
CPU가 진행되는 전체적인 개요
보통 컴퓨터 프로그램을 실행을 한다면
CPU 는 평균적으로 0.3 나노초 마다 1 번 연산을 수행하는데, 하드 디스크에서 데이터가 올 때 까지 기다리는 동안 대략 3천만 번의 연산을 수행할 수 있다. 만일 CPU 가 매번 하드 디스크에서 필요한 명령어를 읽어들인다면 엄청난 시간을 낭비하게된다.
CPU <-> RAM <-> 하드디스크 (or SSD)
1. 하드 디스크에서 저장되어 있는 프로그램의 위치를 찾아서 램에 복사해놓는다.
2. CPU 는 램에서 명령어를 읽어들여서 실행을 한다.
따라서 위 순서로 실행이 된다.
사실 CPU 에서 RAM 에 접근하는 속도도 그리 빠른 편은 아니다. 옆에 붙어 있기는 해도, CPU에서 연산은 150번 수행할 수 있는 시간이다.
그래서 우리는 캐시(Cache)라는 것을 사용한다. 캐시는 계층별로 L1, L2, L3 캐시로 이루어져 있는데, 제일 가까운 L1 캐시에 저장되어 있는 데이터를 읽는 데에는 1 나노초 밖에 걸리지 않게된다. 따라서 데이터를 읽는 시간을 줄일 수 있는것이다 !
아래 표를 참고해보자.
저장 장치별 접근시간
| 저장장치 | 접근 시간 | 단위 변환 |
|---|---|---|
| RAM | 약 100 나노초 (ns) | 0.1 마이크로초 = 0.0001 밀리초 |
| SSD | 50 ~ 150 마이크로초 (μs) | 50,000 ~ 150,000 나노초 = 0.05 ~ 0.15 밀리초 |
| 하드 디스크 (HDD) | 1 ~ 10 밀리초 (ms) | 1,000,000 ~ 10,000,000 나노초 |
| 참고: 단위 변환 | 1 ms = 1,000 μs = 1,000,000 ns |
저장 장치별 접근시간(비유)
| 접근 대상 | 실제 접근 시간 | 현실 시간 환산 |
|---|---|---|
| 1 CPU 사이클 | 0.4 ns | 1초 |
| L1 캐시 접근 | 0.9 ns | 2초 |
| L2 캐시 접근 | 2.8 ns | 7초 |
| L3 캐시 접근 | 28 ns | 1분 |
| RAM 접근 | 약 100 ns | 4분 |
| NVMe SSD 접근 | 약 25 μs | 17시간 |
| 일반 SSD 접근 | 50 ~ 150 μs | 1.5일 ~ 4일 |
| 일반 하드디스크 접근 | 1 ~ 10 ms | 1 ~ 9달 |
| 서울 ↔ 샌프란시스코 패킷 전송 시간 | 약 180 ms | 14년 |
CPU가 램에서 데이터를 읽는 과정
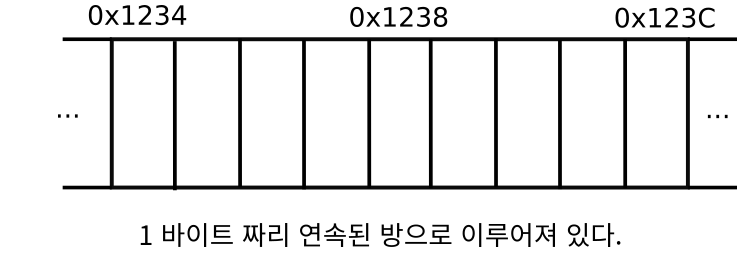
위 그림과 같이 RAM은 1바이트 짜리 연속된 방으로 이루어져 있다. 우리가 RAM에서 데이터를 읽어올 때 해당 자료형 주소부터 바이트 별로 어디 까지 읽을 지를 얘기해주어야한다.
또한 우리는 데이터에 접근하기 위해 레지스터의 해당하는 주소값을 먼저 대입해야한다.
이렇게 CPU 는 주소값 을 통해서 램에 어디에 접근할지 명령하게 된다.
그런데, CPU 가 독자적으로 명령을 내릴 수 있는 것은 아니다. CPU 가 명령을 내리기 위해서는 해당 명령어를 어디선가 가져와야 하는데, 이와 같이 CPU 에 실행할 명령어를 제공하는 것을, 쉬운 말로 프로그램을 실행한다 라고 합니다.
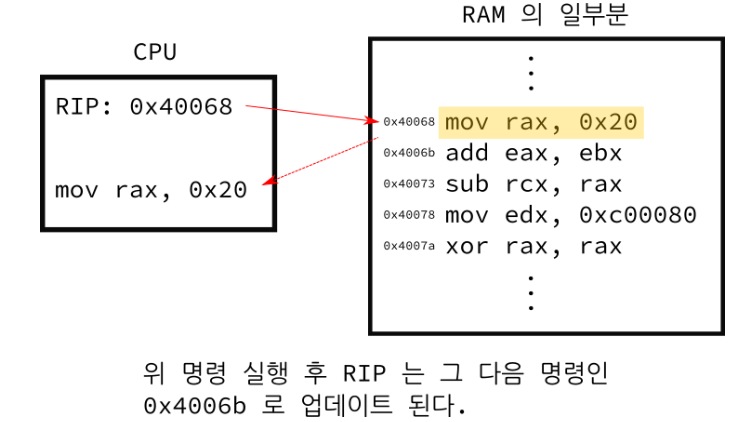
RIP는 레지스터 인덱스 포인터이다.
CPU 는 현재 내가 어떠한 프로그램을 실행하고 있는지 모르기때문에, 그저 현재 자신의 RIP 레지스터가 가리키는 위치에 있는 명령어를 실행하고 그 다음 명령어의 위치로 RIP 를 증가시키는데에만 관심이 있을 뿐 어떠한 프로그램에서 해당 명령어를 실행하는지는 알 수가 없다.
프로그램의 파일을 메모리에 복사해주고, 해주는 것들은 운영체제에서 해결해준다. 말 그대로 OS에 의해 프로세스가 추상화 되어, 프로세서는 그냥 해당 프로세스가 필요한 명령어만 실행하게 되는 것이다.
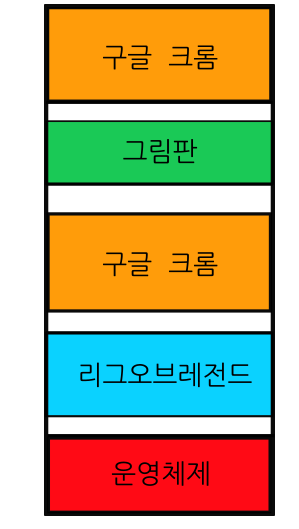
위 그림은 실제로 여러 프로그램들이 같이 실행되고 있을 때 램의 모습의 예시이다. 그런데 실제로 저런식으로 할당 되진 않는다. 위는 CPU가 생각하고있는 메모리 구성이다. 위와 같은 경우에 프로그램을 실행 할 때마다 매번 다른 메모리 주소를 사용하도록 프로그램 명령어를 다시 작성해야해서 비효율적이다.
우리는 가상메모리 즉 메모리 추상화를 한다고 하지 않았나?
그래서 CPU 에서는 메모리를 조금 더 효율적으로 관리하기 위해서 특별한 메커니즘을 제공한다.
가상메모리 vs 물리메모리
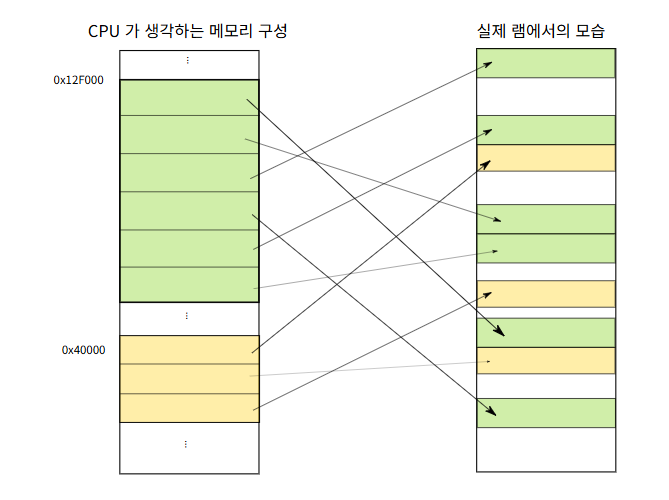
실제 CPU가 생각하는 메모리와 램에서 할당되는 메모리는 차이가 있다. CPU는 가상메모리 즉 추상화된 메모리를 보고 있는 것이고, 실제로는 일정한 크기의 조각들로 쪼개져서 각기 다른영역으로 대응된다.
이러한 변환 방식을 페이징(paging) 이라고 하고, 변환이 되는 최소의 메모리 단위를 페이지(page) 라고 한다. (페이지의 크기는 여러가지로 설정할 수 있지만 대부분의 경우 1 페이지는 4 KB 정도라고 한다.)
어떻게 변환을 수행할 지 기록한 테이블을 페이지 테이블(page table) 이라고 하는데, 이 페이지 테이블은 각 프로그램 마다 하나씩 가지고 있다. 이 덕분에 다른 프로그램에 할당된 주소와 똑같아도 절대 겹치지 않는다는 것이다.
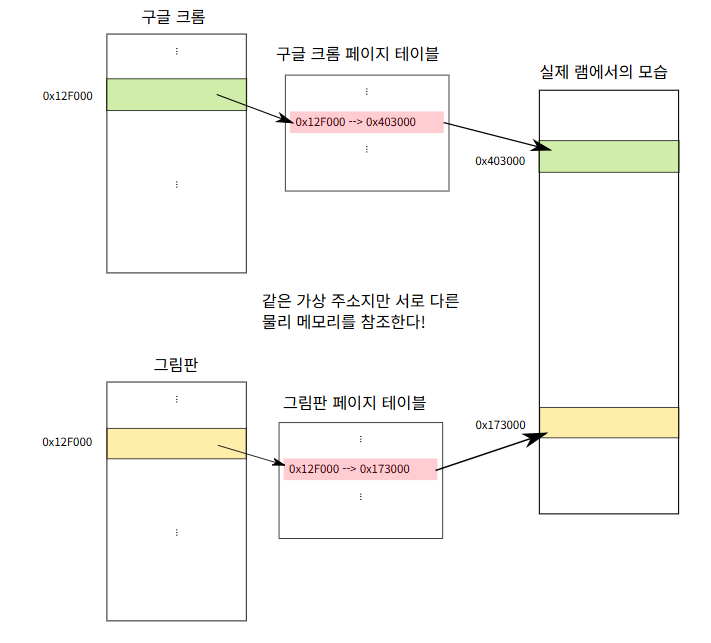
위 그림을 보면 페이지 테이블을 통해 각기 다른 메모리 주소로 할당되어 절대로 겹치지 않는 것을 확인 할 수 있다.
페이징 덕분에 각 프로그램들은 마치 자기 혼자서 메모리 전 공간을 사용하는 것 마냥 생각할 수 있다. 이전 가상화를 공부할 때 페이징에 대한 개념을 몰랐었을때는 무슨 말인지 이해가 안갔는데, 위 개념을 익히고 나니 해당 내용이 이해가 간다.
위와같은 메모리 가상화 덕분에 메모리에 같이 올라가 있는 다른 프로그램들을 전혀 고려 할 필요없이 프로그램을 개발하는 사람들 입장에선 매우 편리하게 프로그램을 작성할 수 있게 되었다고 합니다.
