
1. 해쉬 테이블(Hash Table) 🔍
키(Key)에 데이터 값(Value)을 저장하는 자료구조.
Key를 통해 바로 데이터를 받아오는 것이 가능하며 그래서 속도가 빠르다.
파이썬의 딕셔너리(Dictionary)타입이 해쉬테이블의 대표적인 예시, 따라서 파이썬에서는 해쉬테이블을 따로 구현하지 않아도 된다.
주요 용도 : 데이터의 검색, 저장, 삭제, 읽기가 빈번한 경우 또는 캐쉬 구현(쉬운 중복확인)
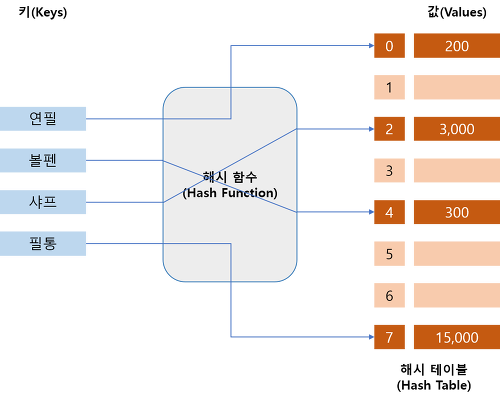
<해쉬 테이블 개념도> 출처 : https://dev-kani.tistory.com/1
2. 용어정리
-
해쉬(Hash) : 임의 값을 고정 길이로 변환하는 것
-
해싱 함수(Hash Function) : Key를 해쉬 값(Value)이 저장되는 주소 값으로 바꾸기 위한 수식
-
해싱(Hashing) : 키(Key) 값을 해시 함수(Hash Function)라는 수식에 대입시켜 계산한 후 나온 결과를 주소로 사용하여 바로 값(Value)에 접근하게 하는 일련의 과정.
-
해쉬 주소(Hash Address) : key를 해싱 함수로 연산 후, 해쉬 값(Value) 을 알아내고, 이것으로 해쉬 테이블에서 해당 key에 맞는 데이터 위치를 찾음
-
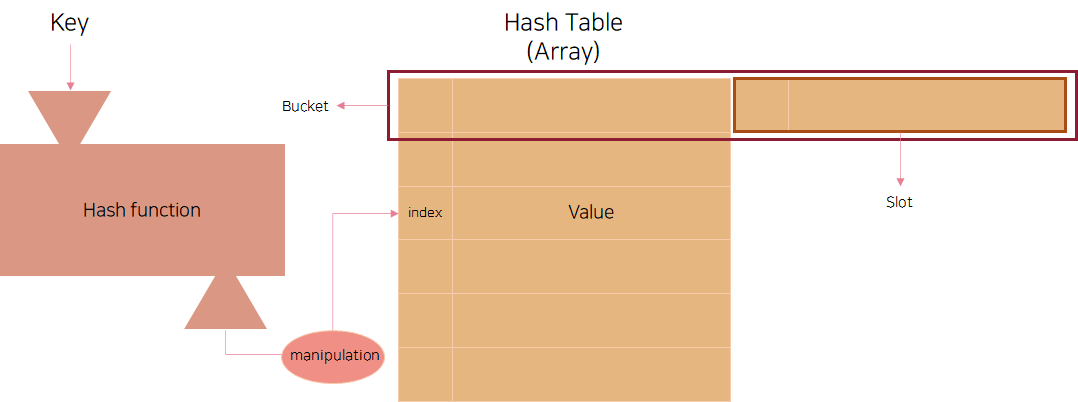
버킷(bucket) : 여러개의 슬롯을 저장하는 레코드 형태의 자료 구조, 갯수는 고정적
-
슬롯(Slot) : 한 개의 데이터를 저장할 수 있는 공간, 하나의 버킷 안에는 여러 개의 슬롯이 존재할 수 있음.
서로 다른 두 개의 key가 해쉬 함수에 의해 동일한 해쉬 주소로 변활될 수 있으므로 여러개의 항목을 동일한 버킷, 다른 슬롯에 저장할 수 있다
3. 해쉬 테이블의 장단점
- 장점
- 데이터 저장, 읽기, 검색 속도가 빠르다. 시간복잡도 O(1)
- key에 대한 데이터가 이미 있는지 중복 확인이 쉽다.
- 다량의 데이터를 적은 리소스로 관리가 가능해 효율적이다.
- key와 해시값 사이에 연관이 없기 때문에 해시값만 가지고는 key를 온전히 알수 없어 보안성이 뛰어나다.
- 단점
- 저장공간이 좀 더 많이 필요하다.
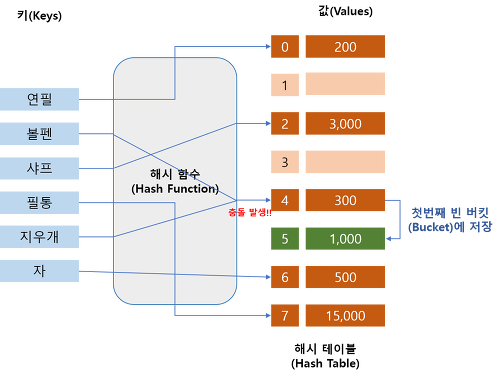
- 여러 key에 해당하는 주소가 동일할 경우 해쉬 충돌(Hash Collision) 이 일어난다.
- 충돌이 일어날 경우 시간복잡도가 O(n)에 가까워진다.
4. 문제점
-
해쉬 충돌(Hash Collision) : 서로 다른 key값이 동일한 인덱스로 매핑될 경우, 해쉬 충돌이 발생하여 해쉬테이블의 성능을 떨어뜨린다. 버킷 안에는 여러 개의 슬롯이 있어서 충돌이 생겨도 저장은 가능하다
-
오버플로우(Overflow) : Key가 모든 slot이 꽉 찬 Bucket에 매핑된 경우, 위의 충돌에서 슬롯의 개수는 유한하기 때문에 주어진 슬롯이 가득차서 저장을 하지 못하는 경우를 오버플로우라고 한다.
-
클러스터(Cluster) : 해쉬 함수가 연산한 해쉬 값들이 골고루 분포하지 않고 레코드(저장공간) 한쪽에 뭉쳐있는 현상
📌 데이터를 적절히 분산하고 충돌을 최소화 하는 좋은 해쉬 함수를 정의하는 것이 중요
5. 해쉬 함수 (Hash Function)
Key를 입력받아 해쉬주소를 생성 후 만들어진 주소가 해쉬테이블의 인덱스가 된다.
-
특징
- 다양한 길이의 입력을 고정된 짧은 길이의 출력으로 변환하는 함수 (일방향 함수)
- 동일한 값이 입력되면 항상 동일한 출력 값이 나온다.
- 해쉬 결과값으로 입력값은 계산할 수 없다.
- 입력값의 일부만 변경되어도 전혀 다른 결과 값이 출력된다.(눈사태 효과)
-
종류
-
Division Method : 나눗셈과 나머지 연산자를 이용, 키(입력값)를 해쉬테이블의 크기로 나눈 나머지를 해시값으로 반환한다.
키 값 % 전체 테이블의 크기 = 인덱스
해쉬 주소가 고르게 분포하기 위해 테이블의 크기를 소수(Prime number)를 사용하고 2의 제곱수와 먼 값을 사용하는 것이 좋다. -
Digit Folding : key를 마지막 부분을 제외하고 동일하게 분할한 후 각 부분을 모두 더하거나 XOR연산 하는 등의 연산을 하여 테이블 내의 주소(Index)로 사용하는 방법.
key가 문자열일 경우 ASCII코드로 바꿔서 연산함. -
Multiplication Method : 숫자로 된 key값이 k이고 A는 0과 1사이의 실수일 때, 보통 2의 제곱수인 m을 사용하여 다음과 같은 계산을 해준다.
나눗셈법 보다는 다소 느림, 2진수 연산에 최적화된 컴퓨터 구조를 고려한 함수
h(k)=(kA % 1) × m -
Radix Conversion : 진수 변환을 통해 테이블 내의 주소로 사용하는 방법.
-
Algebraic Coding : key를 이루고 있는 각각의 bit를 다항식의 계수로 이용하여 계산한 값을 테이블 내의 주소로 사용하는 방법.
-
Univeral Hashing : 다수의 해시함수를 만들고 이 해시함수의 집합 H에서 무작위로 해시함수를 선택해 해시값을 만드는 기법.
-
6. 해쉬 알고리즘 (Hash Algorithm)
📌 대표적으로 쓰이는 알고리즘 예시
-
MD5(message digest 5)
- 임의의 길이로 입력받은 메시지를 512비트 단위로 처리해 128비트로 암호화하고 무결성 검증.
- 입력 메시지 길이는 제한 없으나, 해시값 길이는 128비트로 정해짐
- 전자서명 등 정보보호 또는 MYSQL, 데이터베이스 패스워드 알고리즘등 다방면으로 이용됨
- 복호화가 쉽다는 문제점이 발견되어서 현재는 사용하는 것이 권장되지 않는다.
-
SHA(Secure Hash Algorithm)
- 1993년 미국 NIST에 의해 개발되었고 가장 많이 사용되고 있는 방식
- MD4에 기반을 두고있으며, MD5의 취약성에 대처 하기위해 설계됨
- SHA256, SHA384, SHA512는 AES의 키(Key) 길이인 128, 192, 256 비트에 대응, 출력 길이를 늘린 알고리즘
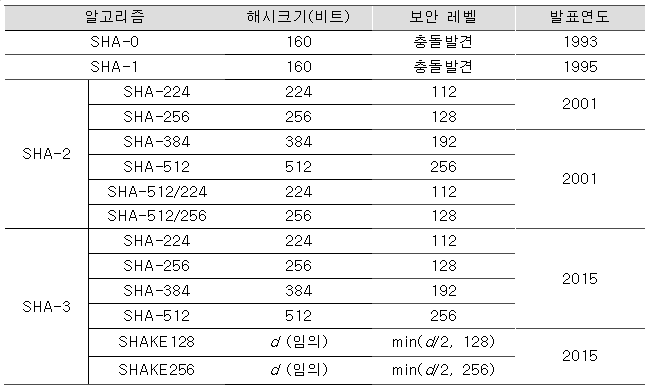
이미지 출처 : http://wiki.hash.kr/index.php/SHA
- RIPEMD(RIPE Message Digest)
- MD4를 기반으로 개발한 암호화 해쉬 알고리즘.
- 타 해쉬 알고리즘에 비하면 비교적 높은 안전함이 있기때문에 비트코인 및 기타 암호화폐에서 많이 사용된다.
- RIPEMD-160 버전이 안정성 때문에 가장 많이 사용된다.
7. 해쉬 충돌 (Hash Collision) 해결법
해쉬함수의 입력 값은 무한하지만 출력 값의 가짓수는 유한하므로 해쉬충돌의 발생은 필연적이다. 그러나 너무 많은 해쉬 충돌은 해쉬 테이블의 성능을 떨어뜨린다.
-
체이닝(Chaining)
- 동일한 bucket에 노드를 추가하여 여러 개의 데이터를 저장하여 관리.
- 충돌 발생시 linked list로 데이터들을 연결.
- bucket이 꽉차도 linked list로 계속 늘림.
- 최근 데이터는 연결리스트의 head에 추가됨.
- 이 경우 𝑂(1), tail에 저장할 경우 𝑂(𝑛)이 됨.
- 데이터의 수가 많아지면 동일한 버킷에 체이닝 되는 데이터가 많아져 효율성이 감소한다는 단점이 있다.

John과 Sandra는 같은 해시 값(152)으로 매핑되고 있다.
-
개방 주소법 (Open Addressing)
-
한 bucket당 들어갈 수 있는 엔트리가 하나뿐인 해쉬 테이블.
-
해쉬 함수로 얻은 주소가 아닌, 비어있는 공간을 활용해서 다른 주소에 데이터를 저장.
-
추가적인 메모리를 사용하지 않아 메모리 문제가 발생하지 않으나 충돌발생 가능.
1. 선형 탐사(Linear Probing)
- 오버플로우 발생 시, 충돌이 발생한 버킷 뒤에 있는 빈 버킷을 찾아 데이터를 넣는 방식.
- 장점 : 방식이 간단하고 캐쉬의 효율이 높다
- 단점 : Cluster현상에 취약, 비어있는 버킷을 찾을 때 까지 탐색하기 때문에 시간이 늘어난다.
2. 제곱 탐사(Quadratic Probing)
- 고정폭으로 이동하는 선형 탐사와 달리 폭이 제곱수로 늘어난다.
- 예를 들어 충돌이 일어나면 1칸, 다음에는 2², 3²칸씩 옮겨짐.
- 해시 값이 같으면 다음 탐사 위치도 동일하기 때문에 효율성 떨어짐.
3. 이중 해싱 (double hashing)
- 탐사할 해시 값을 한번 더 해싱하여 규칙을 없애서 클러스터링을 방지하는 기법.
- 다른 방법들보다 많은 연산이 필요하다.
-
8. 체이닝 vs 개방주소법
-
Chaining :
- 삭제 작업이 간단하다.
- 체이닝은 클러스터링의 영향을 거의 받지않는다.
- 사용 중인 슬롯 비율이 높아져도 성능 저하가 급격히 일어나지 않는다.
-
Open Addressing :
- 데이터의 크기가 작을수록 성능이 좋아진다.(메모리 절약)
- 데이터가 크거나, 데이터의 길이가 가변적일 때 체이닝 보다 뛰어난 성능을 보여준다.
참고 자료(References)
https://colinch4.github.io/2021-01-14/DataStructure_HashTable/
https://dev-kani.tistory.com/2
https://j3sung.tistory.com/759
https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/
https://medium.com/depayse/kotlin-data-structure-hashtable-ebb9f949e936
http://wiki.hash.kr/index.php/%ED%95%B4%EC%8B%9C%EC%B6%A9%EB%8F%8C
