
1. 그래프의 이해와 종류
요즘은 인터넷에서도 버스와 지하철의 노선도를 확인할 수 있다.
뿐만 아니라 출발지와 목적지를 정하면, 그에 맞는 최적의 경로를 알 수도 있다.
이러한 프로그램의 구현에 사용되는 것이 바로 그래프 알고리즘이다.
다음 그림을 보자.
이는 한 학생들의 비상연락망 구조를 표현한 그래프이다.
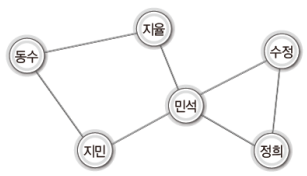
위 그림에서는 학생의 이름이 정점이고, 이를 연결하는 선이 간선이다.
이렇든 '정점(vertex)'은 연결의 대상이 되는 개체 또는 위치를 의미하고, '간선(edge)'은 이들 사이의 연결을 의미한다.
그리고 위의 그림은 학생들의 관계를 정점과 간선을 이용해서 표현했기 때문에 그래프라 할 수 있다.
위의 그래프에는 방향성이 빠져있다.
이렇듯 연결 관계에 있어서 방향성이 없는 그래프를 가리켜 '무방향 그래프(undirected graph)'라 한다.
그럼 이번에는 위의 그래프에 방향성을 부여해보겠다.
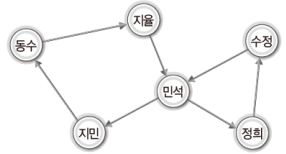
위 그래프의 간선에는 방향정보가 포함되어 있다.
이렇듯 간선에 방향정보가 포함된 그래프를 가리켜 '방향 그래프(directed graph)'또는 '다이그래프(digraph)'라 한다.
그리고 이러한 '무방향 그래프'와 '방향 그래프'는 간선의 연결형태에 따라서 '완전 그래프(complete graph)'로 구분이 된다.
다음 그림에서 보이는 것이 완전 그래프의 예이다.
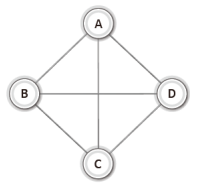
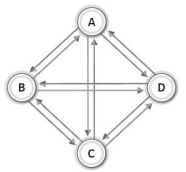
이렇듯 완전 그래프란 '각각의 정점에서 다른 모든 정점을 연결한 그래프'를 뜻한다.
때문에 정점의 수가 동일한 완전 그래프라 하더라도, 방향 그래프의 간선의 수는 무방향 그래프의 간선의 수에 두 배가 된다.
다음 그림에서 보이듯이 간선에 가중치 정보를 두어서 그래프를 구성할 수도 있다.
그리고 이러한 유형의 그래프를 가리켜 '가중치 그래프'라 한다.
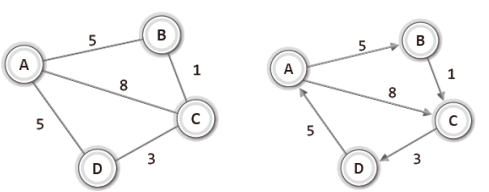
가중치는 두 정점 사이의 거리라던가 두 정점을 이동하는데 걸리는 시간과 같은 정보가 될 수 있다.
예를 들어서 위 그래프에서 A에서 C로 이동하는 가장 빠른 길을 찾는다면, 그리고 가중치가 이동에 걸리는 시간을 의미한다면 그 결과는 A → B → C 이다.
그리고 '부분 집합'과 유사한 개념으로 '부분 그래프'라는 것이 있다.
부분 집합이 원 집합의 일부 원소로 이루어진 집합인 것처럼, 부분 그래프는 원 그래프의 일부 정점 및 간선으로 이뤄진 그래프를 뜻한다.
그럼 위의 무방향 그래프를 대상으로 부분 그래프의 예를 보이겠다.
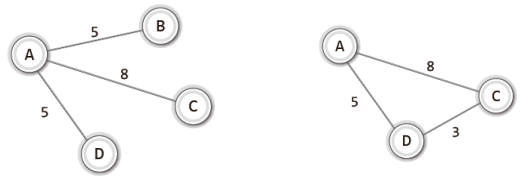
위의 그림에서는 두 개만 보였지만, 이것 외에도 원 그래프를 구성하는 정점과 간선의 일부로 이뤄진 그래프는 모두 부분 그래프가 된다.
그래프는 정점과 간선의 집합이다.
따라서 집합의 표기법을 이용해서 표현할 수 있다.
다음과 같이 정점의 집합과 간선의 집합으로 나누어서 표현을 한다.
그리고 무방향 그래프에서 정점 A와 정점 B를 연결하는 간선을 (A, B)로 표시한다.
먼저 무방향 그래프를 집합의 표기법으로 표현해 보겠다.
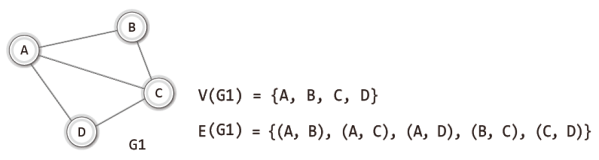
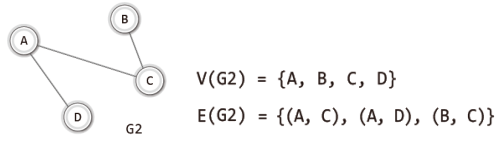
물론 무방향 그래프의 간선에는 방향성이 없으므로 (A, B)와 (B, A)는 같은 간선을 나타낸다.
그럼 이어서 방향 그래프의 집합 표현법을 설명하겠다.
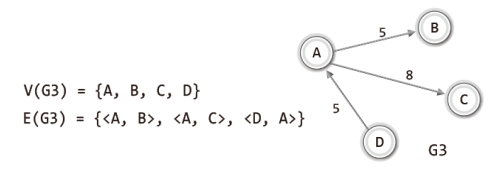
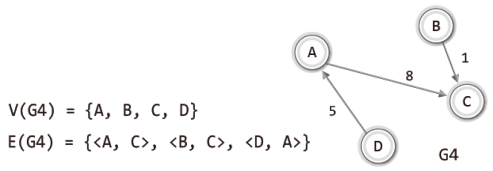
무방향 그래프의 집합 표현과 유일한 차이점은 방향성이 있는 간선의 표시법에 있다.
이제 그래프의 구현을 고민할 차례이다.
그래프를 구현하는 방법도 배열을 이용하는 방법과 연결 리스트를 이용하는 방법으로 나뉜다.
먼저 배열을 이용하는 방법을 보이겠다.
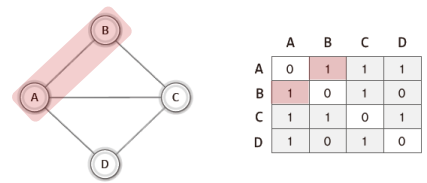
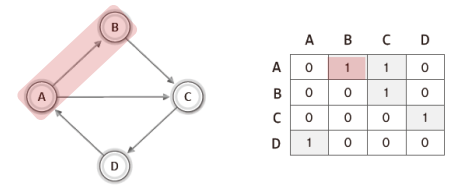
위 그림에서 보이듯이 정점이 4개면 가로세로의 길이가 4인 2차원 배열을 선언한다.
그리고 두 정점이 연결되어 있으면 1로, 연결되어 있지 않으면 0으로 표시한다.
단, 무방향 그래프에서는 방향성이 없기 때문에 하나의 간선에 대해서 두 개의 지점을 1로 표시하고, 방향 그래프에서는 다른 노드로 향하는 간선에 대해서 1로 표시한다.
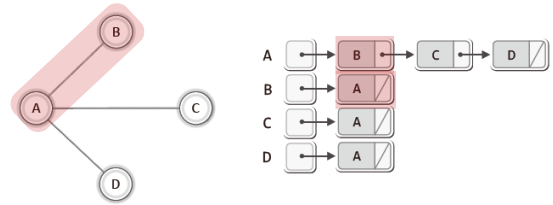
이번에는 연결 리스트 기반의 그래프 표현방법을 살펴보자.
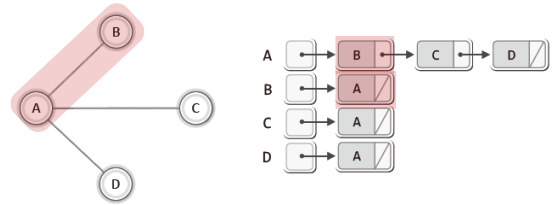
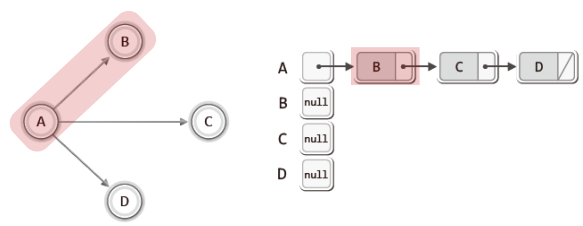
배열을 이용하는 방법과 같이 연결 리스트를 이용하는 방법에서도 무방향 그래프에서는 하나의 간선에 대해 두 개의 노드, 방향 그래프에서는 향하는 간선에 대해서만 하나의 노드로 표시한다.
2. 연결 리스트 기반의 그래프 구현
ALGraph.h
#ifndef __AL_GRAPH__
#define __AL_GRAPH__
#include "DLinkedList.h"
// 정점의 이름들을 상수화
enum {A, B, C, D, E, F, G, H, I, J};
typedef struct _ual
{
int numV; // 정점의 수
int numE; // 간선의 수
List * adjList; // 간선의 정보
} ALGraph;
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv);
// 그래프의 리소스 해제
void GraphDestroy(ALGraph * pg);
// 간선의 추가
void AddEdge(ALGraph * pg, int fromV, int toV);
// 유틸리티 함수: 간선의 정보 출력
void ShowGraphEdgeInfo(ALGraph * pg);
#endifALGraph.c
#include <stdio.h>
#include <stdlib.h>
#include "ALGraph.h"
#include "DLinkedList.h"
int WhoIsPrecede(int data1, int data2);
// 그래프의 초기화
void GraphInit(ALGraph * pg, int nv)
{
int i;
pg->adjList = (List*)malloc(sizeof(List)*nv);
pg->numV = nv;
pg->numE = 0; // 초기의 간선 수는 0개
for(i=0; i<nv; i++)
{
ListInit(&(pg->adjList[i]));
SetSortRule(&(pg->adjList[i]), WhoIsPrecede);
}
}
// 그래프 리소스의 해제
void GraphDestroy(ALGraph * pg)
{
if(pg->adjList != NULL)
free(pg->adjList);
}
// 간선의 추가
void AddEdge(ALGraph * pg, int fromV, int toV)
{
LInsert(&(pg->adjList[fromV]), toV);
LInsert(&(pg->adjList[toV]), fromV);
pg->numE += 1;
}
// 유틸리티 함수: 간선의 정보 출력
void ShowGraphEdgeInfo(ALGraph * pg)
{
int i;
int vx;
for(i=0; i<pg->numV; i++)
{
printf("%c와 연결된 정점: ", i + 65);
if(LFirst(&(pg->adjList[i]), &vx))
{
printf("%c ", vx + 65);
while(LNext(&(pg->adjList[i]), &vx))
printf("%c ", vx + 65);
}
printf("\n");
}
}
int WhoIsPrecede(int data1, int data2)
{
if(data1 < data2)
return 0;
else
return 1;
}ALGraphMain.c
#include <stdio.h>
#include "ALGraph.h"
int main(void)
{
ALGraph graph;
GraphInit(&graph, 5); // A, B, C, D, E의 정점 생성
AddEdge(&graph, A, B);
AddEdge(&graph, A, D);
AddEdge(&graph, B, C);
AddEdge(&graph, C, D);
AddEdge(&graph, D, E);
AddEdge(&graph, E, A);
ShowGraphEdgeInfo(&graph);
GraphDestroy(&graph);
return 0;
}3. 그래프의 탐색
연결 리스트는 노드의 연결 방향이 명확하기 때문에 탐색을 진행하는 것이 어렵지 않다.
반면 트리는 노드의 연결 방향이 일정치 않기 때문에 탐색을 진행하는 것이 복잡한 편이다.
하지만 이진 탐색 트리의 경우 노드의 연결에 규칙이 있기 때문에 비교적 간단한 편이라 할 수 있다.
이름 그대로 탐색을 고려하여 디자인 된 트리가 아닌가?
그렇다면 그래프의 탐색은 어떨까?
지금껏 소개한 그 어떤 자료구조보다도 탐색이 복잡한 편이다.
그래프는 정점의 구성뿐만 아니라, 간선의 연결에도 규칙이 존재하지 않기 때문이다.
그래서 그래프의 탐색을 위한, 다시 말해서 그래프의 모든 정점을 돌아다니기 위한 별도의 알고리즘 두 가지를 소개하고자 하는데, 그 두 가지는 다음과 같다.
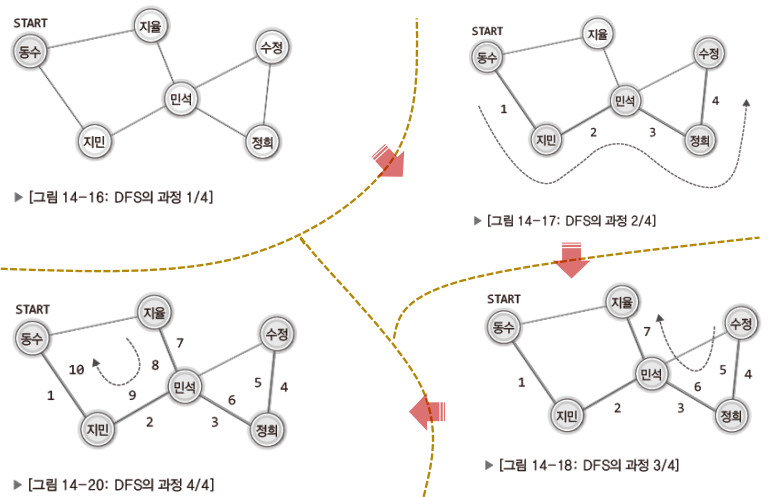
- 깊이 우선 탐색: Depth First Search(DFS)
- 너비 우선 탐색: Breadth First Search(BFS)이 두 가지 방법의 원리를 글로 설명하는 것은 이해에 별로 도움이 되지 않으니, 그림을 대상으로 각 탐색의 원리를 이해하기 바란다.
DFS
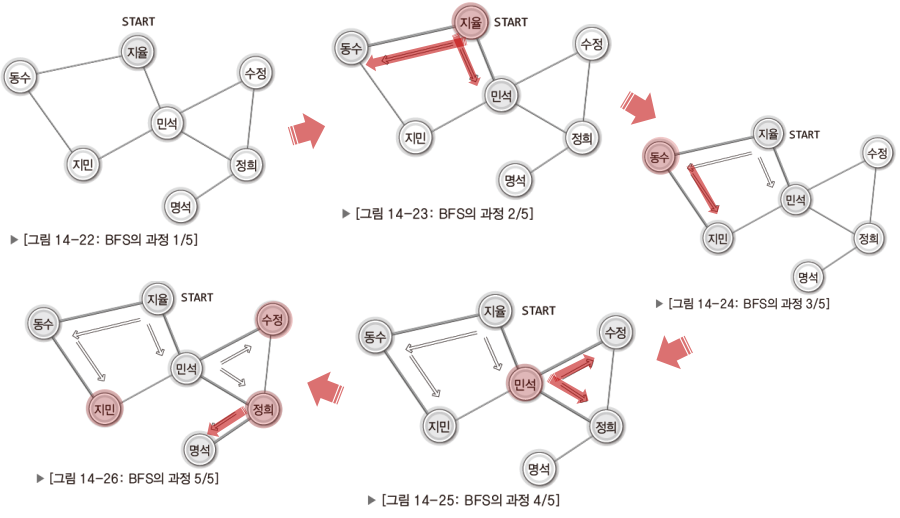
BFS
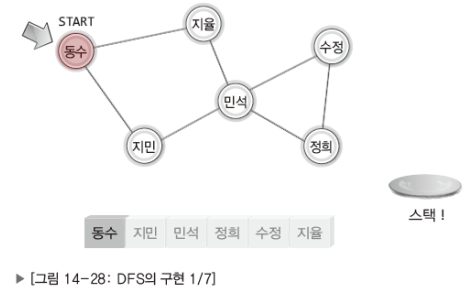
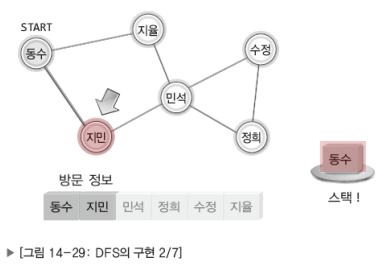
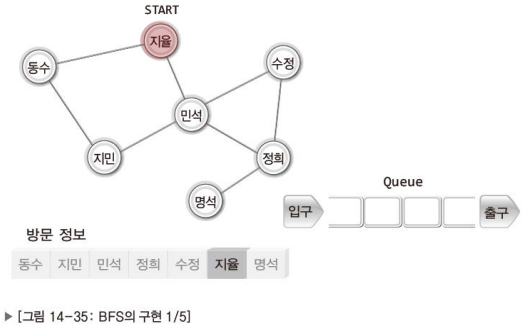
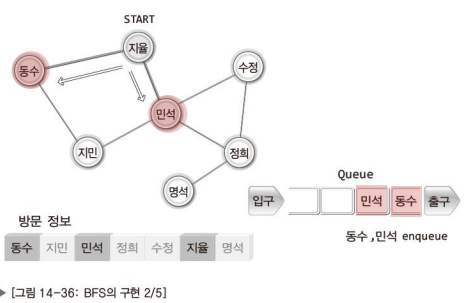
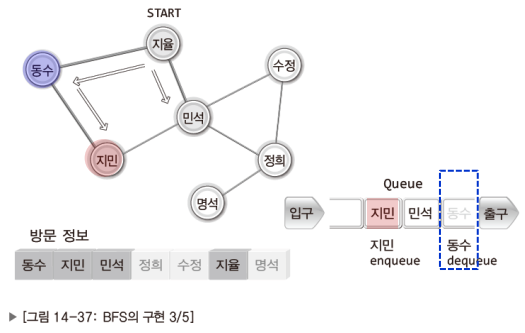
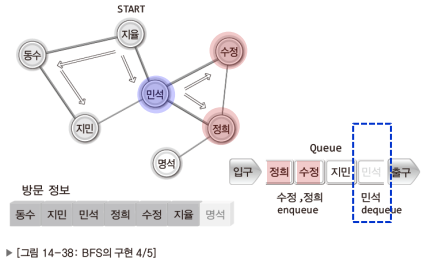
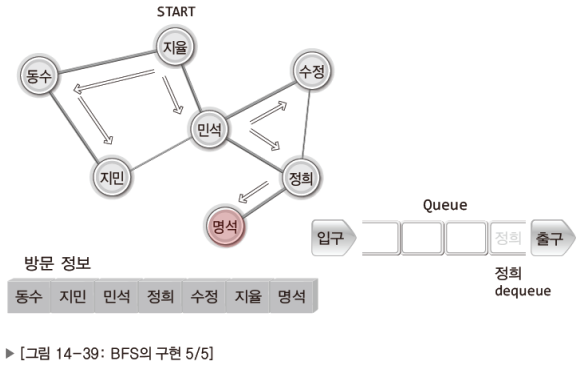
이제 DFS와 BFS의 구현방법을 고민할 차례이다.
이 역시 그림으로 이해하는게 더 빠르니 잘 보고 이해하기 바란다.
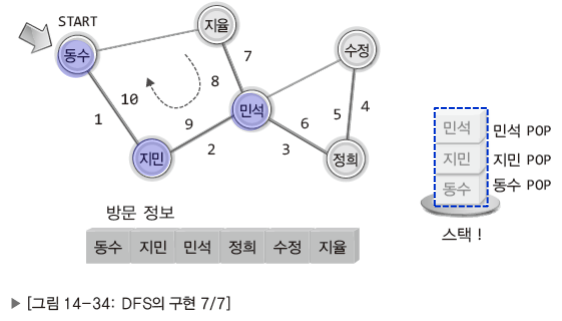
참고로 DFS는 스택을, BFS는 큐를 이용해서 구현한다.
DFS
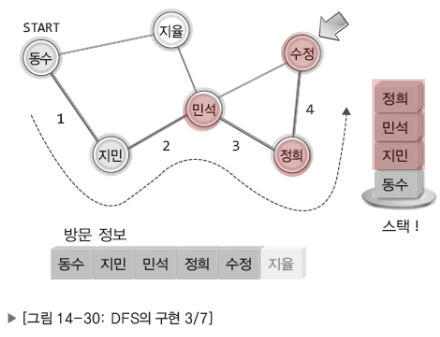
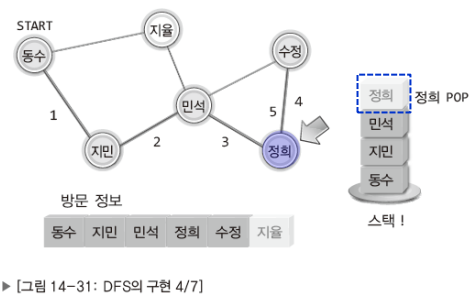
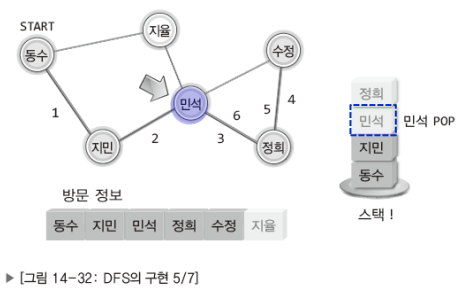
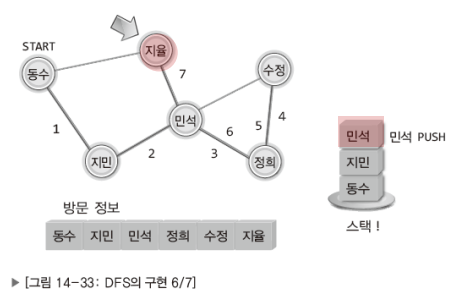
BFS
4. 최소 비용 신장 트리
마지막 이야기도 트리로 끝을 맺는다.
잊을만하니까 등장하는 트리!
그런데 그래프를 이야기하는 중간에 왜 트리를 언급하는 것일까?
사실 트리는 그래프의 한 유형이다.
다음 그래프를 보고서 정점 B에서 정점 D에 이르는 모든 '경로(path)'를 찾아서 열거해보자.
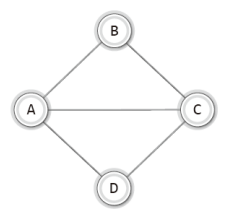
정점 B에서 정점 D에 이르는 경로는 총 4개이며 이는 다음과 같다.

이렇듯 두 개의 정점을 이슨 간선을 순서대로 나열한 것을 가리켜 '경로'라 한다.
즉 위의 네 경로는 '정점 B에서 정점 D로 이르는 경로'가 된다.
그리고 위의 네 경로와 같이 동일한 간선을 중복하여 포함하지 않는 경로를 가리켜 '단순 경로(simple path)'라 한다.
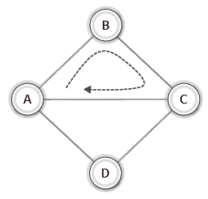
참고로 정점 B에서 정점 D에 이르는 경로 중 단순 경로가 아닌 예를 들면 다음과 같다.
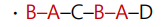
그럼 다음 질문에 답을 해보자.
"위 그림의 그래프를 대상으로 구성한 경로 A-B-C-A는 단순 경로인가요?"정점 A가 두 번 등장하지만 단순 경로가 맞다.
중복된 간선이 포함되지 않았기 때문이다.
즉, 이는 경로의 시작과 끝이 같은 단순 경로가 맞다.
중복된 간선이 포함되지 않았기 때문이다.
즉, 이는 경로의 시작과 끝이 같은 단순 경로이다.
그리고 이렇듯 단순 경로이면서 시작과 끝이 같은 경로를 가리켜 '사이클(cycle)'이라 한다.
사이클은 그림을 통해서 더 쉽게 이해할 수 있다.
그렇다면 지금껏 경로, 단순 경로, 사이클에 대해서 소개한 이유는 무엇일까?
우리가 이번에 공부할, 그리고 구성할 그래프는 다음 그림의 예와 같이 사이클을 형성하지 않는 그래프이기 때문이다.
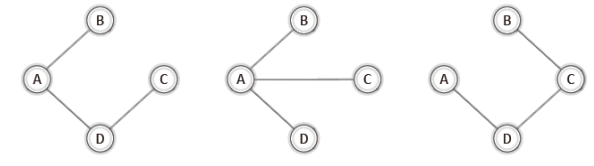
그런데 위의 그래프들에서 트리의 냄새가 나지 않는가?
사실 이들은 그래프이자 트리이다.
이점이 이해되지 않는 사람을 위해서 위의 그래프들을 90~180도 회전시켜 보겠다.
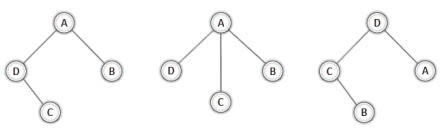
이렇듯 회전시켜놓으니 트리의 형태가 눈에 들어올 것이다.
물론 중간에 위치한 그래프는 이진 트리는 아니지만 그래도 트리의 일종이다.
그리고 위 그림과 같이 사이클을 형성하지 않는 그래프들을 가리켜 '신장 트리(spanning tree)'라 한다.
앞서 설명한 사이클을 형성하지 않는 그래프, 다시 말해서 신장 트리의 특징 두 가지는 다음과 같다.

물론 다음과 같이 가중치 그래프를 대상으로도, 그리고 그림으로 보이지는 않았지만 간선에 방향성이 부여된 방향 그래프를 대상으로도 신장 트리를 구성할 수 있다.
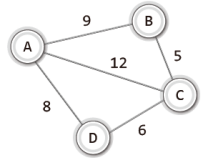
그리고 신장 트리의 모든 간선의 가중치 합이 최소인 그래프를 가리켜 '최소 비용 신장 트리(minimum cost spanning tree)' 또는 '최소 신장 트리(minimum spanning tree)'라 한다.
즉 위 그래프의 최소 비용 신장 트리는 다음의 형태가 된다.
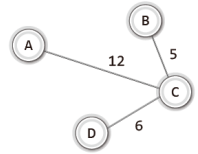
이렇듯 줄여서 MST라 표현되는 '최소 비용 신장 트리'는 개념적으로 간단하다.
최소 비용 신장 트리의 구성에 사용되는 대표적인 알고리즘 두 가지는 다음과 같다.
- 크루스칼(Kruskal) 알고리즘: 가중치를 기준으로 간선을 정렬한 후에 MST가 될 때까지 간선을 하나씩 선택 또는 삭제해 나가는 방식
- 프림(Prim) 알고리즘: 하나의 정점을 시작으로 MST가 될 때까지 트리를 확장해 나가는 방식물론 이 두 가지 이외에도 다른 알고리즘이 더 있다.
하지만 지금은 하나의 알고리즘을 정확히 이해하는 것이 더 의미있고 또 필요하다.
따라서 이 두 가지 중에서 MST를 보다 더 대표하는 크루스칼 알고리즘을 선택하여 설명하고 또 구현까지 진행하고자 한다.
그럼 크루스칼 알고리즘에 대한 설명을 시작하겠다.
위에서도 이 알고리즘을 다음과 같이 설명하고 있다.
"가중치를 기준으로 간선을 정렬한 후에 MST가 될 때까지 간선을 하나씩 선택 또는 삭제해 나가는 방식"지금은 이 문장이 의미하는 바가 이해되지 않을 것이다.
그러니 '가중치를 기준으로 간선을 정렬한다'라는 사실에만 주목하기 바란다.
이것이 크루스칼 알고리즘의 핵심이니 말이다.
그럼 이와 관련해서 다음 그림을 보자.
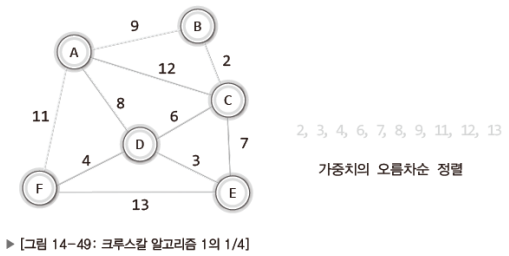
위의 그래프를 크루스칼 알고리즘을 활용하여 MST가 되게 하려 한다.
그래서 가중치를 기준으로 간선을 오름차순으로 정렬하였다.
간선의 가중치가 중복되지 않기 때문에 위의 그림에서는 가중치 정보만을 오름차순으로 정렬해 놓았다.
이제 가중치가 낮은 간선들을 하나씩 추가해보자.
낮은 가중치의 간선을 하나씩 추가하다 보면 어느 순간 MST가 되지 않겠는가?
그래서 다음과 같이 첫 번째 단계를 진행하였다.
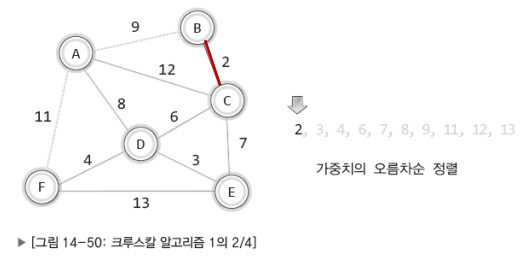
이어서 정렬 순서대로 가중치가 3, 4, 6인 간선도 추가해보겠다.
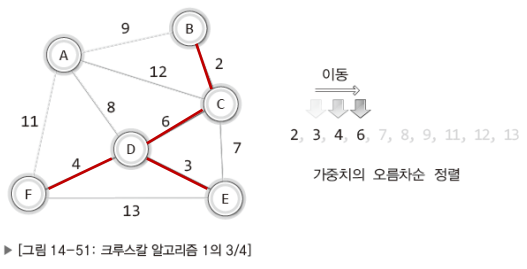
이제 위의 상태에서 가중치가 7인 간선을 추가할 차례이다.
그런데 이를 그래프에 추가하면 다음과 같은 문제가 발생한다.
"그래프 내에 사이클이 형성됩니다."정점 D와 C와 E를 연결하는 사이클이 형성된다.
그런데 MST에는 사이클이 형성되면 안되기 때문에 가중치가 7인, 정점 C와 E를 연결하는 간선은 그래프에 추가하지 않는다.
그럼 가중치가 8인 다음 간선으로 넘어가자.
그리고 이를 추가해도 그래프 내에서 사이클이 형성되지 않으니 다음 그림과 같이 이를 그래프에 추가한다.
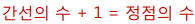
이로써 추가된 간선의 수가 정점의 수보다 하나 작은 다섯 개가 되었다.
따라서 더 이상 간선을 추가하지 않아도 된다.
왜냐하면 MST는 다음의 특성을 지니는데 위의 그래프는 이를 만족하기 때문이다.
간선의 수 + 1 = 정점의 수위 식에 대한 증명은 필요 없을 것 같다.
네 개의 정점을 대상으로 MST를 구성한다고 할 때 세 개의 간선이 필요한 것을 증명할 필요가 있겠는가?
앞서 언급했듯이 크루스칼 알고리즘의 핵심은 가중치를 기준으로 간선을 정렬한다는데 있다.
하지만 반드시 오름차순으로 정렬해야 하는 것은 아니다.
크루스칼 알고리즘에는 내림차순으로 정렬된 상황에서 적용할 수 있는 모델도 있으니 말이다.
간선을 내림차순으로 정렬하면 낮은 가중치의 간선을 하나씩 추가하는 방식이 아니라, 높은 가중치의 간선을 하나씩 빼는 방식으로 알고리즘이 전개된다.
때문에 크루스칼 알고리즘을 두 가지로 구분하기도 한다.
그럼 다음 그림을 시작으로 크루스칼 알고리즘의 또 다른 적용 모델을 소개하겠다.
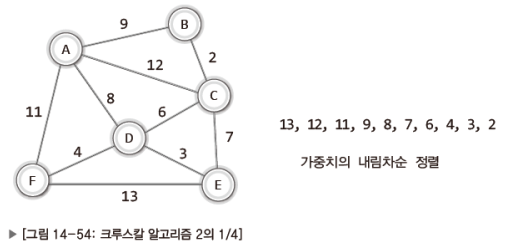
쉽게 생각하자.
내림차순으로 정렬되었으니, 앞쪽에 위치한 높은 가중치의 간선들을 하나씩 빼내어 어느 순간에 MST가 되게 하는 것이 핵심이다.
그럼 첫 번째 단계를 보이겠다.
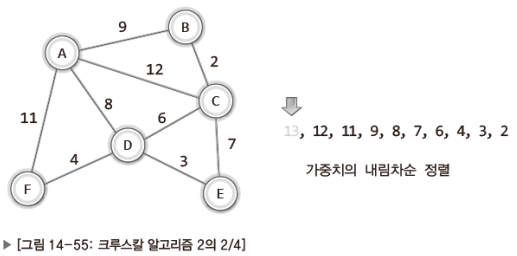
위 그림에서 보이듯이 가중치가 13인, 제일 높은 가중치의 간선이 삭제되었다.
이렇듯 정렬 순서대로 간선을 하나씩 제거해 나간다.
그러면 이어서 가중치가 12, 11, 9인 간선이 순서대로 삭제되어 다음의 상태가 된다.
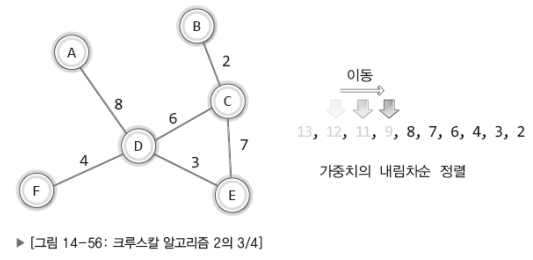
이어서 가중치가 8인 간선을 삭제할 차례이다.
그런데 이 간선을 삭제하면 다음과 같은 문제가 발생하기 때문에 삭제하지 않는다.
"가중치가 8인 간선을 삭제하면 정점 A와 정점 D는 어떠한 경로를 통해서든 닿지 않습니다."MST의 모든 정점은 간선에 의해서 하나로 연결되어야 하기 때문에 이러한 경우에는 간선을 삭제하지 않는다.
그리고 이를 통해서 다음과 같은 결론을 내릴 수 있다.
"두 정점이 다른 경로를 통해서도 연결되어 있는 경우에만 해당 간선을 삭제할 수 있다."그럼 다음 순서로 가중치가 7인 간선을 삭제할 수 있겠는가?
삭제할 수 있다!
삭제를 해도 정점 C와 정점 E는 C-D-E를 잇는 경로로 연결되기 때문이다.
즉 가중치가 7인 간선이 삭제되어 다음의 상태가 된다.
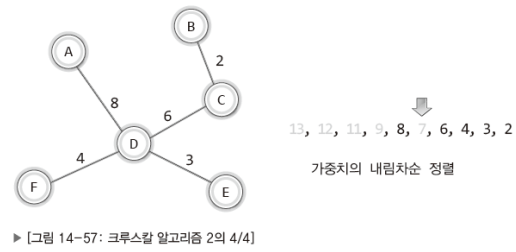
이로써 MST가 완성되었다.
정점의 수가 간선의 수보다 하나 더 많은 상황이니 MST가 완성되었음에 의심이 필요 없다.
이것으로 '자료구조'에 대한 설명에 끝을 맺겠다.
