
이번 글에서는 여러 ItemWriter의 구현체들에 대해 알아보겠습니다.
ItemWriter는 ItemReader에서 처리한 Item에 대해 다른 형식의 데이터로 변환해 저장하는 역할을 합니다. 예를 들어 ItemReader에서 csv 파일을 자바 객체로 변환했다면, ItemWriter에서는 이 자바 객체를 DB에 저장하는 합니다. 물론 반대도 가능합니다. ItemReader가 DB에서 읽어 자바 객체로 변환해 ItemWriter에서 이를 csv 파일로 쓸 수도 있는 것이죠.
먼저 FlatFileItemWriter에 대해 알아볼텐데요, Item을 csv나 txt 파일로 변환하는 작업을 합니다. 전체적인 개념이나 사용하는 API는 FlatFileItemReader에서 보았던 것과 유사합니다. FlatFilwItemWriter를 사용할 때에는 구분자를 사용해 문자열을 가르는 방식과 고정된 길이로 가르는 두 가지 사용 방식이 있습니다. 그 중 구분자 방식을 먼저 코드로 바로 볼텐데요, ItemReader에서 받은 객체의 필드를 문자열 배열로 변환해 구분자로 자르는 원리로, 내부의 Extract텍스트orLineAggregator 클래스가 이 역할을 합니다.
@Bean
public ItemWriter<? super Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("src/main/resources/customer_writer.txt")) // 생성 파일 경로 + 생성될 파일명 설정
.append(true) // 이어 쓰기 설정 여부. 기본이 false
.shouldDeleteIfEmpty(true) // Reader에서 아무런 파일이 오지 않을 때, 위 리소스의 FlatFile 삭제 여부. 기본이 false
.shouldDeleteIfExists(false) // 동일한 파일이 존재할 때 삭제 여부. 기본이 true
.delimited().delimiter(",")
.names("id", "firstName", "lastName", "birthDate")
.build();
}이전 글에서 사용했던 JpaPagingItemReader를 이용해 DB에서 값을 읽은 다음 FlatFileItemWriter를 사용해보겠습니다.
@Configuration
@RequiredArgsConstructor
public class JobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final String sql3 = "SELECT c FROM Customer c WHERE firstName like :firstName ORDER BY lastName, firstName";
@Bean
public Job batchjob() {
return jobBuilderFactory.get("batchjob")
.start(step1())
.build();
}
@Bean
public ItemReader<Customer> jpaPagingItemReader() {
HashMap<String, Object> parameters = new HashMap<>();
parameters.put("firstName", "A%");
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaCursorItemReader")
.pageSize(10) // 가져올 데이터 갯수
.entityManagerFactory(entityManagerFactory) // EntityManager 설정
.queryString(sql3) // 실행할 jpql문
.parameterValues(parameters) // jpql문 내 인자
.build();
}
@Bean
public ItemWriter<? super Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("src/main/resources/customer_writer.txt")) // 파일 경로 설정
// .append(true) // 이어 쓰기 설정
.shouldDeleteIfEmpty(true) // Reader에서 아무런 파일이 오지 않으면 위 리소스의 FlatFile 삭제
// .shouldDeleteIfExists(false) // 기존 동일한 파일이 있어도 삭제 X
.delimited().delimiter(",")
.names("id", "firstName", "lastName", "birthDate")
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Customer, Customer>chunk(10)
.reader(jpaPagingItemReader())
.writer(flatFileItemWriter())
.allowStartIfComplete(true)
.build();
}
}그 결과, 아래와 같은 txt 파일이 생성되었습니다.
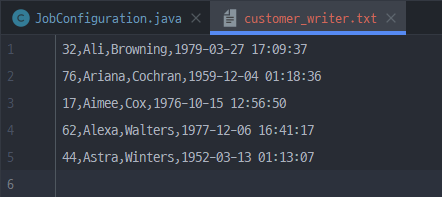
다른 방식인 고정된 길이를 자르는 format 방식을 볼텐데요, 사실 그렇게 효율적인 방식은 아닙니다. 아무래도 고정된 길이로 자르기 때문에 Item 데이터들의 길이가 항상 일정할 때에만 사용해야 한다는 주의점이 있습니다. 간단하게 코드만 보고 넘어가겠습니다.
@Bean
public ItemWriter<? super Customer> delimetedFlatFileItemWriter() {
return new FlatFileItemWriterBuilder<>()
.name("delimetedFlatFileItemWriter")
.resource(new FileSystemResource("src/main/resources/customer_writer.txt")) // 파일 경로 설정
.formatted().format("%-1d%-5s%-10s%-6s")
.names("id", "firstName", "lastName", "birthDate")
.build();
}이제 DB ItemWriter를 알아보겠습니다. 역시 여기에도 JDBC 기반 JdbcBatchItemWriter와 JPA 기반의 JpaItemWriter가 있습니다. 먼저 JdbcBatchItemWriter를 살펴보겠습니다. ItemReader에서 읽어들인 Item을 DB에 저장하는 구현체로, DB를 설정하고 sql문을 날리는 매우 간단한 방식입니다. 코드로 보겠습니다.
@Bean
public ItemWriter<? super Customer> jdcbBatchItemWriter() {
return new JdbcBatchItemWriterBuilder<>()
.dataSource(dataSource)
.sql(sql5)
.beanMapped() // 객체와 그 필드를 DB 테이블과 컬럼에 매핑
.build();
}빌더를 통해 매우 간단하게 구현할 수 있습니다. FlatFile의 경우와 동일하게 ItemReader를 통해 DB에서 값을 읽어와 객체에 매핑한 후, Writer를 통해 DB에 저장하는 전체 코드를 보겠습니다. 보면 beanMapped()라는 API를 사용하는데요, ItemReader에서 받은 객체를 DB의 테이블과 매핑시켜주는 역할을 합니다. 덕분에 매우 간단하게 작업을 할 수 있습니다.
@Configuration
@RequiredArgsConstructor
public class JobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final DataSource dataSource;
private final String sql3 = "SELECT c FROM Customer c WHERE firstName like :firstName ORDER BY lastName, firstName";
private final String sql5 = "INSERT INTO customer2 VALUES (:id, :firstName, :lastName, :birthDate)";
@Bean
public Job batchjob() {
return jobBuilderFactory.get("batchjob")
.start(step1())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Customer, Customer>chunk(10)
.reader(jpaPagingItemReader())
.writer(jdcbBatchItemWriter())
.allowStartIfComplete(true)
.build();
}
@Bean
public ItemReader<Customer> jpaPagingItemReader() {
HashMap<String, Object> parameters = new HashMap<>();
parameters.put("firstName", "A%");
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaCursorItemReader")
.pageSize(10) // 가져올 데이터 갯수
.entityManagerFactory(entityManagerFactory) // EntityManager 설정
.queryString(sql3) // 실행할 jpql문
.parameterValues(parameters) // jpql문 내 인자
.build();
}
@Bean
public ItemWriter<? super Customer> jdcbBatchItemWriter() {
return new JdbcBatchItemWriterBuilder<>()
.dataSource(dataSource)
.sql(sql5)
.beanMapped() // 객체와 그 필드를 DB 테이블과 컬럼에 매핑
.build();
}
}이를 위해 Customer와 동일한 필드를 가진 Customer2라는 엔티티와 테이블을 별도로 생성해주었습니다. 테스트 결과 Customer2 테이블에 담긴 데이터를 보면 아래와 같습니다.
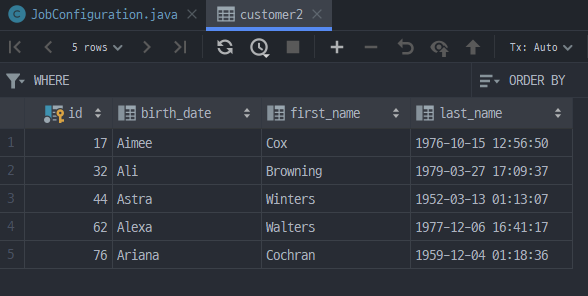
이제 JpaItemWriter를 살펴볼 차례입니다. Jdcb와는 달리 DB가 아닌 EntityManager를 설정해주면 됩니다. 또 별도의 sql문을 사용하지 않습니다. 그 이유는 특정 컬럼에 대한 쿼리가 아닌 엔티티 자체를 영속화 하는 것이기 때문인데요, 또한 Write할 객체는 필수적으로 엔티티로 선언되어야 합니다. JpaItemWriter를 구현하는 코드를 보겠습니다. usePersist() API는 이 대상을 영속화할 것인지 여부를 결정합니다.
@Bean
public ItemWriter<? super Customer2> jpaItemWriter() {
return new JpaItemWriterBuilder<>()
.usePersist(true) // 영속화할 것인지 여부
.entityManagerFactory(entityManagerFactory)
.build();
}이제 ItemWriter를 포함한 전체 코드를 볼텐데요, JpaItemWriter에는 한 가지 주의사항이 있습니다. 읽을 객체와 쓸 객체가 다를 때 발생하는 일인데요, 바로 ItemProcessor가 꼭 필요하다는 점입니다. 그 이유는 바로 Reader에서 읽은 Item을 Item2로 변환하는 과정에서 Item2를 엔티티로 변환해주는 과정이 꼭 필요합니다. 만약 서로 다른 타입으로 읽고 쓸 경우에 ItemProcessor를 사용하지 않으면 PersistentObjectException 예외가 발생하게 됩니다. 사실 이 부분을 계속 테스트해봐도 정확한 이유를 파악하지는 못했습니다. ItemProcessor 없이 단순 타입으로 받는 것과 ItemProcessor를 통해 엔티티 객체를 생성해서 받는 것의 차이인 것으로 보이기는 합니다.
코드로 볼텐데요, step1의 chunk() API를 보면 Chunk<I, O>가 각각 다름을 확인할 수 있습니다.
@Configuration
@RequiredArgsConstructor
public class JobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final DataSource dataSource;
private final String sql3 = "SELECT c FROM Customer c WHERE firstName like :firstName ORDER BY lastName, firstName";
@Bean
public Job batchjob() {
return jobBuilderFactory.get("batchjob")
.start(step1())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Customer, Customer2>chunk(10)
.reader(jpaPagingItemReader())
.processor(itemProcessor())
.writer(jpaItemWriter())
.allowStartIfComplete(true)
.build();
}
@Bean
public ItemReader<Customer> jpaPagingItemReader() {
HashMap<String, Object> parameters = new HashMap<>();
parameters.put("firstName", "A%");
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaCursorItemReader")
.pageSize(10) // 가져올 데이터 갯수
.entityManagerFactory(entityManagerFactory) // EntityManager 설정
.queryString(sql3) // 실행할 jpql문
.parameterValues(parameters) // jpql문 내 인자
.build();
}
@Bean
public ItemProcessor<Customer, Customer2> itemProcessor() {
return new CustomItemProcessor();
}
@Bean
public ItemWriter<? super Customer2> jpaItemWriter() {
return new JpaItemWriterBuilder<>()
.usePersist(true) // 영속화할 것인지 여부
.entityManagerFactory(entityManagerFactory)
.build();
}
}사용한 ItemProcessor의 구현체는 아래와 같습니다. Customer와 Customer2는 동일한 필드를 가진 클래스입니다. ItemReader에서 DB로 부터 데이터를 읽어 Customer 타입의 객체로 매핑합니다. 그런 다음 ItemProcessor에서 Customer 타입의 Item을 Customer2 엔티티로 매핑하는 과정을 거칩니다. 그리고 최종적으로 ItemWriter에서 이 엔티티를 영속화(DB로 저장)하게 되는 것입니다.
public class CustomItemProcessor implements ItemProcessor<Customer, Customer2> {
@Override
public Customer2 process(Customer item) throws Exception {
Customer2 customer2 = new Customer2();
customer2.setId(item.getId());
customer2.setFirstName(item.getFirstName() + "_2");
customer2.setLastName(item.getLastName() + "_2");
customer2.setBirthDate(item.getBirthDate() + "_2");
return customer2;
}
}그리고 Customer2 테이블에 들어간 데이터를 보면 아래와 같습니다.

아무래도 JPA가 곁들어지다보니 개념적으로 복잡한 부분이 생기기도 하는데요, JPA의 엔티티와 영속화 개념을 이해하고 있다면 도움이 될 것 같습니다.
이번 글에서는 여러 ItemWriter 구현체들에 대해 알아보았습니다. 다음 글에서는 ItemProcessor에 대해 알아보겠습니다.
