0. 개요
통계청의 통계 분류 포털을 접속하면 아래와 같이, 한국 직업 분류 엑셀 파일을 얻을 수 있다.

이를 CSV파일로 바꾸면 아래처럼 바뀐다.

각 컬럼이 ,와 줄바꿈을 통해 행과 열을 구분하는 형식의 파일로 바뀌는 것이다. 이것이 csv 파일이다.
또한 직업 종류코드속성의 자리수가 늘어 날 때 마다 하위 분류로 표기 되었음도 알 수 있다.
이를 자바를 이용해 오라클 데이터베이스에 한번 저장해보자.
job 카테고리 구조
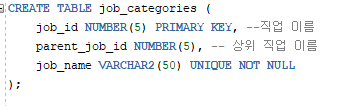
1. 자바 코드 작성
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class CsvToSqlConverter {
public static void main(String[] args) {
// --- 사용자가 수정할 부분 ---
String csvFilePath = "your_data.csv"; // 원본 CSV 파일 경로
String outputSqlFilePath = "insert_jobs.sql"; // 생성될 SQL 파일 경로
// -------------------------
try {
convertCsvToSql(csvFilePath, outputSqlFilePath);
System.out.println("✅ '" + outputSqlFilePath + "' 파일이 성공적으로 생성되었습니다.");
} catch (IOException e) {
System.err.println("❌ 파일 처리 중 오류가 발생했습니다: " + e.getMessage());
e.printStackTrace();
}
}
public static void convertCsvToSql(String csvPath, String sqlPath) throws IOException {
// 각 들여쓰기 레벨별 마지막 부모 ID를 저장하는 맵
// Key: 들여쓰기 공백 수(Integer), Value: 해당 레벨의 마지막 ID(String)
Map<Integer, String> levelParentMap = new HashMap<>();
// try-with-resources 구문으로 파일 스트림을 안전하게 자동 종료
try (BufferedReader reader = new BufferedReader(new FileReader(csvPath));
BufferedWriter writer = new BufferedWriter(new FileWriter(sqlPath))) {
String line = reader.readLine(); // 헤더(첫 줄) 읽기 (건너뛰기)
while ((line = reader.readLine()) != null) {
// 1. 줄을 콤마 기준으로 분리 (직업명에 콤마가 있을 수 있으므로 2개로만 나눔)
String[] parts = line.split(",", 2);
if (parts.length < 2) continue; // 비정상적인 데이터는 건너뛰기
String codeRaw = parts[0];
String jobNameRaw = parts[1];
// 2. 현재 줄의 들여쓰기 수준(공백 수) 계산
int indentLevel = codeRaw.length() - codeRaw.replaceAll("^\\s+", "").length();
// 3. 코드와 직업명에서 앞뒤 공백 제거
String jobId = codeRaw.trim();
String jobName = jobNameRaw.trim().replace("'", "''"); // SQL Injection 방지를 위해 작은따옴표 이스케이프
// 4. 부모 ID 찾기
String parentId = "NULL";
if (indentLevel > 0) {
int parentLevel = -1;
// 현재 레벨보다 낮은 레벨 중 가장 가까운(큰) 레벨을 찾음
for (int level : levelParentMap.keySet()) {
if (level < indentLevel) {
parentLevel = Math.max(parentLevel, level);
}
}
if (parentLevel != -1) {
parentId = levelParentMap.get(parentLevel);
}
}
// 5. 현재 ID를 다음 자식들이 참조할 수 있도록 맵에 기록
levelParentMap.put(indentLevel, jobId);
// 6. SQL 구문 생성 및 파일에 쓰기
String sql = String.format(
"INSERT INTO job_categories (job_id, parent_job_id, job_name) VALUES (%s, %s, '%s');\n",
jobId, parentId, jobName
);
writer.write(sql);
}
}
}
}- 위 자바 코드와 csv파일을 같은 폴더위치에 넣는다.
- 자바코드의 csv_file_path = 'your_data.csv' 부분을 실제 파일명으로 수정한다.
- cmd에서 cd 명령어로 (자바+csv)두개의 파일이 담긴 폴더로 이동하고, 아래코드 실행해 컴파일
javac CsvToSqlConverter.java- 아래 명령어로 컨버터 작동 시 아래처럼 sql이 만들어진다.
java -cp . CsvToSqlConverter
2. 조회하기
만들어진 테이블은 상위 카테고리가 존재하는 테이블임으로 계층형 쿼리를 통해 조회할 수 있다.
SELECT
LEVEL,
LPAD(' ', (LEVEL-1)*4) || job_name AS job_name_indented, -- 들여쓰기 적용
job_id,
parent_job_id
FROM
job_categories
START WITH
parent_job_id IS NULL -- 최상위 부모(parent_job_id가 NULL인)부터 시작
CONNECT BY
PRIOR job_id = parent_job_id; -- 부모의 job_id가 자식의 parent_job_id와 같은 관계

결과 파일

DB가 좋아요