❗ 개인적으로 공부했던 내용을 복습하고 정리하기 위한 글입니다! 따라서 내용이 정확하지 않을 수 있습니다!
📚 Collection
만약 콜렉션이 없다면 실무에서 개발하기 너무너무 어려울 것이다. 일일히 구현을 하나씩 전부 해줘야하고, 그 구현하는데 시간 다 까먹고...

그래서 자바에서는 콜렉션을 제공한다. 자바에서의 콜렉션은 자료구조를 내장하고 있는 프레임워크이다. 그래서 우리는 스택, 큐, 정렬등을 직접 구현 안 하고도 손쉽게 가져다 쓸 수 있다.
또한 배열은 하나의 타입의 데이터들만 저장 가능하고, 한 번 지정된 크기는 변경이 불가능하고, 배열 중간에 위치한 데이터를 추가하거나, 중간에 새로운 데이터를 삭제하려면 기존의 데이터를 뒤로 밀거나, 앞으로 당겨서 사용해야 하는 불편함이 있다.
반면 콜렉션을 이용하면 여러 타입의 데이터들을 한번에 저장 가능하고(물론 제네릭을 이용해 하나의 타입에 대해서만 데이터들을 저장 할 수 있다.), 크기에 제약이 없으며, 중간에 값을 추가하거나 삭제할 때 데이터를 이동할 필요없이 메소드를 호출해서 사용이 가능하다는 장점이 있다.
그렇다고 무조건 배열을 지양하자, 하고자 하는 건 아니다. 방대한 데이터들을 저장만 하고 조회의 목적으로만 사용한다. 반면 컬렉션은 이런 방대한 데이터들을 추가, 수정, 삭제할 경우에 사용한다.
List 계열
List계열은 담고자 하는 값(Value)만 저장하고, 저장 시 순서(Index)를 유지, 중복값을 허용한다. List 계열이 예시로는 ArrayList, LinkedList, Vector가 있다. 여기에서는 가장 많이 사용하는 ArrayList 사용법에 대해 알아볼 것이다.
ArrayList
우선 표현법은 다음과 같다.
ArrayList list = new ArrayList(int size);여기서 ArrayList의 사이즈는 생략이 가능하다. 또한 만약 ArrayList의 사이즈를 3으로 지정하고, 만약 크기가 3을 벗어날 경우, 자동으로 크기가 늘어난다.
또한, 하나의 데이터 타입이 아닌 여러 종류의 타입을 담을 수 있다. 아래에 예시로 Music.java라는 클래스를 만들고, 이 클래스를 통해 만든 객체와 다른 데이터를 ArrayList에 담아 보는 예제이다. 데이터를 추가할 때에는 add()메소드를 사용하면 된다.
// Music.java
public class Music {
private String title;
private String artist;
public Music() {
super();
}
public Music(String title, String artist) {
super();
this.title = title;
this.artist = artist;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getArtist() {
return artist;
}
public void setArtist(String artist) {
this.artist = artist;
}
@Override
public String toString() {
return "Music [title=" + title + ", artist=" + artist + "]";
}
}
//ArrayListRun.java
public class ArrayListRun {
public static void main(String[] args){
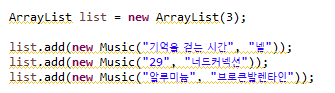
ArrayList list = new ArrayList(3); // 크기가 3인 ArrayList형의 list 생성
// add()메소드를 통해 list에 데이터 추가
list.add(new Music("기억을 걷는 시간", "넬"));
list.add(new Music("29", "너드커넥션"));
list.add(new Music("알루미늄", "브로큰발렌타인"));
System.out.println(list);
}
}[Music [title=기억을 걷는 시간, artist=넬], Music [title=29, artist=너드커넥션], Music [title=알루미늄, artist=브로큰발렌타인]]toString()메소드가 오버라이딩 되어 잘 출력됨을 확인할 수 있다. 그러면 이 출력된 객체에서 첫번째에 저장된 노래제목 title만 뽑아내고 싶으면 어떻게 해야할까? 우선 ArrayList의 get()이라는 메소드가 있다. 이 메소드는 인덱스 번호를 매개변수로 하여, 해당 인덱스의 데이터를 반환하여 준다. 그러면 위의 코드에선 Music 타입의 객체 하나만 반환되니, 참조 연산자로 getTitle()을 하면 되겠지. 했지만...
System.out.println(list.get(0).getTitle());위와 같이 작성하면 빨간줄이 그어지며 오류가 난다. 오류 메세지에는 The method getTitle() is undefined for the type Object라고 적혀있다. Object클래스에 정의되지 않은 메소드를 사용하려 했기 때문에 오류가 났다. 그럼 간단하다. 모든 클래스는 Object클래스를 상속받고 있기 때문에, 다운캐스팅을 통해 강제 형변환을 해주면 될 것이다.
System.out.println(((Music)list.get(0)).getTitle()); // 연산자 우선순위에 주의하자. 괄호로 묶지 않으면 오류가 난다.여기서 하나의 의문점은, 분명 Music객체가 반환될텐데 Object객체로 반환되었다는 점이다. 이것은 우리가 처음 list를 만들 때 제네릭으로 만들지 않아서이다. 해당 관련 내용은 아래 Generic에서 서술할 것이다.
이외에도 다양한 메소드가 이미 구현되어 있다. 리스트의 부분만 추출해서 새로운 리스트를 만들어 반환하는 subList(), 리스트가 비어있는지 확인해주는 isEmpty(), 현재 리스트의 사이즈를 반환해주는 size()등이 있다.
Set 계열
Set계열은 저장하고자 하는 값만 저장하고, 저장 시 Index개념을 무시하며(저장 순서를 보장해주지 않는다.), 중복값을 허용하지 않는다. Set계열의 대표적인 자료구조인 HashSet에 대해 알아보고자 한다.
HashSet
HashSet의 표현은 아래와 같이 한다.
HashSet 객체이름 = new HashSet();
// HashSet<String> hs = new HashSet<String>(); 당연히 제네릭으로 선언해도 된다.또한 HashSet의 사용은 ArrayList와 비슷하게 사용한다. Hash에 데이터를 추가하기 위해서 add()메소드를 사용한다.
HashSet<String> hs = new HashSet<String>();
hs.add("문자열 입니다.");
hs.add("중복 데이터 입력");
hs.add("중복 데이터 입력");
System.out.println(hs);위에 서술한 것 처럼 중복값을 허용하지 않는다를 확인하기 위해서 중복값도 추가한 뒤 출력해 본다.
[문자열 입니다., 중복 데이터 입력]"중복 데이터 입력"문자열은 중복된 데이터기 때문에 두번 추가되지 않고, 한 번만 추가되었다. 그렇다면 아래와 같이 객체를 추가하여 출력해보면 어떻게 될까?
HashSet<Music> musicSet = new HashSet<Music>();
musicSet.add(new Music("기억을 걷는 시간", "넬"));
musicSet.add(new Music("중복된 노래", "중복된 가수"));
musicSet.add(new Music("중복된 노래", "중복된 가수"));
System.out.println(musicSet);[Music [title=중복된 노래, artist=중복된 가수], Music [title=기억을 걷는 시간, artist=넬], Music [title=중복된 노래, artist=중복된 가수]]
// 저장 순서는 보장되지 않았다. 
분명 위의 설명 대로라면, 같은 값을 가진 데이터가 들어가면 안 될 텐데... 중복값이 놀랍게도 들어갔다! 그 이유는 다음에 있다.
HashSet은 값이 추가될 때마다 equals()와 hashCode()로 비교 후 두 개의 결과가 모두 true일 경우에만 동일 객체로 취급한다.
따라서 같은 값을 가진 객체더라도, 다른 주소를 참조하고 있기 때문에 false가 반환되어 HashSet이 다른 객체로 취급하기 때문에 중복값이 들어가는 것처럼 보인다. 먼저 이것들을 equals()와 hashCode() 메소드로 출력해 보았다.
Music m1 = new Music("중복된 노래", "중복된 가수");
Music m2 = new Music("중복된 노래", "중복된 가수");
System.out.println(m1.equals(m2));
System.out.println(m1.hashCode());
System.out.println(m2.hashCode());false
118352462
1550089733이 두 메소드는 최상위 클래스 Object클래스에 정의되어 있다. 그러나 상식적으로, 같은 값을 입력했는데 주소가 달라 다른 객체로 판단이 되어 HashSet에 들어가면 조금 곤란한 일이 생길수도 있다.(중복을 허용하면 안 되는데 중복값이 들어간다거나...) 따라서 우리는 이 두 메소드를 toString()메소드처럼 오버라이딩 하여 사용되는 것이 권장된다.
@Override
public int hashCode() {
final int prime = 31; // 소수 중 적당히 큰 수인 31을 prime로 쓴다고 한다.
int result = 1;
result = prime * result + ((artist == null) ? 0 : artist.hashCode());
result = prime * result + ((title == null) ? 0 : title.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Music other = (Music) obj;
if (artist == null) {
if (other.artist != null)
return false;
} else if (!artist.equals(other.artist))
return false;
if (title == null) {
if (other.title != null)
return false;
} else if (!title.equals(other.title))
return false;
return true;
}다행이도 이클립스 기준 자동완성을 지원한다! 그럼 이 상태로 다시 equals()와 hashCode()를 출력해 보자.
true
2038544073
2038544073오버라이딩하니 값이 출력 값이 바뀌었다! 따라서 오버라이딩 후에 이 두 객체를 HashSet에 추가하면 중복값으로 인식되어 하나만 들어가게 된다.
musicSet.clear(); // 먼저 hashSet을 초기화 해 주었다.
musicSet.add(m1);
musicSet.add(m2);[Music [title=중복된 노래, artist=중복된 가수]]
Map 계열
Map계열은 key와 value가 하나의 세트로 저장이 되는 자료구조이다. Map은 저장 시 순서 유지가 안 되고, 중복 key도 허용이 안 되지만, 중복 값은 허용이 된다. Map의 대표적인 예시로는 HashMap과 properties가 있다.
HashMap
먼저 HashMap은 다음과 같이 사용한다.
HashMap<key, value> 이름 = new HashMap<key, value>();HashMap은 List, Set과는 다르게 put()을 통해 데이터를 추가한다.
// 먼저 Music 객체 3개를 만든 후
Music m1 = new Music("기억을 걷는 시간", "넬");
Music m2 = new Music("29", "너드커넥션");
Music m3 = new Music("알루미늄", "브로큰발렌타인");
// HashMap을 만든 후
HashMap<String, Music> hm = new HashMap<String, Music>();
// HashMap에 put()을 통해 Music객체 3개를 넣고
hm.put("1번", m1);
hm.put("2번", m2);
hm.put("3번", m3);
// key값은 다르게 넣고 같은 값을 넣은 후
hm.put("4번", m1);
// 출력하였다.
System.out.println(hm);{4번=Music [title=기억을 걷는 시간, artist=넬], 3번=Music [title=알루미늄, artist=브로큰발렌타인], 2번=Music [title=29, artist=너드커넥션], 1번=Music [title=기억을 걷는 시간, artist=넬]}특히 4번 key에 같은 m1객체를 넣었는데도 제대로 동작이 되는 걸 알 수 있었다.
데이터를 가져오려면 get(key)를 하면 된다. 여기서 주목해야 할 점은, key값을 통해 데이터를 가져온다는 점이다.
System.out.println(hm.get("1번"));Music [title=기억을 걷는 시간, artist=넬]그런데 우리가 이 HashMap에 있는 데이터들에 순차적으로 접근하고 싶을 때는 어떻게 해야할까? 인덱스가 없기 때문에 for문을 쓸 수도 없는 노릇이다. 그 때, 우리는 Iterator을 사용하는 것이다. Map계열을 Set계열로 바꾼 뒤 출력하는 것인데, 이에 대한 사용법은 다음과 같다. 첫번째, key들의 값을 Set에 담는다. 두번째, 만들어진 Set의 데이터들을 Iterator에 담는다. 마지막으론 Iterator로부터 반복문을 이용해서 순차적으로 key와 value의 값을 출력한다.
Set<String> keyset = hm.keySet();
Iterator<String> itKey = keyset.iterator();
while(itKey.hasNext()) {
String key = itKey.next();
System.out.println(key + "-" + hm.get(key));
}3번-Music [title=알루미늄, artist=브로큰발렌타인]
2번-Music [title=29, artist=너드커넥션]
1번-Music [title=기억을 걷는 시간, artist=넬]또 다른 방봅으로는 entrySet()을 이용하는 방법이다. 먼저 Map에 있는 key와 value세트를 Entry형식으로 Set에 담는다. 그다음 반복문을 통해 출력해 준다.
Set<Entry<String, Music>> entrySet = hm.entrySet();
for(Entry<String, Music> e : entrySet) {
System.out.println(e.getKey() + "-" + e.getValue());
}3번-Music [title=알루미늄, artist=브로큰발렌타인]
2번-Music [title=29, artist=너드커넥션]
1번-Music [title=기억을 걷는 시간, artist=넬]Properties
Properties는 Map계열 중 하나의 자료구조이며, key값과 value값을 세트로 저장한다. 또한 key값과 value의 값을 String형으로 다룬다. 표현법은 다음과 같다
Properties 이름 = new Properties(); //객체를 생성하듯 생성한다.예제는 다음과 같다.
Properties prop = new Properties();
// prop객체에 데이터 추가
prop.setProperty("List", "ArrayList");
prop.setProperty("Set", "HashSet");
prop.setProperty("Map", "HashMap");
try {
// store(OutputStream os, String Comments)
// 파일을 기록할 때 쓰는 메소드
// key = value 형태로 파일이 출력된다.
prop.store(new FileOutputStream("song.properties"), "Properties Test");
// try-catch문이 없으면 오류 발생!
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}이 후 프로젝트를 새로고침하면 song.properties 파일이 생성된 것을 확인할 수 있다.
파일이 생성되었고,
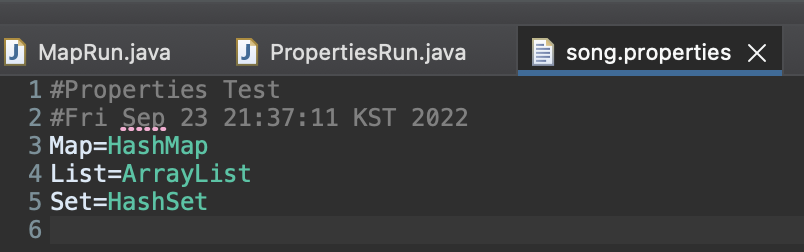
해당 파일을 클릭하면 다음과 같은 값들이 저장된 것을 확인할 수 있다.
Properties의 용도는 파일 입출력을 하기 위함이다. 주로 파일로부터 읽어오는 용도로 많이 사용되고, properties확장자를 많이 사용한다. 프로젝트에서는 자주 변경되지 않는 설정 파일이나, 해당 프로그램이 기본적으로 가져야할 정보들을 담는 파일로 많이 사용된다.
🛠 Generic
제네릭은 컬렉션 안에서 다룰 타입들을 미리 지정해주는 역할이다. 사실 우리가 위의 방법대로 컬렉션을 생성하면 노란 밑줄이 생길 것이다. 오류는 아니고, IDE에서 경고 메시지를 보내주는 건데...
이 이유는 컬렉션을 제네릭으로 생성하지 않아서이다. 제네릭을 사용하지 않았다면 컬렉션 객체 생성 시 다양한 타입이 담길 수 있다. 물론 이는 컬렉션의 장점이다. 다양한 데이터 타입을 담으려고 사용하는 이유도 있지만, 내 의도와는 다르게 다른 데이터 타입이 들어갈 수도 있다. 그래서 이를 막기 위해 컬렉션을 제네릭 타입으로 생성하는 것이다. 또한 위에서 이름을 하나 얻기 위해 getTitle()을 하였는데, 이를 하기 위해 다운캐스팅을 해주었다. 한 줄이야 쉽지만... 매번 이런다면 정말 귀찮을 것이다. 따라서 제네릭은 매번 형변환하는 절차를 없애기 위해서도 사용한다.
제네릭은 다음과 같이 사용한다.
ArrayList<Music> list = new ArrayList<Music>();이렇게 되면, 해당 컬렉션은 Music 타입으로만 사용 가능하다. 또한 이렇게 하면 위에 서술했듯이 다운캐스팅을 할 필요가 없어진다.
System.out.println(list.get(0).getTitle()); //형변환을 안 해도 오류가 안 난다!✔ 마치며
학부생 시절 자료구조를 낑낑대며 C언어, 특히 포인터를 사용하면서 구현했던 기억이 많이 난다. 배열이고, 링크드리스트고, 스택이고, 큐고... 잠시 악몽이 떠올랐지만, 친절하게도 자바는 이러한 기능들을 콜렉션으로 구현해 두었다! 그러나 이걸 막 가져다 쓰는 건 중요하지 않다. 물론 어느 상황에 어느 자료구조를 사용하고, 어느 메소드를 이용하는 건 중요할 것이다. 하지만 내가 중요하게 생각하는 건 이 자료구조들이 어떤 원리로 동작하는지이다. 어떠한 구조로 저장되고, 어떻게 구현이 되는지 공부하면 좋을 것 같다는 생각이 들었다. 아마 지금 당장은 아니지만 나중에 있을 취업준비, 특히 코딩 테스트에서 유용하게 쓰일 것이다.
끝!🤓
