서론
앞 챕터에서 COUNT 함수로 행 개수를 구할 수 있었다.
COUNT의 인수로는 집합을 지정하였는데 이제까지 봐온 예제에서는 테이블 전체 혹은 WHERE 구로 검색한 행이 그 대상이었다.
지금부터는 GROUP BY 구를 사용해 집계함수로 넘겨줄 집합을 그룹으로 나누는 방법을 설명하겠다.
이 같은 그룹화를 통해 집계함수의 활용범위를 넓힐 수 있다.
먼저 그룹화에 관해 간단히 살펴보고, 조건을 지정하거나 정렬하여 사용하는 법에 관해 알아보겠다.
1. GROUP BY로 그룹화
GROUP BY 구로 그룹화하기에 앞서 sample_table의 데이터를 다시 한 번 살펴보자.
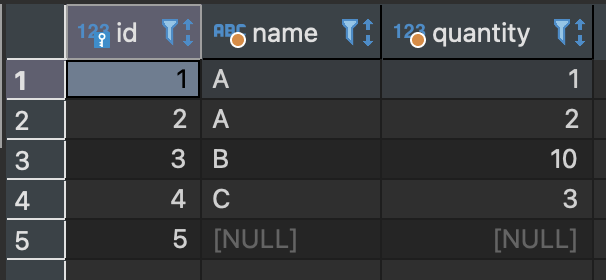
name 열이 A인 행은 두 개, B와 C인 행은 각각 한 개씩 있다.
이때 name 열에서 같은 값을 가진 행끼리 한데 묶어 그룹화한 집합을 집계함수로 넘겨줄 수 있다.
GROUP BY 구에는 그룹화할 열을 지정한다.
물론 복수로도 지정할 수 있다.
name 열을 지정하면 어떤 결과가 나오는지 알아보자.
SELECT name FROM sample_table GROUP BY name;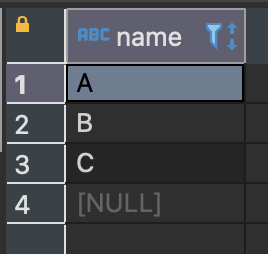
DISTINCT를 지정했을 때와 같은 결과가 나왔다.
GROUP BY 구에 열을 지정하여 그룹화하면 값이 같은 행끼리 하나의 그룹으로 묶인다.
따라서 GROUP BY를 지정해 그룹화하면 DISTINCT와 같이 중복을 제거하는 효과가 있다.
그럼, DISTINCT로 중복을 제거하는 것과 GROUP BY로 그룹화하는 것은 어떤 차이가 있을까?
실은 GROUP BY 구를 지정하는 경우에는 집계함수와 함께 사용하지 않으면 별 의미가 없다.
GROUP BY 구로 그룹화된 각각의 그룹이 하나의 집합으로서 집계함수의 인수로 넘겨지기 때문이다.
구체적으로 어떻게 처리되는지 COUNT와 SUM 집계함수를 사용해 알아보겠다.
SELECT name, COUNT(name), SUM(quantity) FROM sample_table GROUP BY name;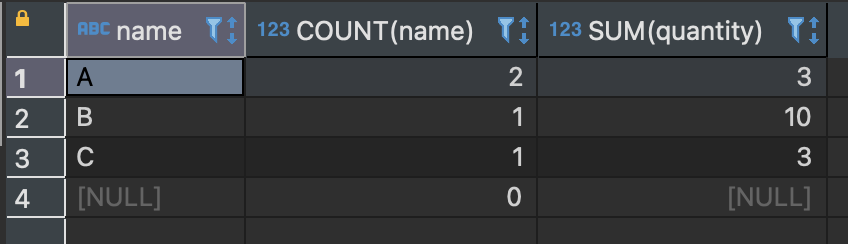
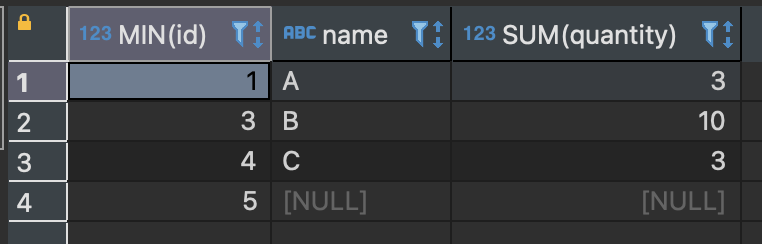
GROUP BY name에 의해 name 열의 값이 A, B, C 그리고 NULL의 네 개 그룹으로 나뉜다.
A 그룹에는 두 개의 행이 있는데, COUNT는 행의 개수를 반환하므로 2 가 된다.
A 그룹에 해당하는 2개 행의 quantity 열 값은 각각 1 과 2 이다.
SUM은 합계를 구하는 집계함수이므로 3 을 반환하였다.
2. HAVING 구로 조건 지정
WHERE 구의 조건식에서는 집계함수를 사용할 수 없다.
WHERE 구로 행을 검색하는 처리가 GROUP BY로 그룹화하는 처리보다 순서상 앞서기 때문이다.
//내부 처리 순서
WHERE 구 => GROUP BY 구 => HAVING 구 => SELECT 구 => ORDER BY 구대신 HAVING 구를 사용한다.
SELECT name, COUNT(name) FROM sample_table GROUP BY name HAVING COUNT(name)=1;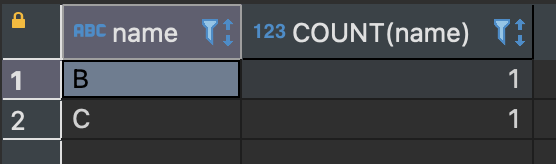
3. 복수열의 그룹화
GROUP BY에 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구에 기술해서는 안 된다.
SELECT id, name, quantity FROM sample_table GROUP BY name; //에러 발생!GROUP BY로 그룹화하면 반환되는 결과는 그룹당 하나의 행이다.
하지만 name 열 값이 'A' 인 그룹의 id열과 quantity 열 값은 각각 1과 2이다.
이때 그룹마다 하나의 값을 반환해야 하는데, 1과 2 중에 어느 것을 반환해야 할지 모르기 때문에 에러가 발생하는 것이다.
이때 집계함수를 사용하면 집합은 하나의 값으로 계산되므로, 그룹마다 하나의 행을 출력할 수 있다.
즉 다음과 같이 쿼리를 작성하면 문제없이 실행할 수 있다.
SELECT MIN(id), name, SUM(quantity) FROM sample_table GROUP BY name;