ELK
1.엘라스틱 스택

엘라스틱 서치가 처음 등장했을때는 빅데이터 파이프라인을 구성하는 플랫폼 형태로 될것이라고 예상하기 어려웠을것이다. 엘라스틱 서치가 등장했을무렵 사이트내에서 전문 검색기능을 제공하는 강력한 소프트 웨어의 필요성이 있었고 검색솔루션 서비스는 대부분 구현체를 공개하지 않아서
2.엘라스틱 서치 검색 정리
쿼리컨텍스트필터 컨텍스트쿼리스트링과 쿼리 dsl의 차이점쿼리컨텍스트: 도큐먼트에서 연관성을 계산해 최대한 비슷한 데이터를 찾아준다.필터 컨텍스트: 찾고자하는 문자열이 정확한지 아닌지 예/아니요만 가지고 찾아준다.엘라스틱 서치에서 쿼리를 사용하는 방법은 쿼리 스트링과 쿼
3.엘라스틱 서치 - 집계 정리
엘라스틱 서치에서 집계는 데이터를 그룹핑하고 통곗값을 얻는 기능으로 SQL의 GROUP BY와 통계함수를 포함하는 개념집계를 잘 이해할수록 키바나 툴을 더 잘 사용할 수 있다.집계를 위한 특별한 API가 제공되는 것이 아니다. search API의 요청본문에 aggs
4.Logstash 란?
이름 그대로 로그를 저장한다라는 의미를 가지고 있다.로그라는 것은 반정형데이터이며 세상의 모든것이 로그가 될 수 있기때문에 로그 형태를 강제할 방법도 없다. 결국 로그를 수집하는 쪽에서 로그형태를 분석하고 시스템에ㅔ서 인식할 수 있도록 로그를 정제하는 작업이 필요하다.
5.비츠 정리
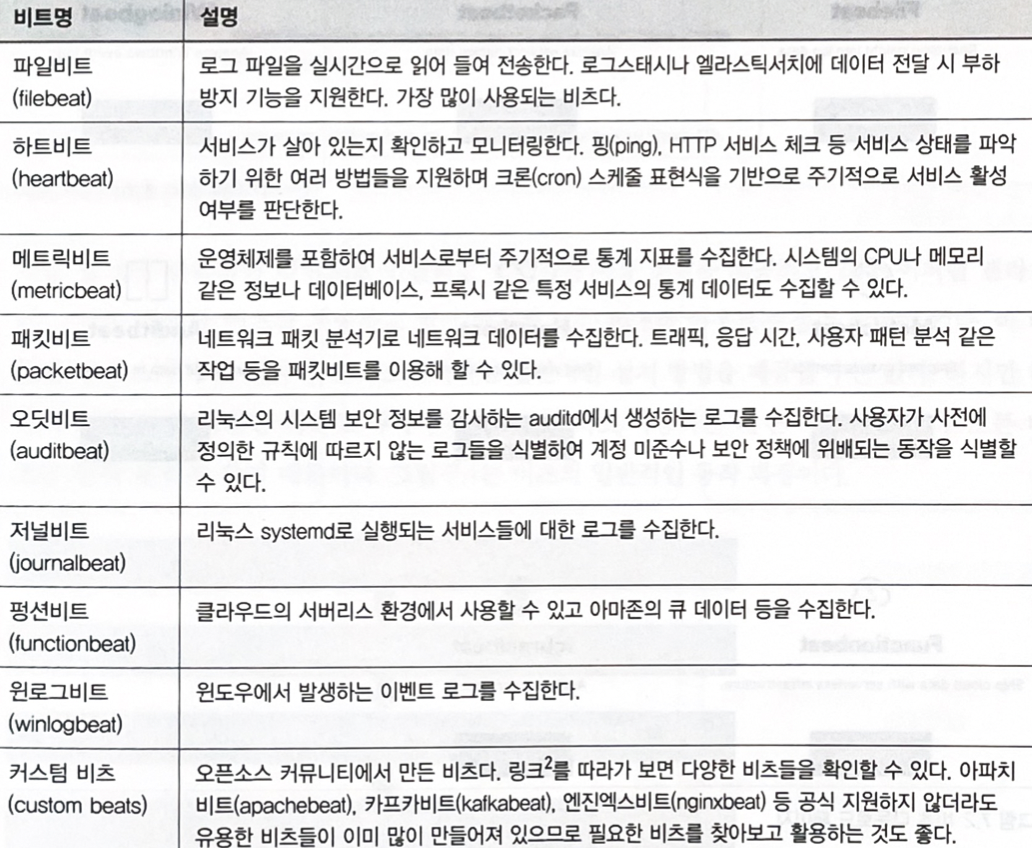
아파치 httpd 서버 관리는 아주 잘 알고 있지만 엔진 엑스에 대해서는 아직 낯설다면 로그에서 어떤 내용을 찾아서 어떻게 해석해야 할지 막막할 것이다. 리눅스 서버의 정상 동작을 파악하기 위한 메트릭을 알아내기 위해 제법 시간을 들여야 한다. 이 모든 사항을 설정으로
6.키바나 정리

빅데이터 아키텍처에서 시각화는 상당히 중요한 위치를 차지하고 있다. 엘라스틱 서치와 키바나를 결합하면 텍스트 문서부터 로그파일, 메트릭, 전자상거래 트래픽, 기업의 비즈니스 트랜잭션에 이르기까지 다양한 데이터를 탐색하고 조사할 수 있다. 이와같이 잘 사용하기 위해선 엘