
1. 배열과 연결 리스트: 개념 및 차이점
배열 (Array)
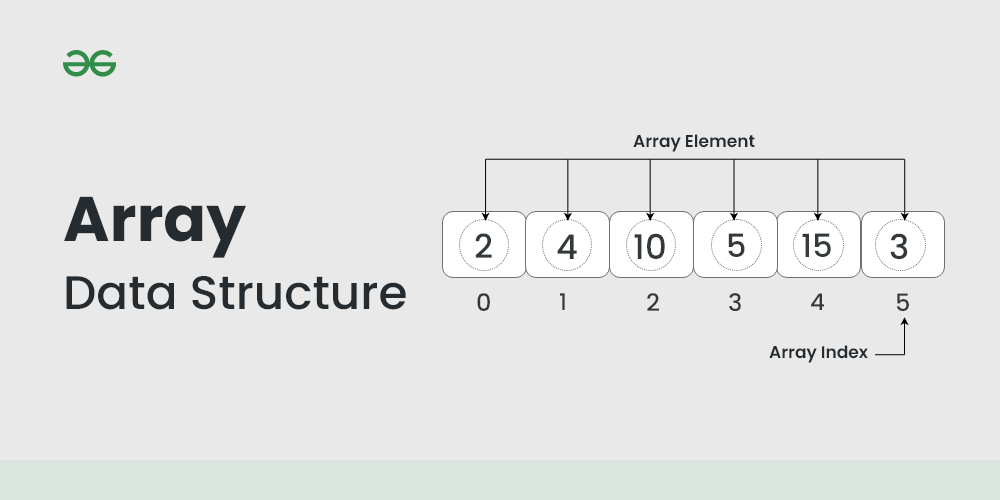
배열은 고정된 크기의 연속적인 메모리 공간에 동일한 데이터 타입의 원소를 저장하는 자료 구조입니다. 각 원소는 인덱스를 사용하여 접근할 수 있으며, 인덱스는 0부터 시작합니다.
장점:
- 빠른 접근: 인덱스를 통해 원소에 빠르게 접근할 수 있으며 시간 복잡도는
O(1)입니다. - 메모리 효율: 원소들이 연속적으로 저장되므로
메모리 효율이 좋습니다.
단점:
- 크기 제한: 배열은 생성 시 크기가
고정되며, 크기를 변경하려면 새 배열을 생성하고 데이터를 복사해야 합니다. - 삽입 및 삭제 비효율성: 중간에 원소를 삽입하거나 삭제할 때 다른 원소들을 이동시켜야 하므로 비효율적이며 시간 복잡도는
O(n)입니다.
연결 리스트 (Linked List)
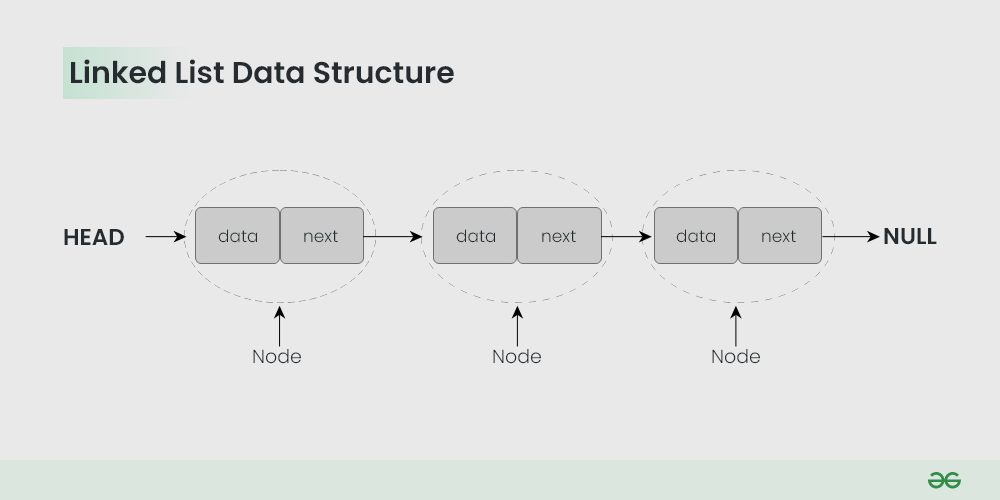
연결 리스트는 각 원소가 데이터와 다음 원소를 가리키는 링크(포인터)로 이루어진 자료 구조입니다. 각 노드는 이전 노드와 다음 노드를 가리키는 링크로 연결되어 있습니다.
장점:
- 동적 크기: 원소를 삽입하거나 삭제하기 용이하며, 크기에 제한이 없습니다.
- 삽입 및 삭제 효율: 중간에 원소를 삽입하거나 삭제할 때 링크만 업데이트하면 되므로 효율적이며 시간 복잡도는
O(1)입니다.
단점:
- 느린 접근: 특정 인덱스에 접근하기 위해 처음부터
순차적으로 탐색해야 하므로 접근이 느립니다. 시간 복잡도는O(n)입니다. - 추가 메모리 사용: 각 노드는 데이터와 링크를 저장해야 하므로
추가 메모리 사용이 필요합니다.
2. 배열의 적용 및 예시
배열은 다음과 같은 상황에서 유용합니다:
예시: 빠른 원소 접근이 필요한 경우
- 배열은
인덱스를 통한 빠른 원소 접근이 필요한 경우에 적합합니다. 예를 들어, 데이터베이스 검색 결과를 배열로 저장하면 특정 레코드에 빠르게 접근할 수 있으며 시간 복잡도는O(1)입니다.
배열을 사용하지 않는 경우:
- 만약 데이터의 크기가
동적으로 변하며, 중간에 데이터를 삽입하거나 삭제해야 하는 경우 LinkedList나 동적 배열과 같은 다른 자료 구조를 고려할 수 있습니다. 이러한 경우 시간 복잡도가 상대적으로 낮은 자료 구조를 선택해야 합니다.
3. 스택과 큐: 개념 및 활용
스택 (Stack)
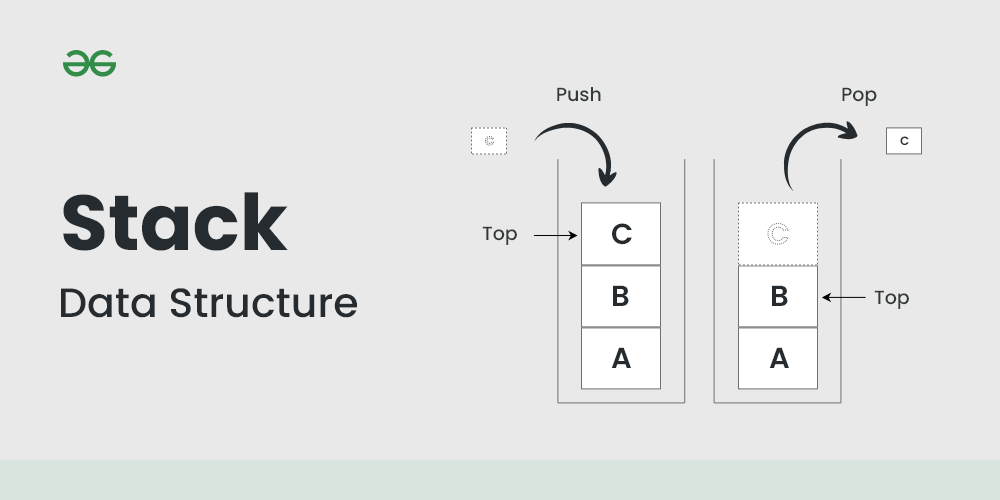
스택은 선입후출의 특성을 가진 자료구조로, 원소가 추가되는 push와 원소가 제거되는 pop의 두 가지 주요 연산으로 이루어져 있습니다. 스택은 배열 또는 연결 리스트를 사용하여 구현할 수 있습니다.
활용 예시:
- 브라우저의 '뒤로 가기' 기능: 웹 페이지 방문 기록을 스택에 저장하여, 사용자가 '뒤로 가기' 버튼을 클릭할 때마다 최근에 방문한 페이지를 스택에서 꺼내어 보여줍니다.
- 메모리 영역의 스택 영역: 함수 호출 시에 지역 변수 및 매개 변수 등의 정보가 스택 영역에 저장되며, 함수가 종료될 때 해당 정보는 스택에서 제거됩니다.
큐 (Queue)
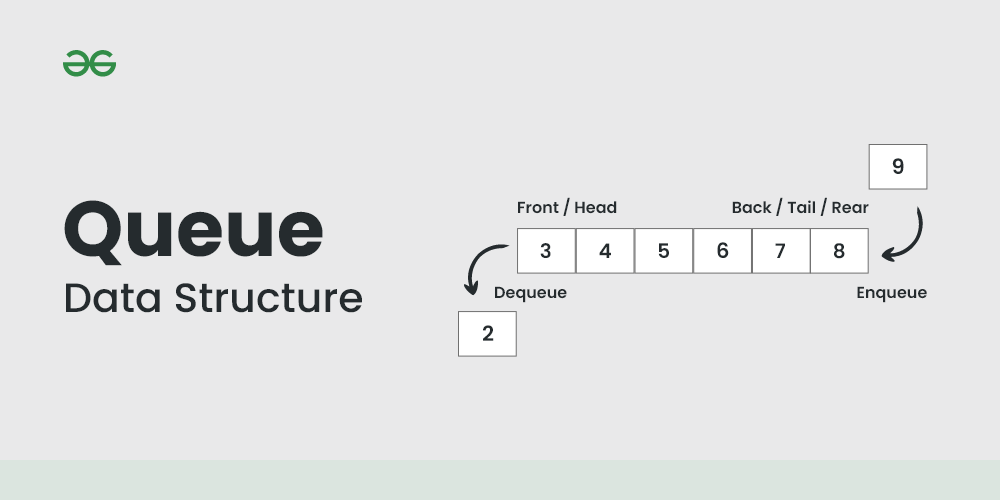
큐는 선입선출의 특성을 가진 자료구조로, 원소가 추가되는 enqueue와 원소가 제거되는 dequeue의 두 가지 주요 연산으로 이루어져 있습니다. 주로 연결 리스트를 사용하여 큐를 구현합니다.
활용 예시:
- 프린터 큐: 여러 문서의 인쇄 요청을 순차적으로 처리하기 위해 큐에 저장합니다.
- CPU 스케줄링의 Ready Queue: 프로세스들이 CPU 할당을 기다리는 대기열에서 큐를 사용하여 순차적으로 처리됩니다.
4. 우선순위 큐와 힙: 개념 및 구현
우선순위 큐 (Priority Queue)
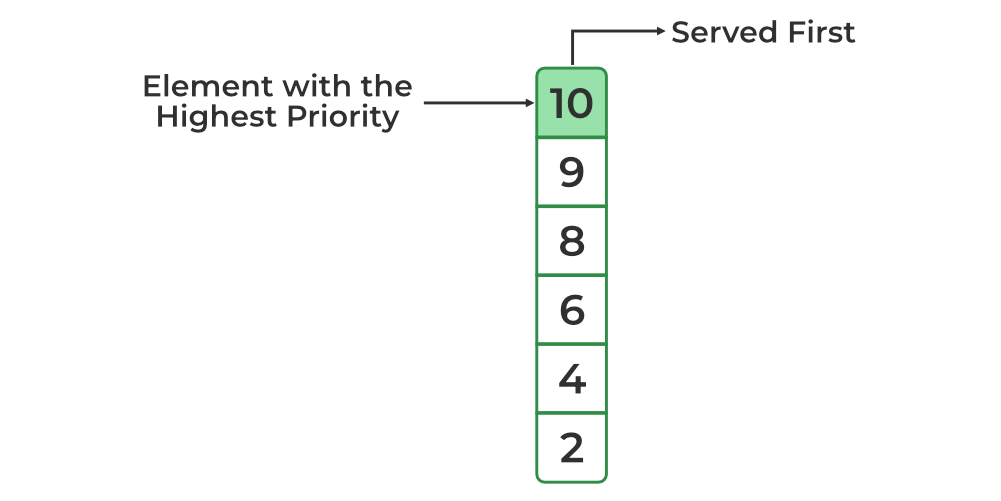
우선순위 큐는 큐와는 다르게 우선순위에 따라 원소를 꺼내게 됩니다. 우선순위 큐는 배열, 연결 리스트, 그리고 힙을 통해 구현될 수 있
습니다. 효율적인 구현을 위해선 힙이 주로 사용됩니다.
구현 방법:
- 배열 또는 연결 리스트: 원소를 추가할 때마다 우선순위에 따라 정렬
- 힙 (Heap): 삽입 및 삭제 연산이
O(logN)의 시간 복잡도를 보장
힙 (Heap)
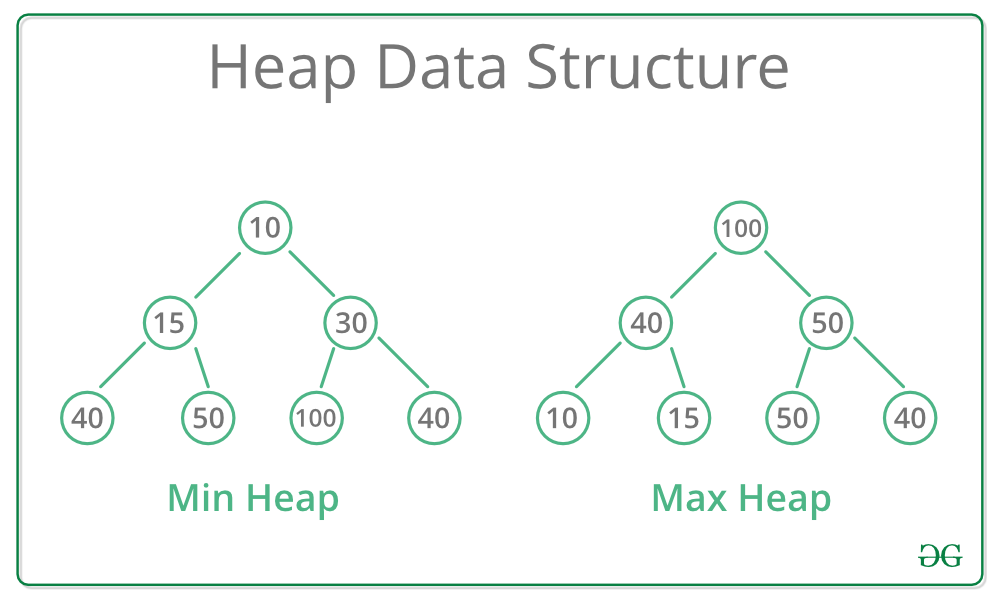
힙은 '완전 이진 트리'의 특징을 갖는 특별한 트리 구조입니다. 부모 노드와 자식 노드 간에 일정한 순서 관계를 가집니다.
동작 원리:
- 삽입: 트리의 가장 마지막 위치에 노드를 추가하고, 부모 노드와의 관계를 확인하여 힙의 성질을 유지하도록 조정 (
Heapify연산) - 삭제: 루트 노드를 제거하고, 트리의 가장 마지막 노드를 루트로 이동시킨 후, 자식 노드와의 관계를 확인하여 힙의 성질을 유지하도록 조정 (
Heapify연산)
모든 삽입 및 삭제 연산은 O(logN)의 시간 복잡도로 수행됩니다.
5. 해시 테이블 (Hash Table)
해시 테이블의 개념
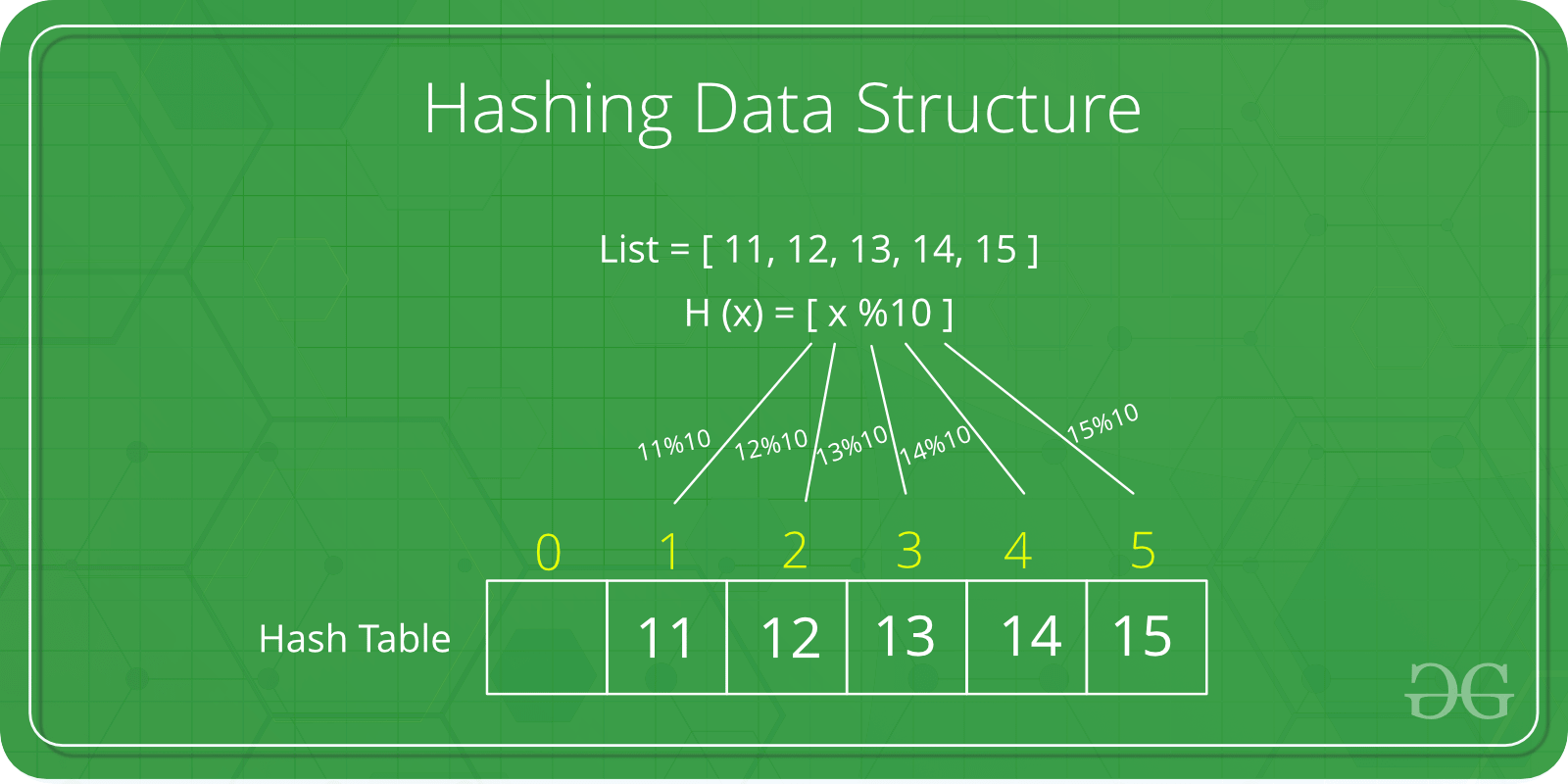
해시 테이블은 Key-Value 쌍으로 값을 저장하는 자료구조입니다. 이 자료구조의 눈에 띄는 특징은 검색 시간 복잡도가 평균적으로 O(1)이라는 것입니다. 이는 해시 함수를 통해 Key를 특정 해시 값(인덱스)으로 빠르게 변환하고, 해당 인덱스를 바로 참조해 Value를 검색하기 때문입니다.
해시 테이블의 검색 시간 복잡도
평균적으로 O(1)의 빠른 검색 속도를 제공하는데, 이는 해시 함수의 효과적인 변환 덕분입니다. 해시 함수는 Key를 고유한 해시 값(인덱스)으로 변환해주며, 이 인덱스를 통해 Value에 바로 접근할 수 있습니다.
해시 충돌 (Hash Collision)과 해결 방법
때로는 서로 다른 Key가 같은 해시 값(인덱스)을 반환하는 해시 충돌이 발생할 수 있습니다. 이런 문제를 해결하기 위해 다음과 같은 방법들이 주로 사용됩니다:
- Chaining: 각 인덱스에 연결 리스트를 할당해, 동일한 해시 값에 여러 Key-Value 쌍을 저장합니다.
- Open Addressing: 충돌이 발생하면 다른 인덱스로 데이터를 저장하는 방식입니다.
체이닝 (Chaining) vs. 개방 주소법 (Open Addressing)
-
체이닝 방식의 장단점:
- 장점:
- 메모리를 효율적으로 사용
- 해시 함수 선택의 유연성
- 상대적으로 적은 메모리 사용
- 단점:
- 해시 값에 연결된 리스트가 길어지면 검색 효율성 감소
- 외부 저장 공간 필요성
- 장점:
-
개방 주소법의 장단점:
- 장점:
- 해시 테이블 내에서만 데이터 저장 및 처리
- 외부 저장 공간 필요 없음
- 단점:
- 해시 함수의 성능에 민감
- 데이터 증가에 따른 저장소 확장 필요
- 장점:
6. 이진 탐색 트리 (BST)와 AVL 트리
이진 탐색 트리 (BST)

BST는 이진 트리의 특별한 형태로, 노드에 저장된 값들이 특정한 순서를 따르는 구조입니다. 주요 특징은:
- 각 노드의 왼쪽 서브 트리에는 현재 노드의 값보다 작은 값들만, 오른쪽 서브 트리에는 큰 값들만 위치합니다.
- 검색 연산의 시간 복잡도는 트리의 높이에 의존하며, 평균적으로
O(logN)입니다.
AVL 트리
AVL 트리는 BST의 균형을 유지하는 확장된 형태입니다. 주요 특징은:
- 노드의 왼쪽과 오른쪽 서브 트리의
높이 차이가 최대1입니다. - 높이의 균형을 유지하기 위해 삽입 및 삭제 시
회전 연산을 수행합니다.
RBT (Red-Black Tree)
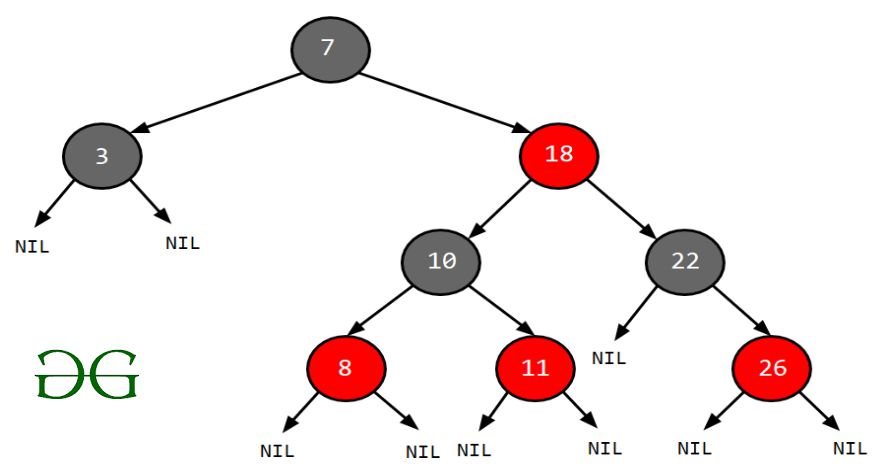
RBT는 BST의 한 종류로, 균형을 유지하는 특성을 가진 자료구조입니다. RBT는 삽입 및 삭제 연산 시 특정 규칙을 따라 색상을 변경하며 균형을 유지합니다. 노드의 child가 없을 경우 child를 가리키는 포인터는 NIL 값을 저장합니다. 이러한 NIL들을 leaf node로 간주합니다.
7. 이진 트리와 그래프
이진 트리와 그래프의 차이
-
그래프
노드와 엣지로 구성된 포괄적인 구조로,순환 구조를 포함할 수 있습니다. -
이진 트리
특정한 규칙을 따르는 그래프의 한 형태입니다. 각 노드는 최대 두 개의 자식만을 가지며, 순환 구조는 존재하지 않습니다.
8. 이진 트리의 순회 (Traversal)
-
전위 순회 (Preorder Traversal)
루트 노드→왼쪽 서브 트리→오른쪽 서브 트리 -
중위 순회 (Inorder Traversal)
왼쪽 서브 트리→루트 노드→오른쪽 서브 트리 -
후위 순회 (Postorder Traversal)
왼쪽 서브 트리→오른쪽 서브 트리→루트 노드
