트리로 정말 많은 자료구조를 구현할 수 있다.

귀여운 크리스마스 트리다. 자료구조 트리는 이러한 나무의 형태와 비슷하다.
Heap
Heap을 쉽게 표현하자면 순서가 있는 리스트이다. 이것은 내가 트리를 공부하기 전에 힙을 이해했던 방식이다. 실제로 리스트의 인덱스에서, 내 인덱스 * 2는 왼쪽 자식, * 2 한거에 +1하면 오른쪽 자식이라고 정의한다.
순서가 있다는 것은 무슨 이야기일까?
항상 정렬되어 있다!
요소를 추가해도, 삭제해도 항상 heap은 요소들 간의 순서를 질서정연하게 유지한다.
트리로 어떻게 구현하는가?
완전 이진 트리 형태 + 힙 속성인 부모 노드가 두 자식 노드의 데이터보다 크거나 같다 를 지켜주면 된다.
즉 왼쪽 자식이 다 채워진 트리 (완전 이진 트리)에서 힙 속성을 지켜주면 된다.
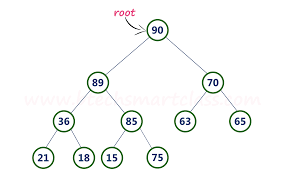
왼쪽 자식이 오른쪽 자식보다 크거나, 작아야 한다는 규칙 같은 것이 없다.
그럼 정렬은 어떻게?
트리 자체에서 정렬을 하는 것이 아니다.
- 우선 root 노드가 노드들 중 가장 큰 노드임을 전제하고
- root 노드를 마지막 노드와 바꾸어준다.
- 그리고 2번 과정 이후 힙 속성을 어기게 되므로 다시 heapify로 기존의 root 노드를 제외한 노드들 중 가장 큰 노드를 새로운 root 노드로 정의한다.
- root 노드와 바꿔치기 해줄 노드가 남아있지 않을 때까지 2, 3번 과정을 계속 반복한다.
[None, 1, 1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 10]이런 결과물이 나온다. 시간복잡도는 O(nlg(n)) (높이에 비례 * 노드 n개만큼 반복)
삽입의 시간복잡도
삽입은 맨 뒤 인덱스에 삽입하여, 힙 속성을 어기지 않을 때까지 부모 노드를 타고 타고 올라간다. 최악의 경우에는 O(lg(n)) (높이만큼)
이진 탐색 트리
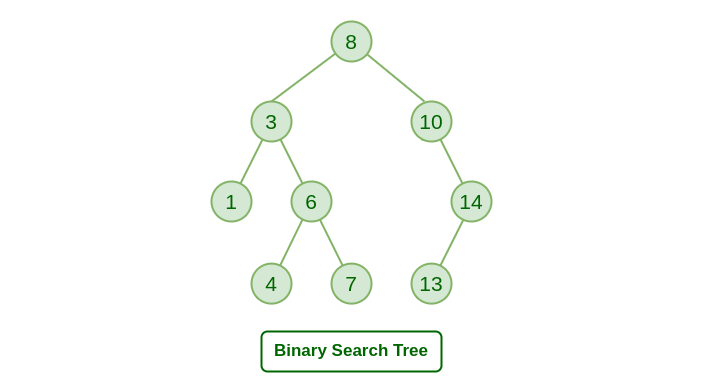
이진 탐색 트리는 힙과는 다른 자료구조이다. 왜냐하면 왼쪽 자식과 오른쪽 자식 간의 순서가 존재하기 때문이다.
부모 노드보다 값이 작으면 왼쪽 자식, 값이 크면 오른쪽 자식!
이런 간단한 규칙으로 트리를 만들 수 있다.
이진 탐색 트리는 딕셔너리와 세트를 구현할 때 사용된다고 한다.
삽입과 삭제, 탐색
탐색에는 최악의 경우보다는 평균적인 시간복잡도를 고려한다. 높이에 비례하여 평균적으로 O(lg(n))이 걸린다고 한다.
삽입은 순서를 어기지 않도록 높이에 비례하여 root 노드와 비교한다. 왼쪽 자식 혹은 오른쪽 자식이 비어있으면 추가한다. O(h), 평균적으로 O(lg(n))이 걸린다. (탐색의 과정이 포함되고, O(1)만큼 더 걸려서 사실 탐색이랑 같은 시간복잡도이다)
삭제는 경우가 다양하다. 간단하게 말하자면 삭제 연산 역시 높이에 비례하는 연산이다. O(h), 평균적으로 O(lg(n)) (h는 높이)가 걸린다.
해시테이블과의 비교
해시테이블은 모든 연산의 시간복잡도가 O(1)여서 매우 효율적인 자료구조이다. 그렇다면 왜 우리는 딕셔너리를 해시테이블로 구현하지 않고 이진 탐색 트리로도 구현하는 걸까?
해시테이블은 순서가 없는 자료구조이다. 그러나 이진 탐색 트리에는 있다.
순서가 중요한 세트, 딕셔너리 구현에서는 이진 탐색 트리를 고려하는 것도 나쁘지 않은 선택지일 듯 하다.
