알고리즘
정말 오랜만에, 그리고 굳어있던 머리를 다시금 원할하게 윤활유를 붓는 시간이다.
시간 복잡도와 공간복잡도.
시간 복잡도(Time Complexity)는 알고리즘의 절대적인 실행 시간을 나타내는 것이 아닌 알고리즘을 수행하는 데 연산들이 몇 번 이루어지는 지를 숫자로 표기한다.
#case 1
sum = n + n
#case 2
for i in number
sum += n
#case 3
for i in number
for j in number
sum += num
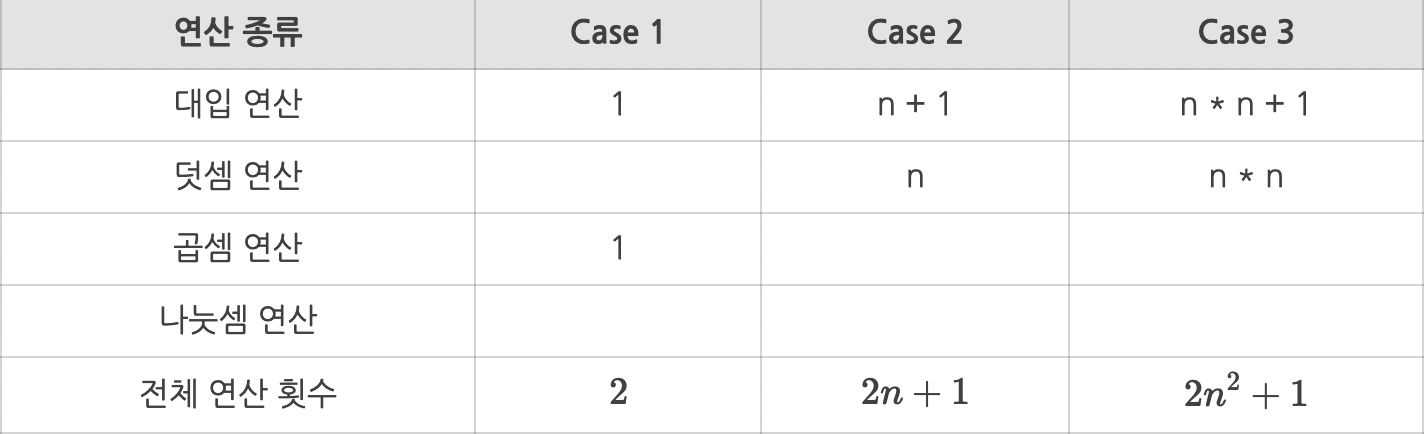
곱셈 연산은 덧셈 연산보다 시간이 더 소요되지만 동일하다고 가정하자.
하나의 연산이 t 만큼의 시간이 필요하다고 가정한다면
Case 1의 경우는 2t만큼의 시간이 필요하고
Case 2의 경우는 (2n+1)t만큼의 시간,
마지막으로 Case 3의 경우에는 (2n2+1)t만큼의 시간이 필요하다.
공간복잡도는 알고리즘에서 사용하는 메모리 양이라 생각한다.
공간 복잡도는 보조공간(Auxiliary Space)과 입력 공간(input size) 을 합친 포괄적인 개념이며
보조 공간(Auxiliary Space) 은 알고리즘이 실행되는 동안 사용하는 임시 공간이기에, 입력 공간(input size) 을 고려하지않는다.
빅오 표기법(big-oh notation)
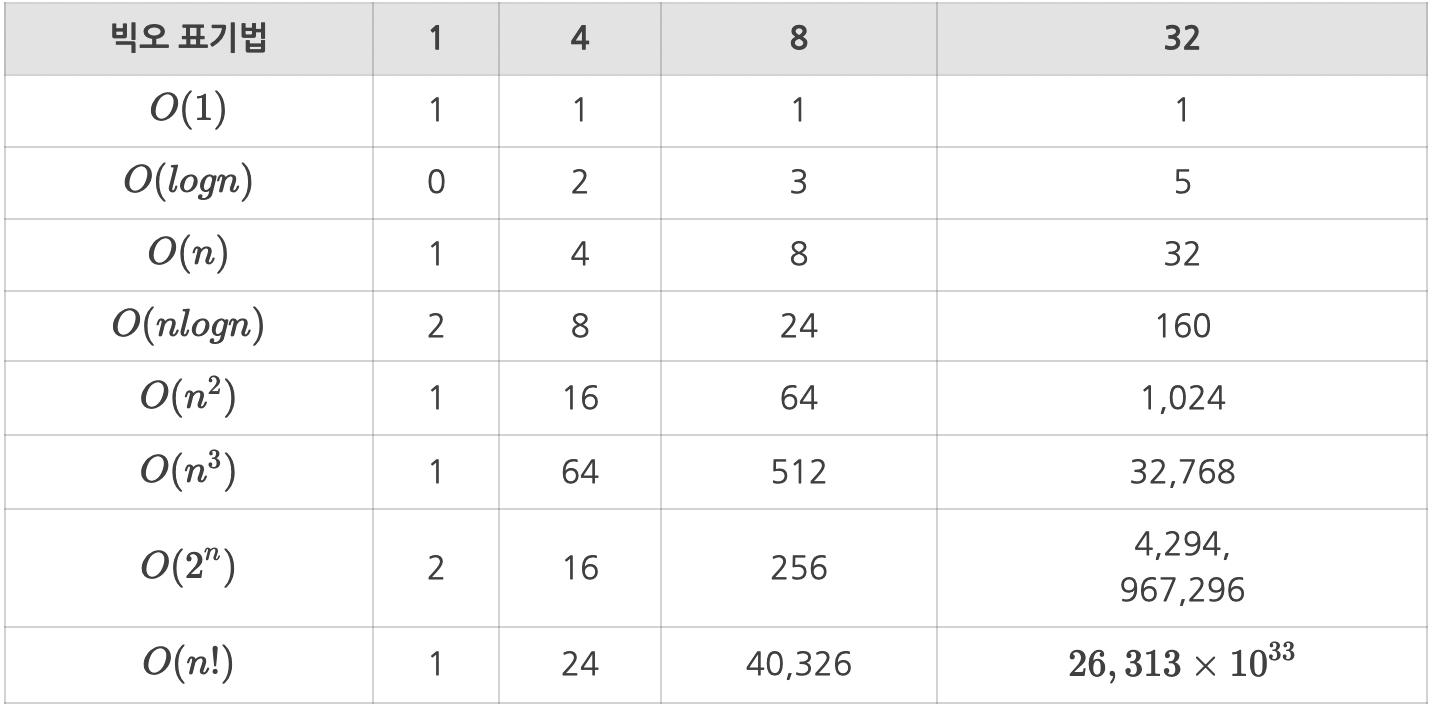

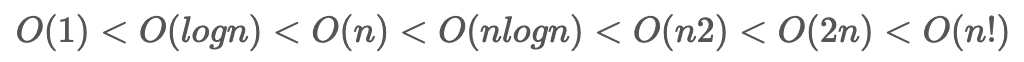
빅오 표기법이란, 쉽게말해 알고리즘의 성능이 어떤 효율을 가지고있는지 알려주는 일종의 지표이며, 시간복잡도와 공간복잡도를 표현할때 많이 사용된다.
대표적인 예는 다음과 같다.
- O(1) : 스택에서 Push, Pop
- O(log n) : 이진트리
- O(n) : for 문
- O(n log n) : 퀵 정렬(quick sort), 병합정렬(merge sort), 힙 정렬(heap Sort)
- O(n^2): 이중 for 문, 삽입정렬(insertion sort), 거품정렬(bubble sort), 선택정렬(selection sort)
- O(n!) : 피보나치 수열
입출력
파이썬의 입출력은 간단하게 두개로 받을수있다
n = int(input())
start, end = map(int, input().split())간단하게 input으로 입력받은 값을 int형으로 받거나
다수가 입력될경우, map을 돌려 split을 통해 받는다.
또는
from sys import stdin
n = int(stdin.readline().rstrip())
el = list(map(int, stdin.readline().rstrip().split()))
el2 = map(int, stdin.readline().rstrip().split())
해당하는것처럼
stdin.readline().rstrip()을 통해 오른쪽문자들을 제거하고 리스트, 혹은 그냥입력받을수 있다.
여러줄을 입력받거나 시간의 제한이 짧을경우 해당하는 함수로 받는것이 시간에 매우 유리하니 왠만하면 해당 형식으로 입력받자
자료구조
스택

스택은 시간 순서에 따라 자료가 쌓여서 가장 마지막에 삽입된 자료가 가장 먼저 삭제된다는 구조적 특징을 가지게 된다.
이러한 스택의 구조를 후입선출(LIFO, Last-In-First-Out) 구조라고 한다.
배열의 형식에서는
n = []
n.append('1')
a = n.pop()
print(a) # 1해당하는것처럼 뒤에 항상 붙고, pop을 사용할시 마지막으로 들어온 원소가 나간다.
큐

큐는 간단하게 줄을 선 모습이라 생각하면 된다.
쌓여나가는것은 스택과 동일하지만
선입선출(FIFO, First in first out) 방식의 자료구조를 말한다.
파이썬에서는 감사하게도 collections 내장함수에서 deque를 지원하므로 이를 활용하면 빠른시간안에 알고리즘을 풀 수 있다.
from collections import deque
deq = deque()
# Add element to the start
deq.appendleft(10)
# Add element to the end
deq.append(0)
# Pop element from the start
deq.popleft()
# Pop element from the end
deq.pop()
# Contain 1, 2, 3, 4, 5 in deq
deq = deque([1, 2, 3, 4, 5])
deq.rotate(1)
print(deq)
# deque([5, 1, 2, 3, 4])
deq.rotate(-1)
print(deq)
# deque([1, 2, 3, 4, 5])
deq = []
arr = deque(deq)
- deque.append(item): item을 데크의 오른쪽 끝에 삽입한다.
- deque.appendleft(item): item을 데크의 왼쪽 끝에 삽입한다.
- deque.pop(): 데크의 오른쪽 끝 엘리먼트를 가져오는 동시에 데크에서 삭제한다.
- deque.popleft(): 데크의 왼쪽 끝 엘리먼트를 가져오는 동시에 데크에서 삭제한다.
- deque.extend(array): 주어진 배열(array)을 순환하면서 데크의 오른쪽에 추가한다.
- deque.extendleft(array): 주어진 배열(array)을 순환하면서 데크의 왼쪽에 추가한다.
- deque.remove(item): item을 데크에서 찾아 삭제한다.
- deque.rotate(num): 데크를 num만큼 회전한다(양수면 오른쪽, 음수면 왼쪽).
데크는 리스트보다 매우 월등한 속도를 자랑한다.
push/pop이 빈번할경우 데크를 사용하는것을 추천한다.
그리고
너비 우선 탐색 알고리즘 (BFS - Breadth-First Search) 에선
방문한 노드들을 순차적으로 뽑아내려면 큐를 사용해야하기에, 해당 알고리즘에서도 사용된다.
힙
힙은 특정한 규칙을 가지는 트리로,
최댓값과 최솟값을 찾는 연산을 빠르게 하기 위해 고안된 완전이진트리를 기본으로 한다.
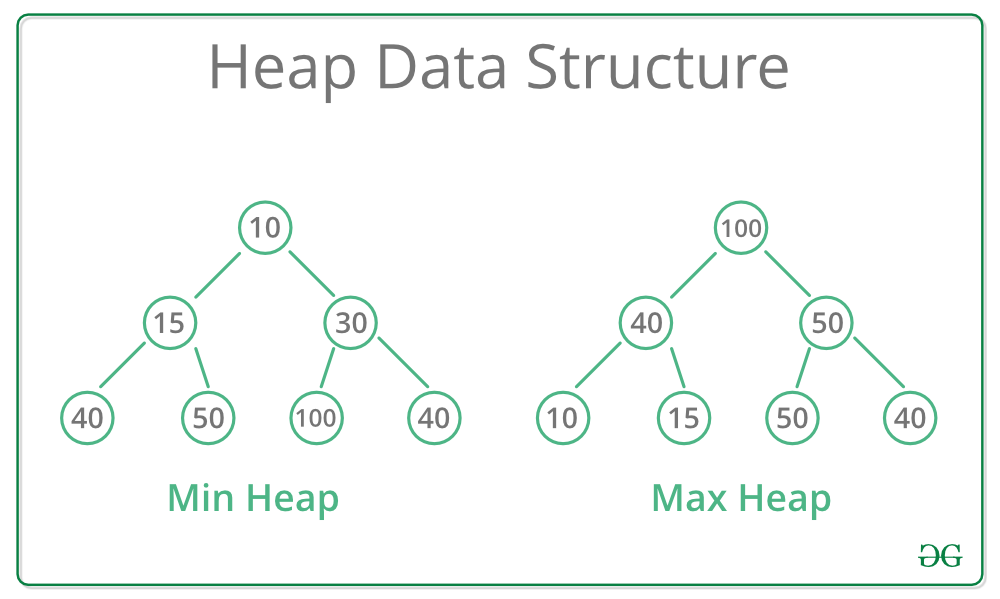
키값의 대소 관계는 부모/자식 간에만 성립하고, 형제노드 사이에는 대소 관계가 정해지지 않는다.
파이썬 heapq 모듈은 heapq (priority queue) 알고리즘을 제공한다.
모든 부모 노드는 그의 자식 노드보다 값이 작거나 큰 이진트리(binary tree) 구조인데,
내부적으로는 인덱스 0에서 시작해 k번째 원소가 항상 자식 원소들(2k+1, 2k+2) 보다 작거나 같은 최소 힙의 형태로 정렬된다.
heapq는 내장 모듈로 별도의 설치 작업 없이 바로 사용할 수 있다.
- heapq.heappush(heap, item) : item을 heap에 추가
- heapq.heappop(heap) : heap에서 가장 작은 원소를 pop & 리턴. 비어 있는 경우 IndexError가 호출됨.
- heapq.heapify(x) : 리스트 x를 즉각적으로 heap으로 변환함 (in linear time, O(N) )
import heapq
heap = []
heapq.heappush(heap, 50)
heapq.heappush(heap, 10)
heapq.heappush(heap, 20)
print(heap) # [10, 50, 20]
result = heapq.heappop(heap]
print(heap[0]) # 10. [10,50,20] 제거하지 않고 출력만 한다.
print(result) # 10,[50,20] 가장 작은 원소를 제거하고 반환한다.만약 최대힙으로 바꾸고 싶다면
heapq.heappush(heap, (-50, 50))
#-50이라는 키값으로 50을 넣되,
#튜플의 형태로 넣는다.
max = heapq.heappop(heap)[1]
#실제 원소 값은 튜플의 두 번째 자리에 저장되어 있으므로 [1] 인덱싱을 통해 접근하면 된다.
print(max) # 50순열, 조합, 중복순열, 중복조합
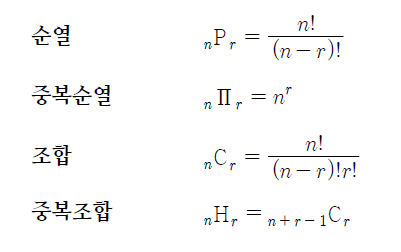
순열
순열은 순서를 고려하여 뽑는 경우의 수이다.
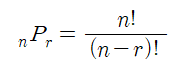
서로 다른 n개에서 r개를 택하여 일렬로 나열하는 경우의 수.
예를들어 1,2,3,4,5,6,7 이란 수 중 3개를 뽑아 세자리 수를 만들수있는 경우의 수를 들자면,
7 x 6 x 5 = 210가지이다.
from itertools
import permutations
sets = [1,2,3,4,5,6,7]
data = itertools.permutation(sets, 3)
#[1,2,3],[1,2,4]....[3,2,1].....[7,6,5]뽑힌 순서로 나열하고, 순서에 의미가 존재한다.
즉 1,2,3과 3,2,1은 값은 원소가 뽑혓으나, 순서가 다르기 때문에 다른 경우의 수로 취급한다.
permutations(반복 가능한 객체, r)
조합
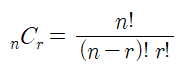
조합은 순서를 고려하지않고 뽑는 경우의 수이다.
예를 들자면 10명중 2명을 대표자로 선발한다 하였을때,
(A,B)나 (B,A)는 같은 원소가 뽑혓기에 같은 경우의 수로 취급한다.
from itertools
import combinations
sets = ['A','B','C','D','E','F','G']
data = itertools.combinations(sets, 2)반복 가능한 객체(=길이가 n인)에 대해서 중복을 허용하지 않고 r개를 뽑는다.
어떤 것을 뽑는지만 중요하게 보기 때문에 뽑은 순서는 고려하지 않는다.
중복순열
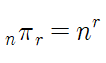
순열과 비슷하나, 중복가능한 수 n 중 r을 뽑는다
위의 순열 예제 중,
1,2,3,4,5,6,7에서 3자리를 만들되, 중복을 허용하여 만들수있는 3자리의 수는
777, 666, 555 와 같은 수가 가능하다.
from itertools import product
sets = [1,2,3,4,5,6,7]
#2개를 뽑아 일렬로 나열하는 경우의 수(단, 중복 허용)
data = itertools.product(sets, repeat = 3)
#[1,1,1],[1,1,2]....[3,3,3].....[7,7,7]중복조합
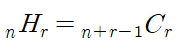
중복 가능한 n개의 수 중, 순서를 고려하지않고 r개를 뽑는 수이다.
예를 들자면
10명의 입후보중 중복하여 회장, 부회장을 격임할 사람을 뽑는다 고려한다면
(A,B)와 (B,A)는 같은 경우이지만
(A,A)나 (B,B)가 가능하다.
from itertools
import combinations_with_replacement
sets = ['A', 'B', 'C']
data = itertools.combinations_with_replacement(sets, 2)