
파이썬만의 특징인 GIL(Global Interpreter Lock)에 대해 알아보자.
1. 🐍 Python Interpreter 란 ?
인터프리터는 코드를 한 줄씩 읽어 내려가며 실행하는 해석 프로그램 이라고 생각하면 편하다.
파이썬은 자바스크립트, 루비 등과 함께 대표적인 인터프리터 언어 중 하나이다.
C언어 등으로 대표되는 컴파일러와는 반대 개념이며 컴파일이란 어떤 언어의 코드를 다른 언어로 바꿔주는 과정이고 C++코드를 기계어로 바꿔주는 예시가 있다.
컴파일러 👉 번역기
인터프리터 👉 통역기 인터프리터는 실행시 마다 한줄씩 코드를 기계어로 번역하는 방식이기 때문에 속도는 정적 컴파일 언어 보다 느리나,프로그램 수정이 간단하다는 장점과 동적인 기능을 지원하기에 유리하기 때문에 수정이 빈번한 용도의 프로그래밍에서 선호된다.
📌 Python의 구현체 CPython
Python은C언어를 이용해 구현한 언어이다.
파이썬 내부의 소스 코드를 열람해 보면 C언어로 구현이 되어있는데 그 구현체가CPython이다.
따라서 CPython은 인터프리터이면서 컴파일러이다.
파이썬은 파이썬의 문법에 맞춰 작성한 코드를 실행하여 주는 프로그램이므로 충분히 다른 언어로도 구현될 수 있다.
대표적인 사례로 Java로 구현한 Jython(자이썬)이 있다.
2. 🔒 GIL (Global Interpreter Lock)
Python WIKI에서 Global Interpreter Lock : GIL (전역 인터프리터 락)이란
CPython에서의 GIL은 Python 코드(bytecode)를 실행할 때에 여러 thread를 사용할 경우, 단 하나의 thread만이 Python object에 접근할 수 있도록 제한하는 mutex 이다. 그리고 이 lock이 필요한 이유는 CPython이 메모리를 관리하는 방법이 thread-safe하지 않기 때문이다.
하나의 스레드에 모든 자원을 허락하고 그후에는 Lock을 걸어 여러 개의 쓰레드가 파이썬 코드를 동시에 실행하지 못하게 하는 것이다.
즉, 한 프로세스 내에서, Python 인터프리터는 한 시점에 하나의 쓰레드에 의해서만 실행될 수 있다는 것이다.
일반적으로 멀티코어에서 여러개의 스레드를 통해 작업을 하는경우 병렬적으로 일할 것이라 생각되지만 이 GIL때문에 파이썬에서는 병렬 실행이 불가능 하다.
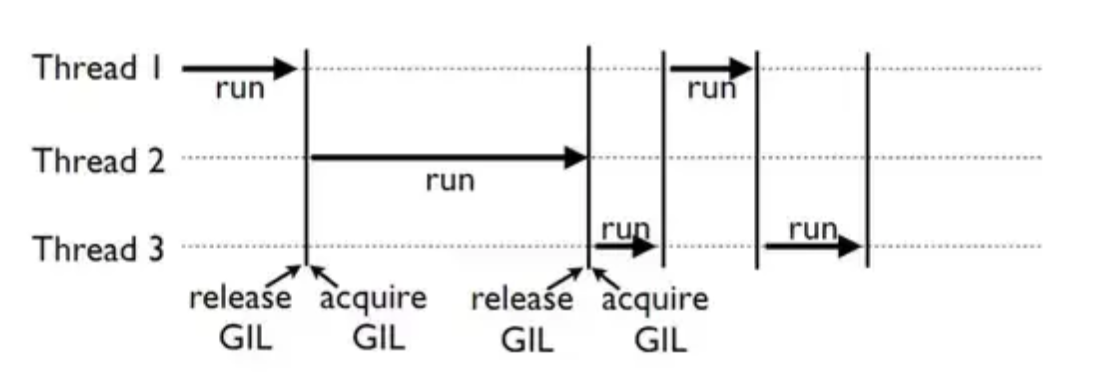
각각의 스레드는 GIL을 얻고 동작하며 다른 스레드는 동작을 멈추게 된다.
그리고 멀티 스레드일 경우 Thread context switch에 따른 비용도 발생하기 때문에 오히려 싱글 스레드보다 시간이 더 오래걸리는 문제가 발생할 수 있다.
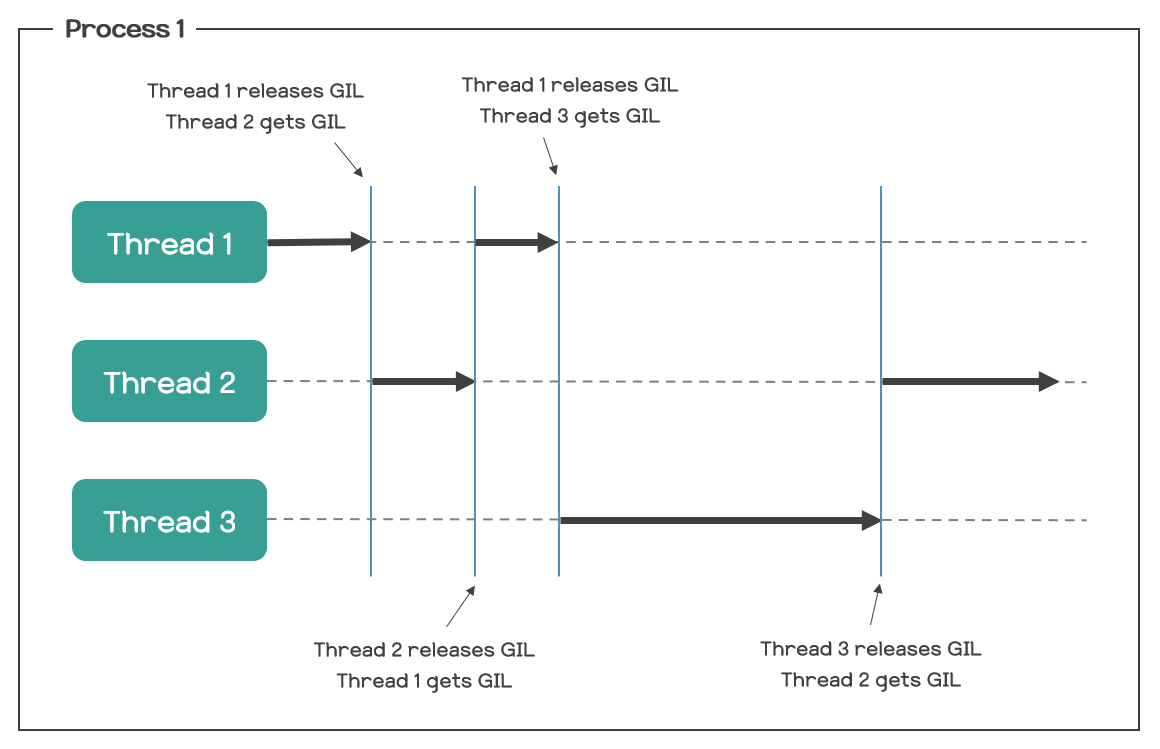
3. 🧷 Mutex 란?, Thread-Safe하지 않다는 게 뭐지?
CPython은 C로 만들었으므로 mutex와 thread-safeness의 개념을 C 언어에서 참고하자.
운영체제가 생성하는 작업 단위 -> 프로세스
프로세스 안에서 공유되는 메모리를 바탕으로 하는 여러 작업의 단위-> 스레드
스레드마다 할당된 개인적인 메모리가 존재,
스레드가 속한 프로세스가 가지는 메모리에도 접근가능.
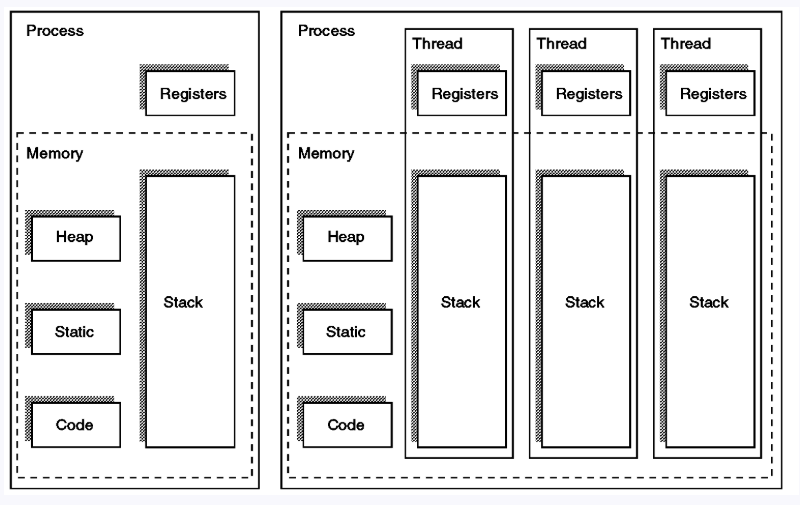
Thread-Safe ❓
"Thread-Safe않다" 는 것이 무엇인지 보여주는 예제.
import threading
x = 0 # 공유 값 선언
def foo():
global x
for i in range(100000000):
x += 1
def bar():
global x
for i in range(100000000):
x -= 1
# 결과는 0 으로 예상 되지만 엉뚱한 결과가 나온다.
t1 = threading.Thread(target=foo)
t2 = threading.Thread(target=bar)
t1.start()
t2.start()
t1.join()
t2.join()
print(x)
# 첫번째 시도 결과 값 : -3780005
# 두번째 시도 결과 값 : -3517680
# 세번째 시도 결과 값 : 6957599파이썬에서 스레드들이 프로세스가 공유하는 메모리에 접근하면 전역변수 x에 두 개의 스레드가 동시에 접근해서 각자의 작업을 하면서 어느 한 쪽의 작업 결과가 반영이 되지 않기 때문이다.
두명의 사람이 번갈아 가면서 하나의 버튼을 빠르게 1000번 누른다고 가정할 때, 당연히 +2번씩 카운트가 올라가겠지만, 두 사람이 동시에 버튼을 눌러 +1번 카운트 되는 경우가 생기는 것과 비슷하다.
이런 문제를 경쟁 상태(Race Condition) 이라고 하며, 반대로 thread safe 하다는 것은 스레드들이 race condition을 발생시키지 않고 각각의 일을 수행한다는 뜻이다.
경쟁 상태(race condition)란 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태를 말한다.Mutex ❓
뮤텍스(mutex)는 상호 배제(mutual exclusion)의 약자이다.
Thread-safe한 코드를 만들기 위해서 사용하는 것 중 하나가 mutex이다.
위와 같은 상태를 막기 위해 공유되는 메모리의 데이터를 여러 스레드가 동시에 사용할 수 없도록 Lock시키는 일을 mutex가 맡는다.
- 어느 한 스레드가 최초로 mutex를 가져가면, 그 스레드는 그 다음 코드를 계속 진행하고
- 이 후 다른 스레드가 mutex를 가져가려고 하면, 첫 스레드가 lock을 풀 때까지 기다려야 한다
- 뮤텍스의 lock이 해제되면, 두 번째 스레드가 mutex를 받아서 다음 코드를 진행.
.png)
4. 🤔 그럼 왜 GIL을 쓰는 걸까?
그럼 병렬 실행이 불가능 하게 만드는 GIL은 왜 굳이 쓰는 걸까?
Python에서 모든 것은 객체(Object)이다.
그리고 각 객체는 참조 횟수(Reference Count)를 저장하기 위한 필드를 가지고 있다.
참조 횟수란 그 객체를 가리키는 참조가 몇 개 존재하는지를 나타내는 것으로, Python에서의 GC(Garbage Collection)는 이러한 참조 횟수가 0이 되면 해당 객체를 메모리에서 삭제시키는 메커니즘으로 동작하고 있다.
GC에 관해선 다음 포스팅에 다뤄 볼 예정이다.
sys 라이브러리의 getrefcount() 함수를 사용하면 특정 객체의 참조 횟수를 알아낼 수 있다.따라서,
참조 횟수에 기반하여 GC를 진행하는 Python의 특성상, 여러 개의 쓰레드가 Python 인터프리터를 동시에 실행하면 아까 위에서 설명했던 Race Condition이 발생, 각 객체의 참조횟수가 올바르게 관리되지 못할 수도 있고, GC가 제대로 동작하지 않을 수도 있기 때문에 mutex를 사용해 예방하는 것이다.
결국 GC의 올바른 동작을 보장하려면 결국 모든 객체에 대해 뮤텍스를 걸어줘야 하는데 이는 매우 비효율적이다.
효율성을 위해 Python은 애초에 한 스레드가 인터프리터를 실행하고 있을 때는 다른 스레드들이 파이썬 인터프리터를 실행하지 못하도록 막는 GIL(전역 인터프리터 락) 을 선택했다.
그리고 다른 역사적인 이유도 찾을 수 있었다.
Python이 태동하던 시기에는 thread라는 개념이 없었을 당시였고, 쉽고 간결한 언어를 표방했던 Python에 많은 사용자들이 모여들고 있었다.
수 많은 C extension들이 이미 만들어졌는데, 시간이 지나서 thread 개념으로 인한 문제를 해결하기 위해서 가장 현실적인 방안은 GIL이었다.
거대한 커뮤니티에서 만들어낸 C extension들을 새로운 메모리 관리 방법에 맞춰서 모두 바꾸는 것은 불가능하다.대신 Python이 GIL을 도입하면 C extension들을 바꾸지 않아도 됐던 것이다.
이렇게 초장기에 만들어진 CPython의 GIL은 현재 Python 3가 되도록 크게 변하지 않은 부분이라고 한다.BDFL은 GIL에 대한 개선을 하고 싶은 사람들에게 이렇게 말했다.
I’d welcome a set of patches into Py3k only if the performance for a single-threaded program (and for a multi-threaded but I/O-bound program) does not decrease. 단일 thread 프로그램에서의 성능을 저하시키지 않고 GIL의 문제점을 개선할 수 있다면, 나는 그 개선안을 기꺼이 받아들일 것이다.그리고 지금까지 그렇게 해서 받아들여진 개선안은 없다고 한다.
출처:개발새발로그
출처:https://realpython.com/python-gil/
5. 🎛 Multi Threading은 Python에서 쓰지 말아야 할까?
😞 CPU 연산의 비중이 큰 작업을 할 때 멀티 쓰레딩은 오히려 성능을 떨어뜨린다. 2번 문단에서 설명했듯이 병렬적인 실행은 불가능한데 문맥 전환(Context Switching) 비용만 잡아먹기 때문이다.
😎 하지만, Python에서는 외부 연산(I/O, Sleep 등)을 하느라 CPU가 아무것도 하지 않고 기다리기만 할 때는 다른 쓰레드로의 문맥 전환을 시도하게 되어있다.
이때는 다른 스레드가 실행되어도 공유 자원의 race condition 문제가 발생하지 않기 때문.
따라서 CPU 연산의 비중이 적은 외부 연산(I/O, Sleep 등)의 비중이 큰 작업을 할 때는 멀티 스레딩이 굉장히 좋은 성능을 보인다. 따라서 Python에서 멀티 스레딩이 무조건 안 좋다고는 할 수 없다.
예제1)
# 예제1) sleep 매서드로 멀티스레드 성능개선
def loop2():
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
# Single Thread
start = time.time()
loop2()
loop2()
end = time.time()
print('Single Thread: {}'.format(end - start))
# Multi Thread
start = time.time()
threads = []
for i in range(2):
threads.append(threading.Thread(target=loop2))
threads[-1].start()
for t in threads:
t.join()
end = time.time()
print('Multi Thread : {}'.format(end - start))
# 싱글스레드 결과 값 : 9.312692880630493
# 멀티스레드 결과 값 : 7.911287069320679 -> 성능이 개선된 것을 알 수 있다예제2)
# 예제2)
def sleep_for_2s():
time.sleep(2)
# Single Thread
start = time.time()
sleep_for_2s()
sleep_for_2s()
end = time.time()
print('Single Thread : {}'.format(end - start))
# Multi Thread
start = time.time()
thread1 = threading.Thread(target=sleep_for_2s)
thread2 = threading.Thread(target=sleep_for_2s)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end = time.time()
print('Multi Thread : {}'.format(end - start))
# 싱글스레드 결과 값 : 4.0100319385528564
# 멀티스레드 결과 값 : 2.005458354949951 -> 성능이 향상된 것을 알 수 있다.sleep 메서드로 인해 싱글 스레드에서는 아무런 동작도 취하지 못한 체 동작을 대기해야 하는데, 멀티스레드에서는 sleep으로 멈춘 경우 다른 스레드로 context switching하여 효율이 개선됨을 알 수 있다.
참고) 외부 연산 (I/O)
프로그램을 CPU-bound, I/O-bound 프로그램으로 나누자면
CPU-bound 프로그램 : 행렬곱, 이미지처리 등 CPU 코어를 최대한 활용하는 프로그램
I/O-bound 프로그램 : 네트워크, 데이터베이스 등 입출력을 기다리는데 많은 시간을 소비하는 프로그램
I/O-bound 프로그램의 경우 GIL이 성능에 영향이 없다.
하지만 CPU-bound 프로그램의 경우 GIL로 인해 멀티 스레드로 짠다고 해도 단일 스레드로 동작함.
멀티스레드로 구현하면 실제로 단일 쓰레드로 구현한 것보다 느려질 수 있는데, 그 이유는 lock으로 인한 오버헤드때문.
출처: https://torbjorn.tistory.com/6696. 💡 GIL우회 방법은? (병렬 처리 하는법)
1️⃣ Multi Process
가장 널리 사용되는 방식, 멀티스레드 대신 멀티프로세스(Multi Process)를 사용하는 것이다.
한 프로세스의 여러 스레드들은 서로 자원을 공유하지만, 여러 개의 프로세스들은 각자 독자적인 메모리 공간을 가져서 서로 자원을 공유하지 않기 때문
multiprocessing 등의 모듈을 사용할 수 있는데, 프로세스는 독립된 메모리 할당이 필요하고 자체적 오버헤드가 있어 순수한 멀티스레드보다는 성능이 떨어질 수 있고, 메모리를 더 필요로 하며, 문맥 전환의 비용이 더 든다는 단점을 가짐.
2️⃣ 다른 Python 인터프리터 구현체 사용
CPython이 아닌 다른 Python 인터프리터 구현체를 사용하는 것이다.
예를 들면 Jython, Pypy 등이 있으나 흔히 사용하는 방법은 아니므로 권장하지 않는다.
참고자료 (Reference)
https://ssungkang.tistory.com/entry/python-GIL-Global-interpreter-Lock%EC%9D%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
https://it-eldorado.tistory.com/160
https://dgkim5360.tistory.com/entry/understanding-the-global-interpreter-lock-of-cpython
https://namu.wiki/w/%EC%9D%B8%ED%84%B0%ED%94%84%EB%A6%AC%ED%84%B0
https://www.ciokorea.com/news/210764
