
📌 대표값
- 방대한 데이터의 특징을 대표하는 주요 값
- 어떤 대표값을 사용할지에 따라 결론이 완전히 달라짐
- 보고서 작성 시 대표값 세 개를 모두 제시해야 함
- 평균, 중앙값, 최빈값이 모두 같을 때 이상치 데이터가 들어오면 평균만 영향을 받음
🔹 평균(mean)
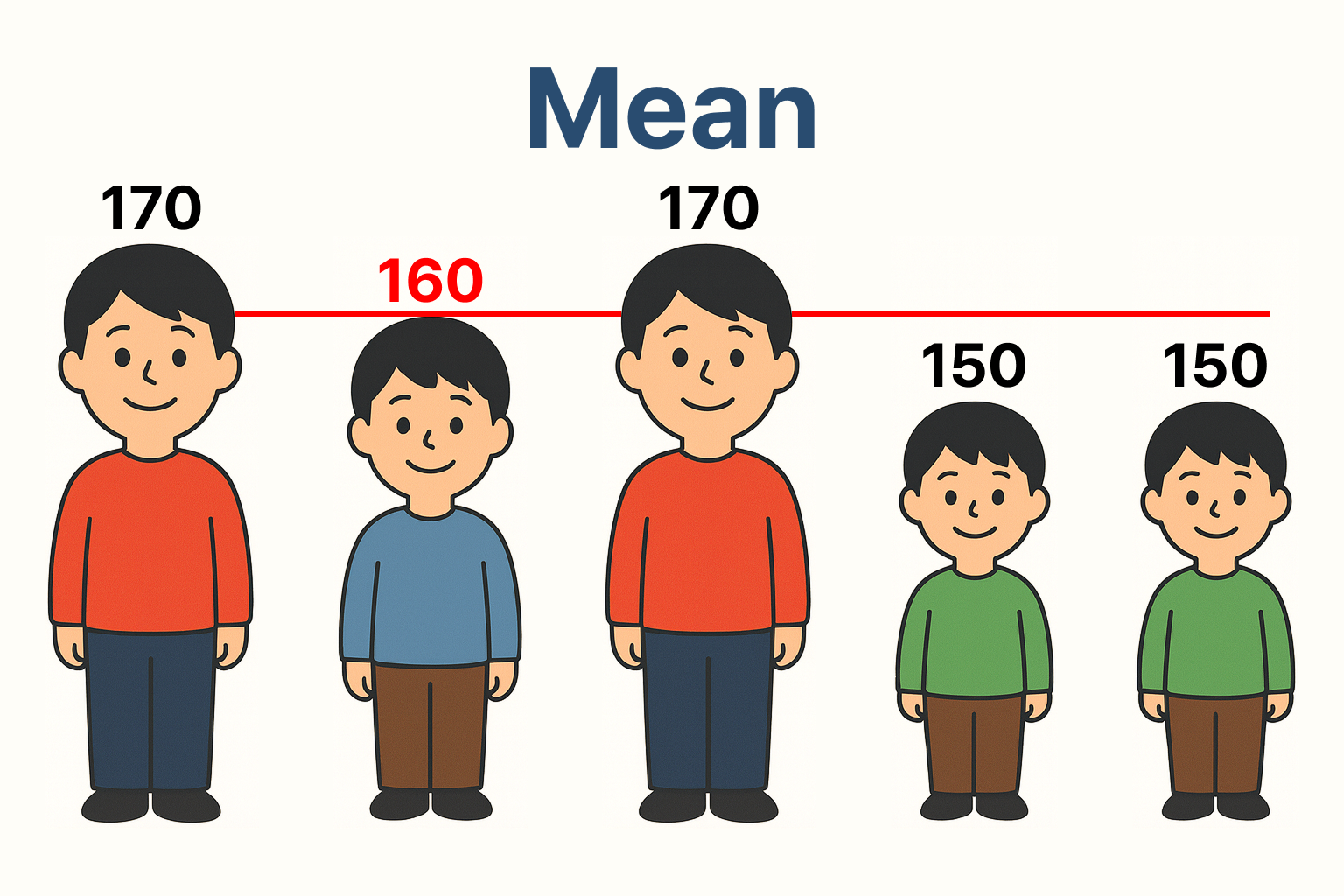
정의
- 데이터의 전체 합을 데이터 개수로 나눈 값
특징
- 데이터의 일반적인 경향을 잘 보여줌
- 이상치에 크게 영향을 받음
- 이상치가 없을 경우: 시험 점수 [10, 10, 10, 10, 10] 평균 = 10
- 이상치가 있을 경우: 시험 점수 [10, 10, 10, 10, 100] 평균 = 28
예시
- 우리 구의 평균 음식 배달 시간은 20분으로 매우 빠름
- 다른 동네는 5분 이내에 배달이 완료되는 반면,
- 우리 동네는 155분이 걸림
🔹 중앙값(median)

정의
- 데이터를 크기 순으로 정렬했을 때 중간에 위치한 값
특징
- 데이터 개수가 짝수면 중간에 있는 두 값의 평균을 중앙값으로 함
- 이상치에 영향을 거의 받지 않음
예시
- 아파트 가격의 평균 = 12억, 중앙값 = 9억
- 대부분 9억대이지만 일부 매우 비싼 매물로 인해 평균 값이 증가함
🔹 최빈값(mode)
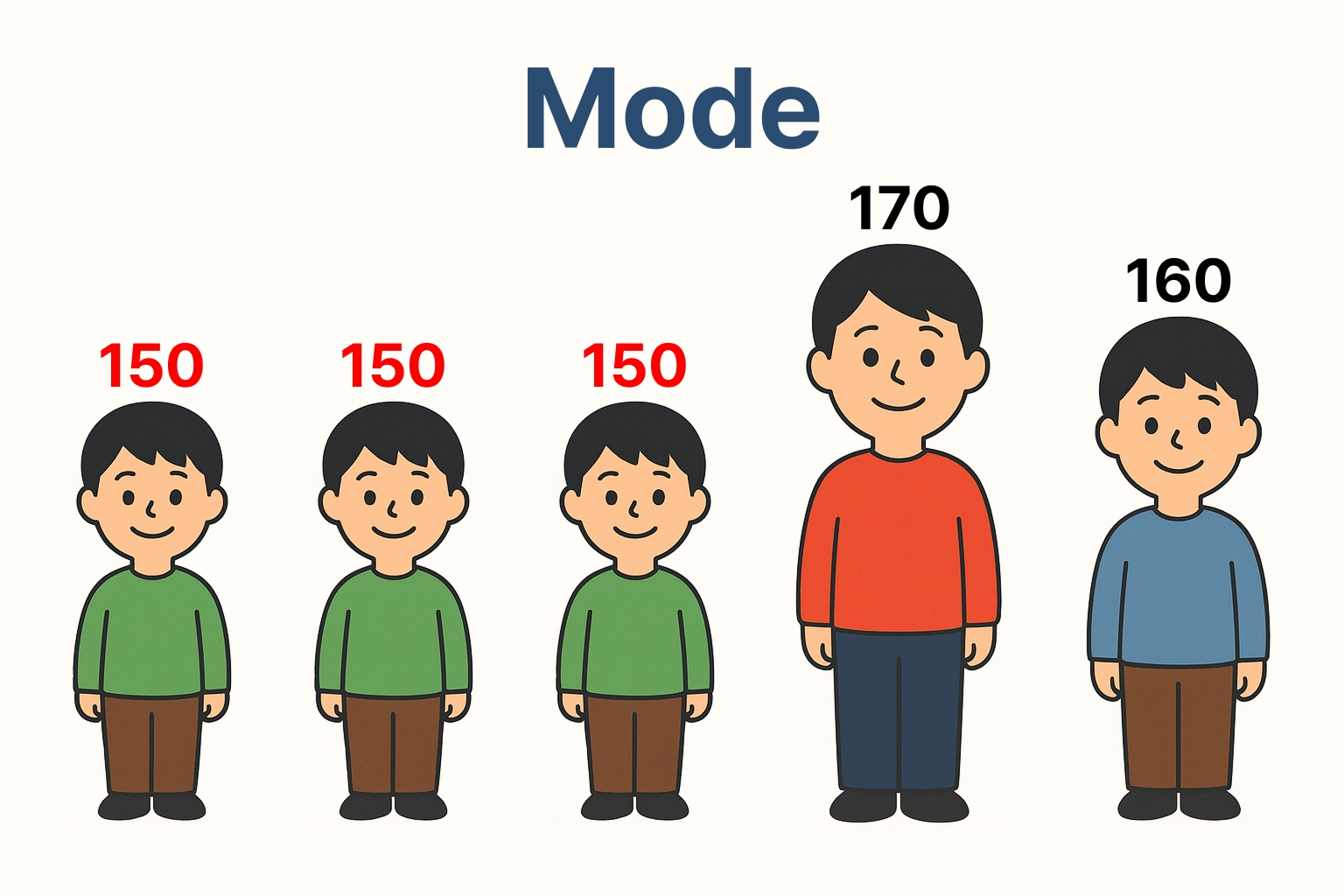
정의
- 데이터 내에 가장 자주 등장한 값
특징
- 범주형 데이터에서 중요한 정보 중 하나
- 사람들의 실제 행동/선호도를 파악할 수 있음
- 소비자 선호 분석에 매우 유용
예시
- 쇼핑몰 결제 데이터: 평균 = 30만 원, 중앙값 = 5만 원, 최빈값 = 9,900원
- VIP 관리 → 평균(중심)
- 가격대별 프로모션 → 중앙값(일반적인 수준)
- 일반 고객 전략 → 최빈값(실제 선택과 행동 반영)
📌 편차 → 분산 → 표준편차
💡 왜 필요한가?
평균만 보면 데이터의 흩어짐을 알 수 없음
- 반 A: [70, 72, 75, 78, 80] → 평균 75
- 반 B: [30, 50, 75, 95, 100] → 평균 75
➡️ 평균은 같지만 점수 분포에 엄청난 차이가 있음
🔸 편차(deviation)
정의
- 데이터 값들이 평균에서 얼마나 떨어져 있는지 나타내는 값
특징
-
데이터가 평균보다 크면 +, 평균보다 작으면 -
- [20, 15, 17, 22, 21] → 평균 19
- 편차 = [+1, -4, -2, +3, +2]
- 모든 편차의 합 = 0
💡 편차의 합이 0인 이유?
평균은 데이터들의 무게중심(균형점)으로
- 평균보다 작은 값들이 만든 음수(-) 편차와
- 평균보다 큰 값들이 만든 양수(+) 편차가
서로 완벽히 상쇄됨
🚨 따라서 편차만으로는 흩어짐을 측정할 수 없음(편차를 합치면 0이되어 흩어짐이 사라져버림)
🔸 분산(variance)
정의
- 편차의 한계를 극복하기 위해 모든 편차를 제곱하여 평균을 낸 값
특징
- 데이터의 흩어짐 정도를 수치로 표현
- 값이 클수록 데이터가 평균으로부터 멀리 퍼져 있음
- 분산이 작다: A반의 점수가 평균 근처에 모여있다! → 반 친구들의 실력이 비슷
- 분산이 크다: A반의 점수가 제멋대로다! → 반 친구들의 실력이 매우 다양
- 직관성이 떨어짐(데이터가 평균에서 ±125 정도 떨어져 있음)
- 시험 점수 [70, 80, 90, 100] 평균 = 85, 분산 = 125
계산
-
(편차: 각 데이터 - 평균)²의 합 / 데이터의 개수
💡 편차를 제곱하는 이유
-
편차의 음수값을 양수로 바꾸기 위해
-
절대값 대신 제곱을 쓰는 이유 → 이상치에 큰 벌칙을 주기 위해
평균에서 멀리 떨어진 값일수록 차이가 더 커짐(추후 머신러닝에서 사용)
- 작은 실수 → 매우 가볍게 혼남
- 큰 실수 → 매우 크게 혼남(제곱 효과: 혼나지 않기 위해 주의함)
-
🔸 표준편차(standard deviation)
정의
- 분산의 제곱근으로, 데이터의 흩어짐을 데이터 단위 그대로 표현
💡 분산에 루트를 씌우는 이유
제곱으로 인해 뻥튀기된 단위를 다시 돌려놓기 위해
특징
- 데이터가 평균에서 얼마나 떨어져 있는지를 직관적으로 알 수 있음
- 직관성이 좋음(데이터가 평균에서 ±11 정도 떨어져 있음)
- 시험 점수 [70, 80, 90, 100] 평균 = 85, 분산 = 125, 표준편차 = 11.18
- 값이 클수록 데이터가 평균으로부터 넓게 퍼져 있음
- 표준편차 = σ (시그마) 라고도 부름
계산
- 분산 값의 제곱근
표준편차 = √분산
분산 = (표준편차)²
예시
- 공장 A, B의 불량률 확인
- 공장 A: 평균 = 10cm, σ ≈ 0.1cm → 안정적
- 공장 B: 평균 = 10cm, σ ≈ 1.5cm → 불량률이 많음
보고서 작성 시
- 잘못된 예: "고객 평균 결제액은 30만 원이다."
- 잘된 예: "평균 결제액이 30만원이지만 표준편차가 22만 원으로 변동성이 크다. 일반 고객은 5만 원대 결제가 많고, 소수의 VIP가 평균을 끌어올리고 있다."

📌 데이터 변환과 표준편차
데이터 전처리/EDA 단계에서 착시를 피하기 위해 알아두면 좋음
🔹 위치이동
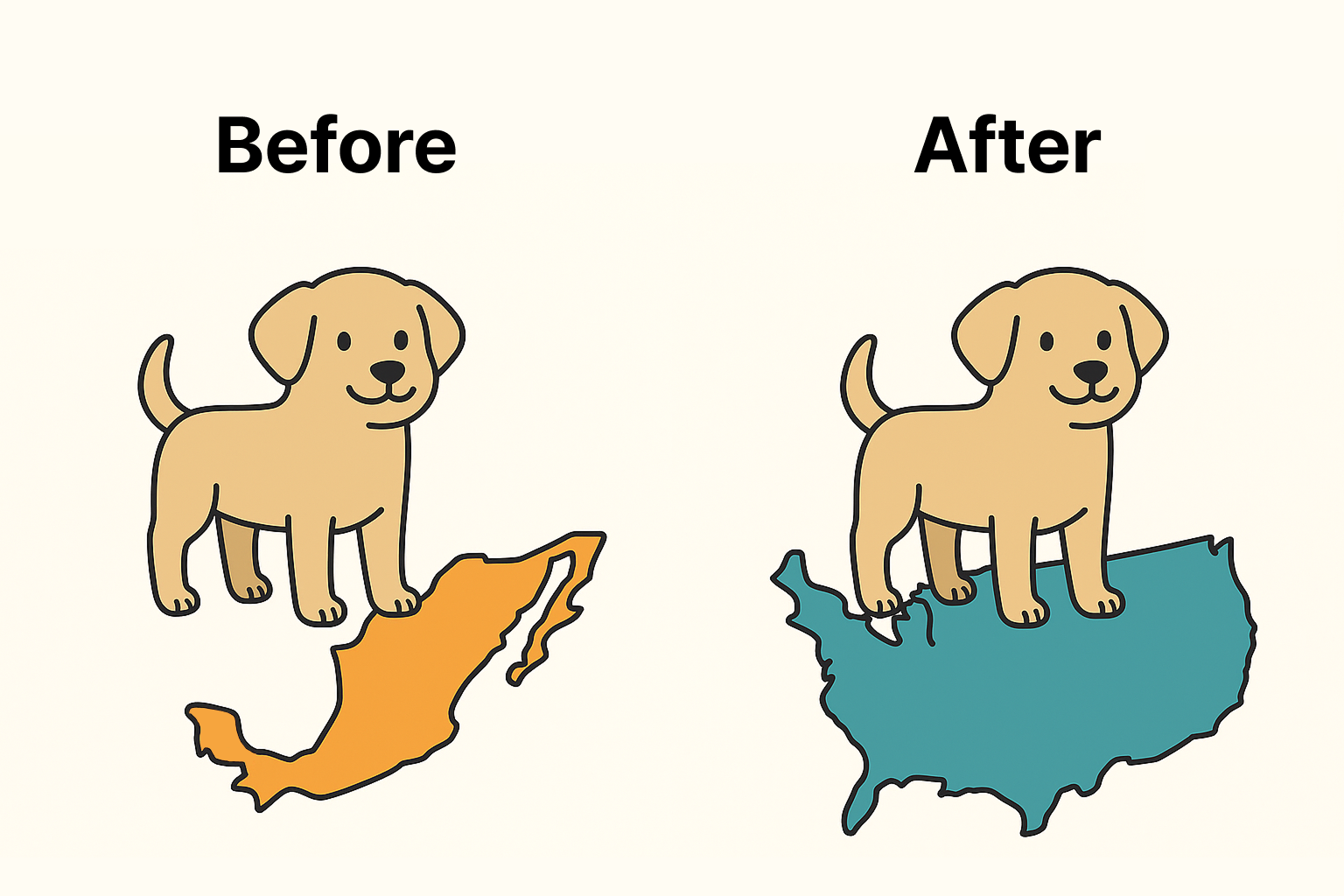
+a: 평균만 이동, σ는 그대로
원래 데이터 모두에 임의의 값을 더하거나 뺌
-
기존 데이터 [2, 4, 6] 평균 = 4, σ ≈ 1.63
-
10을 더함 [12, 14, 16] 평균 = 14, σ ≈ 1.63
값의 위치만 달라질 뿐, 평균과 표준편차는 변하지 않음💡 위치이동을 하는 이유
- 민생 지원금 받았을 때
- 모든 국민 소득에 15만원씩 더함
- 민생 지원금 받았을 때
🔹 스케일 변화
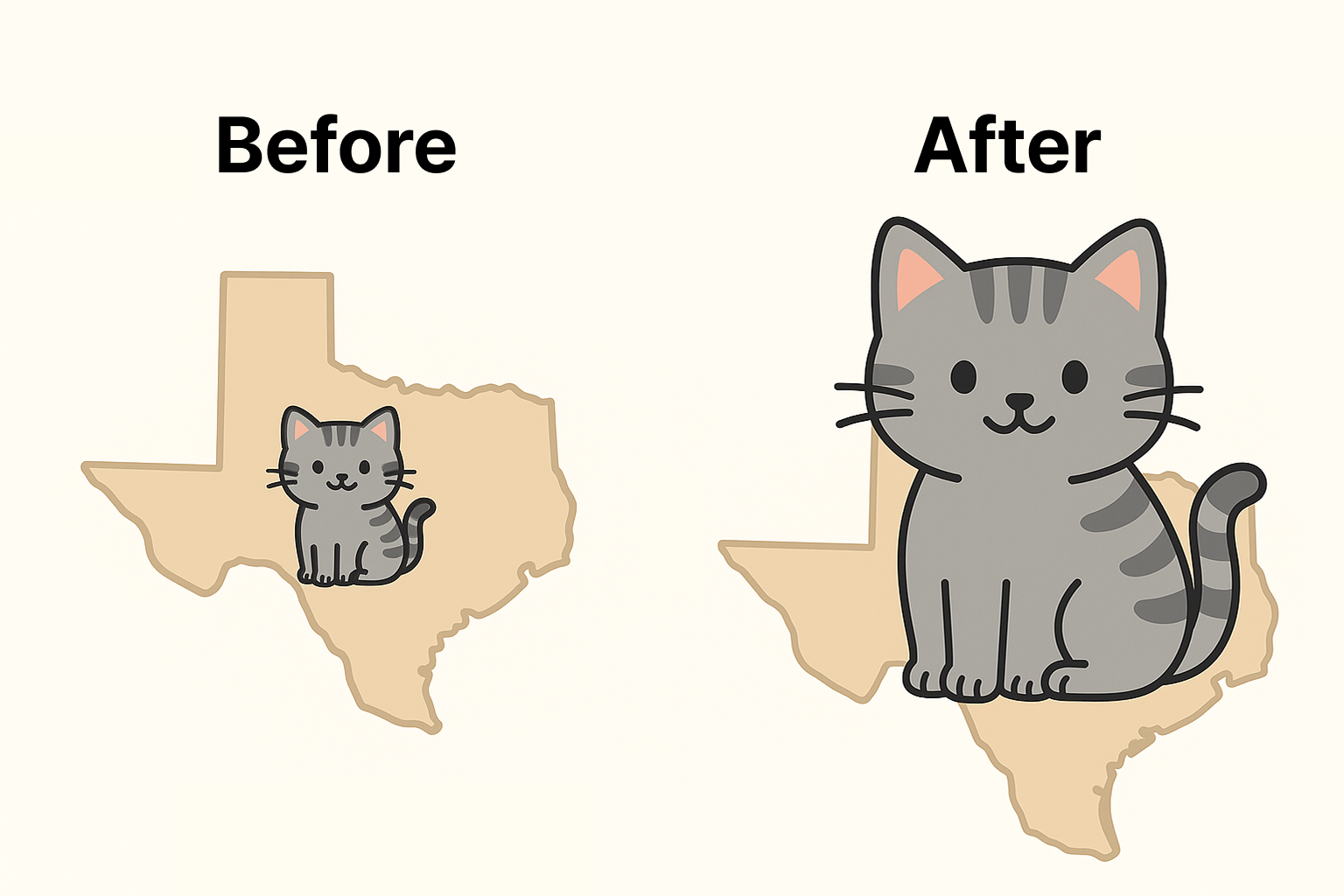
xk: 평균과 σ모두 up 또는 down
원래 데이터 모두에 임의의 값을 곱하거나 나눔
-
기존 데이터 [2, 4, 6] 평균 = 4, σ ≈ 1.63
-
2를 곱함 [4, 8, 12] 평균 = 8, σ ≈ 3.27
평균과 표준편차 모두 2배씩 확대됨💡 스케일 변화를 하는 이유
- 서로 다른 기준을 통일하고자 할 때 사용
- 학교별 시험 점수 단위 통일 (100점 만점 vs 160점 만점)
- 키와 몸무게 단위 통일 (cm vs kg)
- 서로 다른 기준을 통일하고자 할 때 사용
📌 퀴즈
화면을 드래그해서 정답 확인
대표값 (o vs x)
🐷 몸무게
지인들의 10명의 평균 몸무게가 50kg일때, 대한민국 국민의 평균 몸무게도 50kg일까?
→ 정답: x
💸 연봉
A사의 평균 연봉이 1억일때, 곧 입사할 내 연봉도 1억 근처일까?
→ 정답: x
💳 제품
애플 매장에서 1인 평균 결제 금액이 500만 원일때, 500만 원짜리 프로모션을 기획 해야할까?
→ 정답: x
