자바애플리케이션 vs 다른애플리케이션
- 자바애플리케이션은 아래서부터 순서대로 하드웨어,os,JVM,java애플리케이션의 순서인 반면 보통은 하드웨어,os,애플리케이션으로 쌓어져있다.
- 자바애플리케이션은 JVM이 설치되어있는 곳에서만 실행가능하다
- java 애플리케이션이 os에 바로붙어있지 않기때문에 자바애플리케이션은 os에 종속적이지 않다.
하지만 jvm은 os에 바로 붙어있기때문에 os에 종속적이다. - 단점) 하드웨어에 맞게 완전히 컴파일된 상태가 아니라 실행시에 해석돼서 속도가 느리다
- 자바에서 모든 코드는 클래스안에 정의되어야한다.
- 하나의
.java파일안에 여러 클래스를 정의할 순 있지만 소스파일의 이름은 반드시 public class의 이름과 일치해야한다. 만약 public class가 없다면 있는 class들중 아무거나로 해도 된다
실행과정
.java라는 소스파일을 자바컴파일러로 컴파일하면바이트코드를 얻어낸다. 그리고 바이트코드를java.exe즉, 인터프리터로 해석하고 실행시킨다
변수
값을 저장할수있는 메모리상의 공간
선언과 초기화
선언: 변수타입만큼의 저장공간이 확보되고, 변수이름을 통해 이 공간을 사용할 수 있게 된다
초기화: 사용하기전에 값을 초기화하는것
자료형
- 자료형은 기본형(소문자로시작하는타입)과 참조형(대문자로시작하거나 내가 만든class)으로 나눌수있다.
상수
- 한번 값을 넣으면 변경할 수 없는 수
- 앞에 final을 붙인다
리터럴
- 'A', "안녕하세요" 와같은 문자/숫자 등의 상수를 의미함
- 상수는 리터럴에 의미있는 이름을 붙인것임
상수가 필요한 이유
- 20대신에 20이 무엇인지를 의미하는 상수를 선언한다면 더 의미가 명확해질것이다
타입의 불일치에도 대입이 가능한경우
- long을 int에 대입할 수 있다. 범위가 더 넓기때문이다
이처럼 범위가 더 넓은것 -> 좁은것으로는 대입이 가능하다
다른 타입 간 연산
char c1 = 'a';
char c2 = c1 +1;//컴파일에러o
char c3 = 'a' + 1;//컴파일에러 x, c3 = 'b'- 두번째 줄 같은 경우는 char + int를 해서 int가 됐는데 char로 선언하고 변수는 int라 타입이 불일치하여 컴파일 에러가 발생하였다
- 세번째 줄은 리터럴간의 연산이다. 리터럴간의 연산은 컴파일시에 계산이 돼서 값이 저장이 된다. 그래서 'b'가 들어가게 된다
리터럴은 컴파일러때 미리 계산된다
- 86400을
60*60*24로 풀어쓴다고해서 더 오래걸리지않는다. 왜냐하면 리터럴이여서 컴파일러시간에 계산되기때문이다. - 또한 가독성측면에서 더 좋다
유니코드
char x = 'a';
char x = 65;x는 a를 저장하는게 아니라 a라는 유니코드 즉 숫자를 저장한다
그래서 사실은 모든 데이터를 숫자로 변환하여 저장하는 것이다
때문에 'a'말고 유니코드값을 직접 넣어줘도 된다
인코딩 디코딩
- 인코딩: 'a' -> 65
- 문자 -> 코드
- 디코딩: 65 -> 'a'
- 코드 -> 문자
정수 자료형 고르기
- 피연산자 스택이 4바이트 기준으로 저장해서 4바이트보다 작은 값 계산할때는 4바이트로 변환하여 수행함
그래서 int가 효율적임 - short나 byte는 성능보다 저장공간을 절약해야할때 사용해야함
그럼 long은?
- 4바이트 기준이라면, long은 데이터가 잘린다는얘기인가?
https://www.codeit.kr/community/threads/10989 을 참고해보면 - 4바이트 > 자료형크기 -> int로 변환 후 스택에 쌓음
- 4바이트 < 자료형크기 -> 해당 자료형으로 스택에 쌓음
실수형의 overflow
- 정수형의 경우 음수값이 나오지만 실수형의 경우 변수의 값이 무한대가 된다.
- underflow의 경우 변수의 값은 0이된다
double과 float
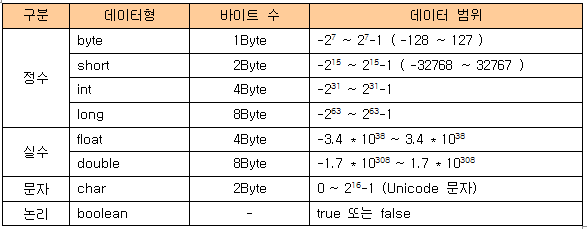
- double: double이 더 큰 범위를 갖는다
- float에 값을 저장하려면 실수리터럴 뒤에 f를 붙여야한다
float f1= 3.14; // 컴파일에러
float f2= 3.14f;- double이 더 큰 범위를 갖기때문에 더 많은 수를 표현할 수 있다. 더 정확하다는 의미다.
flaot vs double
- 연산속도 향상, 메모리 절약 -> float
- 더 큰 범위, 더 높은 정밀도 -> double
float -> double 형변환
- 오차가 발생한다
- double을 구성하는 부호,지수,가수 부분이 있는데 여기서 가수부분만 0으로 채우기때문이다.
- 가수: 소수이하부분, 부호: +-, 지수: 2의지수
float와 double의 비교
- double을 float로 형변환해야한다
- 둘다 오차가있을수밖에없는데 그 오차가 다르게 나기때문이다.
실수
- 실수횽은 값을
부동소수점 수로 저장한다 - 부동소수점 수: +-M * 2^E 같은 형태로 표현하는 것
- 22.3 을 이진수로 표현할때 .3은 2씩 곱해서 1이될때까지 반복하는데 이렇게 변환을하다보니 유한소수여도 이진수로 바꾸면 무한소수가 될때가있음. 이러다 보니 오차가 발생함.
- 애초에 실수는 무한대이기때문에 어느정도의 반올림같은것들을 넣음 그러다 보니 오차가 발생함
자동 형변환
float s = 1234;
int i= 3;
double a = 1.0 + i;//자동형변환 -> 산술변환- 이게 가능한이유는 1234 앞에 (float)가 생략되었고
자동으로 형변환이 되었기때문이다 - 연산시 더 넓은 자료형으로 자동 형변환이 되기도 한다
- int보다 작은연산자들끼리의 덧셈은 int로 자동형변환된다
- char + short -> int + int -> int 가된다
- char + char -> int + int -> int
- char + int -> int + int -> int
- 비교연산자의 경우에도 이항연산자여서 위와 같은 형변환이 일어난다
c1++
char c1 = 'a';
c1++;
//c1 = c1+1; // error! 연산결과가 int형이기때문
System.out.println(c1);//'b'printf
- println: 값 변환없이 그대로 출력 다른 형식으로 출력못함
- printf를 통해 소수점 둘째짜리 출력 등을 할 수 있다
word
- word: CPU가 한번에 처리할 수 있는 데이터의 크기
비트 연산자
- 피연산자를 비트단위로 논리연산
- 피연산자를 이진수로 표현했을때의 각자리에 대해 연산을 수행한다
16진수 한자리씩 뽑기
0xABCD 에다가 0xF를 AND연산한다
1010 1011 1100 1101
0000 0000 0000 1111
-> 1101 만 남아서 0xD를 얻을 수 있다
복합대입연산자
i *= 10 + j
i = i* (10+j);
안녕하세요!