Back Propagation
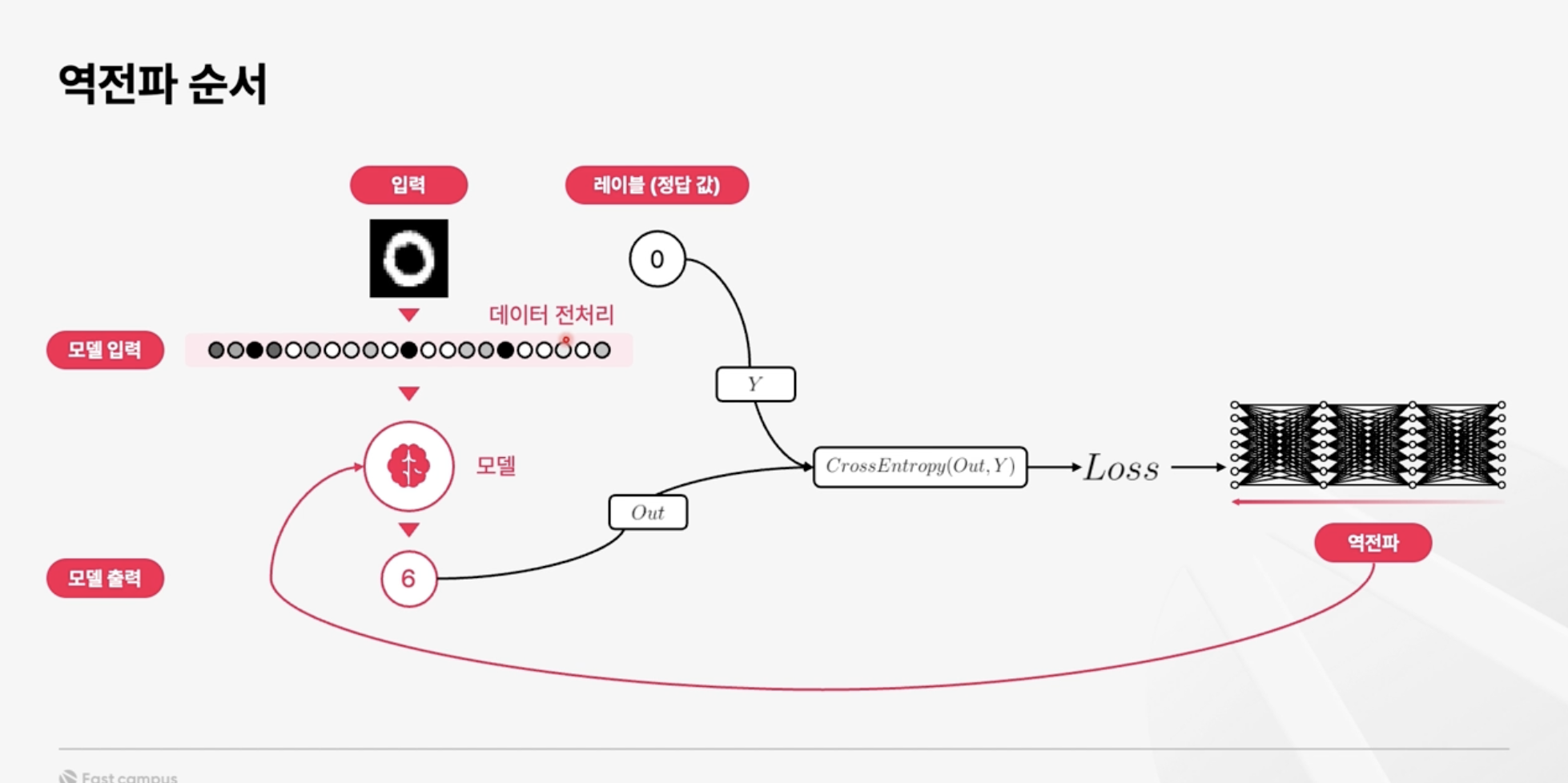
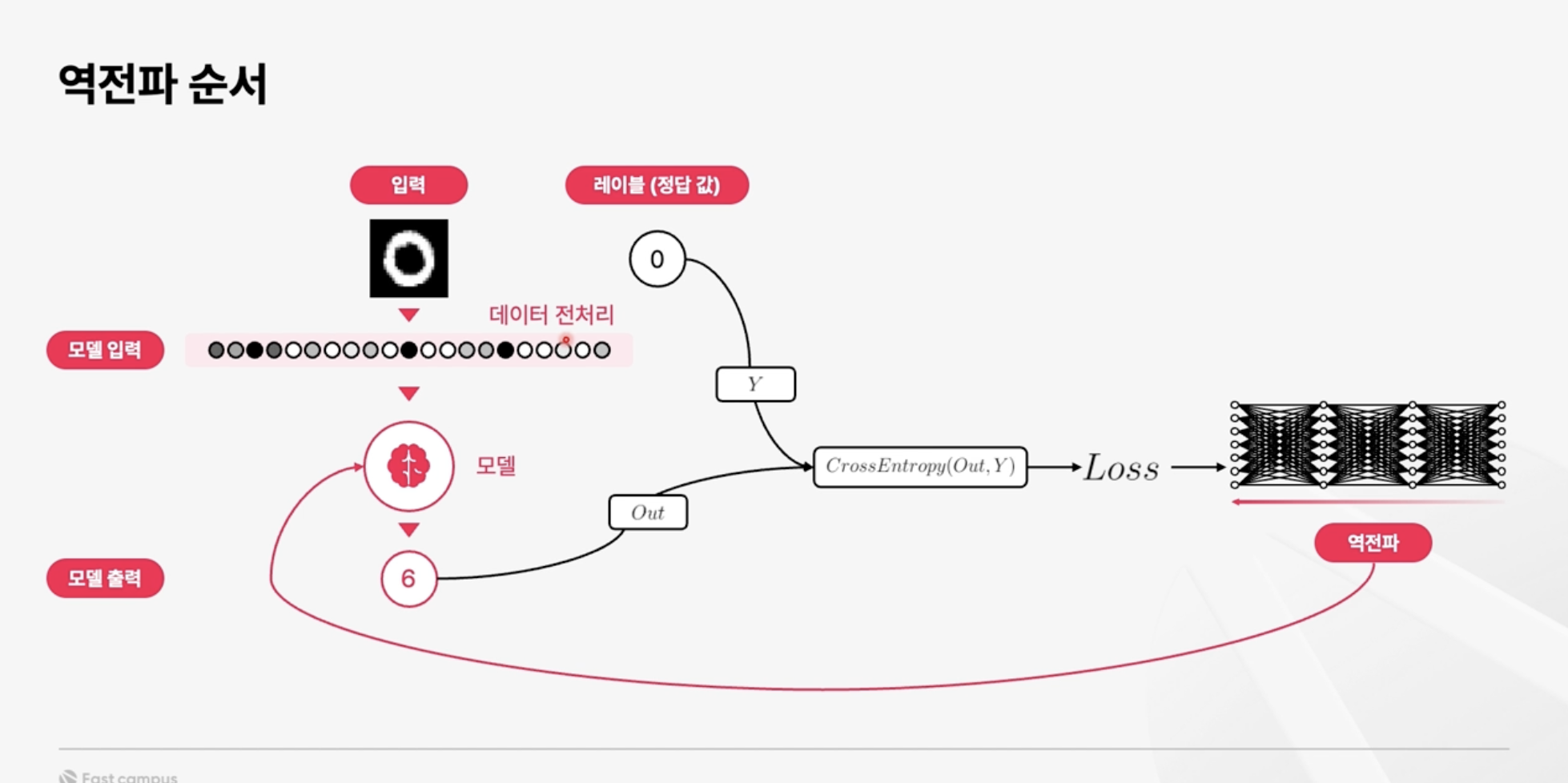
MNIST를 통한 AI model의 학습 과정을 알아봤었고, 그중에서도 지난 번에는 feed-forward 과정을 보았었다. MNIST 손글씨 이미지는 Feed-forward 과정을 거치며 숫자에 대한 예측 값을 output으로 도출해낸다. 그러나 여기서는 가중치와 편향 값을 계산에 활용만 했을 뿐이고 숫자를 알아맞히기에는 모델의 능력이 턱없이 부족한 상태일 것이다. 우리는 이러한 가중치와 편향들의 업데이트가 필요하고 이것의 핵심이 되는 것이 바로 오늘 알아볼 역전파(back propagation)이다.
먼저 loss에 대해 알아보자. Loss는 feed forward의 결과값과, 주어진 정답의 차이라고 할 수 있다. 이 차이, 즉 오차를 계산하는 방법은 함수로도 표현하여 loss function 이라고도 한다. 쉽게 말해 모델이 얼마나 잘못 예측했는지를 수치로 구하는 것이고, 모델은 이 값을 최소화 하는 방식으로 가중치와 편향을 조절해 간다. 우리는 이 과정을 '모델이 학습한다'고 표현하는 것이고, 그 원리에 역전파가 중요한 역할을 한다고 정리할 수 있겠다.
그렇다면 역전파는 어떤 원리로 가중치와 편향을 조정하는 것인지 알아보자. 방금 언급했던 loss를 각 layer, 각 뉴런마다 거슬러 올라간다고 생각해보는 것이다. 궁극적으로 우리는 loss가 작아지는 방향으로 모델에 사용되는 값들을 조정해나가야 한다. 각 뉴런을 거치는 과정을 함수라고 한다면, output까지 도달한 연산은 여러 개의 합성함수로 표현할 수 있을 것이다. 결론부터 말하면 역전파는 이러한 합성함수의 도함수를 구하는 과정이라고 할 수 있다. 합성함수의 도함수를 구함으로써, 각각의 뉴런들에서 발생하는 변화량이 어떤 방식으로 output에 영향을 미치는지 알 수 있다.
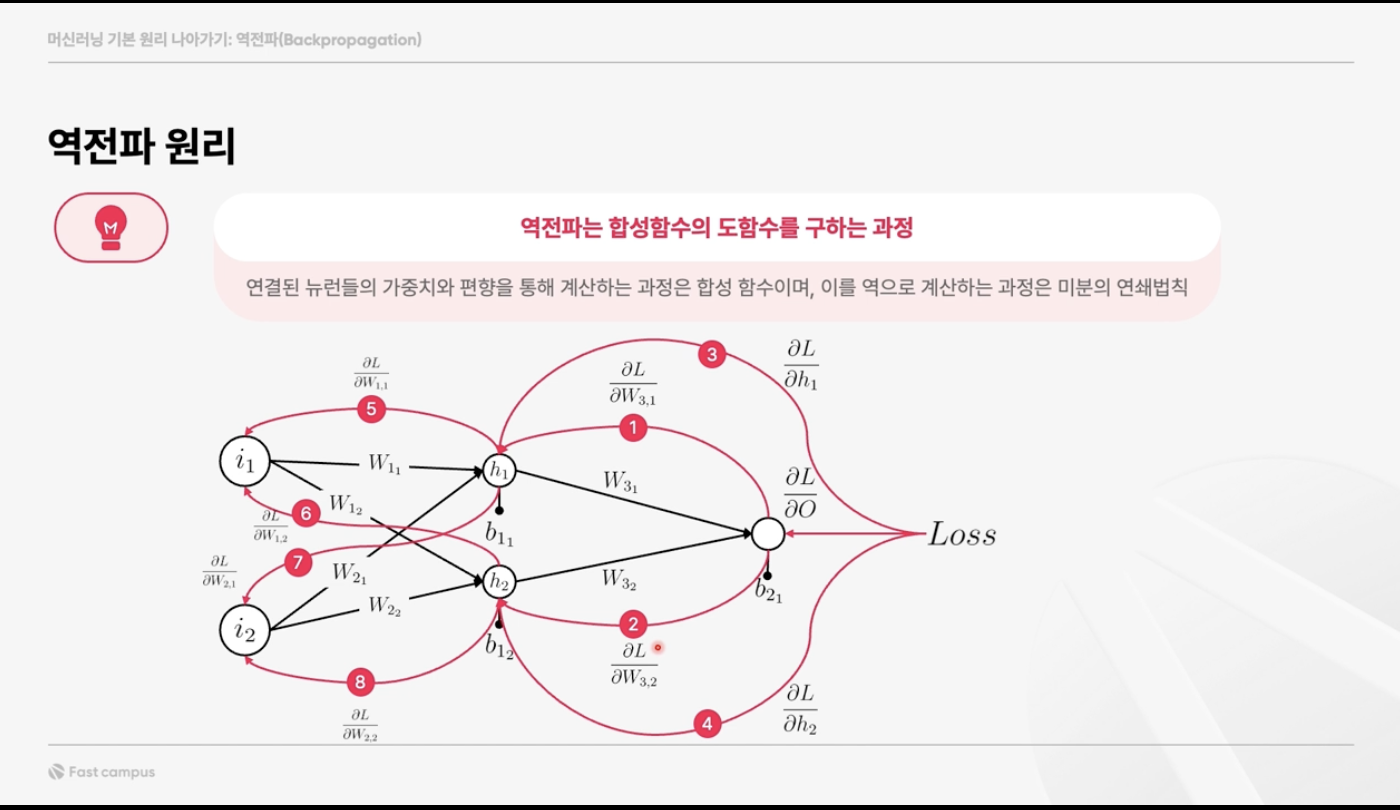
예를 들어 을 보자. 이는 손실 에 대해 가중치 값 이 어떻게 변화하는지를 나타낸 것으로 gradient라고 한다. 즉 gradient는 역전파의 과정을 밟으며 각각의 뉴런을 거칠 때, 어떠한 방향으로, 얼마만큼의 변화가 필요한지 알려주는 것이다. 이 편미분 값들은 손실이 감소하는 방향으로 가중치를 조정하는 데 사용되고, 가중치의 업데이트는 일반적으로 학습률(learning rate)과 이 편미분 값들을 곱한 값에 의해 결정된다. 각 반복마다, 가중치와 편향은 점차적으로 조정되어, 네트워크의 예측이 실제 값에 더 가까워지도록 한다.
