목표
물리적인 메모리 관리 방법인 세그먼트에 대해 알아본다.
물리적인 메모리 관리는 사실 운영체제가 하는 일이 아니고, 하드웨어적으로 일어나는 일들이다.
memory protection

접근 권한은 어처피 그 프로세스한테만 있는데,
그 프로세스가 다 read, wirte 할 수 있냐
read-only만 할 수 있느냐 다.
code 같은 경우는 함수, 기계어를 담고 있기 때문에 그런 페이지는 변경이 되면 안된다. 읽기만 되야 한다.
inverted page table
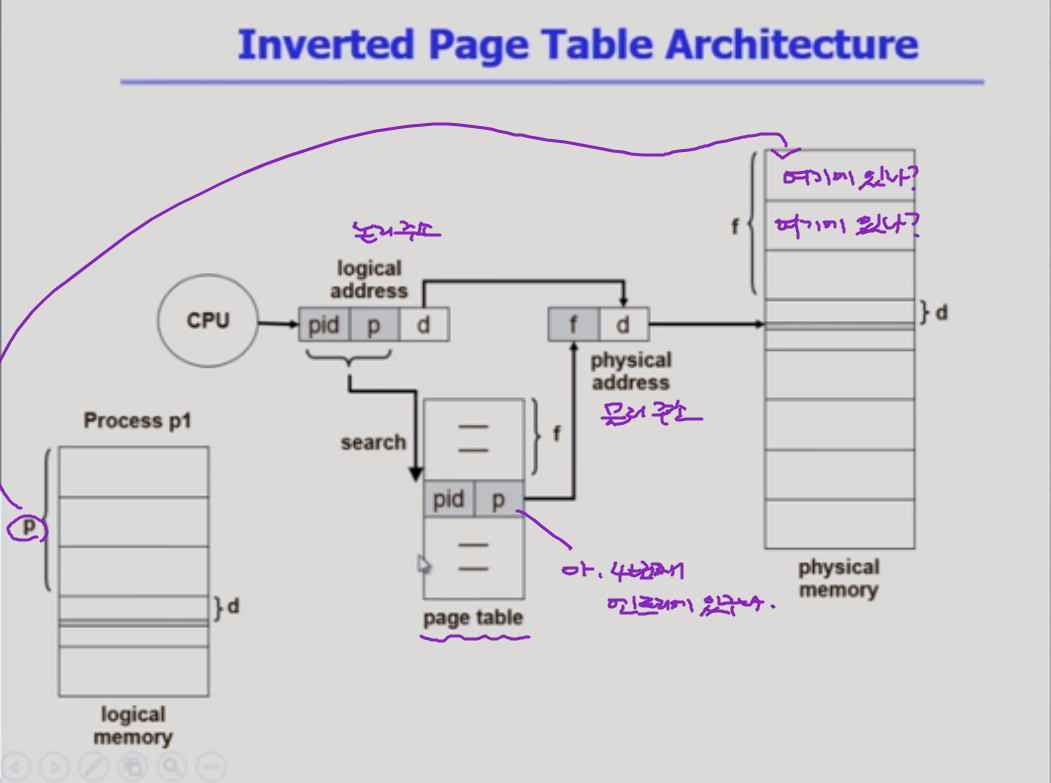
물리적 주소를 통해 논리적 주소를 얻기 쉬운 구조로 되어있다는 것 . 각각이 어떤 논리적 페이지를 담고 있는가를 알 수 있음.
좋은 점: page table이 하나만 있어도 된다. (프로세스가 여러개여도)
단점: 주소 변환 자체는 별반 도움이 안된다. 주소 변환은 원래 논리적 주소에서 물리적 주소를 알아내는게 중요한 것 이기 때문이다.

논리적 페이지 번호 외에 도대체 누구의 논리적 페이지냐를 담고 있는 프로세스 id를 같이 가지고 있어야 한다.
또 주소 변환을 위해서는 페이지 테이블을 싹 다 검사해봐야 한다.
shared pages examples
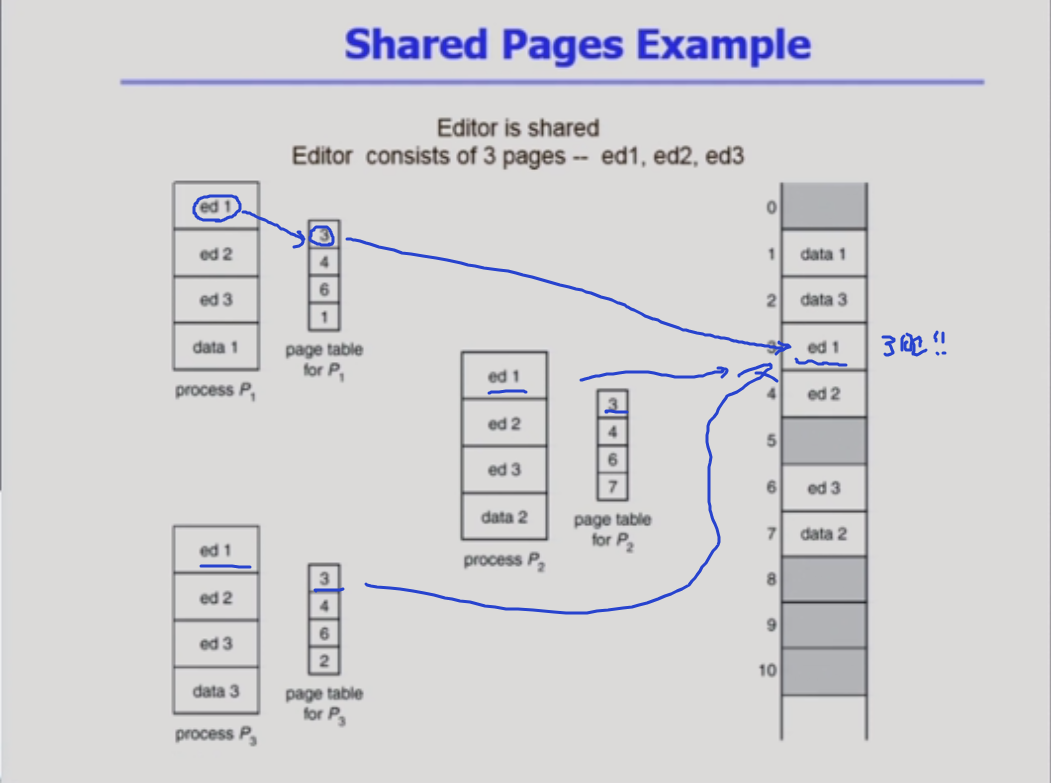
일반적인 경우를 설명하는 것 !
각각의 프로세스마다 페이지 테이블이 있는 모습 !
프로세스는 3개인데 동일한 프로그램이라고 해보자
3개 프로세스를 3번 실행함.
동일한 프로그램이 프로세스 3개를 만들고 있으면
프로그램의 코드는 똑같다.
문서 1 편집
문서 2 편집
문서 3 편집
코드는 똑같은데 데이터가 다른것이다.
프로세스가 다르기 때문에 동일한 코드를 갖다가 물리적 메모리에다가 각각 올리면 동일한 코드가 여러번 올라가니까 메모리가 낭비 된다.
=> 이런 이유로 shared pages가 필요 !
shared page

shared 코드를 담는 페이지는 여러 카피를 올리지 않고 똑같은 기계어니까 메모리에 한 카피만 올리고 공유를 하자 !
제약조건 2개
1) read-only로 되어있어야 한다. 3번 4번 6번은 read only로 세팅
2) 3개 페이지는 동일한 logical address 위치에 있어야 한다.
일단 physical address에는 일단 mapping은 되어 있다.논리적인 주소가 같아야 한다는건? 페이징 기법이니까 페이지 번호가 같아야 한다는 것과 같음.
왜 이런 조건이 붙나?
=> 요 안에 있는 기계어가 바뀌면 안되고 그 안에 있는 논리적 주소도 바뀌면 안된다.

지금까지 페이징 기법을 마무리
: 프로세스의 주소공간을 동일 크기의 페이지로 잘라서 물리적 메모리에 올렸다.
segmentaition
: 의미 단위로 잘라서 물리적 메모리에 서로 다른 위치에 올린다.
프로세스를 구성하는 주소공간을 코드, 데이터, 스택이라고 하면은 코드 segment 하나, 데이터 segment 하나, 스택 segment 하나 이런 식으로 주소 공간이 담고 있는 의미를 기준으로 주소공간을 자르고 각각의 segment는 물리적 메모리의 서로 다른 위치에 올리는 방법이다.
잘려진 segment의 크기가 다 다르게 된다. 따라서 물리적 메로리를 페이지 하나를 담을 수 있는 동일한 크기의 프레임으로 잘라가지고 관리할 수 없게 된다.
페이지 테이블이 있듯이, segment page table이 있다. 비슷한 측면이 있지만, 차이가 있는데 그걸 설명해줄게 ~~~


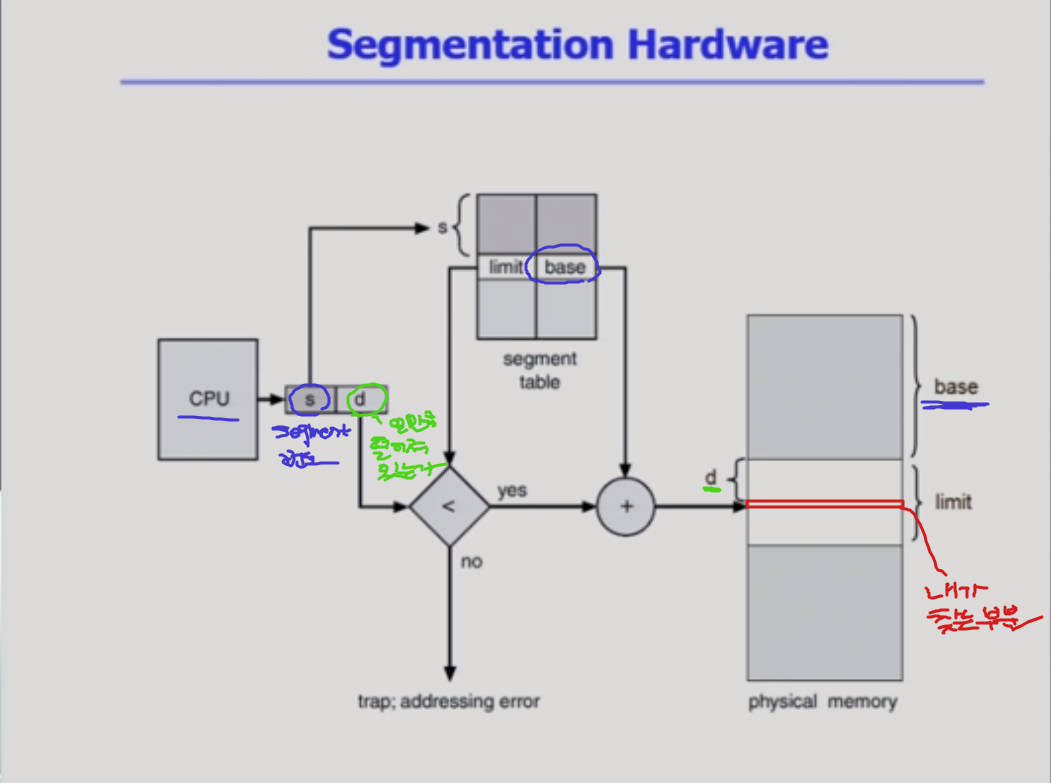
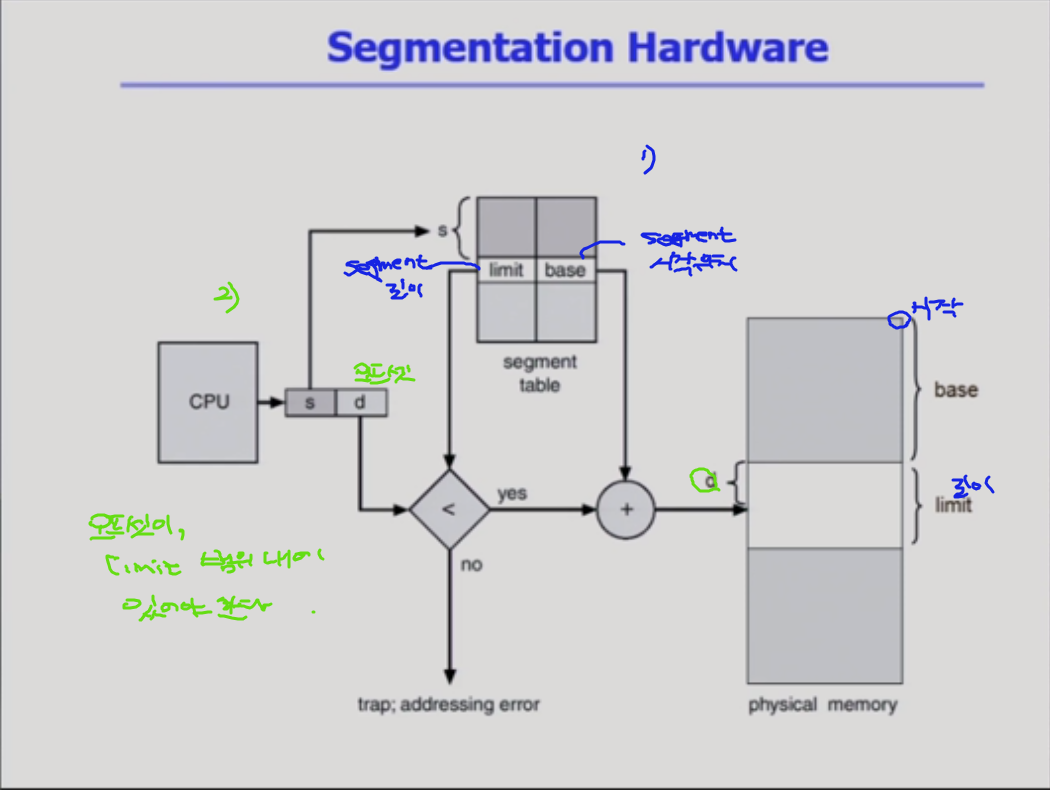
paging 기법하고는 다르게 segmentation 기법에서는 segment 테이블이, segment의 시작위치만 담고 있는게 아니고 각각의 entry 들이 시작위치 외에 하나의 정보를 더 담고 있다. 그건 바로 segment의 길이. paging기법에서는 그게 필요가 없었다. 왜? 어처피 페이지라는건 길이가 다 똑같으니까 필요가 없다.
2) 그리고, 주소변환을 할 때 무조건 시작위치를 d만큼 떨어진 그 위치로 주소변환을 해줘서 될게 아니고, 불순한 메모리 접근 (자기 segment에서 벗어나는 곳에 접근)을 하려고 하면 trap을 걸어서 메모리 접근을 막아야 한다.

주소변환을 위해서 레지스터 2개가 제공되고 있다.
(베이스 레지스터, limit 레지스터) 연속 할당에서는 이 두개 레지스터로 주소변환을 했는데 ! 페이징 기법에서는 페이지 테이블 안에서 주소변환을 하면서 페이지 시작위치와, 길이를 담는 역할로 레지스터를 사용했다. segmentation 기법도 비슷하다 ~~
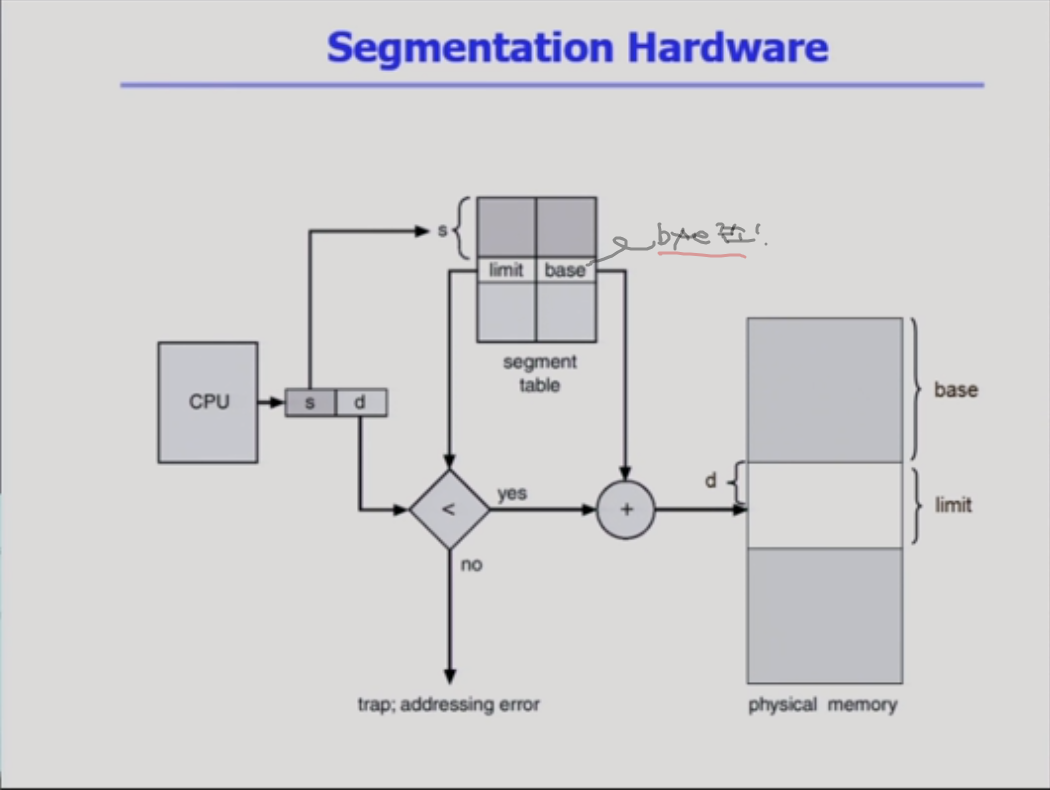
segmentation은 길이가 균일하지 않고, byte 단위도 다 다를 수 있기 때문에 여기 segment의 시작위치를 가지고 있는 base 값은 byte 주소가 된다. 물리적 메모리에서 몇번째 위치냐 이게 아니고 !
=> 연속할당 방식에서 나타났던 문제, 빈 홀이 프로세스 크기보다 작으면, 프로세스가 못들어가는 문제가 segmentation 기법에서도 생긴다 !

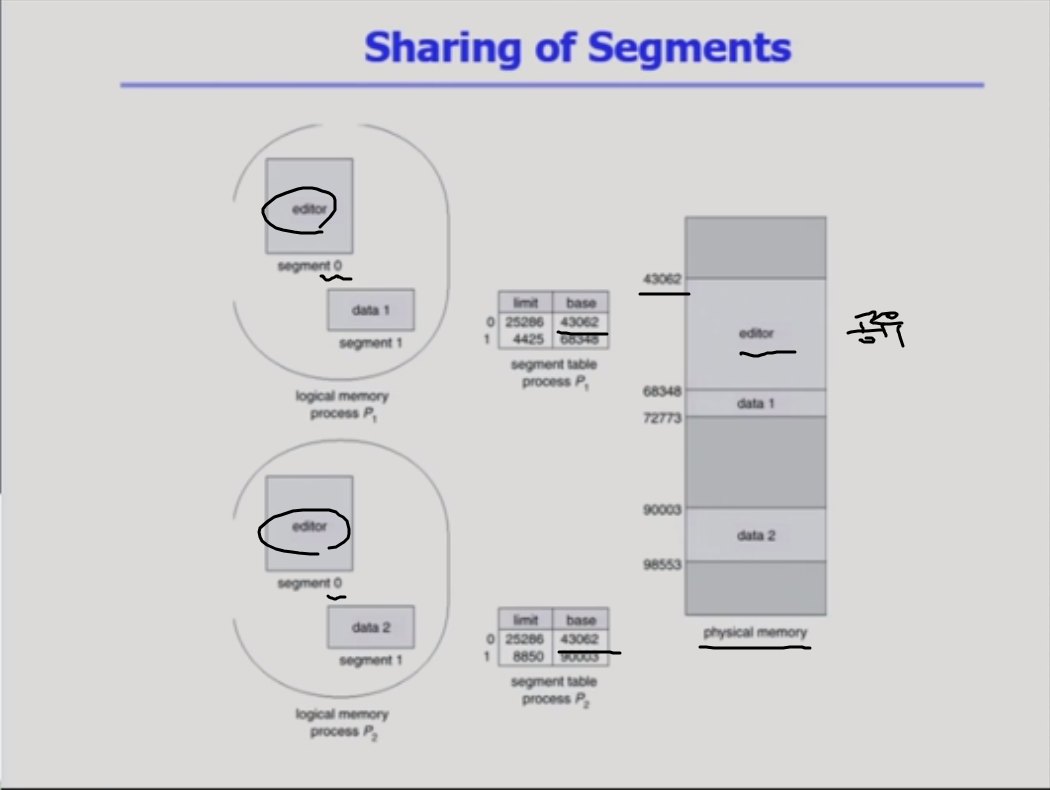
sharing of segments
segment의 공유도 페이지 공유와 비슷하다.
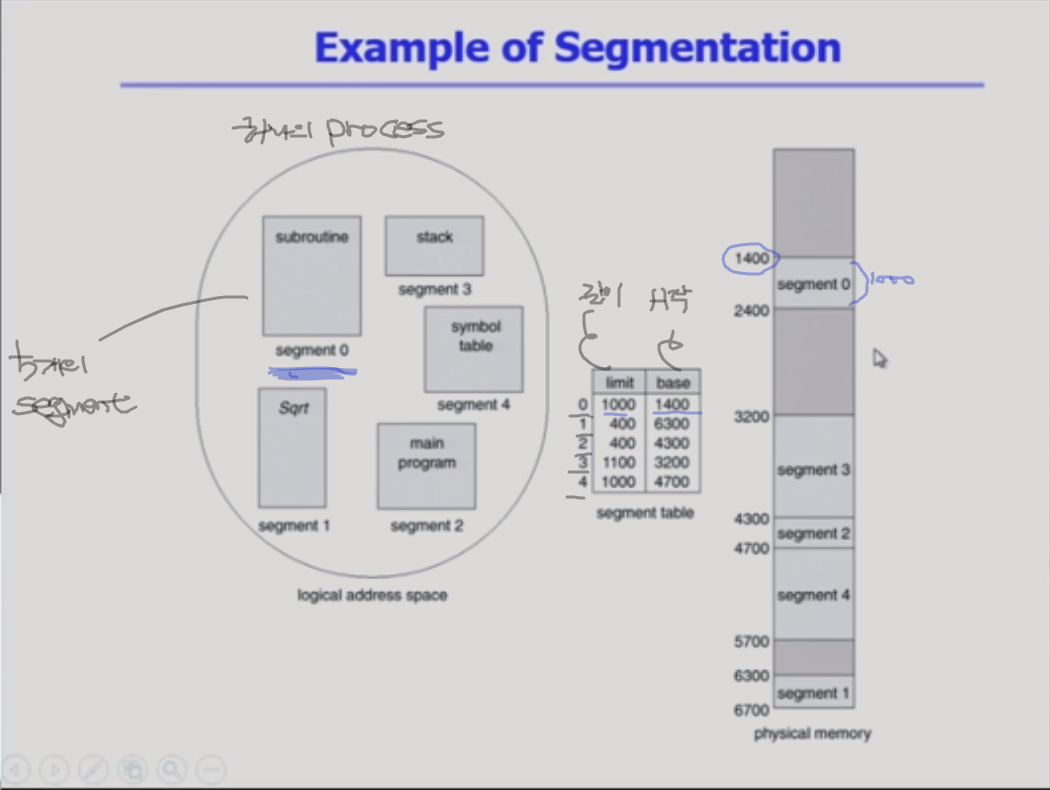
할당문제에서 보면, 페이징 기법이 유리하고
공유/ 보안에서 보면, segment 기법이 유리하지만
구현에서는 또 다른 이슈가 있다..
segmentation은 프로세스 하나를 구성하는 segment가 많지 않다. 코드, 데이터, 스택, 뭐~ 함수 여러개로 나눠봐야 몇개 안된다.
근데 페이징 기법은 100만개 이렇게 된다. 현실적인 구현 문제에서 보면 메모리 공간 낭비는 페이징 기법이 훨씬 심하다.
그렇다고 segmentation 을 pure 하게 쓰지도 않는다.
실제로는 페이징 기법을 근간으로 해서 사용한다.
실제 segmentation을 쓰면 페이징기법과 혼합해서 쓴다.

segmentation with paging
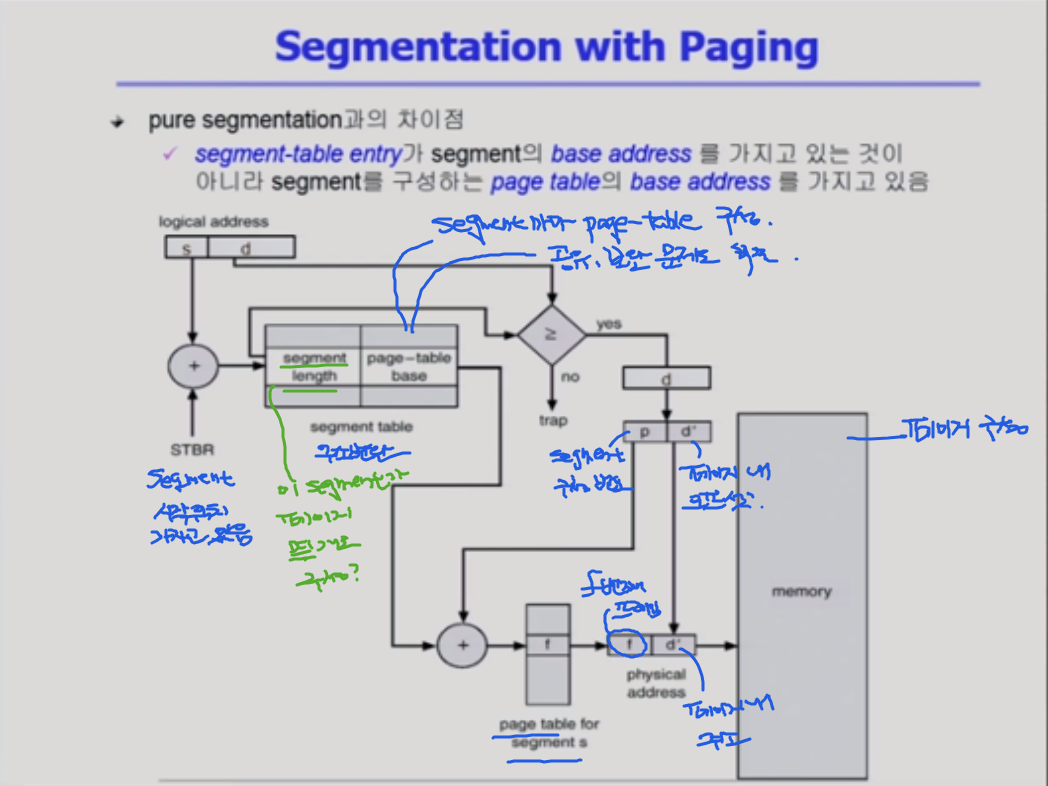
segment가 각각 물리적 메모리에 연속해서 올라가는게 아니고, segment가 여러개의 페이지로 구성된다. segment 크기가 페이지 크기의 배수가 된다. 1번 segment는 페이지 3개로,, 2번 se는 페이지 5개로
