
서론
SQL은 데이터베이스라 불리는 '데이터 집합'을 다루는 언어이다.
이 같은 집합의 개수나 합계가 궁금하다면 SQL이 제공하는 집계함수를 사용하여 간단하게 구할 수 있다.
그렇다면 먼저 COUNT 집계함수를 사용해서 테이블의 행 개수를 구해보겠다.
1. COUNT로 행 개수 구하기
SQL은 집합을 다루는 집계함수를 제공한다.
일반적인 함수는 인수로 하나의 값을 지정하는 데 비해 집계함수는 인수로 집합을 지정한다.
이 때문에 '집합함수'라고도 불린다.
즉, 집합을 특정 방법으로 계산하여 그 결과를 반환한다.
COUNT 함수는 인수로 주어진 집합의 '개수'를 구해 반환한다.
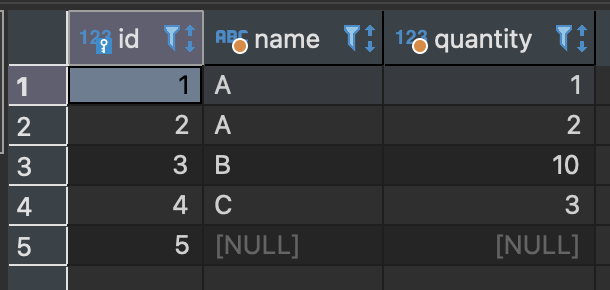
SELECT COUNT(*) FROM sample_table;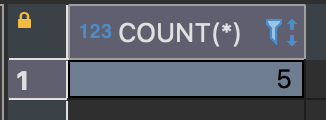
sample_table에는 전부 다섯 개의 행이 있으며 COUNT의 결괏값도 5이다.
인수로 * 가 지정되어 있는데 이는 SELECT 구에서 '모든 열(테이블 전체)'을 나타낼 때 사용하는 메타문자와 같다.
sample_table에는 전부 5개의 행이 있으므로 그 결과 5가 반환되었다.
집계함수의 특징은 복수의 값(집합)에서 하나의 값을 계산해내는 것이다.
일반적인 함수는 하나의 행에 대하여 하나의 값을 반환한다.
한편 집계함수는 집합으로부터 하나의 값을 반환한다.
이렇게 집합으로부터 하나의 값을 계산하는 것을 '집계'라 부른다.
2. 집계함수와 NULL 값
COUNT의 인수로 열명을 지정할 수 있다.
열명을 지정하면 그 열에 한해서 행의 개수를 구할 수 있다.
실제로 집계함수는 보통 그 같은 목적을 위해 많이 사용된다.
여기서 문제는 NULL 값을 어떻게 취급하느냐 하는 것이다.
이전에도 언급했듯 SQL에서는 NULL 값을 고려해야 한다.
집계함수는 집합 안에 NULL 값이 있을 경우 이를 제외하고 처리한다.
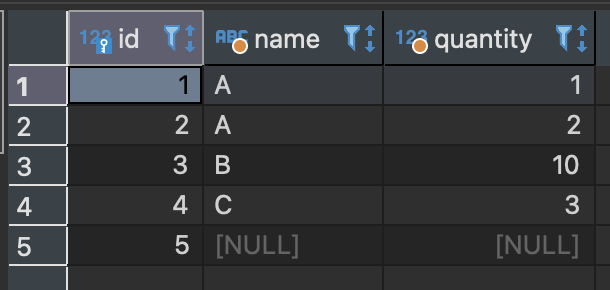
SELECT COUNT(id), COUNT(name) FROM sample_table; 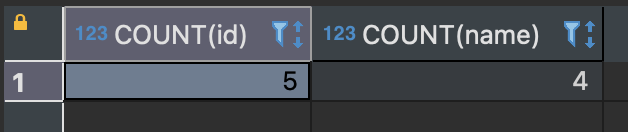
3. DISTINCT로 중복 제거
집합을 다룰 때, 경우에 따라서는 집합 안에 중복된 값이 있는지 여부가 문제될 때도 있다.
sample_table을 사용해서 구체적인 예를 들어 설명하겠다.
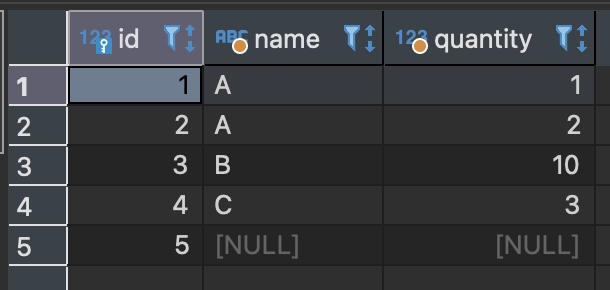
sample_table의 id 열은 '1, 2, 3 ...' 과 같이 일련의 숫자로 되어 있으므로 각 행의 값은 중복되지 않는다.
한편 name 열의 값은 맨 위의 두 줄이 'A'로 값이 중복된다.
SQL의 SELECT 명령은 이러한 중복된 값을 제거하는 함수를 제공한다.
이때 사용하는 키워드가 바로 DISTINCT 이다.
SELECT DISTINCT name FROM sample_table;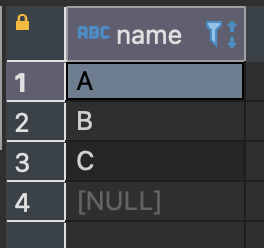
DISTINCT는 예약어로 열명이 아니다.
SELECT 구에서 DISTINCT를 지정하면 중복된 데이터를 제외한 결과를 클라이언트로 반환한다.
4. 집계함수에서 DISTINCT
COUNT 집계함수를 이용해 집합의 개수를 구하는 방법을 살펴보았다.
그리고 DISTINCT를 지정하면 중복된 값을 제거할 수 있다는 것도 알았다.
그렇다면 이번에는 name 열에서 NULL 값을 제외하고, 중복하지 않는 데이터의 개수를 구하는 경우를 생각해보자.
어떻게 하면 좋을까?
방법은 집계함수의 인수로 DISTINCT를 사용한 수식을 지정하는 것이다.
DISTINCT는 집계함수의 인수에 수식자로 지정할 수 있다.
DISTINCT를 이용해 집합에서 중복을 제거한 뒤 COUNT로 개수를 구할 수 있는 것이다.
그럼 실제로 확인해보자.
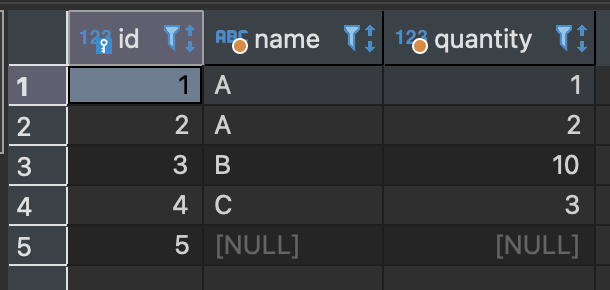
SELECT COUNT(DISTINCT name) FROM sample_table;
