
📌 t가설검정의 핵심 흐름
상황
- 신약 개발 후 효과를 알아보려고 함
흐름
1️⃣ 데이터 준비
- 두 집단의 평균, 표본 수(nA, nB), 표준편차 확인
2️⃣ 가설 설정
- H₀: 신약의 효과 없음
- H₁: 신약의 효과 있음(나의 가설)
3️⃣ 데이터 확인
- 약을 먹은 사람과 안먹은 사람의 데이터 비교(평균, 표본 수, 표준편차 등)
4️⃣ 계산(평균의 차이를 흔들림으로 나누기)
- t = 분자: 두 그룹의 평균차 / 분모: 표본평균의 표준오차(SE)
💡 쉽게 이해하기
분자 → 신약의 효과 / 분모 → 불확실성- 약의 효과가 불확실성보다 크다 → 약의 효과가 있다 → p가 낮아짐
- 약의 효과보다 불확실성이 크다 → 효과보다 우연이 더 크다 → p가 높아짐
5️⃣ 분포 위에 올려보기
- H₀ 세계에서 t값이 얼마나 드문지 확인
6️⃣ 결과 판단
- p < 0.05 → H₀ 기각 → “효과 있을 수 있다”(단, 100% 아님)
- p ≥ 0.05 → H₀ 기각 불가 → 신약에 효과가 없다고 단정할 증거가 부족함
7️⃣ 제한점 기록
- 표본 수 부족 → 데이터가 적으면 결과가 흔들려 신뢰하기 어려움
- 가정 위배 → t검정은 기본적으로 “정규분포”와 “분산이 비슷하다”는 조건을 가정 (깨지면 결과가 왜곡될 수 있음)
- 다중검정 → 여러 번 검정을 반복하면, 우연히 p < 0.05가 나올 확률이 커짐
- 탐색 vs 확증
- 탐색적 분석(EDA): 데이터 보고 가설을 세운 경우 → 결과는 참고용
- 확증적 분석: 미리 가설을 세우고 검정한 경우 → 더 신뢰할 수 있음
💡 SE(표준오차)의 역할
같은 결과라도 SE(불확실성에 따라 차이가 달리짐)A팀 → 80점, B팀 → 78점
- SE큼(점수 들쭉날쭉) → 우연에 의한 차이일 수 있음 → 많이 흔들리기때문에 차이가 자주 발생
- SE작음(점수 안정적) → 겨우 2점차이지만 의미가 있음 → 흔들림이 적기에 약간의 차이에도 민감
📌 t가설 검정의 특징
정의
- 모집단의 σ를 모르기 때문에, 표본의 표준편차와 n으로 SE를 구해 비교하는 방법
특징
- 표본이 많을수록 흔들림이 작아지고, 작은 차이도 뚜렷해짐 → p값이 낮아짐
- 표본이 적을수록 흔들림이 커지고, 같은 차이도 우연처럼 느껴짐 → p값이 커짐
- 그룹간 평균 차이가 크면 t값이 커지고, p값이 작아짐
- 그룹간 평균 차이가 작으면 t값이 작아지고 p값이 커짐
- 즉, 흔들림에 비해 결과의 차이가 클 때만 유의하다할 수 있음
주의
- 귀무가설을 기각했을 때 대립가설이 맞다는 것을 증명한 것이 아닌, 귀무가설을 버릴 근거를 확보했을 뿐임
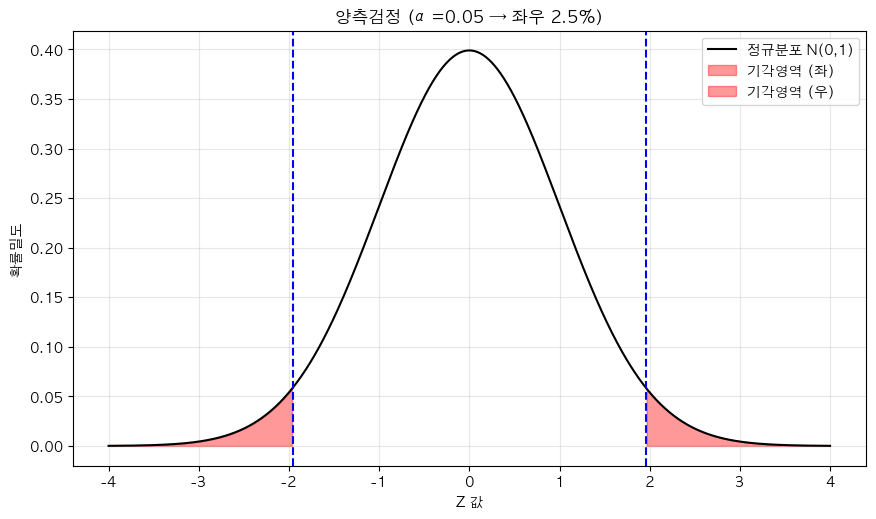
📌 양측검정과 단측검정
양측검정
정의
- 두 그룹의 평균에 차이가 '있다'는 것을 검정하는 방법
특징
- 가장 일반적이고 기본적인 검정 방식
- 효과가 양수든 음수든 양쪽 방향 모두 고려
- 예: 신약이 혈압에 영향을 주는데, 올릴 수도 / 내릴 수도 있음 → 두 방향 다 확인
- 즉, 차이가 크든 작든 방향과 상관없이 차이가 있는지만 확인
- 양쪽 꼬리 영역(좌·우 극단값)을 합쳐서 유의수준 5%로 설정
- 좌·우 꼬리 합쳐서 5% 영역을 기각 기준으로 삼음
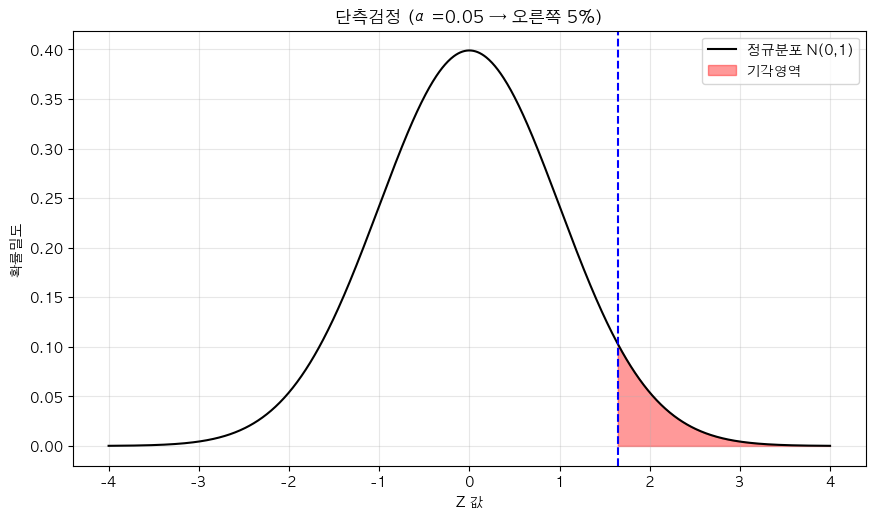
단측검정
정의
- 효과가 특정한 한쪽 방향으로만 존재한다고 가정하는 검정 방법
특징
- 한쪽 꼬리(극단값)만 고려
- 예: 신약은 혈압을 낮추기만 한다(높일 가능성은 배제)
- 하지만 잘못 가정하면 큰 오류를 일으킬 수 있음
- 예: 사실은 혈압을 높일 수도 있는데 배제해버림
- 검정력이 더 커져서, 같은 표본이어도 차이를 더 잘 잡아낼 수 있음
- 연구 설계 단계에서 단측검정을 쓸 명확한 이유가 있어야 함
- 남용을 조심해야 하며, 대부분의 연구에서는 양측검정을 기본으로 사용
📌 신뢰구간과 가설검정
신뢰구간 관점(지도)
- 표본으로부터 모집단 차이가 포함될 범위를 추정
- 예: 우리 집이 어디쯤 있는지 영역을 표시
가설검정 관점(gps)
- 귀무가설의 세계에서 실제 데이터의 표본 차이가 얼마나 드문가?(p값)
- 예: 만약 집이 특정 좌표에 있다면, 지금 내가 있는 곳이 얼마나 벗어나 있는지 p값을 통해 알려줌
💡 신뢰구간 vs 가설검정
같은 계산을 다른 시각에서 본 것
- 신뢰구간: "차이의 범위를 직접 보여줌"
- 가설검정: "우연일 확률 계산"
예시
-
a/b테스트
- 신뢰구간: 전환율 차이 1%p ~ 3%p, (구간 내 0포함 안됨 → 차이 있음)
- 검정: p = 0.012 < a(0.05) → 귀무가설 기각
-
임상시험
- 신뢰구간: 혈압 감소 효과 5~12mmHg(구간 내 0포함 안됨 → 차이 있음)
- 검정: p = 0.004 < a(0.05) → 귀무가설 기각
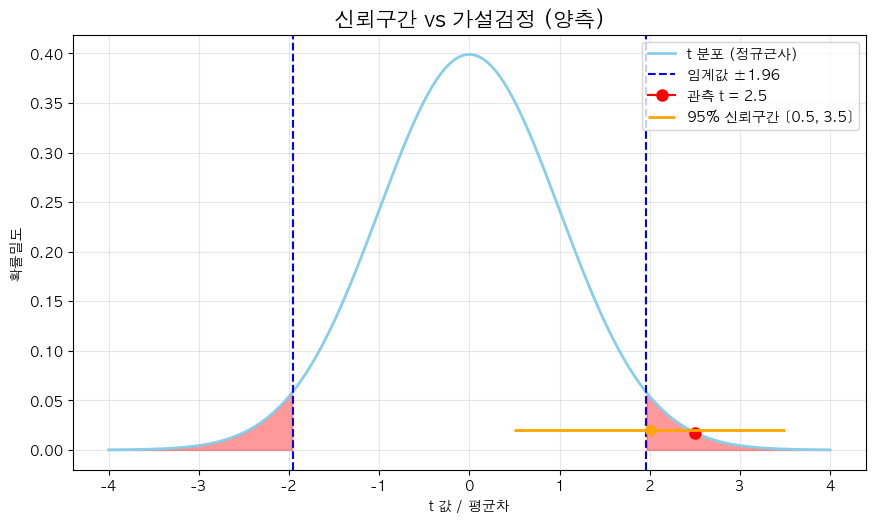
1️⃣ 신뢰구간 관점
- 주황색 막대: 95% 신뢰구간(CI) = [0.5, 3.5]
- 해석:
- “모집단 평균 차이가 이 구간 어딘가에 있을 확률이 95%”
- 구간 내에 0(차이가 없음)이 포함되지 않음
- 즉, “차이가 없다”는 말은 95% 기준에서 불가능
- 따라서 차이가 있을 수도 있다고 판단
2️⃣ 가설검정 관점
- 빨간색 점: t값 = 2.5
- 해석:
- p값이 임계값을 넘어섬(p < a)
- 귀무가설이 맞다면 이런 t값이 나올 확률은 매우 작음
- 따라서 H₀ 기각 → 차이가 있다고 판단
📌 용어
검정력: 실제로 효과가 있을 때 H₀을 기각할 확률(진짜 효과를 잡아낼 힘)
효과크기: 단순히 “차이가 있다”가 아니라 그 차이가 얼마나 큰지(유의해도 결과의 차이가 너무 작으면 실무적 의미가 없음)
