스트림
- 데이터의 흐름
- 장점
- 컬렉션(Collection) 형태로 구성된 데이터를 람다를 이용해 간결하고 직관적으로 프로세싱
for,while등을 이용하던 기존 loop 대체- 쉬운 병렬 처리
- 생성
Stream.of()이용public static<T> Stream<T> of(T... values) { return Arrays.stream(values); }
Collection.stream()이용default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); }
Stream의 구성 요소
- Stream Pipeline
- Source
- Stream의 시작
- 컬렉션, 배열 등
- Intermediate Operations
- 중간 처리 과정
- filter, map 등 중간 처리
- 여러 가지의 중간 처리를 계속 이어 붙일 수 있음
- Terminal Operation
- 종결 처리
- Collect, reduce 등
- Source
Filter
- Predicate에서 true일 경우만 걸러주는 필터 메소드
Stream<T> filter(Predicate<? super T> predicate);
Map
- 데이터를 변형하는데 사용
- 데이터에 해당 함수가 적용된 결과물을 제공하는 streamㅇ르 리턴
<R> Stream<R> map(Function<? super T, ? extends R> mapper);- T 나 T super 타입을 받아서 mapper를 적용해 R(Return)을 반환
Sorted
- 데이터가 순서대로 정렬된 stream을 리턴
- 데이터의 종류에 따라 Comparator 필요
- 정의
- `Stream sorted();
Stream<T> sorted(Comparator<? super T> comparator);
Distinct
- 중복되는 데이터 제거
- Object의 경우 notEquals로 비교하기 때문에 조심
Stream<T> distinct();
FlatMap
- Map + Flatten
- 함수에서 stream을 리턴하는 경우
- 데이터에 함수를 적용한 후 중첩된 stream을 연결하여 하나의 stream으로 리턴
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);- T나 T super 타입을 받아 mapper를 적용하면 R타입의 stream이 나오는데 평평하게 합쳐줌
- 2차원 배열을 1차원 배열로 나타내는 과정과 비슷
Stream Advance
- 종결 처리
- 종결 처리를 통해 최종 결과물을 도출
- Lazy Evaluation
- 종결 처리의 실행이 필요할 때 중간 처리들도 비로소 실행
Max/Min/Count- 스트림 중 최댓값, 최솟값, 개수
Optional<T> max(Comparator<? super T> comparator);Optional<T> min(Comparator<? super T> comparator);long count();
All Match/Any Match- 스트림 중 [모든 | 하나라도] 데이터가 predicate를 만족하면 true
boolean allMatch(Predicate<? super T> predicate);boolean anyMatch(Predicate<? super T> predicate);boolean noneMatch(Predicate<? super T> predicate);
Find First/Find Any- 스트림 중 [첫번째 | 아무] 데이터 리턴
Optional<T> findFirst();Optional<T> findAny();
Reduce- 주어진 함수를 반복 적용해 Stream 안의 데이터를 하나의 값으로 합치는 작업
- 병렬 컴퓨팅에 자주 적용
- Max/Min/Count 도 reduce의 일종
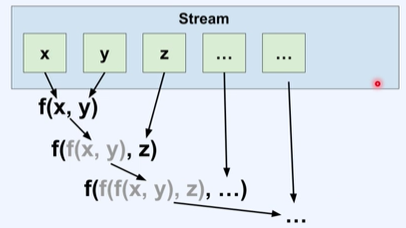
- 오버로딩
- 파라미터
- BinaryOperator 인풋과 아웃풋 타입이 모두 같은 BiFunction
- accumulator를 반복 적용
- identity은 초기값
- combiner는 병렬 작업 시 합치는 용도
Optional<T> reduce(BinaryOperator<T> accumulator);T reduce(T identity, BinaryOperator<T> accumulator);<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);- Map을 통해 U타입으로 바꿀 수 있어 잘 사용 안함
- 파라미터
- 주어진 함수를 반복 적용해 Stream 안의 데이터를 하나의 값으로 합치는 작업
To Map- Stream 안의 데이터를 map 형태(결과값:[입력값...])로 반환해주는 collector
- keyMapper 데이터를 map의 key로 변환하는 Function
- valueMapper 데이터를 map의 value로 변환하는 Function
Collector<T, ?, Map<K,U>> toMap( Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper) { return new CollectorImpl<>( HashMap::new, uniqKeysMapAccumulator(keyMapper, valueMapper), uniqKeysMapMerger(), CH_ID ); }
- Stream 안의 데이터를 map 형태(결과값:[입력값...])로 반환해주는 collector
Grouping By- Stream 안의 데이터에 classifier를 적용했을 때 결과값이 같은 값끼리 List로 모아서 Map의 형태로 반환해주는 collector
public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier) { return groupingBy(classifier, toList()); }
{결과값1 = [입력값1, 입력값2], 결과값2 = [입력값3]}- 두번째 매개변수로 downstream collector를 넘길 수 있음
- value를 모을 때, 제공 된 collector로 모을 수 있음
- 예시) 결과값 List를 Reduce를 통해 합치기, 특정 연산 하기
public static <T, K, A, D> Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream) { return groupingBy(classifier, HashMap::new, downstream); }Partitioning By- Function 대신 Predicate를 받아 true와 false 두 key가 존재하는 map을 반환
- 형태는 groupingBy와 비슷함
public static <T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) { return partitioningBy(predicate, toList()); } public static <T, D, A> Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate, Collector<? super T, A, D> downstream) { BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator(); BiConsumer<Partition<A>, T> accumulator = (result, t) -> downstreamAccumulator.accept(predicate.test(t) ? result.forTrue : result.forFalse, t); BinaryOperator<A> op = downstream.combiner(); BinaryOperator<Partition<A>> merger = (left, right) -> new Partition<>(op.apply(left.forTrue, right.forTrue), op.apply(left.forFalse, right.forFalse)); Supplier<Partition<A>> supplier = () -> new Partition<>(downstream.supplier().get(), downstream.supplier().get()); if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) { return new CollectorImpl<>(supplier, accumulator, merger, CH_ID); } else { Function<Partition<A>, Map<Boolean, D>> finisher = par -> new Partition<>(downstream.finisher().apply(par.forTrue), downstream.finisher().apply(par.forFalse)); return new CollectorImpl<>(supplier, accumulator, merger, finisher, CH_NOID); } }
For Each- 제공된 action을 Stream의 각 데이터에 적용해주는 종결 처리
- Java의 iterable 인터페이스에도 forEach가 있기 때문에 Stream의 중간 처리가 필요 없다면 iterable collection(Set, List 등)에서 바로 쓰는 것도 가능
- 정의
void forEach(Consumer<? super T> action);void forEachOrdered(Consumer<? super T> action);
- 꿀 스트림
IntStream.range(startIndex, endIndex).forEach()같은 반복문 가능
Parallel Stream
- Sequential vs Parallel
- 여러개의 스레드를 이용해 stream의 처리 과정을 병렬화
- 중간 과정은 병렬 처리 되지만 순서가 있는 Stream의 경우 종결 처리 했을 때의 결과물이 기존의 순차적 처리와 일치하도록 종결 처리과정이 조절됨
- List로 collect한다면 순서가 동일
- 종결 처리 과정에 조정하는 것이지 중간 처리는 순차적이지 않음
- 장점
- 굉장히 간단하게 병렬 처리를 사용할 수 있게 해줌
- 속도가 비약적으로 빨라질 수 있음
- 단점
- 항상 속도가 빨라지는 것은 아님
- 공통으로 사용하는 리소스가 있을 경우 잘못된 결과가 나오거나 아예 오류가 날수 있음
- deadlock
- 이를 막기 위해 mutex, semaphore 등 병렬 처리 기술을 이용하면 순차 처리보다 느려질 수 있음
- 정의
- BaseStream.
S parallel(); List.of().parallelStream();public static <T> Spliterator<T> spliterator(Collection<? extends T> c, int characteristics) { return new IteratorSpliterator<>(Objects.requireNonNull(c), characteristics); } default Stream<E> parallelStream() { return StreamSupport.stream(spliterator(), true); }
List.of().stream().parallel();
- BaseStream.

서버 공부합니다.