컬렉션 프레임워크
컬렉션 프레임 워크란?
- 프로그램에 필요한 자료구조와 알고리즘을 구현해 놓은 라이브러리
- 자료구조와 알고리즘은 데이터들을 어떤 구조로 관리했을 때 가장 효율적인 알고리즘을 적용해서 최적의 퍼포먼스를 보일 것인 것에 대한 내용.
- 이 부분은 강사님이 애매하게 설명해주셔서 보충이 필요할 것 같다
- 확실한건 자료구조와 알고리즘이 연관되어 있다는 것 같다
- 자료구조와 알고리즘은 데이터들을 어떤 구조로 관리했을 때 가장 효율적인 알고리즘을 적용해서 최적의 퍼포먼스를 보일 것인 것에 대한 내용.
- java.util 패키지에 구현되어 있음
- 컬렉션 프레임워크를 사용함으로 개발에 소요되는 시간을 절약하고 최적화된 라이브러리를 사용할 수 있다
- 크게 Colletion 인터페이와 Map 인터페이스로 구성되어 있다
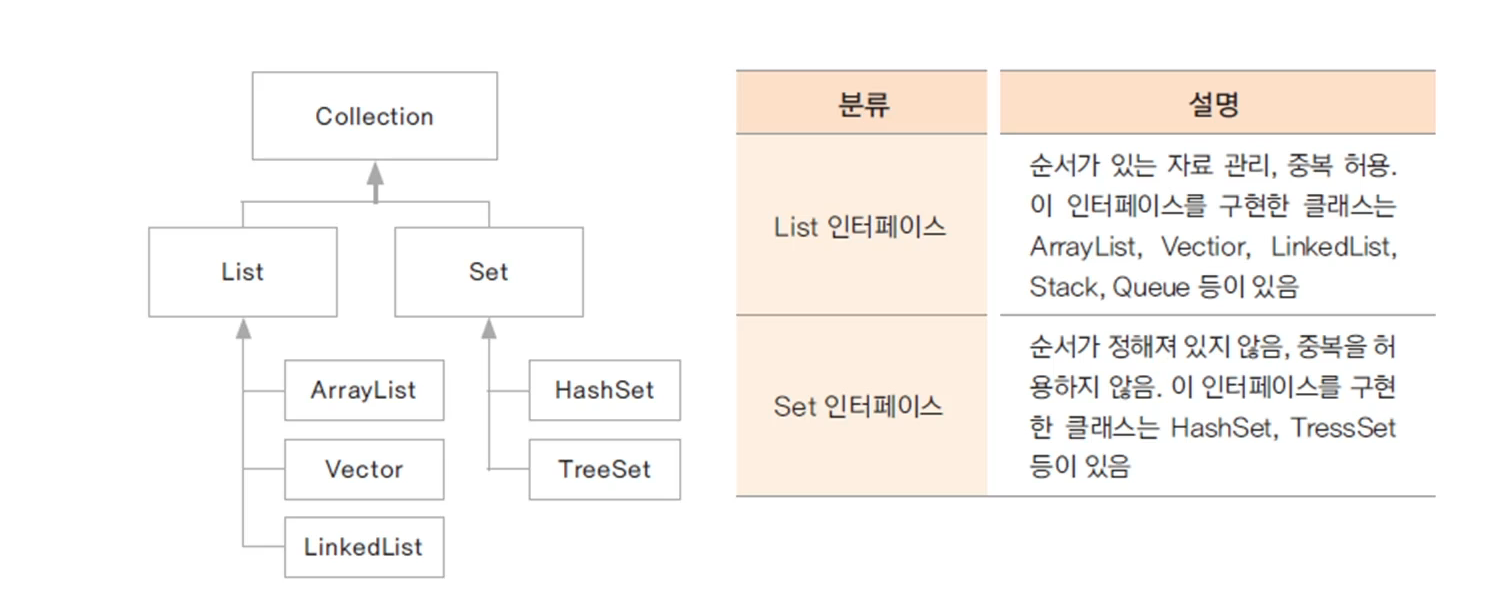
Colletion 인터페이스
-
하나의 객체의 자료구조를 관리를 위해 선언된 인터페이스로 필요한 기본메서드가 선언되어 있다
-
하위에 List인터페이스와 Set인터페이스가 있다
- 이러한 구조를 알아 두면 나중에 사용할 때 도움이 된다
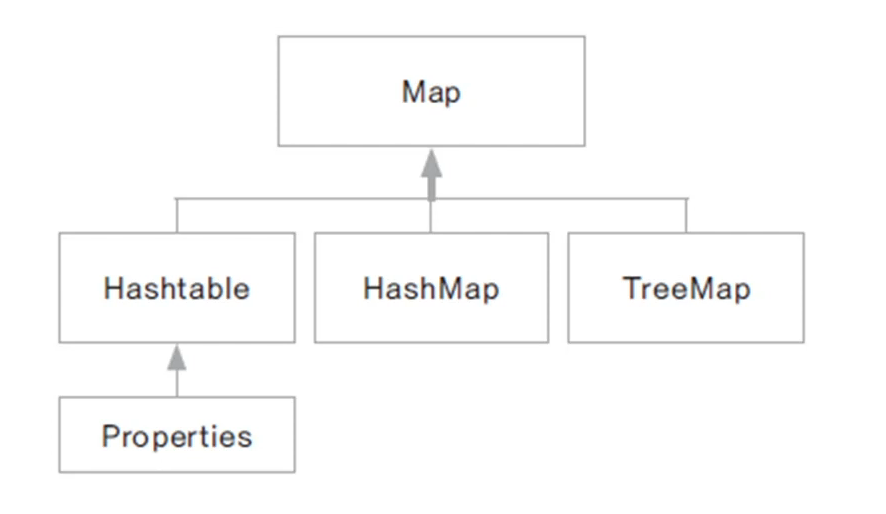
Map 인터페이스
- 쌍으로 이루어진 객체를 관리하는데 필요한 여러 메서드가 선언 되어 있다
- Colletion은 하나, Map은 쌍이니까 두개!
- Map을 사용하는 객체는 Key - Value 쌍으로 되어 있고 Key는 중복될 수 없지만 Value는 중복이 가능하다
자료구조에 대한 전반적인 설명
본격적으로 컬렉션 프레임 워크에 대해 진도에 이해를 더하기 위해 전반적인 자료구조에 대한 설명
- 배열은 선형 자료구조, 논리적인 구조와 물리적인 자료구조가 동일한 형태
- 장점 : 인덱스로 값을 찾기가 편함
- 단점 : 중간에 자료가 빠지면 메모리를 앞으로 땡겨오는 작업필요, 배열의 크기가 정해져있다
- 얘를 구현해 놓은 애가 ArrayList와 Vector, 근데 ArrayList가 최적화 되어있기 때문에 전자 쓰면된다
- Linked List - 논리적으로는 선형으로 되어있지만 물리적인 위치는 동떨어진 형태
- 장점 : 중간에 자료가 빠져도 링크만 조정해주면됨, 크기가 정해져 있지 않다
- 단점 : 인덱스로 찾으려면 첫번재부터 링크를 따라 찾아야 된다
- LikendList 라이브러리 제공된다
- 스택(Stack) 구조
- LIFO: last in first out의 준말
- push()가 자료 입력 pop()이 자료 꺼내는 메서드
- 큐(Que )
- FIFO : first in first out 의 준말
- 자료 앞쪽을 fornt 뒤족을 rear라고 한다
- 자료 입력을 enqueue()라고 하고 자료 출력을 dequeue()라고 한다
- has 구조
- 검색을 위한 자료 구조
- hash(key) 를 입력하면 index로 활용된다. 이 때 key는 중복되지 않는
- index를 넣는 방식이 산술 연산으로 계산이 빨라 검색이 빠른 장점이 있다
- 그렇기 때문에 검색을 위한 알고리즘으로 사용된다
- 바이너리 트리
- 페런트 아래 차일드가 두개보다 작거나 같을 구조를 바이너리 트리라고 한다
- 우리가 배울 바이너리 서치트리는 검색을 위한 트리로 데이터가 들어가는 노드에 중복되지 않는 데이터를 입력하는데 비교 조건에 의해 나보다 작은값은 레프트 차일드에 넣고 나보다 큰값은 라이트 찰이드에 넣는다

배우는 개발 일기