
서론
지금까지 배운 SQL 명령은 대부분 '하나의 테이블'을 사용하는 것이었다.
지금부터는 '복수의 테이블'을 사용해 데이터를 검색하는 방법에 관해 알아보겠다.
1. UNION 으로 합집합 구하기
SQL에서는 SELECT 명령의 실행 결과를 하나의 집합으로 다룰 수 있다.
합집합을 계산할 경우에는 UNION 키워드를 사용한다.
예제로 사용할 테이블은 sample_a와 sample_b로 우선은 두 개의 테이블에 저장된 데이터부터 확인해보겠다.
SELECT * FROM sample_a;
SELECT * FROM sample_b;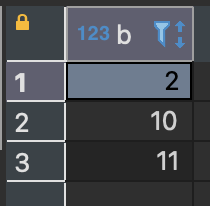
그럼 UNION으로 두 테이블의 합집합을 구해보자.
SELECT * FROM sample_a
UNION
SELECT * FROM sample_b;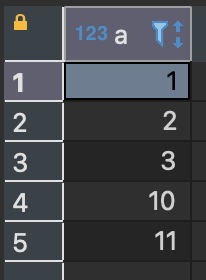
이때 두 개의 SELECT 명령을 하나의 명령으로 합치는 만큼, 세미콜론(;)은 맨 나중에 붙인다는 점에 주의해야 한다.
또한 각각의 SELECT 명령이 반환하는 열의 개수나 자료형은 모두 같아야 한다.
위 예제에서는 각 테이블에 열이 하나밖에 없고 그 자료형 또한 같았기 때문에 애스터리스크(*)를 사용해도 문제가 없었다.
하지만 보통 테이블은 하나 이상의 열이 존재하고 자료형 또한 다양하므로 실제로 UNION을 사용해서 합집합을 보고싶을 때는 다음과 같이 열을 따로 지정해주어야 한다.
SELECT a FROM sample_a
UNION
SELECT b FROM sample_b;2. UNION과 ORDER BY
UNION으로 SELECT 명령을 결합해 합집합을 구하는 경우, 각 SELECT 명령에 ORDER BY를 지정해 정렬할 수는 없다.
ORDER BY를 지정할 때 마지막 SELECT 명령에만 지정하도록 한다.
SELECT a FROM sample_a
UNION
SELECT b FROM sample_b ORDER BY b;하지만 이 쿼리에서는 에러가 발생한다.
ORDER BY를 지정할 수 있다고 해도 마지막의 SELECT 명령의 결과만 정렬하는 것이 아니고 합집합의 결과를 정렬하는 것이기 때문이다.
이때 두 개의 SELECT 명령에서 열 이름이 서로 일치한다면 문제가 없겠지만 반드시 그렇다는 보장이 없다.
이런 경우 서로 동일하게 별명을 붙여 정렬할 수 있다.
SELECT a AS c FROM sample_a
UNION
SELECT b AS c FROM sample_b ORDER BY c;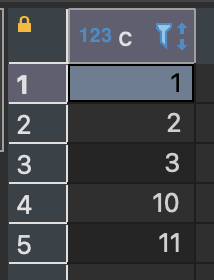
3. UNION ALL
UNION은 합집합을 구하는 것이므로 두 개의 집합에서 겹치는 부분은 공통 요소가 된다.
예를 들어 앞에서 살펴본 sample_a와 sample_b 예제에서는 양쪽 모두 2가 포함되어 있었다.
그리고 이들은 UNION을 통해 합해지는 과정에서 하나만 존재하게 된다.
하지만 경우에 따라서는 중복을 제거하지 않고 2개의 SELECT 명령의 결과를 그냥 합치고 싶을 때도 있을 것이다.
이러한 경우에 UNION ALL을 사용한다.
SELECT a FROM sample_a
UNION ALL
SELECT b FROM sample_b;
UNION ALL은 두 개의 집합을 단순하게 합치는 것이다.
UNION에서는 이미 존재하는 값인지를 검사하는 처리가 필요한 만큼, UNION ALL 쪽이 성능적으로 유리한 편이다.
즉, 중복값이 없는 두 테이블의 합집합을 구하는 경우에는 UNION ALL을 사용하는 편이 좋은 성능을 보여준다.
