
0. 목차
- 모델 개요
- 모델 구조
- 모델의 장점과 단점
- 코드 리뷰
1. 모델 개요
transformer의 시초가 된 논문이다. 특히 자연어처리에 자주 쓰인다. 기존 LSTM등 시계열 모델에서 자연어처리를 하려면 인코더-디코더의 복잡한 모델구조와 함께 단어 하나씩 순차적으로 연산해야 했으므로 이는 연산량과 시간이 매우 오래걸린다는 단점이 있다. 그러나 transformer은 attention의 개념을 도입해 RNN과 같은 모듈을 쓰지 않고 하나의 문장 전체를 입력으로 받아(기존에는 단어를 토큰으로 나누어 input으로 집어넣었다.) 한꺼번에 병렬적으로 처리할 수 있게끔 하였다. 즉, 다시말하면 GPU를 효과적으로 사용할 수 있다는 뜻이다.
1-1. S2S와의 비교
시퀀스 투 시퀀스가 성능이 좋은 RNN계열 모델이었으므로 이와 비교가 된다. 간단히 S2S의 모델의 구조와 그 한계점을 살펴보면 다음과 같다.
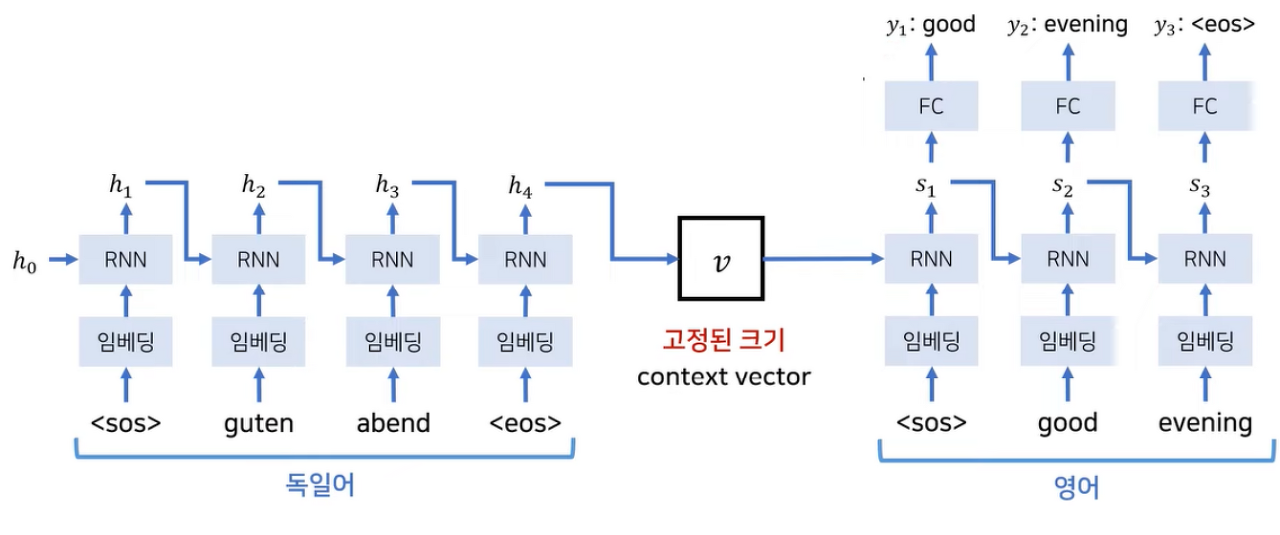
- 토큰을 나누고 토큰 개수만큼 layer를 지나야 한다. 각 layer에서 나온 출력은 기존 RNN처럼 다음 입력을 들어가게 된다.
- 그리고 이를 모아서 고정된 크기의 context vector를 반환하는 것을 볼 수 있는데 앞선 모든 토큰의 정보를 포함하고 있으므로 이 정보가 한데 뭉쳐있기 때문에 decoding시에 개별 토큰과의 관계파악이 어렵다.
- 그리고 순차적으로 정보가 입력되므로 시퀀스가 길어질수록 기울기 소실 문제가 발생한다.
개선점
그러나 attention만을 사용한 transformer는 이런 S2S의 문제를 개선하였다. 우선, 제일 큰 점은 순차적으로 입력하지 않아도 되고 병렬 처리가 가능해 성능이 크게 향상되었다는 점이다.
1-2. attention 개념
attention에는 주로 addictive와 dot이 있는데 본 모델에서는 후자를 사용하였다. 왜냐하면 행렬곱셈 구현이 최적화가 잘되어있어 공간을 많이 절약할 수 있고 계산이 빠르기 때문이다. 그러나 Q와K의 차원이 커질수록 학습이 정상진행되지 않는데 이를 위해 d_k로 스케일조정을 해주는 것이다.
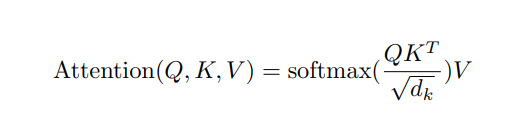
- Q : 쿼리
- K : 키
- V : 밸류
attention이 최종으로 구하는 값은 Q가 가져야할 값이다. K-V는 세트라고 생각하면 편하다. Q가 가져야 할 값을 어떻게 구하게 되냐면 Q와 K의 비교를 통해 구하게 된다. 그러면 K와 V는 세트이므로 K와 Q가 비슷하다면 K의 V를 반환하게 되는 것이다. 둘의 비교는 행렬곱을 통해 비교하게 된다. softmax의 (QKt)부분 이를 d_k로 나눠주는 것은 스케일을 조정해주는 것이다. 이를 attention으로 Energy를 구한다고 하는데 Energy는 softmax() 안에서 계산되어 들어간 Q가 모든 K와 어느정도 유사한지의 비율을 반환하게 된다. 마지막으로 Key의 Value값을 곱해 줌으로써, 최종적으로 Query가 가져야 하는 값을 구할 수 있게 된다.
2. 모델 구조
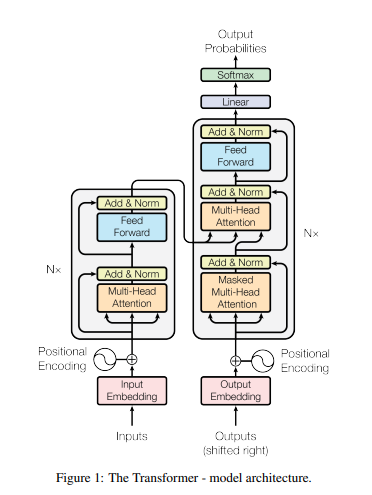
위는 attention을 이용한 transformer의 모델 구조이다. 찬찬히 살펴보도록 하자.
0) multi head attention
in encoder

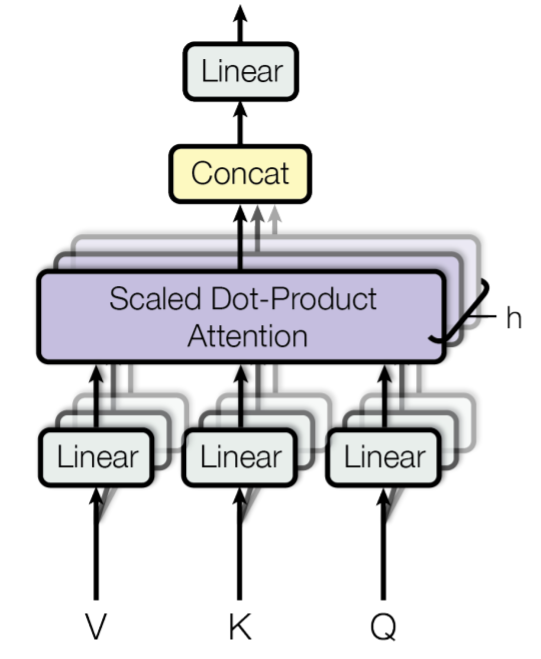
간단히 설명하자면 self-attention을 여러 head에서 실행한 후 concat(합치기)을 한다는 뜻이다. 이 모든 attention에서의 출력을 concat한 뒤에는 linear function을통해 매핑한다. cnn에서 여러개의 필터를 통해서 convolution output을 구하는 것과 비슷하다.
프로세스
- 입력값이 들어오면 V,K,Q가 복제된다. 그 후 그림과 같이 linear layer에서 차원이 변환되는데 임베딩 차원을 V,K,Q의 차원으로 변환한다. 모델 차원과 별개로 K,V,Q의 차원을 각각 결정할 수 있다. 어차피 추후 concat하기 때문에 입출력의 dimension은 같아진다.
- 그 후 앞서 attention의 프로세스에서 확인했던 것처럼 행렬곱을 수행한다.
- linear를 거쳐 output을 최종생산한다.
- 최종적으로 어떤 한 단어(awesome)이 모든 단어(AI, is, awesome)들 중 어떤 단어들과 correlation이 높고, 또 어떤 단어와는 낮은지를 배우게 된다.
in decoder
- 마스킹 실행
- 단어 간의 correlation확률을 뱉어내는 목표는 같다.
- 다만, AR(p)를 보존해야되기 때문에 현재 값에 직접적인 영향을 주는 time series 제한된 벡터만을 참조한다.
in encoder-decoder
- decoder의 sequence vector들이 encoder의 sequence vector들과 어떠한 correlation을 가지는지를 학습한다.
- 이를 위해 Q,K,V 중 일부는 다른곳에서 가져온다.
1) encoder
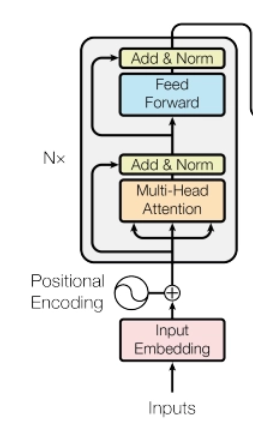
- 6개의 동일한 층으로 구성되어 있다. 여느 RNN처럼 처음 input이 첫번째 층에 들어가고 그 다음층엔 이전층의 output이 들어가는 형태이다.
- 이 6개의 각 층에는 2개의 sub-layer가 있다. 하나는 multi head attention이고 두번째는 단순히 완전 연결된 feed-forward이다.
- 이 2개의 sub layer에는 병목처리(residual connection)을 실행한다. resnet에서 봤던 그 숏컷 그리고 layer normalize를 수행한다.
- 각 sub layer의 출력은 x+sublayer(x)를 normalize한 것이다. residual connection을 용이하게 하기 위해 dim은 512로 설정하였다.
(1) positional Encoding
- RNN을 사용하지 않는 대신 문장 내 포함된 단어들의 위치 정보를 인코딩한다.
- 이때 위치정보는 그 전 layer의 모든 위치정보를 참고한다.
- 해당 위치정보와 모든 위치정보간의 상관관계에 대한 정보를 더해준다.
- input 임베딩과 동일한 dimension으로 합쳐진다.
- 쿼리, 키, 밸류 값으로 각각 복제돼 입력된다.
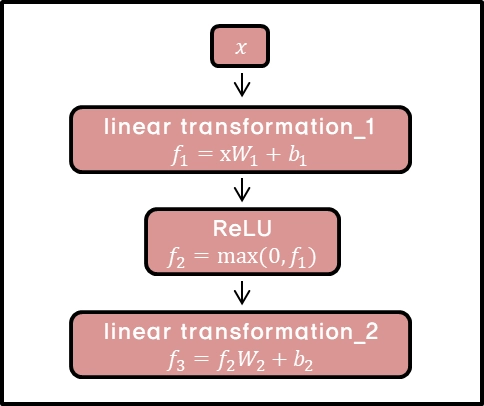
(3) feed forward
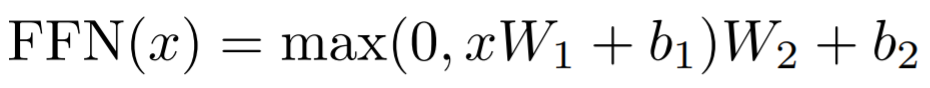
- 입력벡터 x에 linear 변환을 거친 뒤 ReLU함수를 적용하고 그 후 또 다시 linear변환 적용
- 그니까 x -> linear transform -> ReLU -> linear transform을 적용
- max함수는 ReLU활성화함수를 사용하기 위해 사용한다.
- 인코더 디코더 모두 이 network를 가지고 있다.
- 각 단어마다 feed forward를 적용한다.
2) decoder
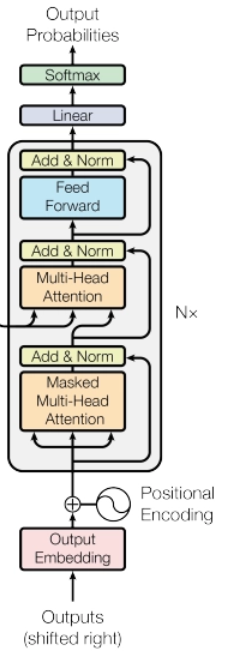
이전 디코더 레이어의 출력을 입력으로 받는다. 다만 인코더와는 다르게 masking을 수행하는데 이를 하는 이유는 특정 단어 이후의 단어들을 참조하지 못하게끔하기 위해서이다. 왜냐하면 RNN과 달리 한꺼번에 문장 데이터가 입력이 되기 때문에 순차적으로 단어를 잊어가는 RNN과 달라서 마스킹이 필요하다.
- 인코더와 같이 6개의 층으로 구성되어있다.
- 2개의 sub layer가 아닌 3개로 이루어져 있다. multi head attention이 그 세번째이다.
- 이 부분은 인코더-디코더 부분인데 추후 다루도록 하겠다.
- 디코더는 병렬처리하던 encoder와 달리 순차적 결과를 만들어야 하므로 masking을 진행한다.
3) encoder-decoder attention
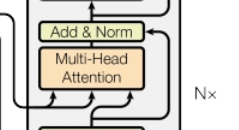
decoder의 이부분을 뜻한다. Q는 이전 디코더 레이어의 출력값이고 K와 V는 인코더의 출력값을 사용한다. 결론적으로 디코더가 출력문장을 생성할 때, 입력문장의 모든 위치의 단어들을 참조할 수 있게 된다.
3. 모델의 장점과 단점
| 장점 | 단점 |
|---|---|
| 기울기 소실 해결 | |
| 긴 문장을 넣을 수 있음 | |
| 계산능력 향상 | |
| 각 Layer당 계산 복잡도의 감소 |
4. 코드 리뷰
5. 출처
[[논문리뷰] Attention is All you need(https://aistudy9314.tistory.com/63)
[NLP 스터디] Attention Is All You Need 논문 리뷰
[Paper review] Attention 설명 + Attention Is All You Need 리뷰
[논문 리뷰] Attention is All You Need
