카프카
1.카프카 기본 개념과 구조/프로듀서 옵션/컨슈머 옵션

카프카를 구성하는 주요 요소 주키퍼(ZooKeeper): 아파치 프로젝트 애플리케이션 이름입니다. 카프카의 * 메타데이터(metadata) 관리 및 브로커의 정상상태 점검(health check)을 담당합니다. 카프카(Kafka) 또는 카프카 클러스터(Kafka clu
2.카프카 환경 구성
AWS 실제 환경 구성 카프카를 실제 운영하는 환경에서는 서비스의 안정성이 최우선이므로 단독 서버 형태로 운영하는 경우는 거의 없고, 대부분 이중화 또는 클러스터 형태로 구성합니다. 주키퍼의 경우 최소수량인 ec2 인스턴스 3대로 구성하고, 카프카의 경우도 최소 수량인
3.카프카 스터디 (1)
1.개발 편의성은 태라바이트대에서 올라온다고 합니다. 태라바이트대정도의 데이터를 주고받아야지 카프카를 선호한다. 그 이하일때는 레빗엠큐가 훨신 유용하다. 운영비나 여러가지를 대비했을때 서비스가 클수록 카프카가 처리량 이 더 좋지만 비싸고 서비스가 작을수록
4.카프카의 내부 동작 원리
카프카는 브로커의 장애에도 불구하고 연속적으로 안정적인 서비스를 제공함으로써 데이터 유실을 방지하며 유연성을 제공합니다. 리플리케이션 동작을 위해 토픽생성시 필숫값으로 replication factor라는 옵셥을설정해야합니다.카프카는 리플리케이션 팩터라는 옵션을 이용해
5.프로듀서 내부동작원리
메시지들은 프로듀서의 send() 메소드를 통해 시리 얼라이저,파티셔너를 거쳐 카프카로 전송됩니다. 카프카의 토픽은 성능 향상을 위한 병렬 처리가 가능하도록 하기 위해 파티션으로 나뉘고, 최소 하나 또는 둘 이상의 파티션으로 구성됩니다. 그리고 프로듀서가 카프카로 전송
6.카프카 / 컨슈머의 내부동장 원리
컨슈머 오프셋 관리 컨슈머의 동작 중 가장 핵심은 오프셋 관리입니다. 컨슈머는 카프카에 저장된 메시지를 꺼내오는 역할을 하기 때문에 컨슈머가 메시지를 어디까지 가져왔는지를 표시하는것은 매우 중요합니다. 컨슈머가 어떠한 문제로 동작을 멈추고 재시작하는 경우나 컨슈머가 구
7.카프카 운영,모니터링
카프카는 애플리케이션이 워낙 안정적이기때문에 클러스터를 구성해놓은 뒤 신경을 쓰지 않는 경우가 많다. 하지만 장애를 대비해서 꼼꼼히 클러스터를 구성해 놓는것이 좋다.최근들어 아파치 카프카 오픈소스 진영에서는 카프카의 코디네이터 역할을 하는 주키퍼의 의존성을 제가혀라는
8.카프카 버전업그레이드
현제 사용중인 버전 체크하기kafkaᅳtopics.sh --version\-/usr/local/kafka/bln/kafka-toplcs.sh --version카프카의 릴리스 노트등을 잘 살펴보면서 업그레이드시 문제가 될 만한 부분은 없는지 확인합니다.스칼라 Scala
9.카프카 스키마 레지스트리
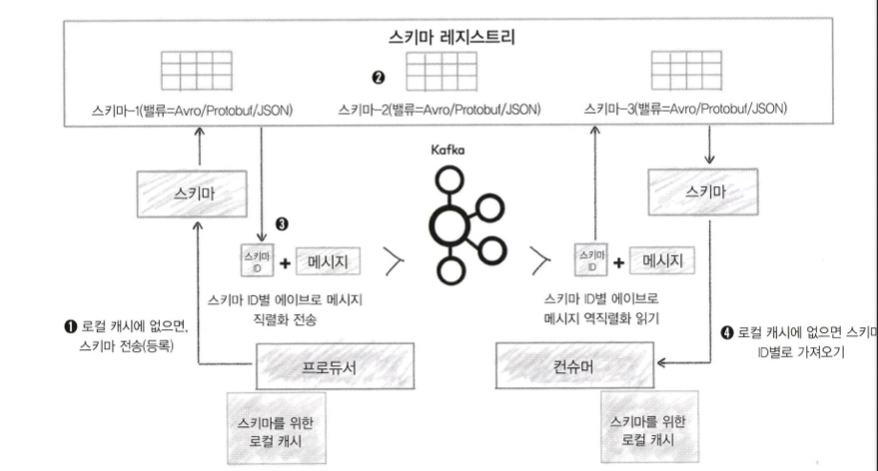
RDB에서 스키마란 정보를 구성하고 데이터가 저장될때에 약속을 만들어 주는것이라고 생각합니다. RDB에서는 스키마를 정의한 형태로 데이터를 입력해야하고 사전에 정의된 스키마의 내용과 다른 데이터를 추가하려고 시도하면 작업은 실패합니다.카프카에서 스키마가 없을때의 예를
10.카프카 커넥트 정리
카프카커넥트는 아파치 카프카의 오픈소스 프로젝트 중 하나로, 데이터베이스 같은 외부 시스템과 카프카를 손쉽게 연결하기 위한 프레임워크입니다.대용량의 데이터를 카프카의 안팎으로 손쉽게 이동시킬수 있습니다. 코드작성없이..프로듀서와 컨슈머를 직접 개발해 원하는 동작을 실행