
서론
메모리는 한정된 희소 자원이다.
반면 데이터베이스가 메모리에 저장하고자 하는 데이터는 굉장히 많다.
따라서 데이터를 메모리에 어떠한 식으로 확보할 것인가 하는 부분에서 트레이드오프가 발생한다.
1. 공짜 밥은 존재할까?
일반적으로 기억장치는 기억 비용에 따라 여러 계층으로 분류한다.
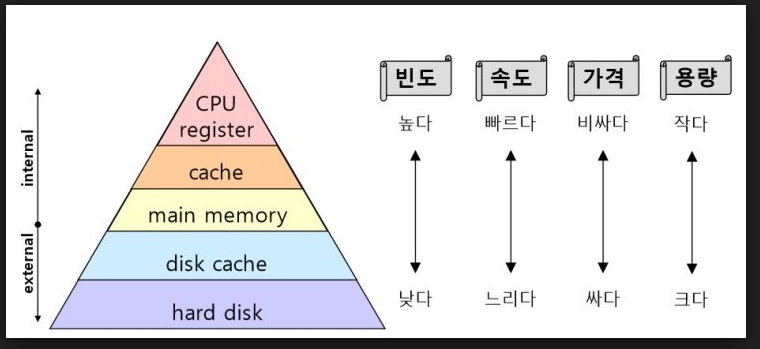
기억 비용이라고 하는 것은 간단하게 '데이터를 저장하는 데 소모되는 비용'을 나타낸다.
아래 계층으로 갈수록 '같은 비용으로 저장할 수 있는 데이터 용량이 많다'라는 것을 의미한다.
그렇다고 아래에 있는 하드 디스크가 위에 있는 메모리보다 우수한 기억장치라고 말할 수는 없다.
물론 다량의 데이터를 영속적으로 저장하는 데는 메모리보다 좋지만, 데이터 접근 속도는 메모리보다 떨어지기 때문이다.
따라서 많은 데이터를 영속적으로 저장하려 하면 속도를 잃고, 속도를 얻고자 하면 많은 데이터를 영속적으로 저장하기 힘들다는 트레이드 오프가 발생한다.
한마디로 시스템의 세계에는 공짜 밥이라는 것이 없다는 것이다.
2. DBMS와 기억장치의 관계
DBMS는 데이터 저장을 목적으로 하는 미들웨어이다.
따라서 기억장치와 떨어뜨릴 수 없는 관계이다.
DBMS가 사용하는 대표적인 기억장치는 다음과 같은 2가지이다.
- 하드디스크(HDD)
DBMS가 데이터를 저장하는 매체(저장소)는 현재 대부분 하드디스크(HDD)이다.
물론 하드디스크 이외에도 많은 선택사항이 있다.
하지만 용량, 비용, 성능의 관점에서 대부분 하드디스크를 선택하고 있다.
그렇다고 해서 DBMS가 데이터를 디스크 이외의 장소에 저장하지 않는다는 뜻은 아니다.
오히려 일반적인 DBMS는 항상 디스크 이외의 장소에도 데이터를 올려놓는다.
바로 상위 계층에 있는 메모리에 말이다.
- 메모리
메모리는 디스크에 비해 기억 비용이 굉장히 비싸다.
따라서 하드웨어 1대에 탑재할 수 있는 양이 크지 않다.
테라바이트 단위의 용량을 가지는 하드디스크와 비교하면 엄청나게 작은 크기이다.
따라서 규모 있는 상용 시스템의 데이터베이스 내부 데이터를 모두 메모리에 올리는 것은 불가능하다.
- 버퍼를 활용한 속도 향상
그렇지만 DBMS가 일부라도 데이터를 메모리에 올리는 것은 성능 향상 때문이다.
한마디로 SQL 구문의 실행 속도를 빠르게 만들기 위함이라는 것이다.
메모리는 하드 디스크보다 훨씬 빠른 기억장치이다.
따라서 자주 접근하는 데이터를 메모리 위에 올려둔다면, 같은 SQL 구문을 실행한다고 해도 디스크에서 데이터를 가져올 필요 없이 곧바로 메모리에서 읽어 빠르게 데이터를 검색할 수 있다.
디스크 접근을 줄일 수 있다면 굉장히 큰 폭의 성능 향상이 가능하다.
이는 일반적인 SQL 구문의 실행 시간 대부분은 저장소 I/O(입출력)에 사용하기 때문이다.
이렇게 성능 향상을 목적으로 데이터를 저장하는 메모리를 버퍼(buffer) 또는 캐시(cache)라고 부른다.
버퍼는 '완충제'라는 의미이다.
사용자와 저장소 사이에서 SQL 구문의 디스크 접근을 줄여주는 역할을 하므로 붙은 이름이다.
캐시 역시 사용자와 저장소 사이에서 데이터 전송 지연을 완화시켜주는 것이다.
모두 물리적인 매체로 메모리가 사용되는 경우가 많다.
따라서 하드디스크 위에 있는 데이터에 접근하는 것보다 훨씬 빠르다.
여기서는 버퍼와 캐시를 거의 같은 용어로 사용한다.
이러한 고속 접근이 가능한 버퍼에 '데이터를 어떻게, 어느 정도의 기간 동안 올릴지' 관리하는 것이 DBMS의 버퍼 매니저이다.
이러한 것을 생각하면 버퍼 매니저가 데이터베이스의 성능에 괸장히 중요한 영향을 끼친다는 것은 쉽게 이해할 수 있을 것이다.
3. 메모리 위에 있는 두 개의 버퍼
DBMS가 데이터를 유지하기 위해 사용하는 메모리는 크게 다음과 같이 두 종류이다.
- 데이터 캐시
데이터 캐시는 디스크에 있는 데이터의 일부를 메모리에 유지하기 위해 사용하는 메모리 영역이다.
만약 실행한 SELECT 구문에서 선택하고 싶은 데이터가 운 좋게 모두 이러한 데이터 캐시에 있다면, 디스크와 같은 저속 저장소에 접근하지 않고 처리가 수행된다.
따라서 굉장히 빠르게 응답한다.
반대로 운이 나빠서 데이터 캐시에 데이터가 없다면, 저속 저장소까지 데이터를 가지러 가야 한다.
따라서 SQL 구문의 응답 속도가 느려진다.
- 로그 버퍼
로그 버퍼는 갱신 처리(INSERT, DELETE, UPDATE, MERGE)와 관련 있다.
DBMS는 갱신과 관련된 SQL 구문을 사용자로부터 받으면, 곧바로 저장소에 있는 데이터를 변경하지 않는다.
일단 로그 버퍼 위에 변경 정보를 보내고 이후에 디스크에 변경을 수행한다.
이처럼 데이터베이스의 갱신 처리는 SQL 구문의 실행 시점과 저장소에 갱신하는 시점에 차이가 있는 비동기 처리이다.
SQL 구문을 실행할 때 단순히 저장소 상의 파일을 바로 변경해버리는 편이 간단한 방법이다.
그럼에도 DBMS가 이러한 시점 차이를 두는 이유는 역시 성능을 높이기 위해서이다.
저장소는 검색뿐만 아니라 갱신을 할 때도 상당한 시간이 소모된다.
따라서 저장소 변경이 끝날 때까지 기다리면 사용자는 장기간 대기하게 된다.
따라서 한 번 메모리에 갱신 정보를 받은 시점에서 사용자에게는 해당 SQL 구문이 '끝났다'라고 통지하고, 내부적으로 관련된 처리를 계속 수행하는 것이다.
4. 메모리의 성질이 초래하는 트레이드오프
앞에서 '메모리가 가진 단점은 가격이 비싸서 보유할 수 있는 데이터양이 적은 것이다'라고 이야기했다.
물론 이것만으로도 굉장히 큰 단점이지만 다른 단점이 하나 더 있다.
메모리에는 데이터의 영속성이 없다.
하드웨어의 전원을 꺼버리면 메모리 위에 올라가 있는 모든 데이터가 사라져 버리는데, 이러한 성질을 휘발성이라고 한다.
DBMS를 껐다 켜면 버퍼 위의 모든 데이터가 사라진다.
따라서 DBMS에 어떤 장애가 발생해서 서버가 죽으면, 메모리 위에 있는 모든 데이터가 날아간다.
결국 미래에 메모리 가격이 엄청나게 싸진다고 해도, 영속성이 없는 이상 기능적으로 디스크를 완전히 대체하는 것은 불가능하다.
5. 시스템 특성에 따른 트레이드오프
DBMS의 로그 버퍼의 크기는 데이터 캐시에 비해 초깃값이 굉장히 작다.
하지만 데이터베이스가 2개의 버퍼에 대해 이렇게 극단적으로 비대칭적인 크기를 할당한 데는 명확한 이유가 있다.
이는 데이터베이스가 기본적으로 검색을 메인으로 처리한다고 가정하기 때문이다.
검색 처리를 할 때는 검색 대상 레코드가 수백만에서 수천만 건에 달하는 경우도 많다.
하지만 갱신 처리를 할 때는 갱신 대상이 많아 봤자 트랜잭션마다 한 건에서 수만 건 정도밖에 안 된다.
따라서 갱신 처리에 값비싼 메모리를 많이 사용하는 것보다는, 자주 검색하는 데이터를 캐시에 올려놓는 것이 좋다고 생각하는 것이다.
실제로 많은 DBMS가 물리 메모리에 여유가 있다면, 데이터 캐시를 되도록 많이 할당할 것을 추천하고 있다.
물론 이는 데이터베이스 제작자가 자기 마음대로 정한 것이다.
만약 어떤 시스템이 검색에 비해 갱신이 많다면, 초기 설정을 그대로 사용해서는 성능이 제대로 나오지 않을 수 있다.
그럴 때는 로그 버퍼의 크기를 늘려주는 튜닝(최적화) 등을 고려해봐야 할 것이다.
6. 추가적인 메모리 영역 '워킹 메모리'
DBMS는 앞에서 설명했던 2개의 버퍼 이외에도, 일반적으로 메모리 영역을 하나 더 가지고 있다.
이는 정렬 또는 해시 관련 처리에 사용되는 작업용 영역으로 워킹 메모리(working memory)라고 부른다.
정렬은 ORDER BY 구, 집합 연산, 윈도우 함수 등의 기능을 사용할 때 실행된다.
반면 해시는 주로 테이블 등의 결합에서 해시 결합이 사용되는 때에 실행된다.
