Algorithm
1.백준 3003

수학구현사칙연산또 다른 방식각 체스말에 정해진 값을 배열에 넣고 for문으로 입력받고 출력하기주의사항1\. for 문 내에서 iterator를 바로 초기화 하면 for문 내에서 선언하면서 iterator가 제대로 적용이 안되어 에러가 발생할 수 있다.2\. 컴파일 시
2.baekjoon 10250
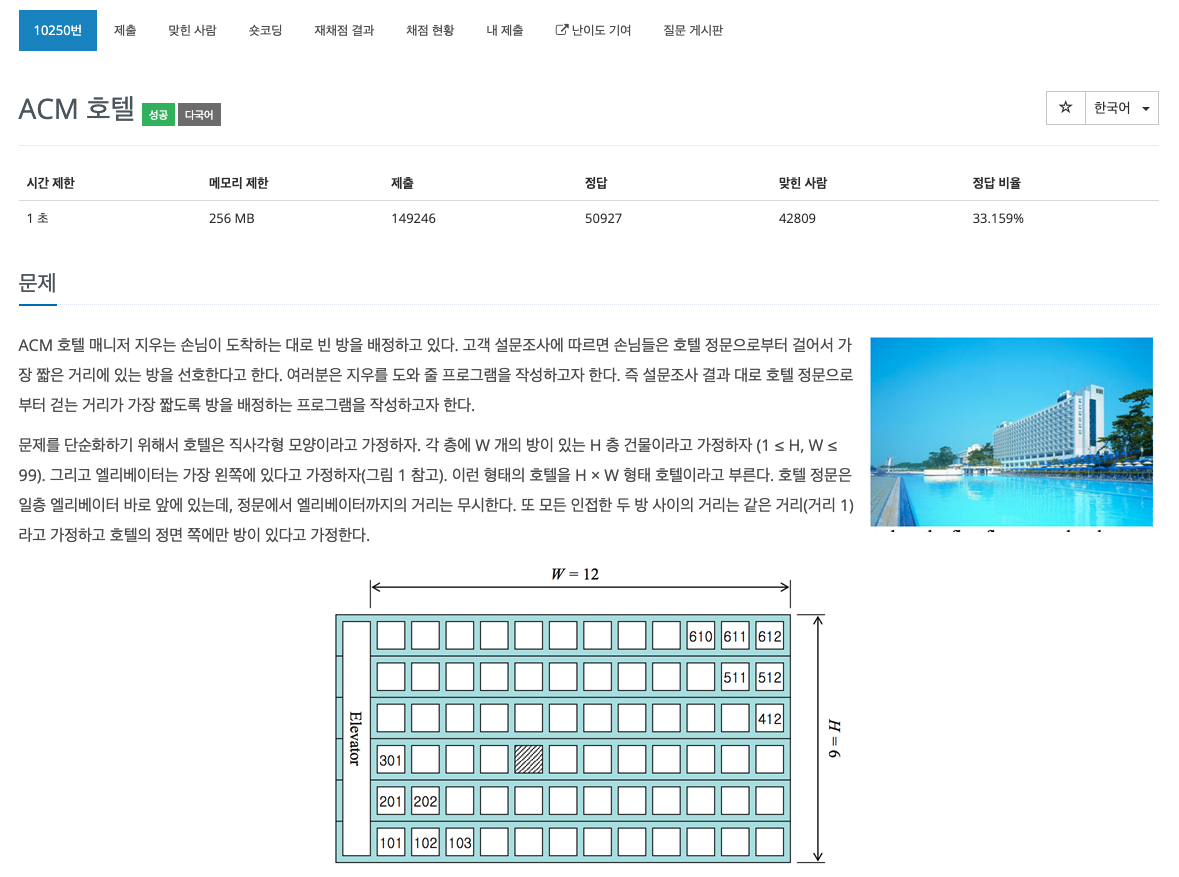
내가 작성한 코드고민한 사항방 호수의 앞 번호와 뒷번호의 관계를 생각했다.\-> 엘리베이터와 가까운 호수번호를 요구하므로 n번째를 높이로 나눈 나머지 값이 해당 호수번호의 앞 번호가 될것이다. 하지만 나머지가 딱 떨어지는 경우는 n의 소인수분해에 h가 포함되는 경우이므
3.baekjoon 2869
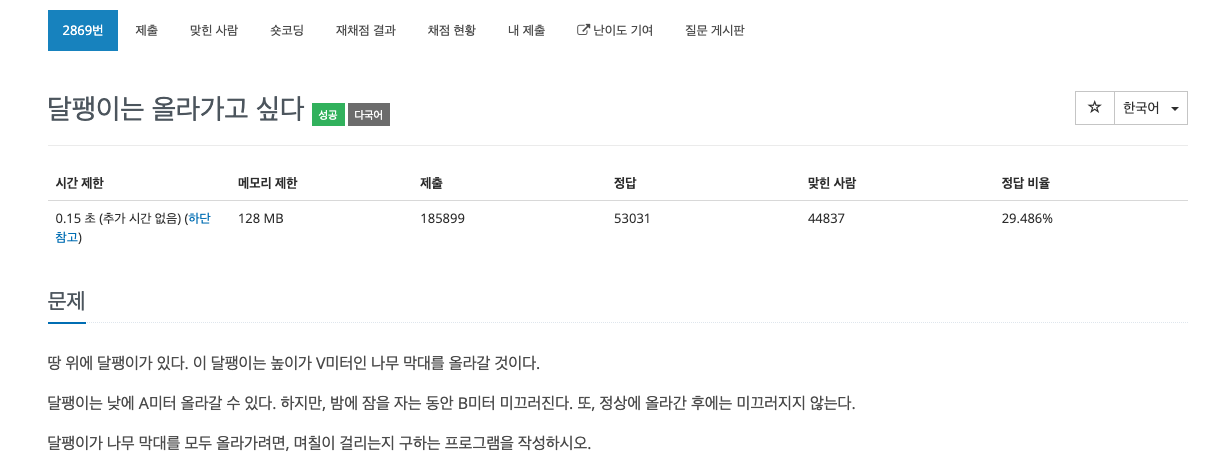
내가 작성한 코드a - b를 통해서 하루에 올라가는 최종 높이를 구할 수 있으나 정상에 올라가면 내려오지 않기 때문에 마지막 날은 내려가는 계산을 하면 안된다.i = v / up로 최대 일수를 구하고 i -= b / up과 같은 방식으로 불필요한 일 수를 제거하고자 하
4.baekjoon 1193
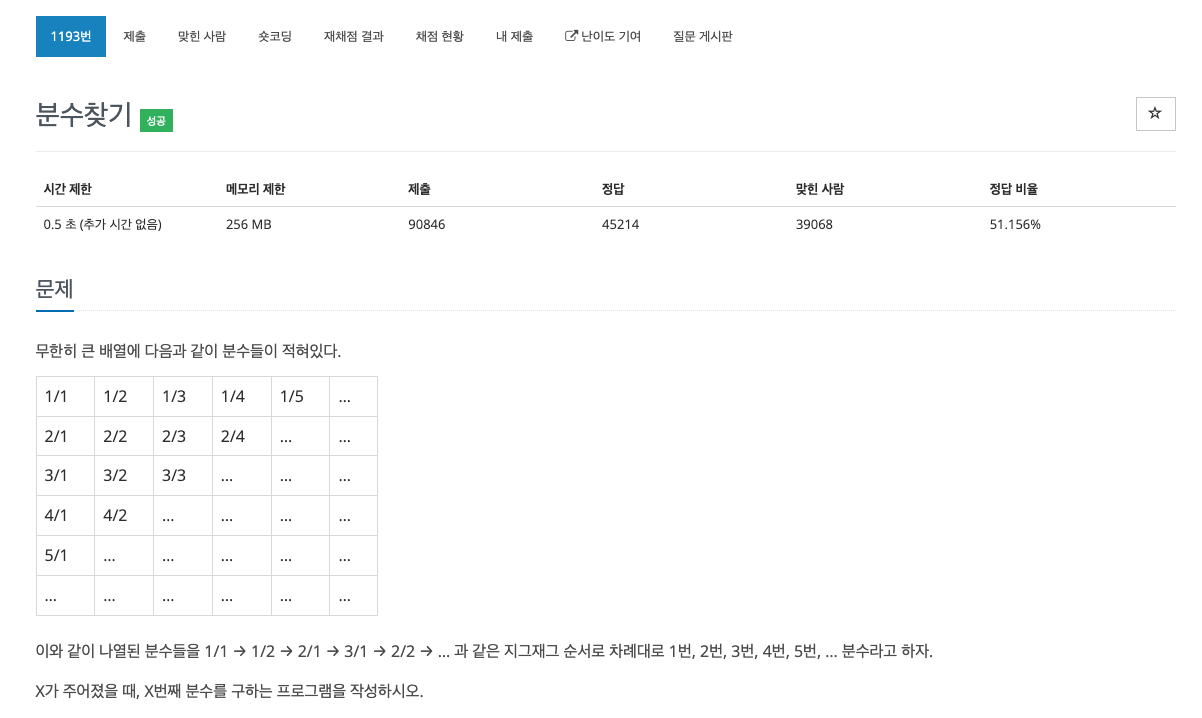
내가 작성한 코드 (cpp)증가하는 방식에 대해서 규칙을 찾고자 하였다.1\. 홀수라인은 오른쪽으로 올라가고 짝수라인은 왼쪽으로 내려간다.2\. 분모와 분자는 2차배열의 index이다.3\. 한줄 씩 증가할 때 한줄의 개수는 1씩 증가한다.코드 길이 감축 539B ->
5.baekjoon 2292
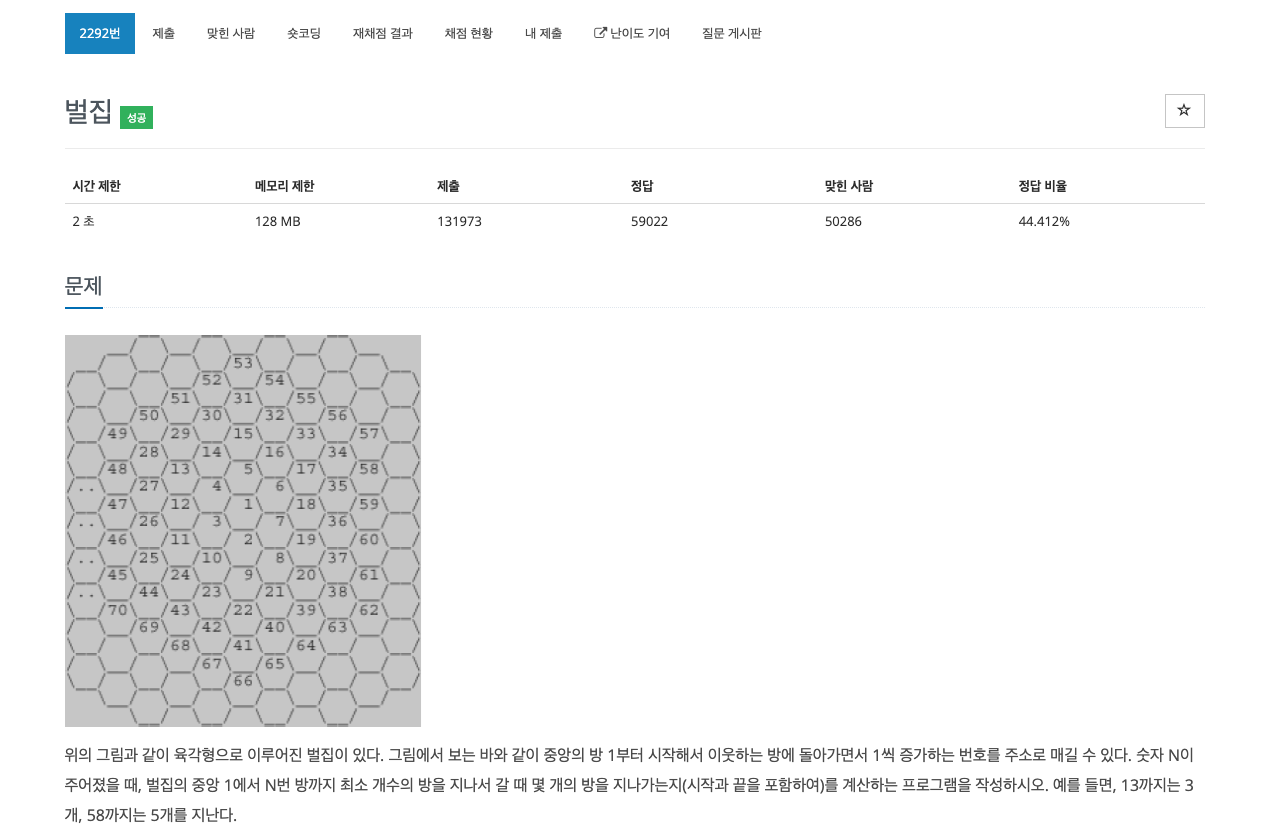
내가 작성한 코드한줄이 증가하는 규칙을 찾아야한다.\-> 한줄이 증가할 때 벌집의 칸은 (i \* 6)씩 증가한다for문의 idx를 바로 줄수로 사용하려하니 1칸일 때 증감식이 적용되지 않아 예외 처리해주었다.
6.baekjoon 1712
내가 작성한 코드A + (B 물건 판 개수) < (C 물건 판 개수)로 하여 반복문을 돌려보려 하였다. 하지만, 불필요한 연산들이라는것을 깨닫고, 물건을 판 순수이익 (C -B)로 초기 투자금 A를 넘어서는 기준으로 계산하였다.
7.baekjoon 2941
내가 작성한 코드고민한 부분1\. 변경할 문자열을 세는 것 말고 a, e같은 문자는 어떻게 셀까\-> c, d, z, l ,n으로 나누어 순차적 if 문을 걸어주는 것\-> 치환할 문자열들을 찾아 길이가 1인 문자로 치환하는 것2\. 치환할 문자열이 두개 이상 중복해서
8.baekjoon 5622
내가 작성한 코드다이얼 7번에 4개의 문자가 할당되어 있어 3으로 나누어 몫을 기준으로 해당 문자의 값을 정하는 방식에 문제가 생겼다.위의 예외사항으로 인하여 7, 8, 9에 맨 마지막 글자들인 S, V, Y, Z의 다이얼 숫자로의 치환이 잘 이루어지지 않았고, 예외
9.baekjoon 2908

내가 작성한 코드reverse함수를 사용해야 하는가stoi로 변환을 해야하는가a, b를 반대로 바꾸고 int로 변환하여 max 함수를 사용하여 값을 출력했으나, 주어지는 글자가 3자리수이고 0이 없으므로 받은 string의 index 2부터 askii code값을 비교
10.baekjoon 1152
내가 작성한 코드입력받은 개수를 출력해야 하는 문제여서 표준입력 cin으로 입력을 받게되면 공백기준으로 끊어 받기때문에 getline()으로 EOF까지 받아주었다.getline()으로 입력받은 문자열의 앞 뒤의 공백을 제거하여 구현할 수 있었지만, stringsream
11.baekjoon 1157
내가 작성한 코드배열 26칸을 만들어 각 배열마다 문자의 개수를 저장하여 비교하려고 하였으나, 문자열에서 개수를 찾고, 배열내의 가장 높은 숫자를 갖는 인덱스를 찾는것이 비 효율적이라 판단되었다.받은 문자열을 sort하여 가장 많이 갖고 있는 문자를 순차적으로 찾으려고
12.Baekjoon 11720
내가 작성한 코드아쉬운점alli - '0'처럼 문자열 0에대한 ascii code 값을 빼주어 숫자로 변환하는 방식이 아닌 stoi 함수를 사용하여 작성하지 못한 점이다.그 이유는 이러한 에러가 발생하였기 때문인데 string 자체의 변수는 stoi로 변환이 가능하였지
13.Baekjoon 11654
내가 작성한 코드static_cast 형변환 방식을 사용하여 기본 자료형간의 형변환을 가능하게 해주었다.그냥 int(x) 처럼 int 형으로 형변환을 시켜줄 수 있지만,예를 들어 (int\*)&d; 처럼 논리적으로 주소값을 int형으로 받았을 때 이 주소 값을 수정하
14.Baekjoon 25304
내가 작성한 코드pair<int, int> type으로 vector를 만들어 make_pair를 통해서 vector에 넣어 first \* second의 합을 구하려고 했으나 불필요한 선언이라 판단되어 for문 내부에서 바로 합을 구하여 해결하였습니다.
15.Baekjoon 2480. 주사위 세개

입력받으면서 max를 확보해두고자 하였다.3 6 3 처럼 같은 숫자 입력의 보장이 되지 않기때문에 정렬하여 순서를 보장하려고 했다.checkSame이라는 함수를 통해서 중복된 수의 개수와 어떤 수가 중복되는지 확인하였고 받은 값을 토대로 출력문을 작성하였다.숫자가 3개
16.baekjoon 2675
내가 작성한 코드
17.baekjoon 10809
내가 작성한 코드find()함수는 인자값의 index값을 반환해주고 찾고자 한 인자가 해당 string에 없다면 string::npos를 반환한다.
18.baekjoon 2775

내가 작성한 코드원하는 값의 수식은 원하는 층 - 1의 인원과 원하는 호수 - 1의 인원의 합과 같다.이를 위해 연속된 for문을 돌려서 2차 배열을 초기화 하고 해당 인덱스를 참조하는 방식을 고민했다. 하지만, 재귀를 사용하는 것이 조금더 재밌을 거같아 재귀로 구성하
19.[프로그래머스]제곱근 구하는 알고리즘
문제 설명 임의의 양의 정수 n에 대해, n이 어떤 양의 정수 x의 제곱인지 아닌지 판단하려 합니다. n이 양의 정수 x의 제곱이라면 x+1의 제곱을 리턴하고, n이 양의 정수 x의 제곱이 아니라면 -1을 리턴하는 함수를 완성하세요. 제한 사항 n은 1이상, 50000
20.[프로그래머스] 하샤드 수 구하기
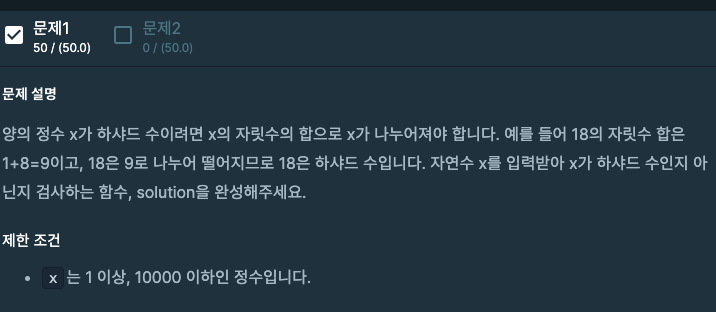
주어진 수의 각 자리수를 합한 수로 주어진 수를 나누었을 때 나누어 떨어지는 수를 의미한다.내가 작성한 코드
21.baekjoon 11659

당연하게도 주어진 수의 배열을 주어진 범위 내에서 순회하며 합연산을 하는것은 시간 초과로 나왔다.해결방법배열에 넣는 값을 DP(동적 프로그래밍)의 방법(작은 문제의 결과 값이 항상 같다는 점을 이용해 큰 문제를 해결하는 방식)으로 해결하고자 하였습니다.그리하여 배열에
22.baekjoon 2839

처음에 단순히 5로 나눈 나머지를 3으로 나누었을 때 떨어지는 경우를 생각했다.하지만, 4, 11, 17, 51 등 5의 개수와 3의 개수가 적절히 필요한 경우가 생겼다.해결방법받은 수 N을 5로 최대한 나누고 나누어지지 않을 때 3으로 나누어 떨어지는 경우를 구하기
23.baekjoon 10757
경 단위가 넘어가는 수를 더하기 위한 자료형이 없었다. 그래서 string을 더하는 로직을 구현하였다.string의 맨 뒷자리부터 수를 더하는 작업이 비효율적으로 느껴졌다.\-> 각 string의 size를 구하고 각 size가 끝나는 시점을 비교하며 각 자리를 더해주
24.baekjoon 1978
주어진 숫자를 2부터 순차적으로 나누어 나누어 떨어지는 수가 있는지 찾기1번의 방식으로 하되 2를 제외한 짝수를 배제하고 제곱근이 있는 수 배제하여 속도 올리기위의 두 방식을 고려했을 때 나중에 수가 커지는 경우에 해당 수가 소수라면 결국에 불필요한 연산을 너무나도 많
25.baekjoon 2581

소수를 구하는 방식은 이전에 작성한 소수 찾기의 방식으로 구현하였다.\-> List Comprehension을 사용하여 초기화 해주었다.\-> range의 3번째 매개변수를 사용하여 초기화 하는 간격을 정해주었다.value error가 발생하였다.발생 원인은 일반적으로
26.baekjoon 11653
2로 나누다가 안나눠져서 3으로 나누었을 때 다시 2로 나눠지는 경우가 있는가?\-> 처음엔 나눠 질수도 있을 거 같아 앞서 구현했던 소수 찾는 로직을 활용하여 구현하였으나 시간초과가 발생함..2로 나누지 못하는 경우에 다시 2로 나눠질 수 없다는 사실을 깨달았고 (약
27.baekjoon 1929
arr에 담긴 배열내에서 0이 아닌 값만 출력하려고 하였으나 궂이? 라는 생각이 들어 범위 내에 인덱스와 소수를 1 : 1 매칭시키는 list를 만들면서 바로 출력해주었다.기본수학 2는 지금까지 다 소수관련된 문제들만 나와서 멕이 좀 빠졌다 그래도 있는 문제를 다 풀고
28.baekjoon 9020
이 문제는 두개의 소수를 더하여 주어진 수가 되고, 그 두개의 수의 차이가 가장 적은 소수 2개를 구하는 것이었다. 그래서 기존에 여러 소수를 구하는 방식이 아닌 원하는 소수를 빠르게 찾을 필요가 있었다.이를 위해서 주어진 수를 2로 나누어 pibot을 정하고 pibo
29.baekjoon 2566
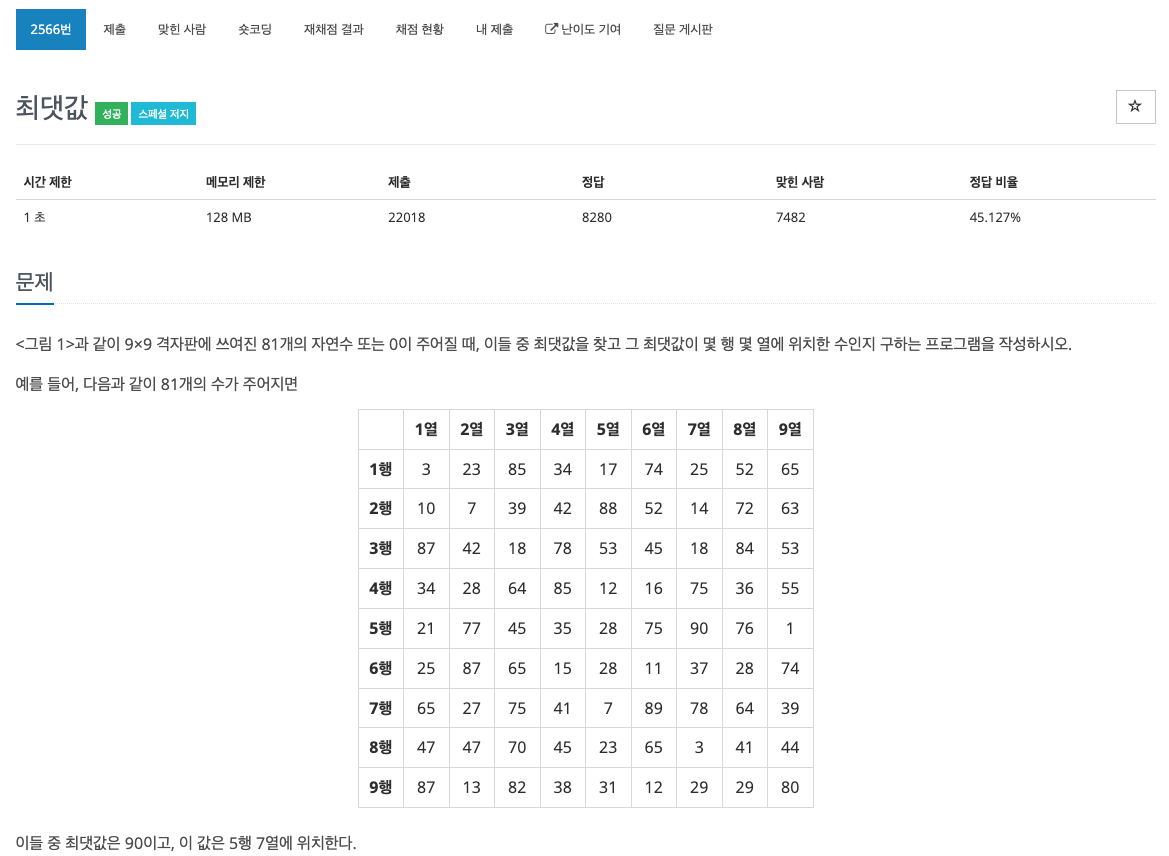
최댓값과, x, y는 하나의 정보를 가리키는 값으로 사용되는데 한번에 c의 구조체처럼 쓰고싶었다.기존에 파이썬은 구조체가 없고, 클래스 또한 데이터 타입을 지정할 수 없어 네임드 튜플을 사용했었다.하지만 파이썬 3.7부터 dataclass를 지원하여 @dataclass
30.baekjoon 2563

일단 밑에 적어둔 실패 코드를 기반으로 생각을 바꾸어 구현하였다.canvas = \[0 \* 100 for i in range(100)]\-> 0 \* 100이렇게 구현하게 되면 1차 배열 타입으로 0으로 초기화된 100크기의 1차 배열이 생성된다. list compr
31.baekjoon 2750
find()함수의 return 조건을 arr\[i] < num으로 하기위해선 맨 뒤에 값부터 비교했어야 했다.\-> 맨 앞에서 부터 비교하기 위해 조건을 바꾸어 주었다.일반적인 버블 정렬의 경우 배열 내에 앴는 값을 순차적으로 비교하며 정렬을 하지만, 이번 문제의
32.baekjoon 2587
이전에 작성한 백준 풀이중 정렬 코드를 차용하여 작성하였다.다른점은 정렬된 배열의 평균 값과 중앙 값을 구하는 것이 목표이다.들어오는 숫자의 개수는 5개 고정이었기 때문에 평균값을 자연수로 나타내기 위하여 //로 나누어주는 부분이 가장 신경써야한 요소였다.
33.baekjoon 25305
두번째 줄에 들어오는 숫자들을 바로 list로 받은뒤 정렬한다.k명이 상을 받기로 했으니 전체 인원수에서 k명을 빼며 나온 값을 인덱스로 사용하면 커트라인에 걸치는 학생의 점수를 구할 수 있다.앞서 두문제에서 삽입 정렬식으로 sort를 구현했었다.이번에는 python에
34.baekjoon 2751

시간 초과 : 2750번 백준 문제와 정말 유사하지만 시간 초과를 내지 않기 위한 방법이 필요했다.처음에는 앞서 풀었던 방식인 삽입 정렬 방식은 시간 초과를 해결할 수 없었다.퀵 정렬을 직접 구현하고 풀었어도 시간 초과의 벽에 부딪혔다.python 내장 함수인 sort
35.baekjoon 10989
전략 : 인덱스를 수로 생각하고 값에 해당 수가 몇번 들어왔는지 마킹용으로 사용하자!!직접 수를 정렬하여 메모리에 담은 것은 아니지만, 정렬된 것과 유사하게 사용할 수 있는 방식을 알게되어 즐겁다.메모리 초과로 실패하였다.. 그 이유로 생각한것이 sort를 할때 기본
36.[프로그래머스] 로또의 최고순위와 최저 순위
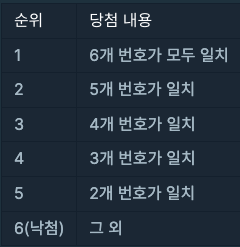
로또 6/45(이하 '로또'로 표기)는 1부터 45까지의 숫자 중 6개를 찍어서 맞히는 대표적인 복권입니다. 아래는 로또의 순위를 정하는 방식입니다.로또를 구매한 민우는 당첨 번호 발표일을 학수고대하고 있었습니다. 하지만, 민우의 동생이 로또에 낙서를 하여, 일부 번호
37.baekjoon 2108
최빈값을 구하기 위해 count를 사용했더니 2%에서 시간초과가 발생했다. count는 list의 전체를 훑기때문에 비효율적이다. 이미 sort를 통해 정렬을 하였으니 최빈값을 찾으려는 타겟의 값에대한 이전에 찾은 값 혹은 현재 값과 같지않은 값이 나오면 그 개수가 해
38.baekjoon 1427
python에서 string은 iterable한 객체이기 때문에 for문으로 list화 시켜주었다.sorted함수의 옵션인 reverse를 true로 주어 내림차순 정렬 후 list를 개행 없이 ''로 합쳐주었다.
39.baekjoon 11650
x좌표와 y좌표를 각각 배열에 받았더니 두개를 쌍으로 묶어 정렬하는 것이 어려웠고, dict로 받으려했으나 중복이 되지 않는 특성때문에 한 쌍의 좌표를 하나의 list에 담는것으로 해결했다.print했을 때 1, 2처럼 출력되어 인덱스로 출력을 해주었다.2차 배열을 s
40.baekjoon 11651
좌표 정렬하기 1과는 다르게 우선 정렬 기준 좌표가 Y좌표여서 sort의 정렬 순서를 바꾸어 주어야 했다.\-> list의 swap 기능을 사용하여 y, x좌표 index를 바꾸어 준뒤 출력또한 바뀐 인덱스에 맞게 출력해주었다.정렬 방법(https://docs
41.baekjoon 1181
정렬 우선 순위를 고려해야한다.1\. 길이가 짧은 것 부터2\. 길이가 같으면 사전 순3\. 동일한 단어는 한번만 출력중복을 허용하지 않기에 3번을 해결 할 수 있다.주어진 단어를 key로 두고 길이를 value로 두어 하나의 자료구조로 한번에 정렬이 가능하다처음에 객
42.baekjoon 10814
list에 pair 타입으로 넣어 들어온 순서를 지키되 원하는 값으로 정렬을 할 수 있도록 하였다.가장 최근의 결과가 틀린 이유는 이 부분의 age0으로 int형 변환을 해주지 않았기 때문이다.하지만 숫자가 문자열 타입이더라도 아래의 코드에서 확인되는 것 처럼 정렬이
43.[baekjoon] 18870
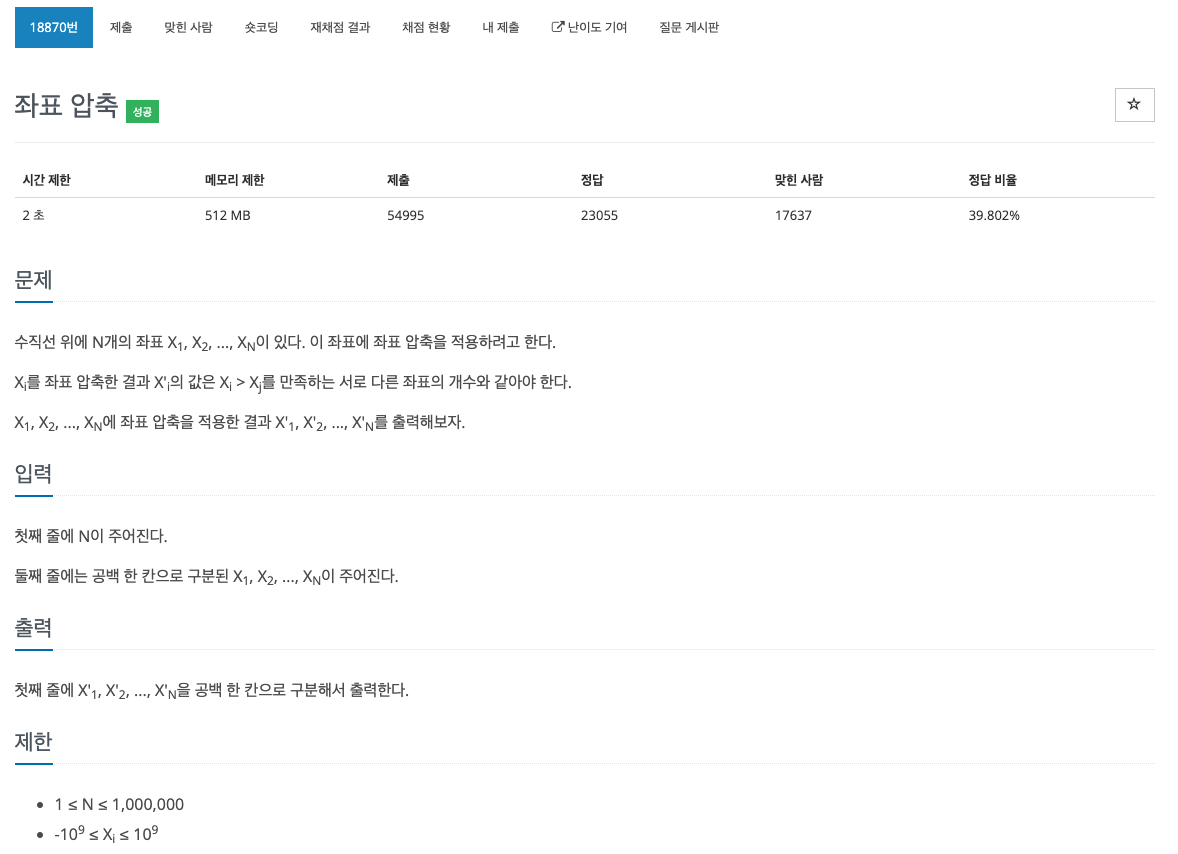
수를 정렬을 하고나서 그 수보다 작은 수들의 개수는 그 수의 인덱스라는 아이디어로 풀어보려 하였으나, 역시 index함수의 시간이 오래 잡아먹혀 시간초과가 발생했다.index함수의 수행 시간(N)을 1로 줄이기 위해 dictionary를 사용하여 arr 값을 키값으로
44.[baekjoon] 10872
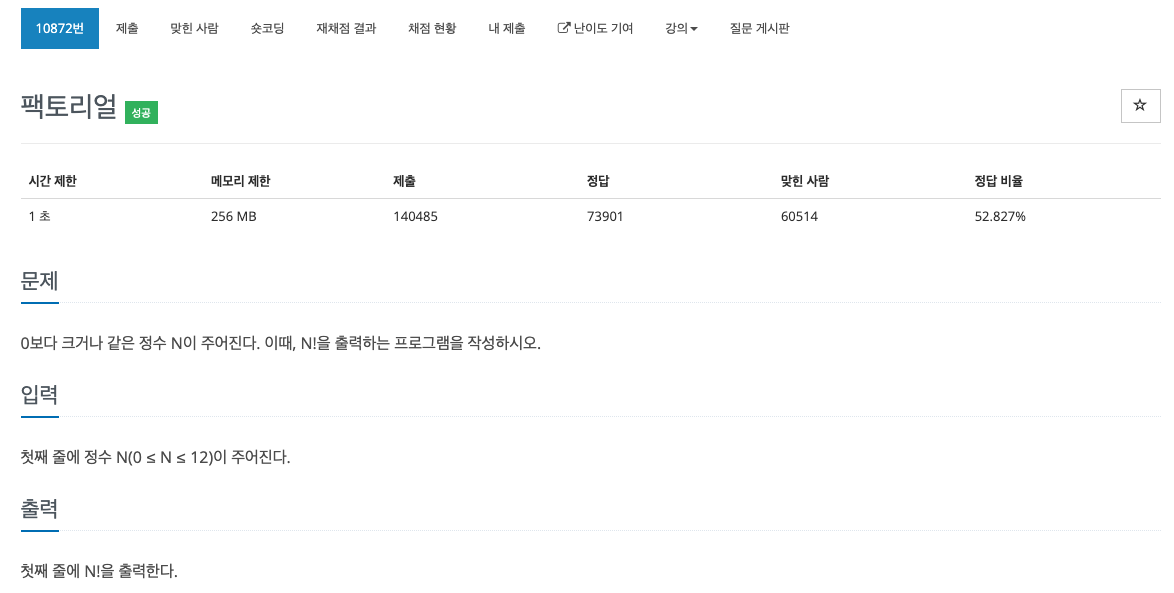
단계별로 풀어보기의 재귀파트 답게 팩토리얼 문제가 시작 문제로 나왔다.들어온 숫자가 1이라면 궂이 0을 곱해줄 필요가 없으므로 1을 리턴해준다.깔끔하게 통과했당 ㅎㅎ
45.[baekjoon] 25501
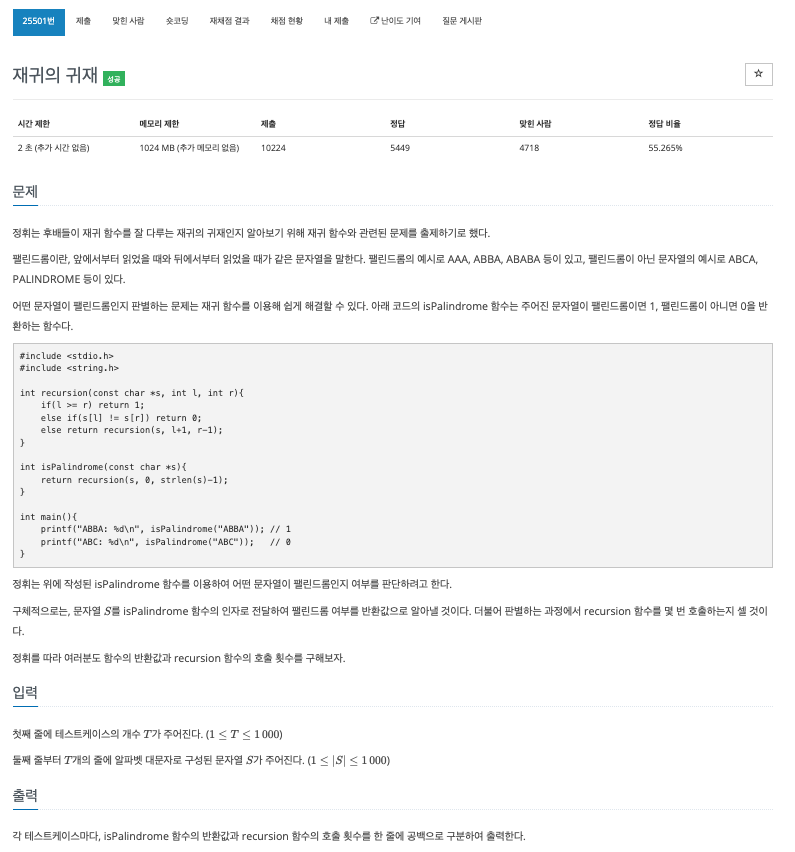
팰린드롬을 식별하기 위한 기본 return값을 제외하고 몇번 호출되었는지 식별 가능한 코드를 구현해야한다.call by reference타입의 변수를 두어 호출시마다 1 증가하도록하여 main문에서 식별 가능하도록 하였다.python은 call by assignment
46.[baekjoon] 24060
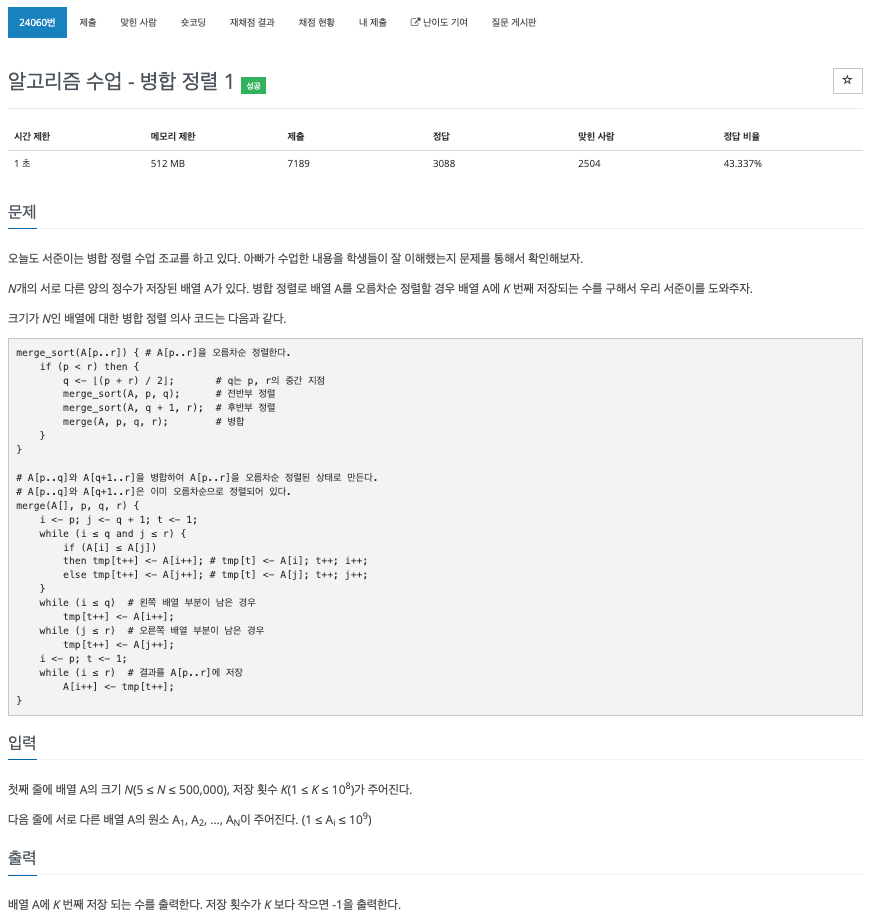
a배열에 정렬된 것으로 초기화 할 때 s의 인덱스를 더해주어 저장하는 위치를 잡아주어야 한다.홀수의 개수를 병합 정렬시 2 : 1로 쪼개어 하나의 값만을 갖는 부분은 정렬할 것이 없으므로 앞서 정렬된 배열과 비교하여 바로 정렬하면 된다.k번째 저장되는 수를 구하기위해
47.[baekjoon] 2447

N의 값이 무엇이던 앞서 나온 결과물을 바탕으로 반복되므로 for in 문으로 앞서 나온 패턴을 그대로 복사하여 필요한 개수만큼 곱하여 append해주어 새로 할당한다.즉, 오른쪽으로 3배증가 (p \* 3)아래 쪽으로 3배 증가 (for문이 3개)2차 배열을 선언하여
48.[baekjoon] 11729

처음에 스택 3개를 만들어 top의 값을 비교하며 위의 것이 아래의 것보다 작아야 한다는 조건을 만족시키려고 하였다. 스택의 맨 아래에 사용하지 않는 칸 하나를 두어 1,2,3의 베이스 판을 구분할 수 있는 값으로 초기화 하려고 하였다. 하나의 스택을 만들어 옮길때마다
49.[baekjoon] 2231

문제 출처단계별 풀어보기의 브루트 포스 부분이다. 브루트 포스란brute: 무식한, force: 힘 무식한 힘으로 해석할 수 있다. 즉, 완전탐색 알고리즘을 의미한다.하나의 함수를 활용하여 완전탐색을 하고자 하였다.가장 낮은 생성자를 구하는 문제이므로 1부터 N까지 증
50.[baekjoon] 7568

문제 사이트본인보다 큰 사람의 수 + 1이 본인의 등수입니다.완전탐색 알고리즘으로 본인을 전체 list의 요소들과 모두 탐색 비교하는 로직으로 구현하고자 하였습니다.중복 저장 가능한 list와 여러개의 값을 비교하기 위한 tuple을 사용하여 값을 저장하고 비교하였습니
51.[baekjoon] 1018

문제 출처완전탐색을 할수록 똑같은 범위의 체스판을 검사해야하기때문에 규칙성이 있는 부분은 검사를 하지 않는방법을 생각했었다. 하지만 이 방법은 시작 타일의 색과 바뀌는 인덱스에 따라 식별하기 어려웠고, 불규칙한 입력의 균일하지않은 규칙의 타일을 기록하는 것이 비효율적이
52.[baekjoon] 1436

문제 출처처음에 N번째의 수를 찾기위해 for i in range(N)의 i를 기준으로 666을 필요한 부분에 붙여가며 구하려고 하였다.i가 1이면 1666, 6이면 6660으로 i의 1의자리가 6이면 N번을 찾는 i에 + 10 66으로 2개면 i에 + 100번을 해주
53.[프로그래머스] PCCP 모의고사 1 - 1번

알파벳 소문자로만 이루어진 어떤 문자열에서, 2회 이상 나타난 알파벳이 2개 이상의 부분으로 나뉘어 있으면 외톨이 알파벳이라고 정의합니다.a는 2회 이상 나타나지만, 하나의 덩어리로 뭉쳐있으므로 외톨이 알파벳이 아닙니다. b, c도 a와 같은 이유로 외톨이 알파벳이 아
54.[baekjoon] 10815

문제 출처처음엔 두개의 list를 사용하여 단순히 if a in b로 구현하였으나 시간초과 발생\-> 문제해결위해서 dict의 key를 사용하여 조회하기로 하였고, 성공할 수 있었다.이분탐색을 사용하여 푼 케이스도 있었다.start, mid, end로 두어 찾고자 하는