목표
FTP, HTTP와 같은 기본 응용 계층 프로토콜의 예를 배운다.
FTP는 굉장히 복잡한 프로토콜임.
- 컴퓨터 안의 파일 시스템 작업을 그 안에서 할 수 있음
- 기능이 너무 많음.
- 원하는 기능이 세션 프로토콜 FTP가 지원하지 않으면 답답함
HTTP는 단순하고 강력함.
HTTP
- 세션 계층 (world wide web을 지원)
- html을 기본 프로젠테이션 계층으로 사용.
- 목적: 전세계 인터넷에 있는 정보를 탐색
동작
- web 자료를 가져와서(GET) 보여주기
- web에 자료를 posting 하기
url
- Universal Resource Locator : 이 온 우주에 하나있는 위치정보
http://artgarden.co.kr/comnet
1) http:
: 프로토콜 이름
ex) file: , ftp: 가 될 수 있음 (ftp도 브라우저로 접속 가능함)
2) //artgarden.co.kr
: host 이름
-
프로세스에 가고자 할 때 필요한 주소 : ip, port
-
ip가 나타내는 것: 기계 자체의 고유 id
3)/comnet/
: 기계까지 간 후 '자원' -
실제로 자원이 위치하는 곳이 어디냐
-
수백개 수천개의 웹페이지와 이미지의 자원들... 중 하나 !

포트번호는 생략할 수 있다.
왜? -
http 프로토콜은 기본적으로 80번 포트를 사용한다.
-
ftp 프로토콜은 기본적으로 21번 포트를 사용한다.
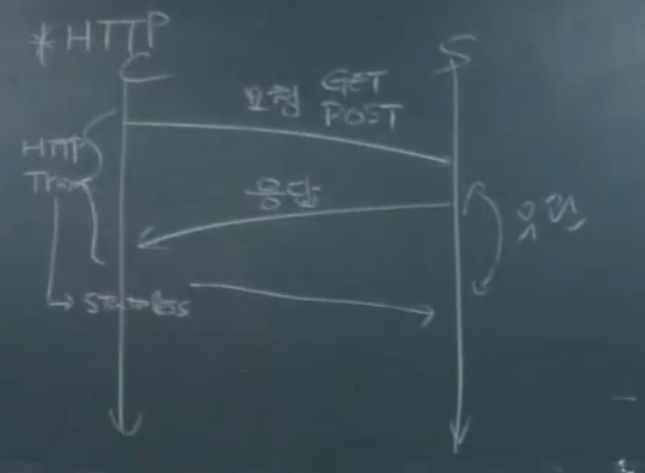
HTTP

사용자가 Http client 웹 브라우저에 url을 입력하면 get, post 요청을 Http server인 웹 서버 (nginx)을 한다. 그러면 http server는 200 응답 또는 error응답을 한다.
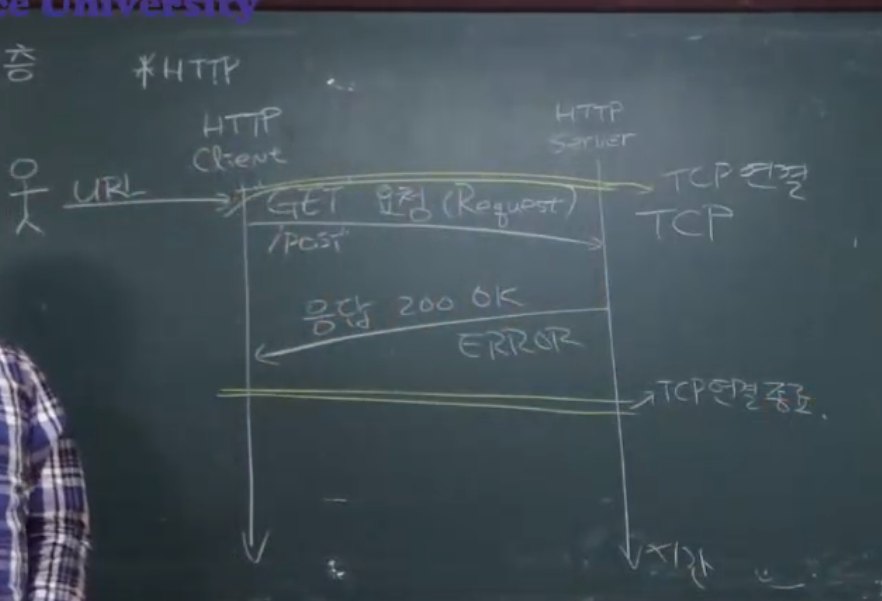
기본적으로 이 HTTP 프로토콜은 TCP를 기반으로 동작한다.
- 연결 존재 (연결을 위해 GET 요청 전에 함)
- 이 연결은 client가 server 한테 하는 것.
- server는 누가 자기한테 연결 요청할지 모르니 server socket을 열어둔다.
- client는 열려있는 server socket으로 tcp 연결을 한다.
- server의 ip address, port(기본적으로 80번)로 ~
- 연결 되고 나면 http client가 get 요청 가즈앙 ~
- 끝나고 나면 tcp연결 종료 ~

HTTP Transaction
HTTP는 Stateless Protocol
FTP는, Stateful protocol
=> 계속 요청하고 응답하면서 client가 어떤 동작하고, 사용자가 누구고, 어떤 디렉토리 사용하는지 server가 계쏙~~~ 추적
HTTP는 Stateless Protocol
=> 한번 요청하고 응답하고나면 client가 어떤 일 하는지, 어떤 정보인지 다 잃어버림.
굉장히 단순하기 때문에 그 위에 풍부한 응용을 언질 수 있음.
GET 요청
- 원하는 자원을 가져오는 목적
- 형식:

GET /comnet/ HTTP/1.1
자원을 주는 입장에서 내가 이렇게 줘도 얘가 이해할까? 라는 의구심이 있음.
-
자원 가져올 때 세심하게 나에 대한 정보를 주면 줄수록 Server가 적절한 정보를 줄 수 있음.
-
png 파일 형식을 이해하는지, 못하는지
-
압축된 파일이 괜찮은지, 안괜찮은지
매개변수 설정 가능.
매개변수1:
매개변수2:server는 같은데 어떤 host를 적느냐에 따라서 다른 정보를 줄 수 있음.
host:formal.kau.ac.kr
내가 쓰는 웹 브라우저는 이러이러한 형태니까, 내가 잘 볼 수 있게 줬으면 좋겠어.
-
-
ex) chrome, internet explore ...
User-agent: Mozila/5.0이 모든 내용을 HTTP 요청 header 라고 함.

한줄 띄기
=> header가 끝이다.라는 의미
=> 이것으로서 GET 요청은 끝.
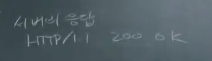
Last-modified : 최근 수정 날짜
... 그밖에도 server의 정보 줄 수 잇음 (난 아파치 쓰고 있음)

몸통이 언제 끝나는지는 어떻게 아는가?
- header의 Content-Length: 487
- 아~ body 크기는 487byte 구나 ~
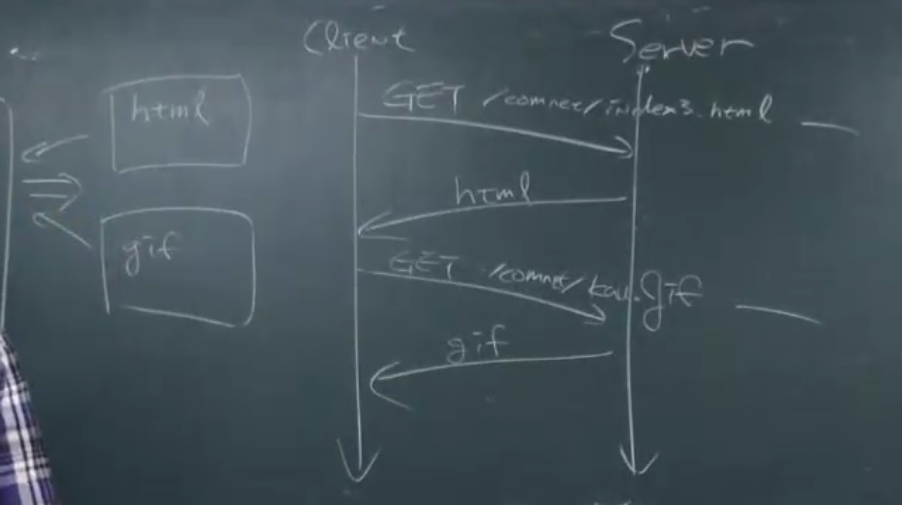
- 두번의 트랜잭션을 통해 하나의 웹 페이지를 보여주고 있음
- html
- gif
POST 요청
: 자원을 server에 게시하고 싶을 때.
- 게시판에 글 올리기
- 인스타그램에 사진 올리기
- 웹 브라우저를 이용해 email 보내기
- 로그인
형식

url 뒤에 인자가 있으면 URI
URL : Univrsal Resource Locater (자원의 위치)
URI : Universal Resource Identifier
중간 정리
- HTTP는 단순한 프로토콜이다.
- Client가 요청하면 Server가 응답
- HTTP Transaction이라고 함.
- Stateless : 한번 요청, 응답하고 나면 server쪽 session layer에서는 앞의 어떤 요청을 기억하지 않는다.
=> 이전 transaction과 다음 transaction이 무관하다
=> 의문이 생김. 아니, 로그인하고 나면 받는 정보가 달라지는데??
=>Cookie가 이 의문점을 해결해줌.
- Stateless : 한번 요청, 응답하고 나면 server쪽 session layer에서는 앞의 어떤 요청을 기억하지 않는다.
- HTTP Transaction이라고 함.
Cookie
쿠키를 설명하기 위해서 client와 server가 어떤 구조("웹 응용의 구조")를 가지고 있는지 설명해야됨
웹 응용의 구조
web client (인터넷 브라우저)

현재 홈페이지
application layer
HTML 엔진을 가지고 있음.
presentation layer: 풍부한 표현 능력을 갖고 있는 두꺼운 엔진임.
HTTP 프로토콜
session layer
web server
서버 응용 프로그램
: http의 단순함으로 server 응용이 높은 자유도를 가지고 있음.
: ex) 로그인 정보, 장바구니 정보
서버 응용 엔진
HTTP 프로토콜
session layer: stateless 하다 ~
ex) 만약 일반적인 경우로 client에서 파일로 된 html을 달라고 url을 주는 경우는,
웹 서버는 그 파일 시스템에서 찾아다가 넘겨준다.
ex2) URI를 통해서 GET, POST를 하는 경우에는, 요청에 맞게 맞춤형으로 자원을 만들어내서 응답해야 한다.
즉, stateless라는 말은 http server 쪽 (session layer)에만 해당되는 내용이고 , 실제 그 위에 올라가는 server 응용이 stateless는 아니라는 말 ~
서버 응용이 누가 이전에 접근한 사람이 다시 온건지, 동일한 사람인지 구별할 방법이 바로 Cookie라는 것~~
Cookie
상태 정보를 담는 도구다.
쿠키란?
: 서버 응용이 클라이언트의 이전 과거 정보 (state)를 파악하기 위한 도구.
쿠키 프로토콜
- 기본적으로 http response header(server => client)에는
Set-cookie 라는 필드가 있음. - http request header(client => server)에는
cookie라는 필드가 존재.
server는 상태 정보를 갖고 있지 않지만, client는 반대로 상태 정보를 갖고 있다.
그 상태 정보가 뭐다? server지난 번에 준 cookie다 ~~
그러면 그 cookie를 보여주면 client가 누군지 server가 생각해낼 수 있음.
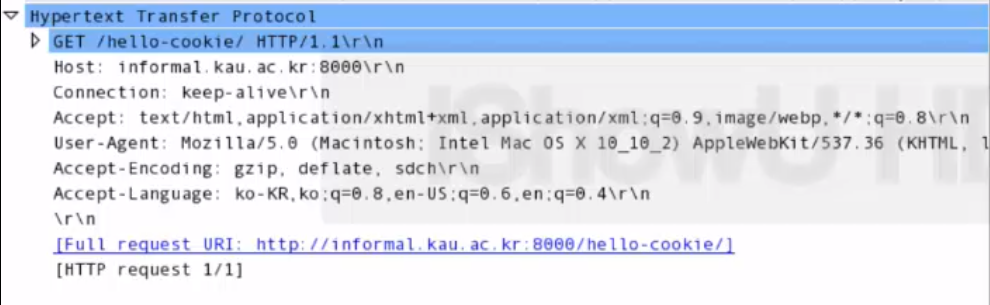
- 요청할 때 header에 쿠키가 없음.
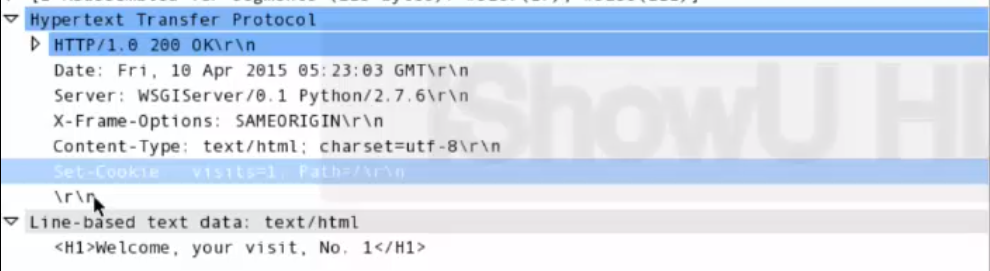
- 응답하니 Set-Cookie가 있음.
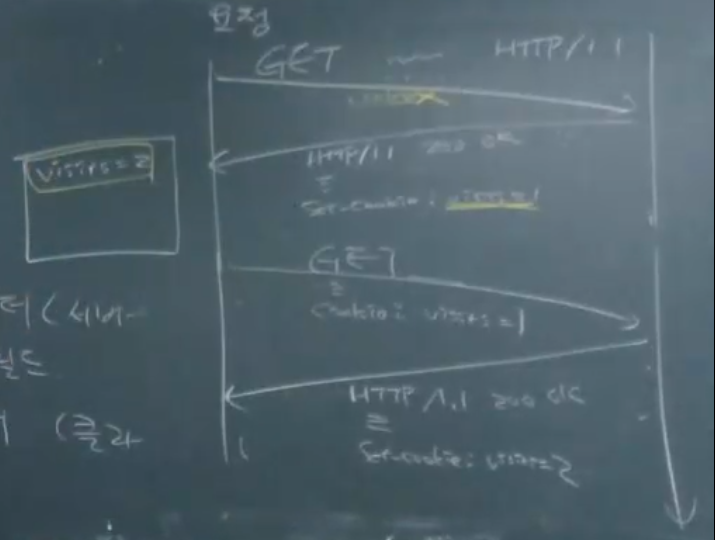
- 한번 방문하면 server에서 visit = 1을 같이 줌.
- client에서 visit=1과 Set-Cookie를 같이 줌.
- server에서 visit=2로 응답함.
..이런식
응용 계층에서 이런 쿠키를 왔다갔다 하고, 세션 계층에서는 이 정보를 이용하지 않는다. 쿠키를 응용계층에 던져줄 뿐임.
web server는 세션계층에서는 stateless 지만, 응용계층에서는 statefull하게 된다.
장점) 쿠키는 기본적으로 client에게 필요한 정보를 쿠키 형태로 보내줌으로써 정보를 알게함
단점) client에게 너무 많은 정보를 open함.
방법론
: 기억해야할 상황을 쿠키에 담아 client가 기억하도록 하고, server는 client의 방문시 주는 키 정보의 맞추어 반응한다.
문제
client에 너무 많은 권한과 정보를 준다.
- 해커가 조작 가능
해결책
=> 이 문제를 해결하기 위한 방법으로 세션이 있음
- 이것또한 쿠키를 이용하는 방법이긴함.
- 하지만, server가 client에게 세션 id만 준다. (몇 번 방문했는지 등 정보는 안줌)
- client는 세션 id만 server에게 준다.
- server가 세션마다 정보를 유지해서, 상대방에게 세션 id만 준다.
session
: client에게 세션 id 정보만 쿠키로 server에게 전달하고, 세션들의 특성은 server가 관리한다.
ex) 몇번 방문했는지등의 정보
- 쿠키 기법은 client가 정보를 저장한다. 쿠키 자체에 담고 있고, server에게 정보 줌
- 세션은 server가 정보를 저장한다. client가 세션 id 주면, server가 그에 맞는 정보를 client에게 줌.
HTTP
지금까지 http 기능에 대해서 알아봤다면, 이제는 성능에 대해 알아보자.
http의 성능을 어떻게 발전시킬 거인가?
HTTP Transaction의 성능
기본 HTTP
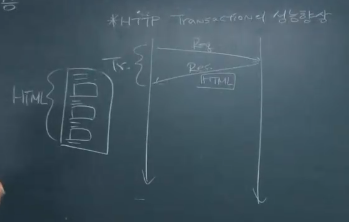
- REQ, RES 하나의 Transcation 을 통해 html을 응답한 모습
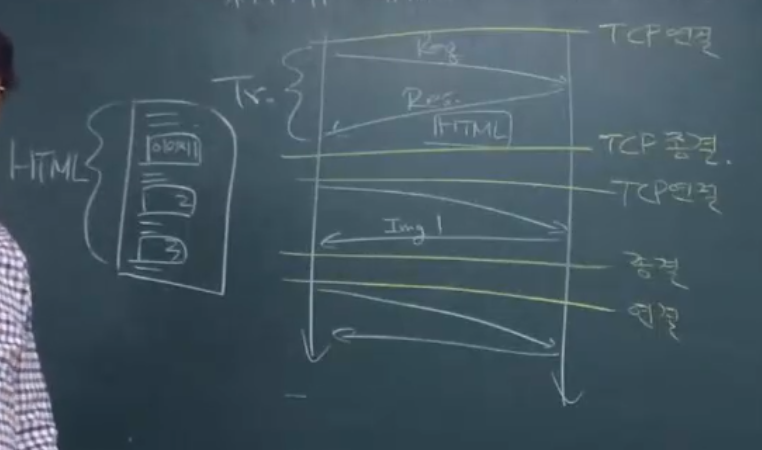
- 원칙적으로 HTTP는 이 때 TCP 연결을 하고, TCP 종결을 한다.
- 이미지 가져오려고, 다시 TCP 연결 새로하고, 보내고, TCP 종결을 한다.
- 낭비가 심함.
Persistant HTTP

- 요청의 필드 중에 Connection keep allow라는 필드가 있음 : 아직 연결 끊지 말라는 것.
- 연결 끊지 않고 다음 연결을 기다려줌.
- html 분석하고, 어? img1 가져와야 하네 . => 요청함.
- 어 img2 가져와야 하네. => 요청
- server가 기다리다가, 혹은 client가 가져올게 없네? 할 때 그때 종결
=> tcp 연결/종결에도 시간이 소요되기 때문에
Pipelined HTTP
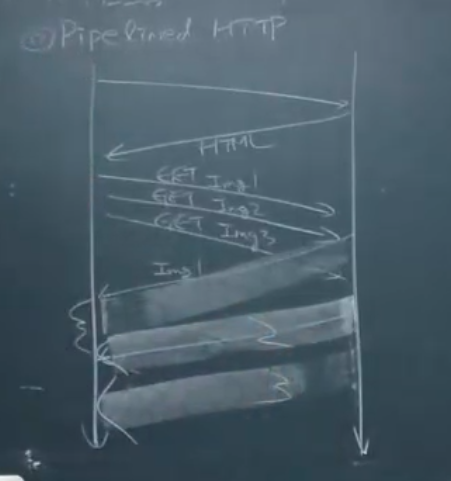
- HTML을 받기 전까지 어떤걸 추가로 받아야 하는지 알 수 없음.
- HTML 한번 반환받고 나면, IMG 추가로 요구해야 하는걸 HTML을 보고 알 수 있음.
- IMG 3개를 다 요청해.
Persistant HTTP와 Pipelined HTTP 성능 향상에 대해 알아보자.
성능을 평가하는 척도
- 지연시간
- 전송률
지연시간
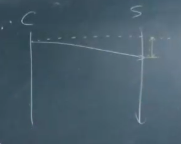
: 패킷을 보내기 시작한 시점에서 패킷을 받기 시작한 시점까지 걸리는 전송 지연 시간
패킷을 미국 구글사에 요청을 보낸다.
그 사이에 아무리 좋은 네트워크가 있어도,
패킷 전송의 시간 지연이 생김
중간에 장비들을 거치고 가면서 결과적으로
어찌됐든 지연 이후에 구글이 패킷을 받는다.
전송률
: 단위 시간당 전송되는 데이터의 양.
- 단위시간은 초 단위가 된다.
패킷을 보냈을 때 - 1메가, 1기가 등의 커다란 파일을 보내는데,
- 4초가 걸렸다.
- 1메가 바이트당 4초가 걸렸으면, 1초당 250KB 만큼 보낸 것.
- 단위 시간당 얼마만큼의 패킷을 보낼 수 있는지임.
블루트스와 내 휴대폰의 거리는 짧지만, 블루투스가 가지고 잇는 대역폭이 좁음.
- 전송률은 KB 수준으로 낮아질 수 있음.
EX)
- 끝단 간(단말) 지연시간이 100ms(밀리 세컨드) 이고, 전송률이 100MB/s 인 네트워크에서 1MB를 전송하여 수신을 완료하는데 걸리는 시간
답)
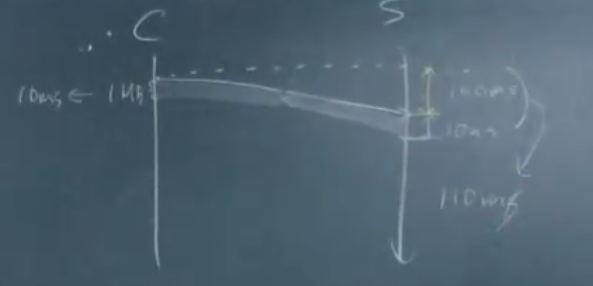
1/100초 => 10ms(밀리 세컨드)
정리
네트워크에 따라서 지연시간 특성, 전송률 특성이 다 다름.
- HTTP를 사용할 때 여러개의 Transaction이 필요함.
- 어떻게 성능을 향상 시킬 것이냐?
- Persistence HTTP
- Pipelined HTTP
이제는 네트워크 구조 관점에서의 성능 향상을 알아보자.
=>Web Cache
Web Cache
많이 사용되는 컴퓨터 성능 향상 기법임.
Web Cache란?
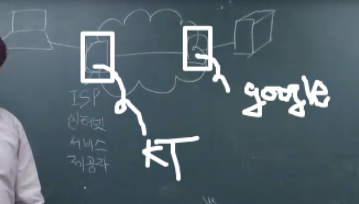
- kt가 구글 서비스를 의뢰하는 것임.
- kt가 만약 구글 서비스 제공 못하면, 고객들이 다른 ISP(Internet service provider_로 이동할 것임
=> 사용자가 몰려있는 컴퓨터 서비스 제공자(을)는 서버가 연결된 서비스 제공자(갑)에게 돈을 지불하는 형태임. - 돈 지불하는 것을 줄이고 싶다면? 적게 요청하면 됨.
- 요청을 적게 하면, client한테 가능하면 ~~ 구글 좀 쓰지마 ~ 이럴 순 없음. ㅋㅋㅋ
- 작은 server Provider는 무언가 인터넷 요청이 왔을 때, 요청을 서버쪽에 날리지 않고, 스스로 처리할 수 없을까? 하는 아이디어
=>Web Cache
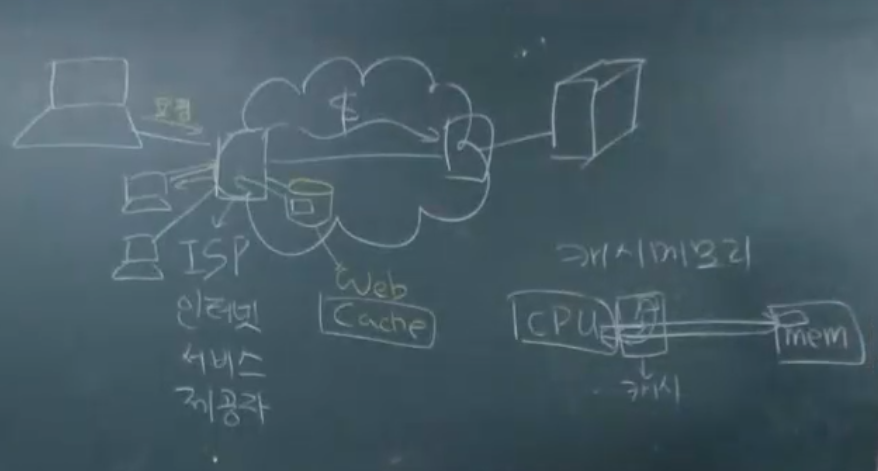
- kt가 만약 구글 서비스 제공 못하면, 고객들이 다른 ISP(Internet service provider_로 이동할 것임
- 만약 싸이의 강남스타일 영상을 요청하는 사용자가 많다? 해당 영상을 Web cache에 저장해서 유튜브 서버에 요청을 더이상 하지 않고, ISP에서 바로 응답한다.
- CPU가 메모리에 접근하는데 드는 시간은 10nano seconds, 캐시 메모리에 접근하는데 드는 시간은 1nano seconds.
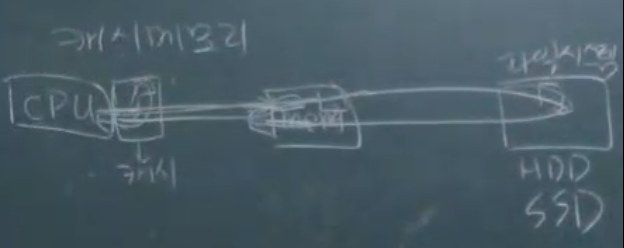
- 실제로 메모리 옆에는 더 느린 storage가 있다. =>
file system- hdd(hard disk drive), ssd(solid state drive)
- 메모리에서 파일시스템까지 갔다오는건 굉장히 시간이 많이 걸린다. 파일 시스템 안에서 많이 읽는 파일은 메모리 안에 둔다.
- 컴퓨터 입장에서는 파일 access 속도가 굉장히 빠름.
- 디스크에 부담을 적게 준다.
결론)Web Cache란?
: Proxy Server라고도 부르며, ISP(Internet Service Provider) 에서 비용절감을 위하여 이전에 가져온 적이 있는 문서를 DB에 임시저장해 놓았다가 동일문서가 다시 요청될 때 재사용한다.
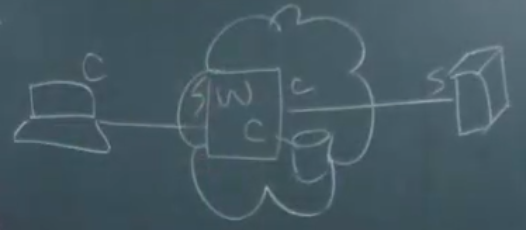
web cache는 client이자, server이다.
개별 client 한테는 db에 저장된 문서를 주는 "server"이고,
google server한테는 문서를 요청하는 "client"임.
web cache가 주는 이득
- 요청에 대한 응답시간 단축
- 제공하는 교통량 증가
- 더 많은 사용자 수용
- 더 적은 서버 용량으로 더 많은 사용자 지원할 수 있음.(google server입장)
web cache 동작

