자료구조와 알고리즘
자료구조
- 데이터를 규칙 또는 목적에 맞게 저장하기 위한 구조
알고리즘
- 자료구조의 데이터를 활용해 문제를 해결하는 방법
시간복잡도와 공간복잡도
- 시간 복잡도 : 입력값에 따른 알고리즘 수행시간
- 공간 복잡도 : 알고리즘 수행에 필요한 메모리 양
빅오 표기법
- 시간복잡도를 표기한 것으로 알고리즘 효율성의 표기법

스택, 큐, 트리, 힙 구조
- 스택 : 프링글스통 같은 구조로 선입후출(First-in Last-out, FILO) 구조
- 큐 : 휴지심 같은 구조로 선입선출(First-in First-out, FIFO) 구조
- 트리 : 정점과 간선을 이용한 비선형구조, 계층 데이터 표현에 적합
- 힙 : 이진트리의 일종으로 주로 우선순위 큐 구현에 사용되며, 최대 힙과 최소 힙으로 구분
우선순위 큐와 내부 구조 및 시간복잡도
- 우선순위가 가장 높은 데이터를 먼저 꺼내기 위한 자료구조
- 주로 힙 구조로 구현, 시간복잡도는 로그 시간(O(logn))
해시 테이블과 시간 복잡도
- 데이터를 (Key, Value) 형식으로 저장하는 자료구조
- 해시 테이블은 Key값에 해시함수를 적용, 고유 index를 생성해 저장된 값을 꺼내는 구조
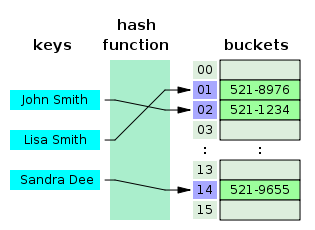
- 고유 index로 값을 조회하여 O(1)의 시간복잡도
- index 충돌시 충돌된 index의 데이터까지 조회해 O(n)까지 증가할 수 있음
- 해결책은 링크드 리스트를 활용한 체이닝과 오픈 주소 법이 존재
LinkedList와 ArrayList 차이
ArrayList
- 순서가 있는 배열 형식으로 데이터가 저장된 형식
- index로 원하는 데이터에 접근 가능
- 리스트의 크기가 제한되어 크기 조정에 연산이 필요
- 데이터 추가/삭제시 임시 배열을 생성하고 복제하는데 시간이 걸림
LinkedList
- 자료의 주소값으로 서로 연결된 형식을 가짐
- 리스트의 크기에 영향 없이 데이터 추가 가능
- 데이터 추가시 새로운 노드를 생성해 연결하기에 추가/삭제 연산이 빠름
- index를 통한 접근이 불가해, 순차적 접근만이 가능
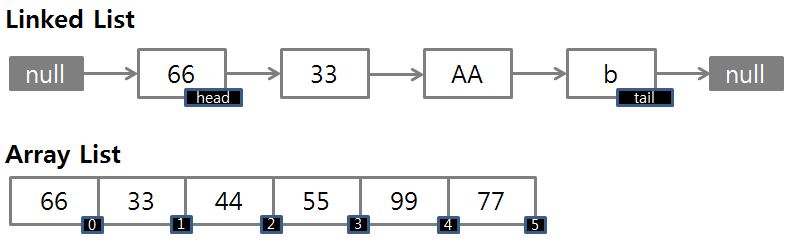
큐와 스택의 구현
- 큐 : Array는 poll 연산 이후 객체 조정 작업이 필요, Linked는 객체 1개만 제거하면 되므로 삽입 및 삭제가 용이한 Linked로 구현 권장
- 스택 : Linked는 객체 제거 작업 필요, Array는 객체 삭제 없이 index를 줄이고 초기화만 하면되므로 Array로 구현 권장
출처
https://mangkyu.tistory.com/89
좋은 글 감사합니다!

정신차려 이 각박한 세상속에서!!!