개요
모든 어플리케이션은 클라이언트로부터 로그를 남겨야 할 필요가 있을 것이다.(그러지 않은 경우는...?) 단순히 파일로 로그를 찍어서 남길 수 있겠지만, 서비스가 커질 수록 쉽지가 않다. 그래서 로그 관리를 위한 아키텍처를 조사해보았다.
로그 관리
- 어떤 수준의 로그를 수집할것인가에 대한 로그 분리 관점
- 로그를 어떻게 모을 것인가의 수집 관점
- 모인 로그를 어떻게 분석하고 사용할 것인가에 대한 분석 관점
- 분석된 결과를 어떻게 볼 것인가에 대한 활용 관점
로그 분리 관점
- 시스템 로그 : OS에서부터 RDBMS 등과 같은 미들웨어에서 올라오는 로그 등, 시스템의 문제가 발생 했을 때 장애의 원인 파악을 위해서 필요
- 애플리케이션 로그 : 개발자가 작성한 애플리케이션 로그, 애플리케이션의 장애 원인 파악이나 디버깅을 위해서 생성되는 로그
- 비즈니스 로그 : 사용자의 서비스 사용 형태, 거래 기록을 이용한 감사 등을 이용해서 애플리케이션에서 인위적으로 찍어내고 수집하는 로그
수집 관점
- 파일을 주기적으로 FTP로 끌어 오기
- Log4J와 같은 Log Appender를 이용해서 직접 수집
- 시스템에 연결하거나 DBMS 등에 쓴 로그를 주기적으로 긁어 오는 방법
- 로그를 수집하기 위해서 여러가지 프레임워크가 제공되는 LogStash가 대표적
분석 관점
- 저장된 로그를 ETL을 이용하여 OLAP에 넣고 분석 하는 방법
- 하둡을 이용하여 데이터를 분석하는 배치 기반의 분석 방법
- Storm/Spark 등을 이용하여 실시간으로 로그를 분석하는 방법
활용 관점
- 분석된 로그를 OLAP DB에 넣고 Saiku나 BI 대시 보드 도구 등을 이용해서 시각화 가능
로그 시스템 종류
일반적인 구조

| 컴포넌트 | 역할 | 솔루션 |
|---|---|---|
| API 서버 | 로그를 클라이언트로 부터 수집하고 데이터를 정제 | 웹 서버 |
| Log Storage | 로그 저장소 | Elastic Search Hadoop, HBase (하둡) Drill, Druid (SQL 기반 빅데이터 플랫폼) |
| Message Consumer | MQ 로 부터 로그를 Message Consumer 가 순차적으로 읽어서 Log Storage에 저장 | Multi Thread(or Process) + Timer 를 조합하여 메시지를 폴링 방식으로 읽어오는 어플리케이션 |
| Message Q | 로그 저장소가 순간적으로 많은 트래픽을 감당할 수 없는 경우가 많기 때문에, 중간에 MQ 를 넣어서 들어오는 로그를 저장하며 완충 | Kafka (대량 큐) AWS SQS or 구글Pub/Sub (클라우드 큐) Rabbit MQ (일반적인 큐) |
| Reporting | 저장된 로그는 Reporting 툴을 이용하여 시각화 | Kibana Zeppeline, Jupyter |
😮 각 필요한 솔루션을 모두 배우고, 설치하고 운영하는데 많은 비용과 시간이 필요한 작업
Google Cloud Logging
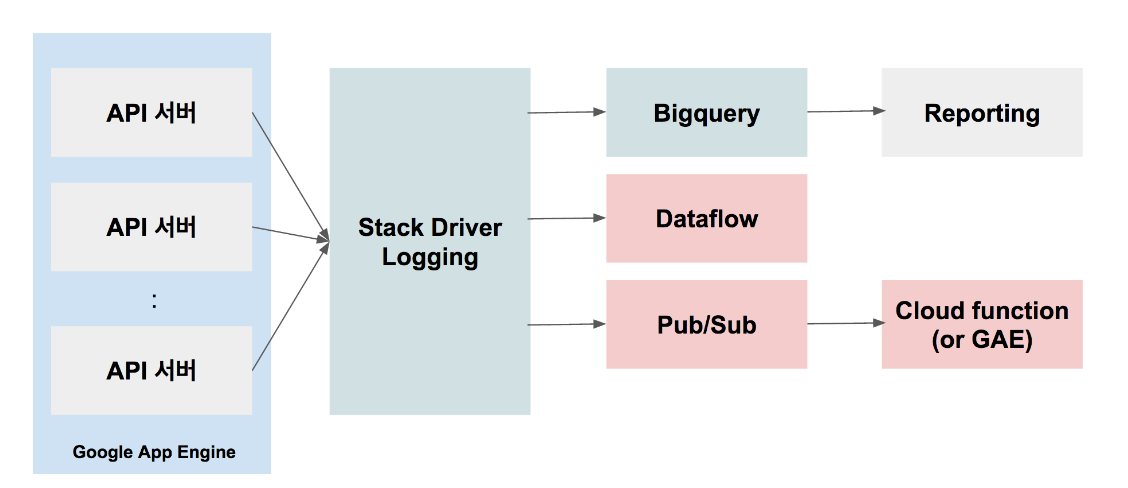
스택드라이버와 빅쿼리를 이용한 로그 수집 시스템 구현
| 컴포넌트 | 역할 |
|---|---|
| API 서버 | API 서버를 이용하여 클라이언트로 부터 로그 수집. API 서버는 스택 드라이버 로깅 서비스로 로그 전송 |
| Stack Driver Logging | Export 기능을 이용하여 수집된 로그를 실시간으로 빅쿼리로 전송 GCS (Google Cloud Storage) 로 주기적으로 파일로 로그 데이터를 보내거나 Pub/Sub이나 BigQuery 로 실시간으로 데이터를 보낼 수 있음 Message Queue/Consumer 구현 불필요, 로그를 직접 빅쿼리에 저장 |
| BigQuery | 방대한 양의 데이터에서 거의 실시간으로 SQL 쿼리를 실행하는 데 사용할 수 있는 페타바이트 규모의 분석 데이터웨어하우스 |
| Reporting | 저장된 로그는 구글 데이타 스튜디오, 제플리, 주피터와 같은 리포팅 도구에 의하여 시각화 |
AWS

| 컴포넌트 | 역할 |
|---|---|
| Amazon ES (Elasticsearch Service) | AWS 클라우드에서 Elasticsearch 클러스터의 배포, 운영 및 확장을 단순화하는 관리 서비스 |
| Kibana | AWS ES 와 통합 된 분석 및 시각화 플랫폼을 제공 |
| AWS Lambda | Amazon CloudWatch 에서 Amazon ES 도메인으로 로그 데이터를 로드하기 위해 사용 서버를 프로비저닝하거나 관리하지 않고도 코드 실행 및 소비한 계산 시간에 대해서만 비용 지불 |
| Amazon CloudWatch | 애플리케이션 및 시스템 전반의 성능 변화에 대응하고, 리소스 사용률을 최적화하고, 운영 상태에 대한 통일 된 시각을 얻을 수있는 데이터 및 실행 가능한 통찰력을 제공 |
| Amazon Cognito | Kibana 대쉬보드 사용자 인증 제공 웹과 모바일 앱에 빠르고 손쉽게 사용자 가입, 로그인 및 엑세스 제어 기능을 추가 할 수 있습니다. |
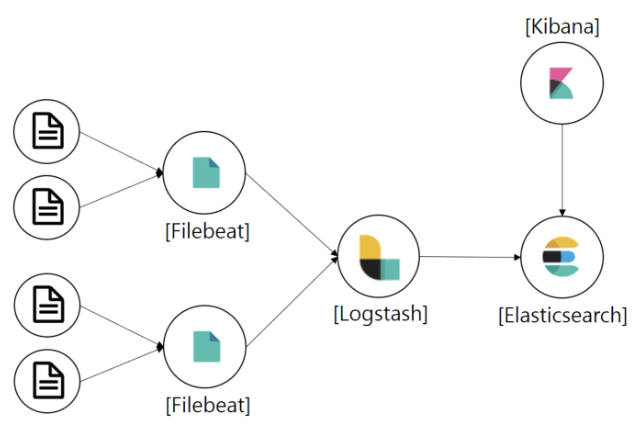
ELK stack
| 컴포넌트 | 역할 |
|---|---|
| Elasticsearch | 대규모의 데이터를 손쉽게 저장, 검색, 분석 |
| Kibana | 다양한 데이터 소스를 위해 미리 구성된 대시보드를 이용해 KPI를 강조 표시하는 라이브 프리젠테이션을 만들고 단일 UI에서 배포 관리 |
| Logstash | 확장형 플러그인 에코시스템으로 구성된 동적 데이터 수집 파이프라인 |
| Filebeat | 단말장치의 데이터를 전송하는 경량 데이터 수집기 플랫폼 |
출처 및 참고

ㅎㅅㅎ