름
- 인스턴스 : 객체에 메모리가 할당되어 실제 활용되는 실체(객체)
싱글톤 패턴
- 하나의 인스턴스만을 생성해 사용하는 디자인 패턴
- 동일한 인스턴스를 자주 생성하는 경우 사용(메모리 낭비 방지)
단점
- 객체 지향 설계 원칙에 적합하지 않음
- 생명주기 제어가 힘들며, 멀티스레드 환경에서 여러 개의 객체가 생성되는 문제 발생
- static 또는 synchronized 사용으로 동기화 작업 필요
추상클래스와 인터페이스 차이
추상클래스
- 단일 상속만 가능
- 모든 접근 제어자 사용
- 변수, 상수 선언 가능
- 추상 메서드와 일반 메서드 선언 가능
인터페이스
- 다중 구현 가능
- public 접근 제어자만 사용
- 상수 선언 가능
- 추상 메서드만 선언 가능
컬렉션 프레임워크
List
- 순차적인 데이터 저장
- 데이터 중복과 Null을 허용
Set
- 순서없이 Key로만 데이터 저장
- Key의 중복과 Null을 허용하지 않음
Map
- 순서없이 Key-Value로 데이터 저장
- Value의 중복은 허용하나 Key는 허용하지 않음
- Key의 Null을 허용하지 않음
Vector와 ArrayList
Vector
- 속도가 느리나 병렬 상황에 안전
- 크기 증가시 2배 증가
ArrayList
- 속도는 빠르나 병렬 상황에 안전하지 않음
- 크기 증가시 1.5배 증가
StringBuffer와 StringBuilder
StringBuffer
- 속도는 느리나 병렬 상황에 안전
StringBuilder
- 속도는 빠르나 병렬 상황에 안전하지 않음
synchronized?
- 여러 스레드가 하나의 자원에 접근시 스레드가 해당 자원을 사용중인 경우 데이터 접근을 막는 키워드
- 메소드에 사용 시 한 시점에 하나의 스레드만이 메소드 실행
- 변수에 사용 시 한 시점에 하나의 스레드만이 변수 참조 가능
String과 불변성
- String은 불변성을 가지고 있음
- 보안
- 스레드 안전성
- 내부의 String pool을 이용해 캐싱과 효율성 챙김
- 해시 맵 키로 사용 가능
- String pool(Constant pool)은 힙영역에 저장되기에 GC의 대상이 됨
자바의 동시성 처리
- Java8에서 Null-safae한 작업을 위한 Optional API 추가
- Date와 Time을 함께 처리하기 위한 LocalDateTime API 추가
Stream API 장단점
장점
- 간결한 코드 작성으로 가독성을 높임
- 병렬스트림과 같은 기술을 이용해 처리 속도를 높임
단점
- 잘못된 사용으로 성능이 저하될 수 있음
- 코드들이 추상화되어 있어 실수 발생
람다
- 불필요한 코드를 줄이고, 가독성을 높이기 위한 익명함수
- 함수의 이름과 반환타입 없이 함수 선언 가능
Java 동작 과정
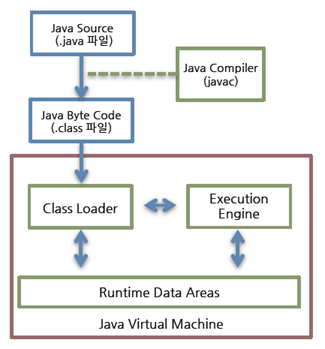
1. Java 소스 파일을 javac로 컴파일해 바이트코드로 생성
2. 클래스로더가 컴파일된 바이트 코드를 런타임 데이터 영역에 로드
3. 실행 엔진이 자바 바이트 코드를 실행
JVM 구조
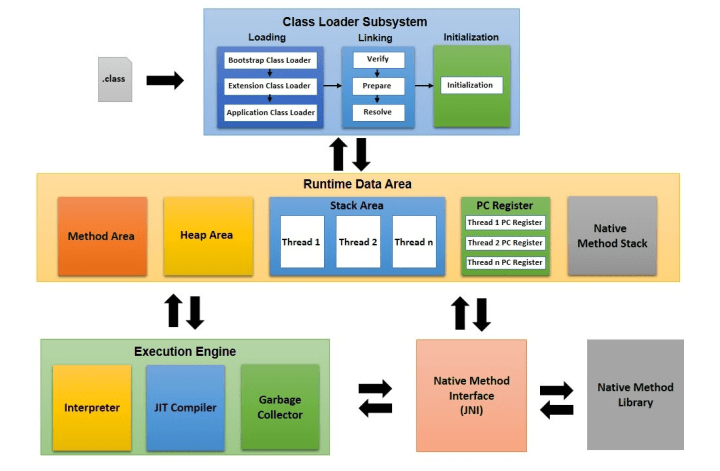
- 메소드 영역 : 클래스 변수의 이름, 타입, 접근 제어자, static 변수, 인터페이스 등이 저장
- 힙 영역 : new를 통해 생성된 객체와 배열의 인스턴스 저장, GC의 대상
- 스택 영역 : 메소드가 실행되면 메소드에 대한 영역을 생성해 지역변수, 매개변수, 리턴값 저장
- Native Method Stack : 자바 외의 언어로 작성된 코드를 위한 메모리 영역, JNI를 통해 사용
JIT
- 실행엔진은 인터프리터, JIT, GC로 구성되며, 프로그램의 실행 방식은 컴파일, 인터프리트 2가지가 존재
- 인터프리트는 실행시마다 기계어 변환 작업을 진행해 코드에 대한 빠른 피드백이 가능하나 실행 속도가 느림.
- 컴파일 방식은 실행전 기계어로 변환 작업을 진행해 한번의 변환 작업만 이뤄져 빠름.
- JIT 컴파일러는 컴파일 + 인터프리트 혼합 방식으로 JVM 안에서는 바이트 코드가 인터프리트 방식으로 실행되는데 이때 반복되는 코드를 네이티브 언어로 컴파일해 캐싱하여 필요시 재사용
OOM
- 힙 메모리에 새로운 객체를 할당할 수 없을 때 발생
가비지 컬렉터란?
- JVM 실행 엔진의 한 요소
- 힙 영역에서 참조되지 않는 객체를 정리
가비지 컬렉터 과정
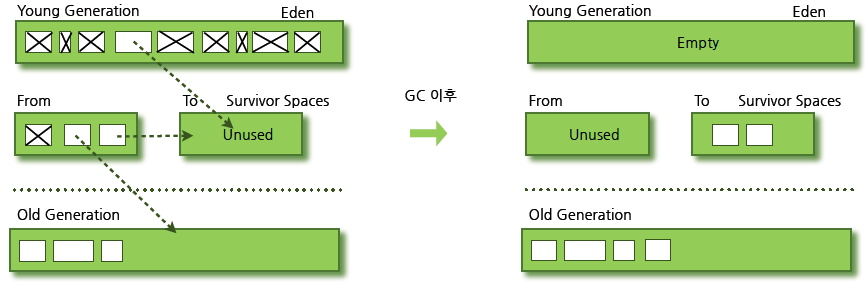
- GC 실행시 GC를 진행하는 스레드 이외의 모든 스레드가 작업을 멈추는 STOP-THE-WORLD
- major(Old 영역) GC와 minor(Young 영역) GC로 나뉨
과정
- 새로운 객체가 Eden 영역에 생성
- Eden 영역에서 GC 동작 후 살아남은 객체가 Survivor0으로 이동
- 2번의 동작이 반복되 Survivor0이 꽉 참
- Survivor0에 GC 가 동작하고, 살아남은 객체는 Survivor1로 이동하면서, Survivor0이 비워 짐
- 위 동작이 반복되 특정 횟수만큼 생존한 객체를 Old 영역으로 이동
- Old 영역이 가득 차 Survivor영역 에서 Old 영역으로 이동 불가시 Old 영역에서 GC 동작
GC 처리 방식
Refrence-Counting
- 객체에 접근 가능한 방법을 카운팅 방식
- 순환 참조로 인한 메모리 부족 발생 가능
Mark-And-Sweep
- 객체 접근 가능 여부를 기준으로 함
- 순환 참조는 해결 했으나 애플리케이션 실행과 GC를 병행해야 함
동작 과정
1. Mark : 그래프 순회를 통해 연결된 객체를 마킹
2. Sweep : 마킹 되지 않은 객체를 힙에서 지움
3. Compact(선택적) : Sweep 이후 분산된 객체를 힙의 시작 주소로 모아 메모리가 할당된 곳과 비어있는 곳을 구분
가비지 컬렉션 알고리즘
- Serial GC : 싱글 스레드로 오버헤드 시간이 가장 길며, Mark-And-Sweep 방식을 사용합니다. 메이저 GC는 Compation이 진행
- Parallel GC : Serial GC와 알고리즘은 같지만 Minor GC를 멀티 스레드로 수행해 serial GC 보다는 오버헤드 시간을 단축, Major GC는 싱글 스레드로 수행.
- Parallel Old GC : 모든 GC가 멀티 스레드 동작, 새로운 GC 방식인 Mark-Summary(sweep와 단일스레드냐 멀티스레드냐 차이)-Compact 방식 도입한 알고리즘
- Concurrent Mark & Sweep GC(CMS) : 애플리케이션 스레드와 GC 스레드를 동시 실행해 오버헤드 시간을 단축, GC 과정이 복잡(메모리 파편화, 높은 CPU 사용량)해져 14 버전 부터는 사용 중지.
- G1 GC : 동적으로 heap 영역을 구분하는 region 개념 도입, Heap 메모리 전체 탐색이 아닌 Region 별로 탐색, 메모리가 많이 채워진 영역별로 GC가 실행, 생존 객체를 효율적인 영역이라 판단한 곳에 재할당.
출처
https://mangkyu.tistory.com/94
감사합니다!!

정신차려 이 각박한 세상속에서!!!