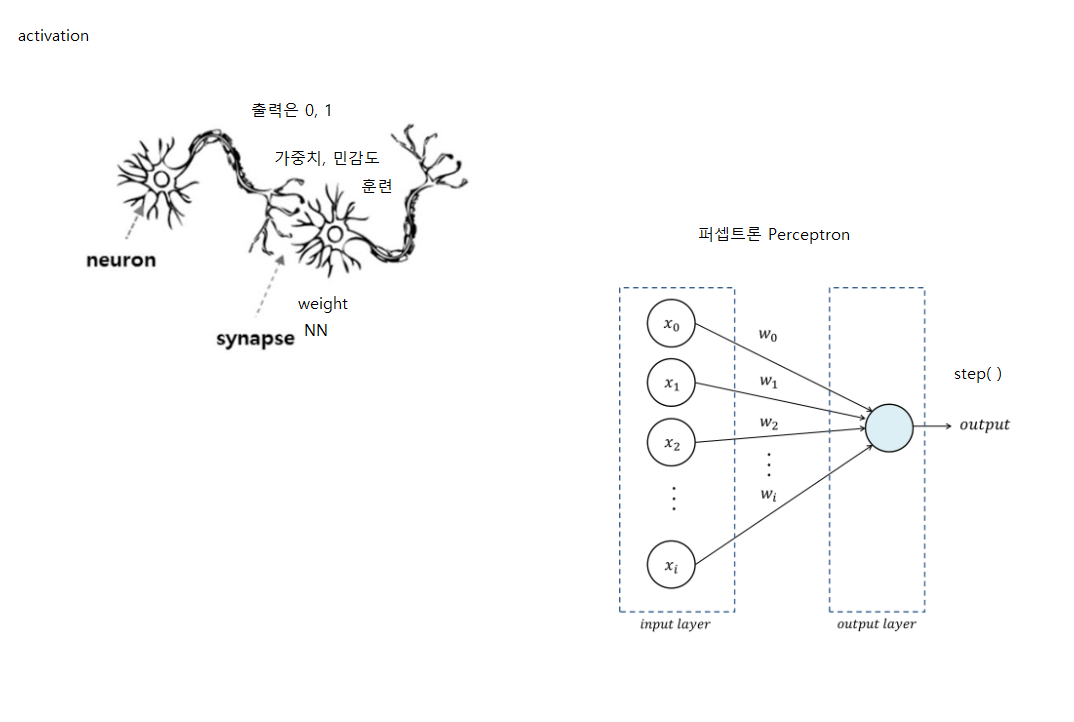
기존 프로그램 방식: 입력과 출력에 대한 함수를 사용자가 만듬
앞으로의 프로그래밍 방식: 데이타를 주면 함수를 자동으로 만들어줌
기존 프로그래밍은 함수, 클래스라면라면, machine learing 은 데이타를 만드는 것이 중요.
import numpy as np // 다차원배열 패키지
import pandas as pd // 데이터를 다루는 패키지
import matplotlib.pyplot as plt // 그래프 그려주는 패키지
def celsius_to_faherengeit(x):
return x * 1.8 + 35
print(celsius_to_faherengeit(20))
data_C = np.array(range(0, 100),)
data_F = celsius_to_faherengeit(data_C)
print(data_C, "\n")
print(data_F)
inp = int(input("섭씨 온도를 입력하세요.\n"))
print("화씨 온도로", celsius_to_faherengeit(inp), "입니다.")머신 러닝 방식: 사용자가 입력과 출력 데이터를 주면 함수를 만듬
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(1, input_dim=1)) // 뇌세포 1개로 이뤄진 , 입력값 * 가중치 + 편향 , 모델
model.compile(loss='mse', optimizer='rmsprop', metrics=['mae'])
print(model.summary())
print(model.predict([1]))
model.save("/content/before_learning.h5")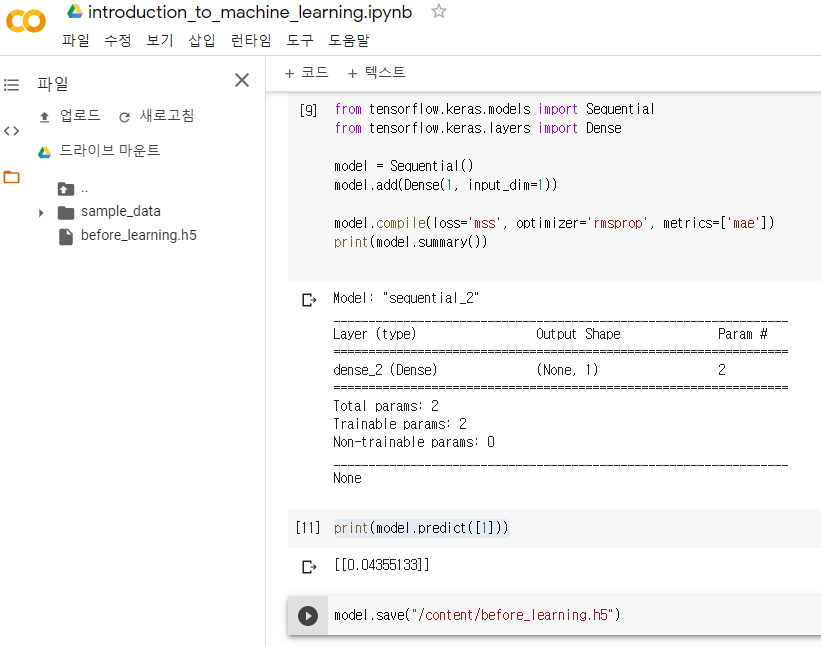
// 데이터 준비
scaled_data_C = data_C / 100
scaled_data_F = data_F / 100
print(scaled_data_C)
print(scaled_data_F)
// 학습
fit_hist = model.fit(scaled_data_C,
scaled_data_F,
epochs =1000,
verbose=1)
// 결과
plt.plot(fit_hist.history['loss'])
plt.show()
print(model.predict([0.01]))
model.save("/content/after_learning.h5")
noise = np.array(np.random.normal(0, 0.1, 100)) // 정규분포 랜덤, 0.1: 표준편차
print(noise)
noised_scaled_data_F = scaled_data_F + noise
plt.scatter(x=scaled_data_C, y=noised_scaled_data_F)
plt.show()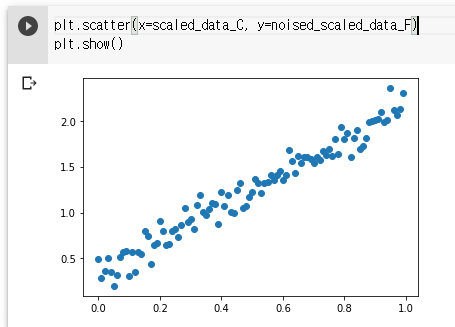
model2 = Sequential()
model2.add(Dense(1, input_dim=1))
model2.compile(loss='mse', optimizer='rmsprop', metrics=['mae'])
print(model2.summary())
print(model2.predict([0.01]))
fit_hist2 = model2.fit(scaled_data_C, noised_scaled_data_F, epochs=1000, verbose=1)
plt.plot(fit_hist2.history['loss'])
plt.show()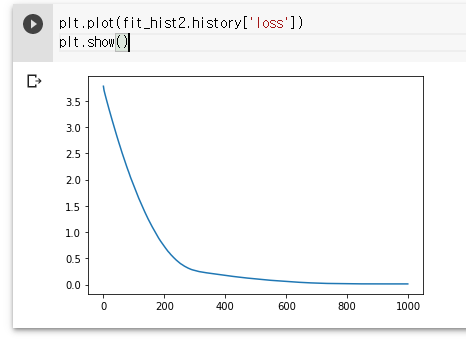
print(model2.predict([0.01]))
model2.save("/content/noise_data_after_learning.h5")
머신러닝의 2가지 기능
- 예측: x 값을 줬을 때 y 값을 찾음, 회귀
- 분류: a 값을 주면 b 이다.
setosa_petal_length = np.random.uniform(low=0.3,
high=1.0,
size=100)
setosa_sepal_length = setosa_petal_length * 1.5 + 0.08
noise = np.array(np.random.normal(0, 0.05, 100),)
setosa_noised_sepal_length = setosa_sepal_length + noise
plt.scatter(setosa_petal_length, setosa_noised_sepal_length, color='r')
virginica_petal_length = np.random.uniform(low=0.3,
high=1.0,
size=100)
virginica_sepal_length = virginica_petal_length * 1.1 - 0.02
noise = np.array(np.random.normal(0, 0.05, 100),)
virginica_noised_sepal_length = virginica_sepal_length + noise
plt.scatter(virginica_petal_length, virginica_noised_sepal_length, color='b')
plt.show()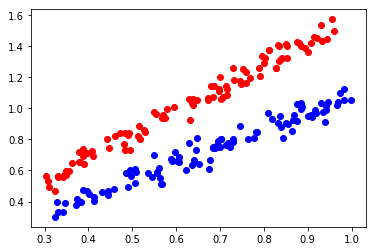
꽃 품종 setosa, virginica 구분 선
keras_xor.ipynb
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
// 이진 분류기
traing_data = np.array([[0,0], [0,1], [1,0], [1,1]], 'float32') // 입력데이터
target_data = np.array([[0],[1],[1],[0]], 'float32') // 정답데이터
model = Sequential()
model.add(Dense(32, input_dim=2, activation='relu')) // 뇌세포 32개
model.add(Dense(1, activation='sigmoid')) // 출력 1개
model.compile(loss='mse', optimizer='adam', metrics=['binary_accuracy'])
print(model.summary())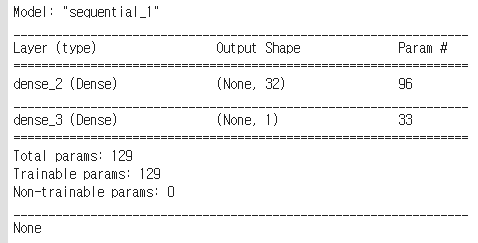
fit_his = model.fit(traing_data, target_data, epochs=100, verbose=1)
plt.plot(fit_his.history['loss'])
plt.show()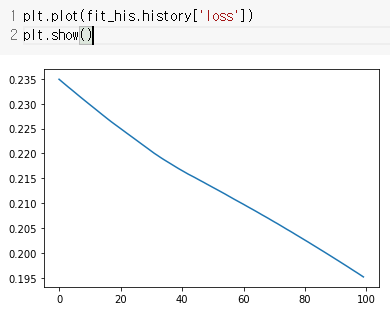
count = 4
while count != 0:
inp = list(map(int, input().split()))
qwe = np.array(inp)
print('입력 값 : ', qwe)
qwe = qwe.reshape(1,2)
print('reshape : ', qwe)
print('결과 값 : ', model.predict(qwe)[0][0].round())
count -= 1OR GATE
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
traing_data = np.array([[0,0],[0,1],[1,0],[1,1]], 'float32')
target_data = np.array([[0],[1],[1],[1]], 'float32')
model = Sequential()
model.add(Dense(32, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mse', optimizer='adam', metrics=['binary_accuracy'])
print(model.summary())
fit_his = model.fit(traing_data, target_data, epochs=100,
verbose=1)
plt.plot(fit_his.history['loss'])
plt.show()
count = 4
while count != 0:
inp = list(map(int, input().split()))
qwe = np.array(inp)
print('입력 값 : ', qwe)
qwe = qwe.reshape(1,2)
print('reshape : ', qwe)
print('결과 값 : ', model.predict(qwe)[0][0].round())
count -= 1 
HeartDisease_predict.ipynb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
heading = ['age', 'sex', 'cp', 'treshtbps', 'chol', 'fbs', 'restecg', 'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'hsl', 'HeartDisease']
raw_DB = pd.read_excel('/content/datasets/heart-disease.xlsx', header=None, names=heading)
print(raw_DB.head(2))
print(raw_DB.tail(2))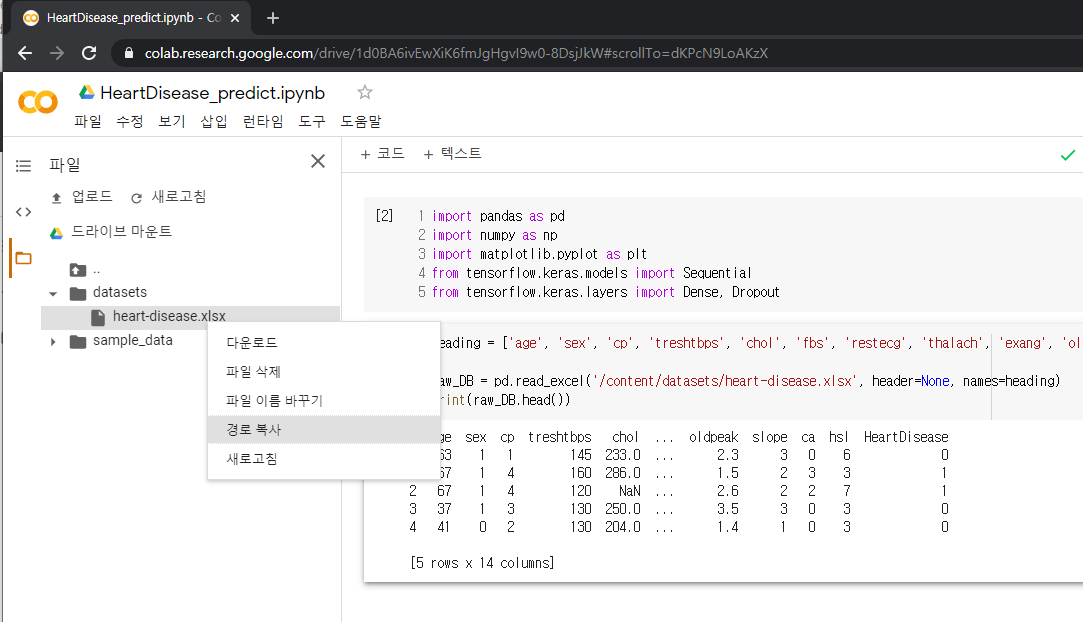
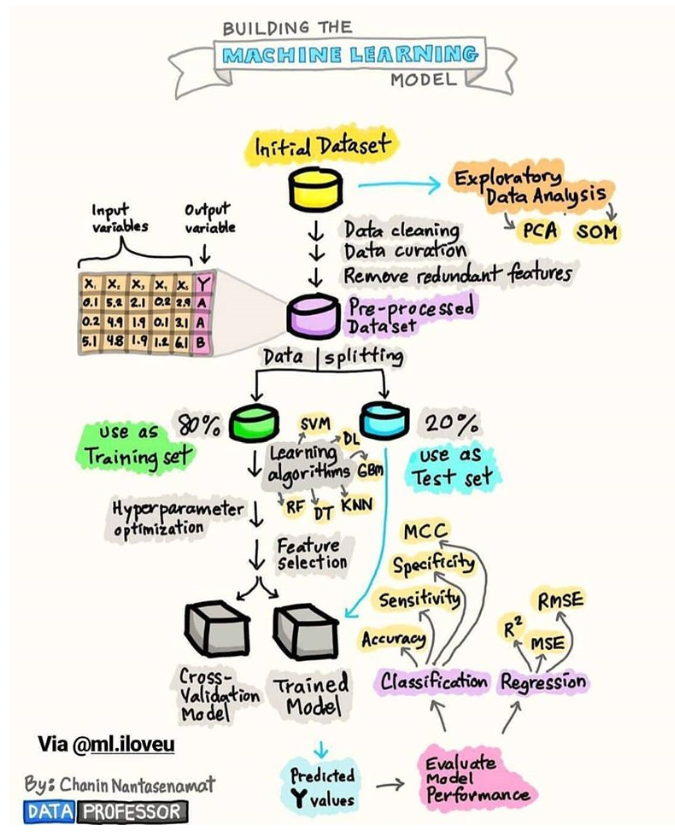
[머신러닝 절차]
* 데이터 전처리 -> 학습 데이터, 검증 데이터 분리, 데이터 정제 -> 모델 만들기 -> 학습 -> 테스팅(성능) -> 활용
print(raw_DB.describe())
print(raw_DB.info())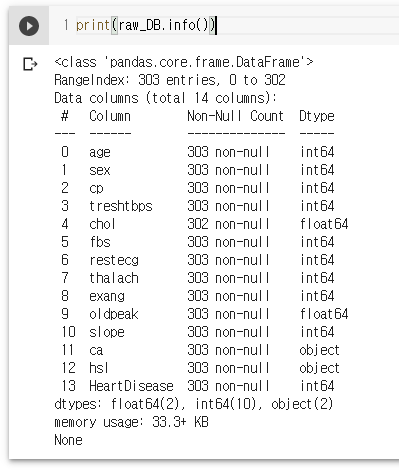
clean_DB = raw_DB.replace("?", np.nan)
clean_DB = clean_DB.dropna()
print(clean_DB.info())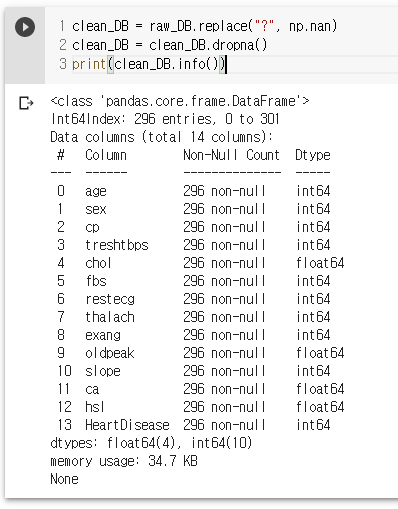
keep = heading.pop()
print(keep)
print(heading)
Input = pd.DataFrame(clean_DB.iloc[:,0:13], columns=heading) // iloc : 인덱스 번호, loc : 컬럼명
Target = pd.DataFrame(clean_DB.iloc[:,13], columns=[keep])
print(Input.head())
print(Target.head())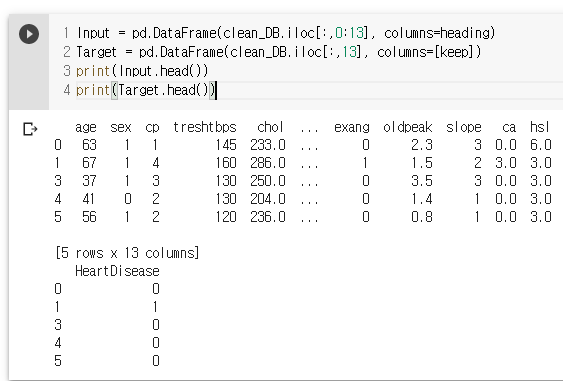
print(Target['HeartDisease'].sum())
print(Target['HeartDisease'].mean()) // 평균
* 표준정규분포
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_DB = scaler.fit_transform(Input)
scaled_DB = pd.DataFrame(scaled_DB, columns=heading)
print(scaled_DB.head())
print(scaled_DB.describe())
print(scaled_DB.describe().T)
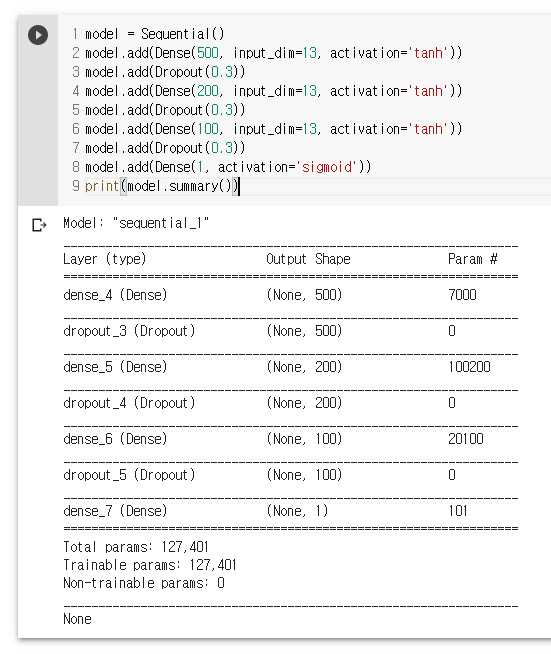
model = Sequential() // 레이어를 순차적으로 , 케라스 , 빈 모델 ,
model.add(Dense(500, input_dim=13, activation='tanh')) // Dense 레이어 , 조밀하다
model.add(Dropout(0.3))
model.add(Dense(200, input_dim=13, activation='tanh'))
model.add(Dropout(0.3))
model.add(Dense(100, input_dim=13, activation='tanh'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid')) // 출력 1개
print(model.summary())훈련용 데이터와 검증용 데이터로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(scaled_DB, Target, test_size=0.30, random_state=5) // 30% 테스트용, 70% 훈련
print('X_train shape : ', X_train.shape)
print('X_test shape : ', X_test.shape)
print('Y_train shape : ', Y_train.shape)
print('Y_test shape : ', Y_test.shape)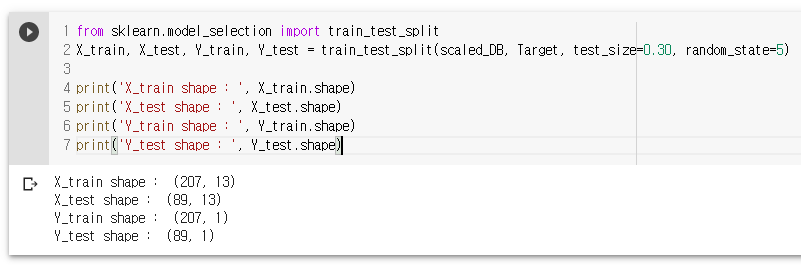
* dropout: 30% 버림
모델 컴파일: 알고리즘을 어떤걸 사용할지 결정
model.compile(loss='mse', optimizer='adam', batch_size=50, epoch=50, validation_split=0.2, verbose=1)mse: 에러의 제곱에 평균
학습
Y_train: 정답,
batch_size: 50번 풀고 답 맞추고,
validation_split:스스로 검증, traing set 중에 20%를 남겨 두었다가 스스로 체크
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
fit_hist = model.fit(X_train, Y_train, batch_size=50,
epochs=50, validation_split=0.2, verbose=1)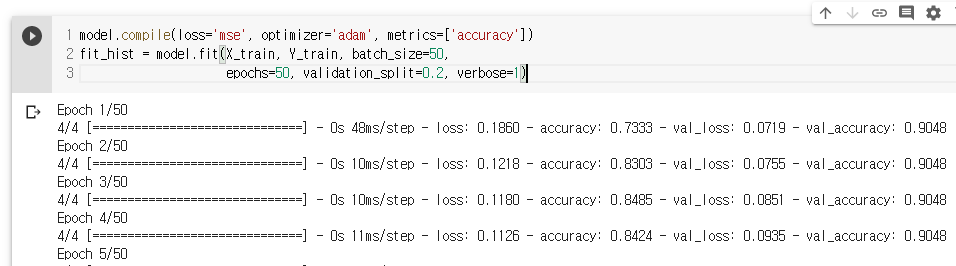
- val_accuracy: 자체 모의고사, 과적합, 문제를 외우게 됨, 문제를 이해하지 않고,
-> 안면인식 시 얼굴에 수박씨가 있으면 인식이 안됨
- dropout: 과적합 처리, 망각, 때문에 머신러닝은 데이터가 많아야 학습이 제대로 됨
plt.plot(fit_hist.history['accuracy'])
plt.plot(fit_hist.history['val_accuracy'])
plt.show()
검증
verbose: 0 , 학습과정은 안보고 결과만 봄
score = model.evaluate(X_test, Y_test, verbose=0)
print('Keras DNN model loss : ', score[0])
print('Keras DNN model accuracy : ', score[1])
심장병 여부를 80 % 는 맞춤
왓슨 인공지능
https://ko.wikipedia.org/wiki/%EC%99%93%EC%8A%A8_(%EC%BB%B4%ED%93%A8%ED%84%B0)
혼동행렬
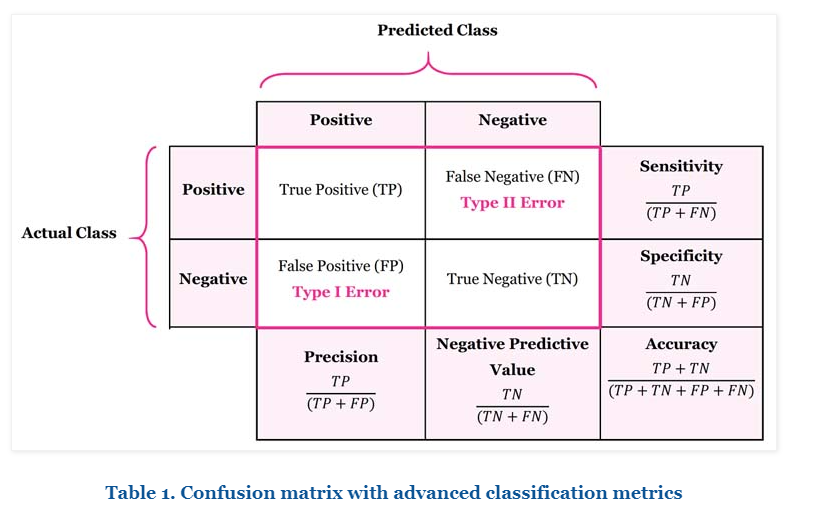
FN-스팸이 아닌데 스팸으로 판단
FP-스팸인데 스팸이 아님으로 판단
Accuracy-정답율
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
pred = model.predict(X_test)
pred = (pred > 0.5)
print(confusion_matrix(Y_test, pred), '\n')
print(f1_score(Y_test, pred, average='micro'))
80 % 맞춤, 11과 5가 문제
F1 score
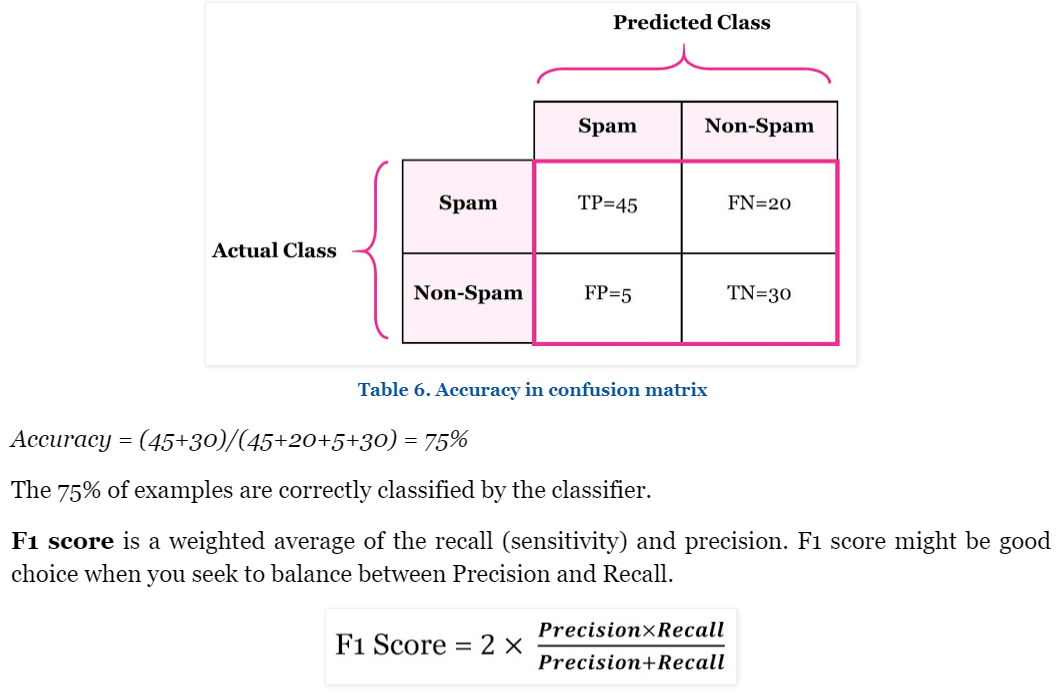
* 다중분류
- 2중 분류를 여러번 한 것
-- coding: utf-8 --
"""HeartDisease_predict.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1d0BA6ivEwXiK6fmJgHgvI9w0-8DsjJkW
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
import xlrd
heading = ['age', 'sex', 'cp', 'treshtbps', 'chol', 'fbs', 'restecg', 'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'hsl', 'HeartDisease']
raw_DB = pd.read_excel('./dataset/heart-disease.xlsx', header=None, names=heading)
print(raw_DB.head(2))
print(raw_DB.tail(2))
print(raw_DB.describe())
print(raw_DB.info())
clean_DB = raw_DB.replace("?", np.nan)
clean_DB = clean_DB.dropna()
print(clean_DB.info())
keep = heading.pop()
print(keep)
print(heading)
Input = pd.DataFrame(clean_DB.iloc[:,0:13], columns=heading)
Target = pd.DataFrame(clean_DB.iloc[:,13], columns=[keep])
print(Input.head())
print(Target.head())
print(Target['HeartDisease'].sum())
print(Target['HeartDisease'].mean())
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_DB = scaler.fit_transform(Input)
scaled_DB = pd.DataFrame(scaled_DB, columns=heading)
print(scaled_DB.head())
print(scaled_DB.describe().T)
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(scaled_DB, Target, test_size=0.30, random_state=5)
print('X_train shape : ', X_train.shape)
print('X_test shape : ', X_test.shape)
print('Y_train shape : ', Y_train.shape)
print('Y_test shape : ', Y_test.shape)
model = Sequential()
model.add(Dense(500, input_dim=13, activation='tanh'))
model.add(Dropout(0.3))
model.add(Dense(200, input_dim=13, activation='tanh'))
model.add(Dropout(0.3))
model.add(Dense(100, input_dim=13, activation='tanh'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
print(model.summary())
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
fit_hist = model.fit(X_train, Y_train, batch_size=50,
epochs=50, validation_split=0.2, verbose=1)
plt.plot(fit_hist.history['accuracy'])
plt.plot(fit_hist.history['val_accuracy'])
plt.show()
score = model.evaluate(X_test, Y_test, verbose=0)
print('Keras DNN model loss : ', score[0])
print('Keras DNN model accuracy : ', score[1])
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
pred = model.predict(X_test)
pred = (pred > 0.5)
print(confusion_matrix(Y_test, pred), '\n')
print(f1_score(Y_test, pred, average='micro'))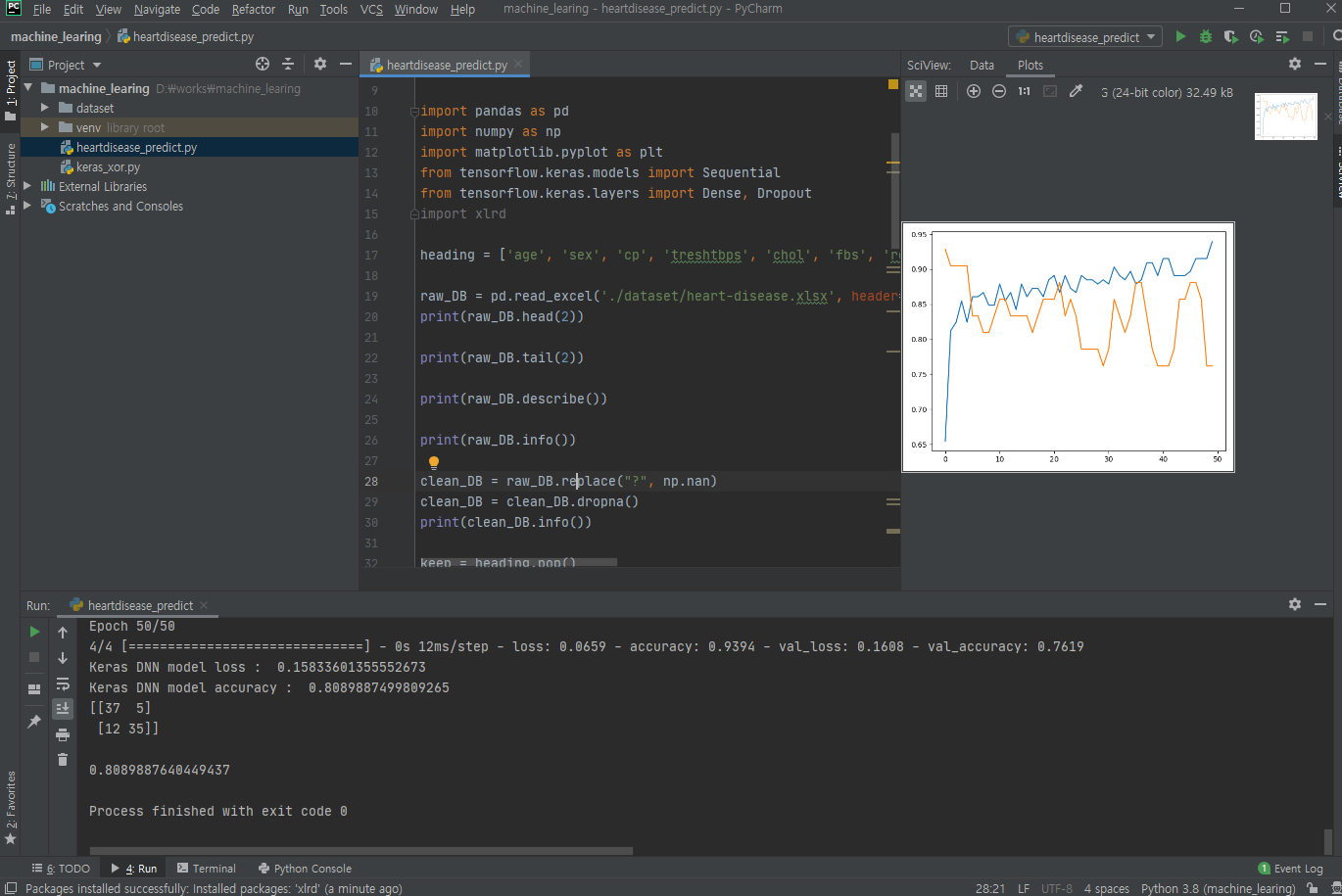
iris_classfication.ipynb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder // 다중분류
iris = load_iris()
print(type(iris))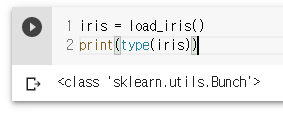
print('== Data shape ==')
print('Data : ', iris.data.shape)
print('Label : ', iris.target.shape)
print('First five data : ', iris.data[:5])
print(iris.data[:5])
print('First five label : ', iris.target[:5])
print('iris_dataset keys \n', iris.keys())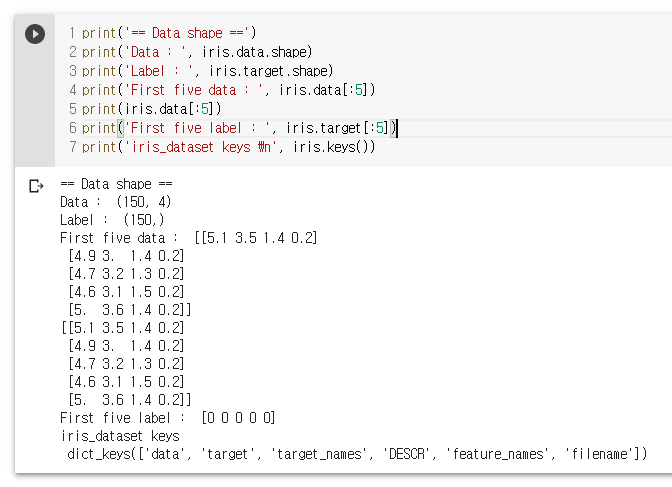
print(iris.target_names)
print(iris.feature_names)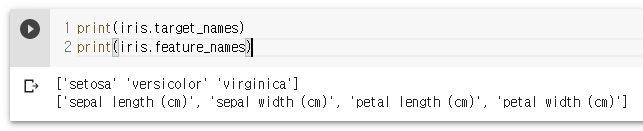
전처리
x = iris.data
y = iris.target.reshape(-1,1) // 결과가 3개 , [1,0,0] , [0,1,0] , [0,0,1] , 희소행렬
print(y.shape)
print(y[:5])
encoder = OneHotEncoder(sparse = False)
y_scaled = encoder.fit_transform(y)
print(y_scaled.shape)
print(y_scaled[:5])
encoder = OneHotEncoder(sparse = False)
y_scaled = encoder.fit_transform(y)
print(y_scaled.shape)
print(y_scaled[:5])
print(y_scaled[50:55])
print(y_scaled[100:105])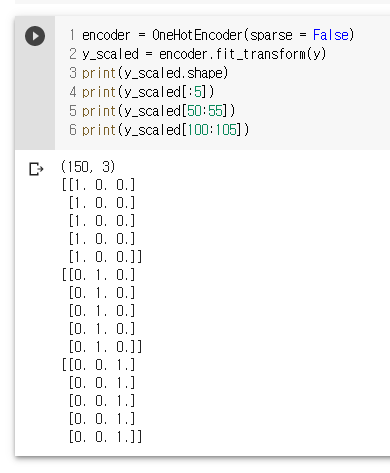
데이터 분리
X_train, X_test, Y_train, Y_test = train_test_split(x, y_scaled, test_size=0.20)
print(X_train.shape, X_test.shape)
print(Y_train.shape, Y_test.shape)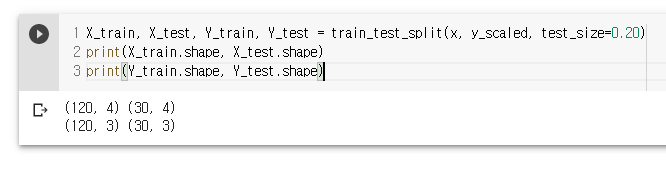
다중분류 모델생성 및 컴파일
model = Sequential()
model.add(Dense(256, input_shape=(4,),activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(3, activation='softmax'))
opt = Adam(lr=0.001)
model.compile(opt, loss='categorical_crossentropy', metrics=['accuracy'])
print(model.summary())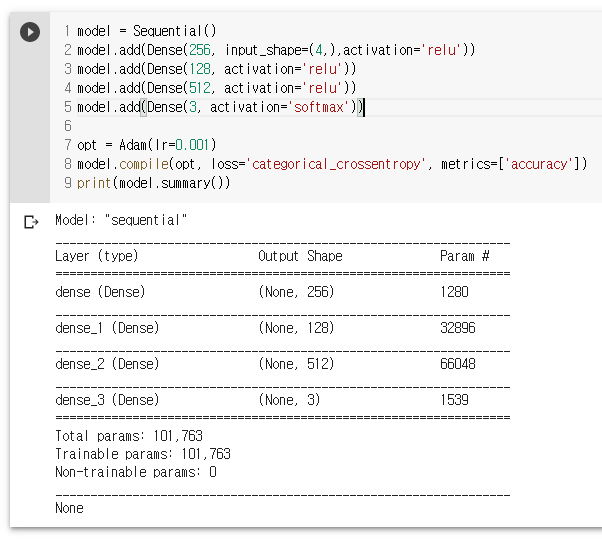
학습시킴
fit_hist = model.fit(X_train, Y_train, batch_size=5, epochs=5, verbose=1)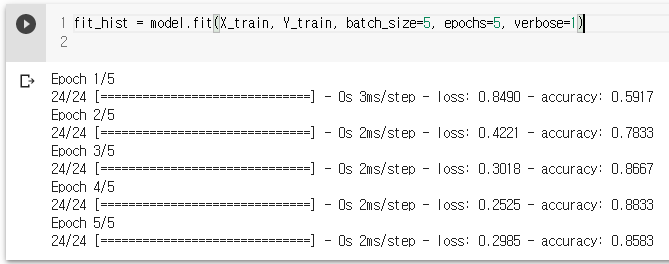
검증
result = model.evaluate(X_test, Y_test, verbose=0)
print('Final test set accuracy : ', result[1])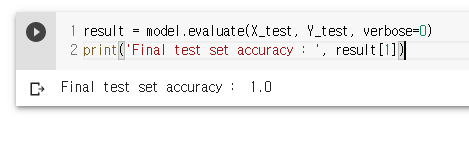
100 % 확률, 과적합
labels = iris.target_names
my_sample = np.random.randint(30) // 0-29 사이 int 값
sample = X_test[my_sample]
sample = sample.reshape(1, 4) // 모양 변경
pred = model.predict(sample)
print(pred)
print(Y_test[my_sample])
print('Target : ', labels[np.argmax(Y_test[my_sample])]) // argmax : 제일 큰 값의 index 값 리턴
print('Prediction after learning is ', labels[np.argmax(pred)])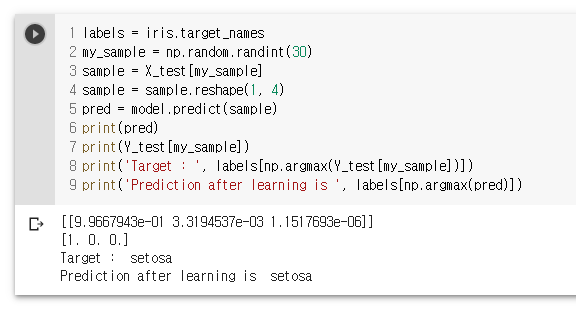
첫번째 90%, 두번째 70%, 세번째 20 %
-> 70% 확률로 versicolor 로 추정
Principles_of_learning.ipynb
# 연산식을 시각화
class AddGraph:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1 # x 에 대해 미분
dy = dout * 1 # y 에 대해 미분
return dx, dy
class MulGraph:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # x에 대해 미분
dy = dout * self.x # y에 대해 미분
return dx, dy
apple = 100
apple_num = 2
orange = 150
orange_num = 3
tax = 1.1
mul_apple_graph = MulGraph() # 곱셈그래프
mul_orange_graph = MulGraph()
add_apple_orange_graph = AddGraph() # 덧셈그래프
mul_tax_graph = MulGraph()
apple_price = mul_apple_graph.forward(apple, apple_num)
orange_price = mul_orange_grapn.forward(orange, orange_num)
all_price = add_apple_orange_graph.forward(apple_price, orange_price)
price = mul_tax_graph.forward(all_price, tax)
print(price)
dprice = 1
dall_price, dtax = mul_tax_graph.backward(dprice)
dapple_price, dorange_price = add_apple_orange_graph.backward(dall_price)
dorange, dorange_num = mul_orange_grapn.backward(dorange_price)
dapple, dapple_num = mul_apple_graph.backward(dapple_price)
print('dApple :', dapple)
print('dApple num : ', dapple_num)
print('dOrange : ', dorange)
print('dOrange num : ', dorange_num)
체인 룰
섭씨 온도를 화씨 온도로
import numpy as np
weight = np.random.uniform(0, 5, 1)
print(weight)
import numpy as np
weight = np.random.uniform(0, 5, 1)[0]
print(weight)
import numpy as np
def celcius_to_fahrenheit(x):
return x * 1.8 + 35
weight_graph = MulGraph() # 곱하기 그래프
bias_graph = AddGraph() # 더하기 그래프
weight = np.random.uniform(0, 5, 1)[0]
print(weight)
bias = 0
data_C = np.array(range(0, 100),)
data_F = celcius_to_fahrenheit(data_C)
scaled_data_C = data_C / 100
scaled_data_F = data_F / 100
#forward
weighted_data = weight_graph.forward(weight, scaled_data_C)
predict_data = bias_graph.forward(weighted_data, bias)
print(predict_data[1]) # 1/100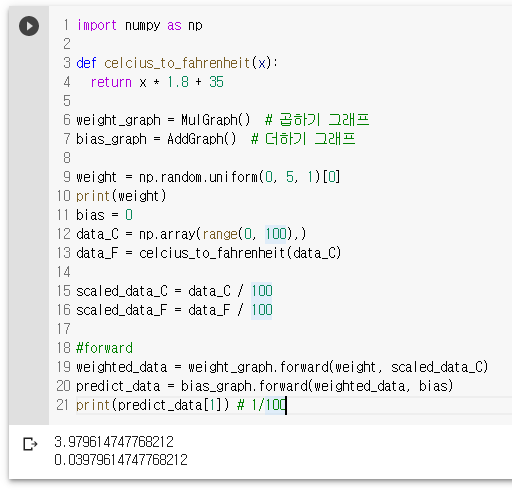
weight 와 bias 에 대한 미분
곱해서 빼주면서 찾기
class AddGraph:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1 # x 에 대해 미분
dy = dout * 1 # y 에 대해 미분
return dx, dy
class MulGraph:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # x에 대해 미분
dy = dout * self.x # y에 대해 미분
return dx, dy
#print(scaled_data_F.shape)
class MSE:
def __init__(self):
self.loss = None
self.y = None
self.t = None
self.x = None
def forward(self, y, t): # y 는 예측값, t 는 정답
self.t = t
self.y = y
self.loss = np.square(self.t - self.y).sum() / self.t.shape[0] # 에러를 제곱하여 합을 갯수로 나눔 = 평균
return self.loss
def backward(self, x, dout=1):
self.x = x
data_size = self.t.shape[0]
dweight_mse = ((self.y - self.t) * x).sum() * 2 / data_size # weight 에 대한 편미분
dbias_mse = (self.y - self.t).sum() * 2 / data_size
return dweight_mse, dbias_mse
apple = 100
apple_num = 2
orange = 150
orange_num = 3
tax = 1.1
mul_apple_graph = MulGraph() # 곱셈그래프
mul_orange_grapn = MulGraph()
add_apple_orange_graph = AddGraph() # 덧셈그래프
mul_tax_graph = MulGraph()
apple_price = mul_apple_graph.forward(apple, apple_num)
orange_price = mul_orange_grapn.forward(orange, orange_num)
all_price = add_apple_orange_graph.forward(apple_price, orange_price)
price = mul_tax_graph.forward(all_price, tax)
print(price)
dprice = 1 # price 에 대한 미분값
dall_price, dtax = mul_tax_graph.backward(dprice) # all_price, tax 에 대한 미분값
dapple_price, dorange_price = add_apple_orange_graph.backward(dall_price) # apple_price, orange_price 에 대한 미분값
dorange, dorange_num = mul_orange_grapn.backward(dorange_price)
dapple, dapple_num = mul_apple_graph.backward(dapple_price)
print('dApple :', dapple)
print('dApple num : ', dapple_num)
print('dOrange :', dorange)
print('dOrange num : ', dorange_num)
import numpy as np
def celcius_to_fahrenheit(x):
return x * 1.8 + 35
weight_graph = MulGraph() # 곱하기 그래프
bias_graph = AddGraph() # 더하기 그래프
weight = np.random.uniform(0, 5, 1)[0]
print(weight)
bias = 0
data_C = np.array(range(0, 100),)
data_F = celcius_to_fahrenheit(data_C)
scaled_data_C = data_C / 100
scaled_data_F = data_F / 100
#forward
weighted_data = weight_graph.forward(weight, scaled_data_C)
predict_data = bias_graph.forward(weighted_data, bias)
print(predict_data[1]) # 1/100
#backward : 미분값을 찾기위해 함
dout = 1
dbias, dbiased_data = bias_graph.backward(dout)
dweight, dscaled_data_C = weight_graph.backward(dbiased_data)
print(dbiased_data)
print(dscaled_data_C)
# 에러 값 구함
mse_graph = MSE()
mse = mse_graph.forward(predict_data, scaled_data_F) # 에러 제곱 평균
print(mse)
# backward
weight_mse_gradient, bias_mse_gradient = mse_graph.backward(scaled_data_C)
print(weight_mse_gradient)
print(bias_mse_gradient)
#leaning_rate = 0.001
leaning_rate = 0.005
leaned_weight = weight - weight_mse_gradient * leaning_rate * dscaled_data_C # leaned_weight 를 계속 수정하면서 기울기를 줄여감
print('before leaning weight : ', weight)
print('after leaning weight : ', leaned_weight)
leaned_bias = bias - bias_mse_gradient * leaning_rate * dbiased_data
print('before leaning wbias : ', bias)
print('after leaning bias : ', leaned_bias)
# 학습
error_list = [] # 에러 list
weight_list = [] # 수정되는 weight list
bias_list = []
weight_mse_gradient_list = []
bias_mse_gradient_list = []
for i in range(3000):
#forward
weighted_data = weight_graph.forward(weight, scaled_data_C)
predict_data = bias_graph.forward(bias, weighted_data)
#backward
dout = 1
dbias, dbias_data = bias_graph.backward(dout)
dweight, dscaled_data_C = weight_graph.backward(dbiased_data)
mse = mse_graph.forward(predict_data, scaled_data_F)
error_list.append(mse)
weight_mse_gradient, bias_mse_gradient = mse_graph.backward(scaled_data_C) # 기울기를 찾음
weight_mse_gradient_list.append(weight_mse_gradient)
bias_mse_gradient_list.append(bias_mse_gradient)
weight = weight - weight_mse_gradient * dscaled_data_C * leaning_rate
weight_list.append(weight)
bias = bias - bias_mse_gradient * dbias_data * leaning_rate
bias_list.append(bias)
#print(weight_list)
#print(bias_list)
import pandas as pd
df = pd.DataFrame({'weight':weight_list, 'bias':bias_list})
print(df.head())
print(df.tail())
import matplotlib.pyplot as plt
plt.plot(weight_list)
plt.show()
plt.plot(bias_list)
plt.show()
plt.plot(weight_mse_gradient_list)
plt.show()
plt.plot(bias_mse_gradient_list)
plt.show()
plt.plot(error_list)
plt.show() 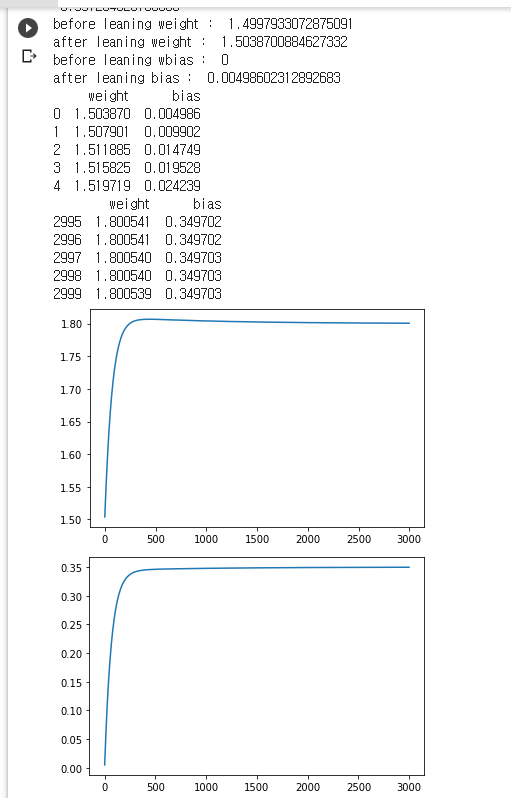
leaning_rate 가 너무 크면 발산되고, 너무 작으면 오래걸리거나 중간에 끝나버림

곱해서 빼주면서 찾기
class AddGraph:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1 # x 에 대해 미분
dy = dout * 1 # y 에 대해 미분
return dx, dy
class MulGraph:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # x에 대해 미분
dy = dout * self.x # y에 대해 미분
return dx, dy
#print(scaled_data_F.shape)
class MSE:
def __init__(self):
self.loss = None
self.y = None
self.t = None
self.x = None
def forward(self, y, t): # y 는 예측값, t 는 정답
self.t = t
self.y = y
self.loss = np.square(self.t - self.y).sum() / self.t.shape[0] # 에러를 제곱하여 합을 갯수로 나눔 = 평균
return self.loss
def backward(self, x, dout=1):
self.x = x
data_size = self.t.shape[0]
dweight_mse = ((self.y - self.t) * x).sum() * 2 / data_size # weight 에 대한 편미분
dbias_mse = (self.y - self.t).sum() * 2 / data_size
return dweight_mse, dbias_mse
apple = 100
apple_num = 2
orange = 150
orange_num = 3
tax = 1.1
mul_apple_graph = MulGraph() # 곱셈그래프
mul_orange_grapn = MulGraph()
add_apple_orange_graph = AddGraph() # 덧셈그래프
mul_tax_graph = MulGraph()
apple_price = mul_apple_graph.forward(apple, apple_num)
orange_price = mul_orange_grapn.forward(orange, orange_num)
all_price = add_apple_orange_graph.forward(apple_price, orange_price)
price = mul_tax_graph.forward(all_price, tax)
print(price)
dprice = 1 # price 에 대한 미분값
dall_price, dtax = mul_tax_graph.backward(dprice) # all_price, tax 에 대한 미분값
dapple_price, dorange_price = add_apple_orange_graph.backward(dall_price) # apple_price, orange_price 에 대한 미분값
dorange, dorange_num = mul_orange_grapn.backward(dorange_price)
dapple, dapple_num = mul_apple_graph.backward(dapple_price)
print('dApple :', dapple)
print('dApple num : ', dapple_num)
print('dOrange :', dorange)
print('dOrange num : ', dorange_num)
import numpy as np
def celcius_to_fahrenheit(x):
return x * 1.8 + 35
weight_graph = MulGraph() # 곱하기 그래프
bias_graph = AddGraph() # 더하기 그래프
weight = np.random.uniform(0, 5, 1)[0]
print(weight)
bias = 0
data_C = np.array(range(0, 100),)
data_F = celcius_to_fahrenheit(data_C)
scaled_data_C = data_C / 100
scaled_data_F = data_F / 100
#forward
weighted_data = weight_graph.forward(weight, scaled_data_C)
predict_data = bias_graph.forward(weighted_data, bias)
print(predict_data[1]) # 1/100
#backward : 미분값을 찾기위해 함
dout = 1
dbias, dbiased_data = bias_graph.backward(dout)
dweight, dscaled_data_C = weight_graph.backward(dbiased_data)
print(dbiased_data)
print(dscaled_data_C)
# 에러 값 구함
mse_graph = MSE()
mse = mse_graph.forward(predict_data, scaled_data_F) # 에러 제곱 평균
print(mse)
# backward
weight_mse_gradient, bias_mse_gradient = mse_graph.backward(scaled_data_C)
print(weight_mse_gradient)
print(bias_mse_gradient)
leaning_rate = 0.05
leaned_weight = weight - weight_mse_gradient * leaning_rate * dscaled_data_C # leaned_weight 를 계속 수정하면서 기울기를 줄여감
print('before leaning weight : ', weight)
print('after leaning weight : ', leaned_weight)
leaned_bias = bias - bias_mse_gradient * leaning_rate * dbiased_data
print('before leaning wbias : ', bias)
print('after leaning bias : ', leaned_bias)
# 학습
error_list = [] # 에러 list
weight_list = [] # 수정되는 weight list
bias_list = []
weight_mse_gradient_list = []
bias_mse_gradient_list = []
for i in range(3000):
#forward
weighted_data = weight_graph.forward(weight, scaled_data_C)
predict_data = bias_graph.forward(bias, weighted_data)
#backward
dout = 1
dbias, dbias_data = bias_graph.backward(dout)
dweight, dscaled_data_C = weight_graph.backward(dbiased_data)
mse = mse_graph.forward(predict_data, scaled_data_F)
error_list.append(mse)
weight_mse_gradient, bias_mse_gradient = mse_graph.backward(scaled_data_C) # 기울기를 찾음
weight_mse_gradient_list.append(weight_mse_gradient)
bias_mse_gradient_list.append(bias_mse_gradient)
weight = weight - weight_mse_gradient * dscaled_data_C * leaning_rate
weight_list.append(weight)
bias = bias - bias_mse_gradient * dbias_data * leaning_rate
bias_list.append(bias)
#print(weight_list)
#print(bias_list)
import pandas as pd
df = pd.DataFrame({'weight':weight_list, 'bias':bias_list})
print(df.head())
print(df.tail())
import matplotlib.pyplot as plt
plt.plot(weight_list)
plt.show()
plt.plot(bias_list)
plt.show()
plt.plot(weight_mse_gradient_list)
plt.show()
plt.plot(bias_mse_gradient_list)
plt.show()
plt.plot(error_list)
plt.show()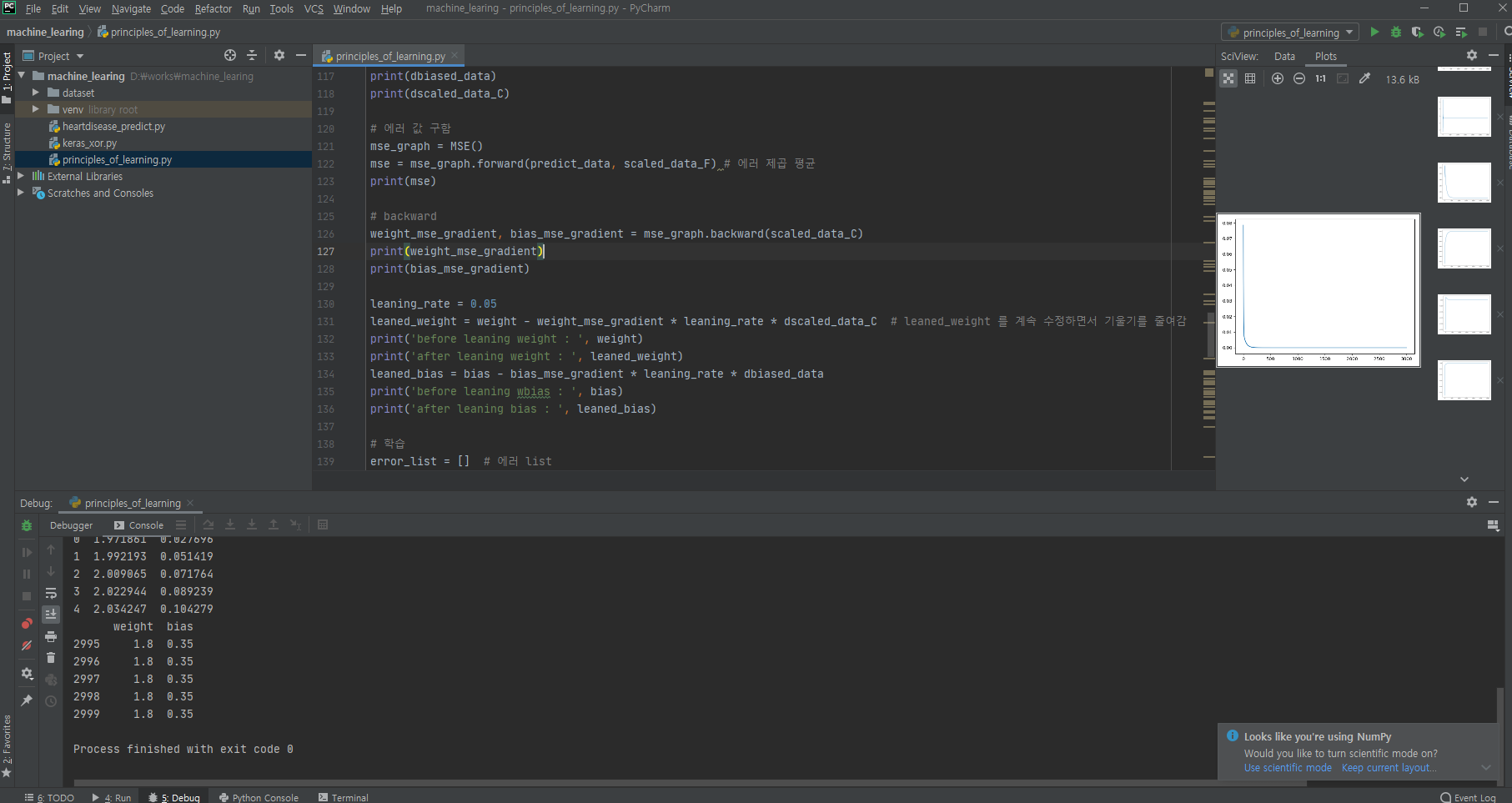
xor_python.ipynb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def step(x): return np.array(x>0, dtype=np.int)
X = np.array([[0,0],[0,1],[1,0],[1,1]])
Y = np.array([[0],[1],[1],[1]])
W_layer_1 = np.array([[0.2, 0.8, 0.1], [0.0, 0.2, 0.9]])
W_layer_2 = np.array([[0.4], [0.4], [0.09]])
print(X)
print(W_layer_1)
print(np.dot(X, W_layer_1))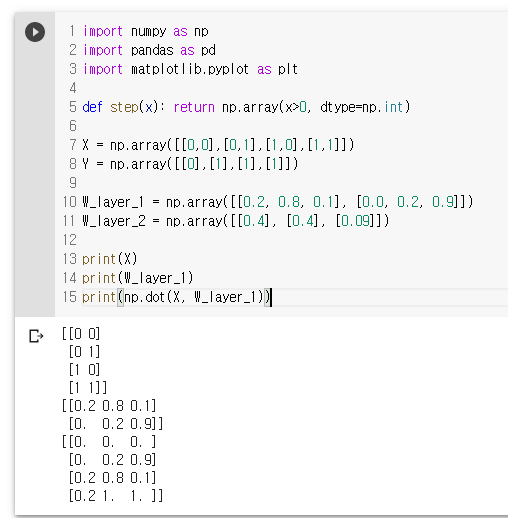


스텝 함수에서 시그모이드 함수로
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def step(x): return np.array(x>0, dtype=np.int) # false 0, true 1
X = np.array([[0,0],[0,1],[1,0],[1,1]])
#Y = np.array([[0],[1],[1],[1]]) # OR GATE
Y = np.array([[0],[1],[1],[0]]) # XOR GATE
W_layer_1 = np.array([[0.2, 0.8, 0.1], [0.0, 0.2, 0.9]]) # 레이어는 weight 값을 가지고 있는 것
W_layer_2 = np.array([[0.4], [0.4], [0.09]])
print(X)
print(W_layer_1)
print(np.dot(X, W_layer_1))
layer1_output = step(np.dot(X, W_layer_1))
print(np.dot(layer1_output, W_layer_2))
layer2_output = np.dot(layer1_output, W_layer_2)
print('Input is ', X)
print('expected output is ', Y)
print('predict is ', layer2_output)
inputSize, layer1Size, layer2Size = 2, 3, 1 # 입력, 레이어,출력
learning_rate = 0.1
def sigmoid(x): return 1/ (1 + np.exp(-x)) # 시그모이드 함수
def sigmoid_derivative(x): return x * (1 - x) # 미분
W_layer_1 = np.random.uniform(size=(inputSize, layer1Size))
W_layer_2 = np.random.uniform(size=(layer1Size, layer2Size))
layer1_output = sigmoid(np.dot(X, W_layer_1))
layer2_output = sigmoid(np.dot(layer1_output, W_layer_2))
error_list = []
for i in range(20000):
layer1_output = sigmoid(np.dot(X, W_layer_1))
layer2_output = sigmoid(np.dot(layer1_output, W_layer_2))
E = np.square(Y - layer2_output).sum() / 4
error_list.append(E)
layer2_grad = (layer2_output - Y) * sigmoid_derivative(layer2_output) # 미분
layer1_grad = layer2_grad.dot(W_layer_2.T) * sigmoid_derivative(layer1_output)
W_layer_2 = W_layer_2 - learning_rate * np.dot(layer1_output.T, layer2_grad)
W_layer_1 = W_layer_1 - learning_rate * np.dot(X.T, layer1_grad)
print('Input is ', X)
print('expected output is ', Y)
print('predict is ', layer2_output)
plt.plot(error_list)
plt.show()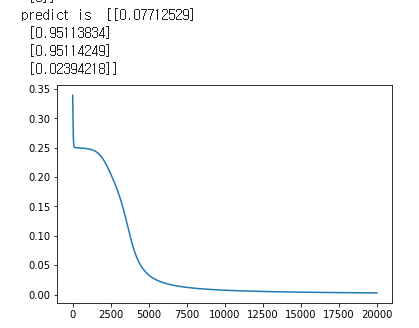
Mnist_classfication.ipynb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from keras.utils import np_utils
from keras import datasets
def DNN_ModelSequential(n_input, n_hidden, n_hidden2, n_out):
model = Sequential()
model.add(Dense(n_hidden, input_shape=(n_input,), activation='relu'))
model.add(Dense(n_hidden2, activation='relu'))
model.add(Dense(n_out, activation='softmax'))
opt = Adam(lr=0.01)
model.compile(opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
# 데이터 준비
# keras datasets 1회만 다운로드 함
(X_train, Y_train), (X_test, Y_test) = datasets.mnist.load_data()
print(X_train.shape, Y_train.shape)
print(X_test.shape, Y_test.shape)
# 데이터 확인
mySample = np.random.randint(60000)
plt.imshow(X_train[mySample])
plt.show()
print(Y_train[mySample])
print(X_train[mySample])
# 28 x 28 , Y_train: 정답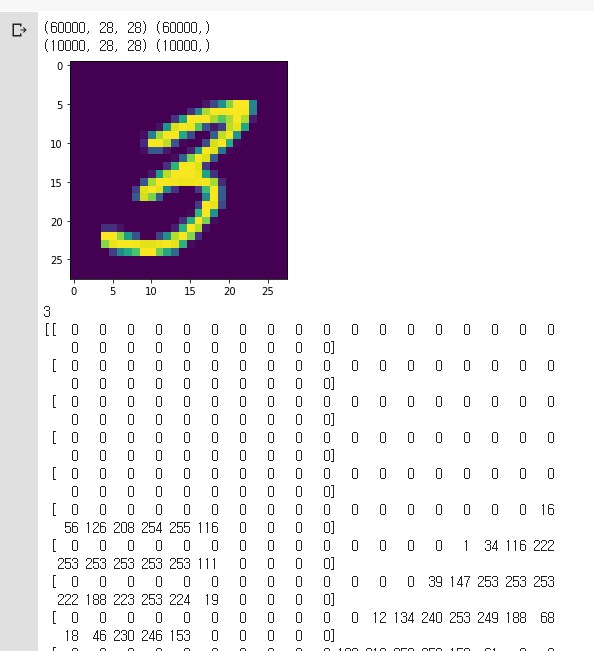
데이터 전처리
def Data_func():
(X_train, Y_train), (X_test, Y_test) = datasets.mnist.load_data()
Y_train = np_utils.to_categorical(Y_train)
Y_test = np_utils.to_categorical(Y_test)
L, W, H = X_train.shape
X_train = X_train.reshape(-1, W * H)
X_test = X_test.reshape(-1, W * H)
X_train = X_train / 255
X_test = X_test / 255
return (X_train, Y_train), (X_test, Y_test)
# 입력 784 개 , 히든 레이어 , 최종출력 10 개
model = DNN_ModelSequential(784, 128, 128, 10)
(x_train, y_train), (x_test, y_test) = Data_func()
print(model.summary())
print(x_train.shape, y_train.shape)
fit_hist = model.fit(x_train, y_train, epochs=15, batch_size=128, validation_split=0.2)
performance_test = model.evaluate(x_test, y_test, batch_size=128)
print('test Loss Accurecy -> ',performance_test)
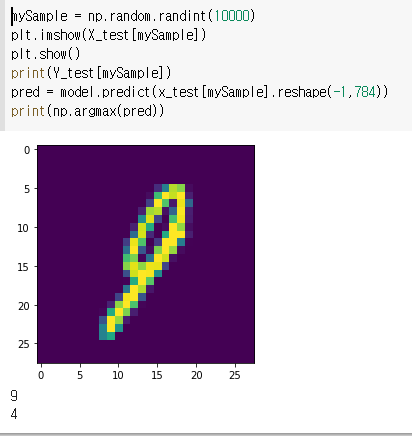
mySample = np.random.randint(10000)
plt.imshow(X_test[mySample])
plt.show()
print(Y_test[mySample])
pred = model.predict(x_test[mySample].reshape(-1,784))
print(np.argmax(pred))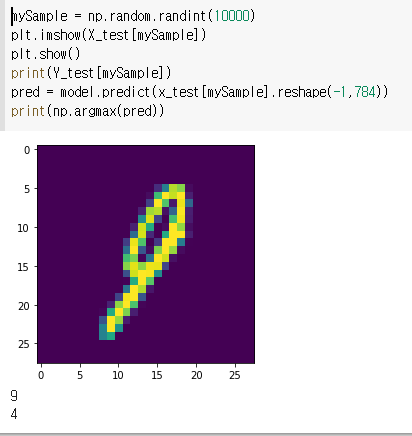
plt.plot(fit_hist.history['loss'])
plt.plot(fit_hist.history['val_loss'])
plt.show()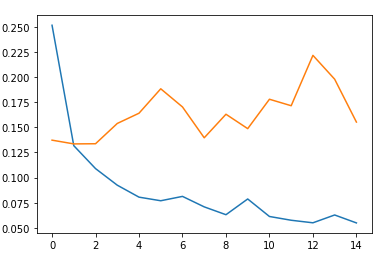
plt.plot(fit_hist.history['accuracy'])
plt.plot(fit_hist.history['val_accuracy'])
plt.show()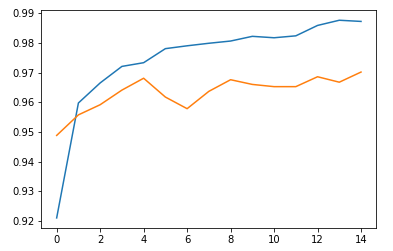
Fashion_Mnist_classfication.ipynb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from keras.utils import np_utils
from keras import datasets
def DNN_ModelSequential(n_input, n_hidden, n_hidden2, n_out):
model = Sequential()
model.add(Dense(n_hidden, input_shape=(n_input,), activation='relu'))
model.add(Dense(n_hidden2, activation='relu'))
model.add(Dense(n_out, activation='softmax'))
opt = Adam(lr=0.01)
model.compile(opt, loss='categorical_crossentropy', metrics=['accuracy'])
return model
label = ['T-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']데이터 준비
keras datasets 1회만 다운로드 함
(X_train, Y_train), (X_test, Y_test) = datasets.fashion_mnist.load_data()
print(X_train.shape, Y_train.shape)
print(X_test.shape, Y_test.shape)데이터 확인
mySample = np.random.randint(60000)
plt.imshow(X_train[mySample])
plt.show()
print(label[Y_train[mySample]])
print(X_train[mySample])데이터 전처리
def Data_func():
(X_train, Y_train), (X_test, Y_test) = datasets.fashion_mnist.load_data()
Y_train = np_utils.to_categorical(Y_train)
Y_test = np_utils.to_categorical(Y_test)
L, W, H = X_train.shape
X_train = X_train.reshape(-1, W * H)
X_test = X_test.reshape(-1, W * H)
X_train = X_train / 255
X_test = X_test / 255
return (X_train, Y_train), (X_test, Y_test)
# 입력 784 개 , 히든 레이어 , 최종출력 10 개
model = DNN_ModelSequential(784, 128, 128, 10)
(x_train, y_train), (x_test, y_test) = Data_func()
print(model.summary())
print(x_train.shape, y_train.shape)
fit_hist = model.fit(x_train, y_train, epochs=15, batch_size=128, validation_split=0.2)
performance_test = model.evaluate(x_test, y_test, batch_size=128)
print('test Loss Accurecy -> ',performance_test)
mySample = np.random.randint(10000)
plt.imshow(X_test[mySample])
plt.show()
#print(Y_test[mySample])
print(label[Y_test[mySample]])
pred = model.predict(x_test[mySample].reshape(-1,784))
#print(np.argmax(pred))
print(label[np.argmax(pred)])
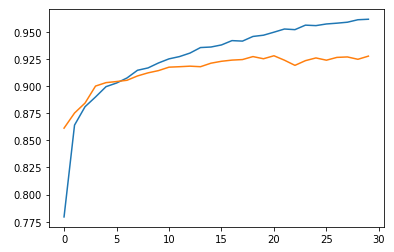
plt.plot(fit_hist.history['loss'])
plt.plot(fit_hist.history['val_loss'])
plt.show()
plt.plot(fit_hist.history['accuracy'])
plt.plot(fit_hist.history['val_accuracy'])
plt.show()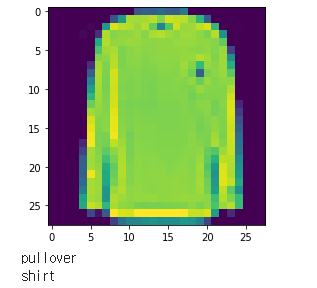
CNN_Fashion_MNIST_classfication.ipynb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Activation
from tensorflow.keras.layers import MaxPool2D, Conv2D, InputLayer, Dropout
from tensorflow.keras.optimizers import Adam
from keras.utils import np_utils
from keras import datasets
label = ['T-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
(X_train, Y_train), (X_test, Y_test) = datasets.fashion_mnist.load_data()
print(X_train.shape, Y_train.shape)
print(X_test.shape, Y_test.shape)
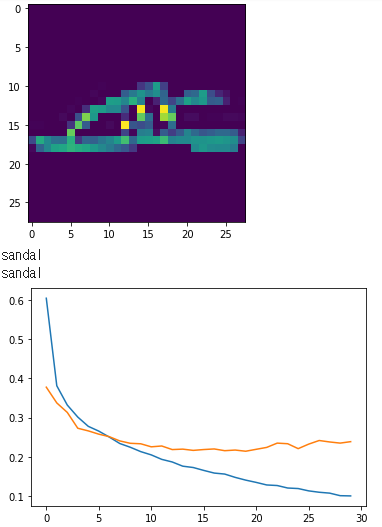
mySample = np.random.randint(60000)
plt.imshow(X_train[mySample])
plt.show()
print(label[Y_train[mySample]])
print(X_train[mySample])
model = Sequential()
model.add(InputLayer(input_shape=(28,28,1))) # 1: 채널 수 , 단색
model.add(Conv2D(32, kernel_size=(3,3), padding='same', activation='relu'))
model.add(MaxPool2D(padding='same', pool_size=(2,2)))
model.add(Conv2D(32, kernel_size=(3,3), padding='same', activation='relu'))
model.add(MaxPool2D(padding='same', pool_size=(2,2)))
model.add(Flatten()) # 레이어를 한줄로 펼침
model.add(Dropout(0.2))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax')) # 다중분류기
model.summary()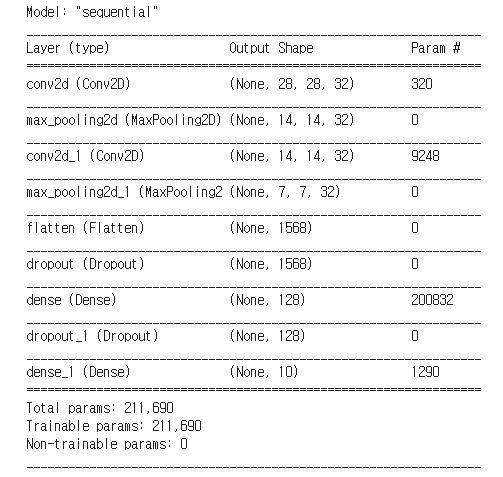
데이터 전처리
x_train = X_train / 255.0
x_test = X_test / 255.0
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
y_train = np_utils.to_categorical(Y_train, 10)
y_test = np_utils.to_categorical(Y_test, 10)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
fit_hist = model.fit(x_train, y_train, epochs=30, batch_size=128, validation_split=0.2)
score = model.evaluate(x_test, y_test)
print(score)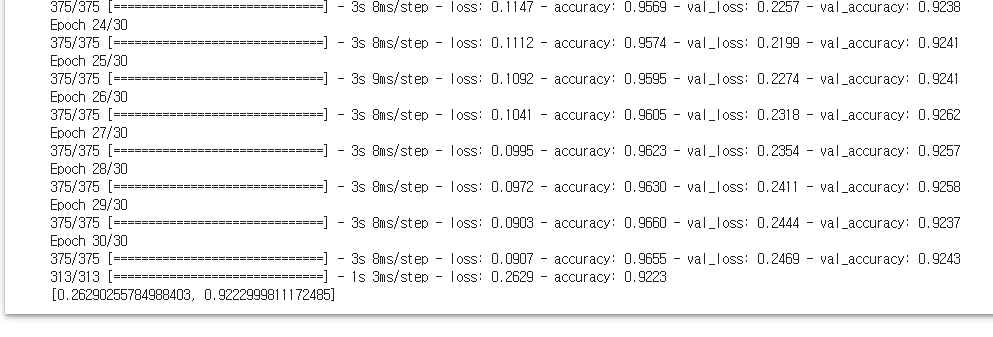
* CNN : 이미지정보 알고리즘, 빠름, 음성정보도 활용 가능
* RNN : 순서정보 알고리즘, 시간이 오래 걸림
샘플, 예측
mySample = np.random.randint(10000)
plt.imshow(X_test[mySample])
plt.show()
print(label[Y_test[mySample]])
pred = model.predict(x_test[mySample].reshape(-1,28, 28, 1))
print(label[np.argmax(pred)])
plt.plot(fit_hist.history['loss'])
plt.plot(fit_hist.history['val_loss'])
plt.show()
plt.plot(fit_hist.history['accuracy'])
plt.plot(fit_hist.history['val_accuracy'])
plt.show()