1) NLP
word embedding
Word2Vec (https://arxiv.org/abs/1301.3781)
📍 배경
- 벡터 공간에 단어를 표상하고 싶은데, 효울적으로 표상하려면 어떻게 해야할까?
- 단어를 숫자로 표현해야한다!
Word Representation
1. Local Representation
- 하나의 원소가 하나의 단어를 표상한다 원핫인코딩
- 문제) 행렬의 크기가 너무 커진다
2. Distributed Representation
- 여러개의 원소가 하나의 단어를 표상한다.
- 구조 주의(의미는 다른 다른 단어와의 관계로 결정된다)
- 인공신경방으로 구현하기 적합하다! → 오차역전파를 통해 학습가능하다!
NLPM
- Neural Probablistic Language Model (Y. Bengio, 2023)
- FFNN을 통해서 Distributed Representation 구현- (n-1)개의 단어 문맥으로 n번째 단어를 예측하는 n-gram 모델
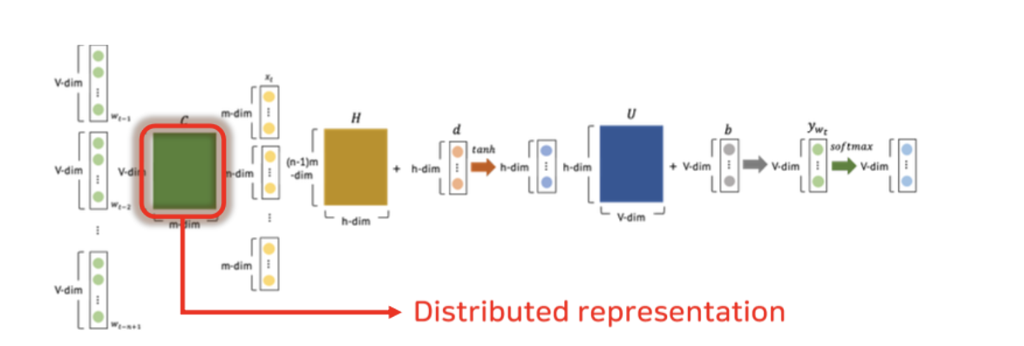
- 문제점: 사전에 정한 개수의 단어 맥락만 고려할 수 있다.
RNNLM
- RNN-based Language Model
- simple RNN 을 통해서 distributed Representation 구현
- 모든 단어 맥락을 모두 고려할 수 있다.
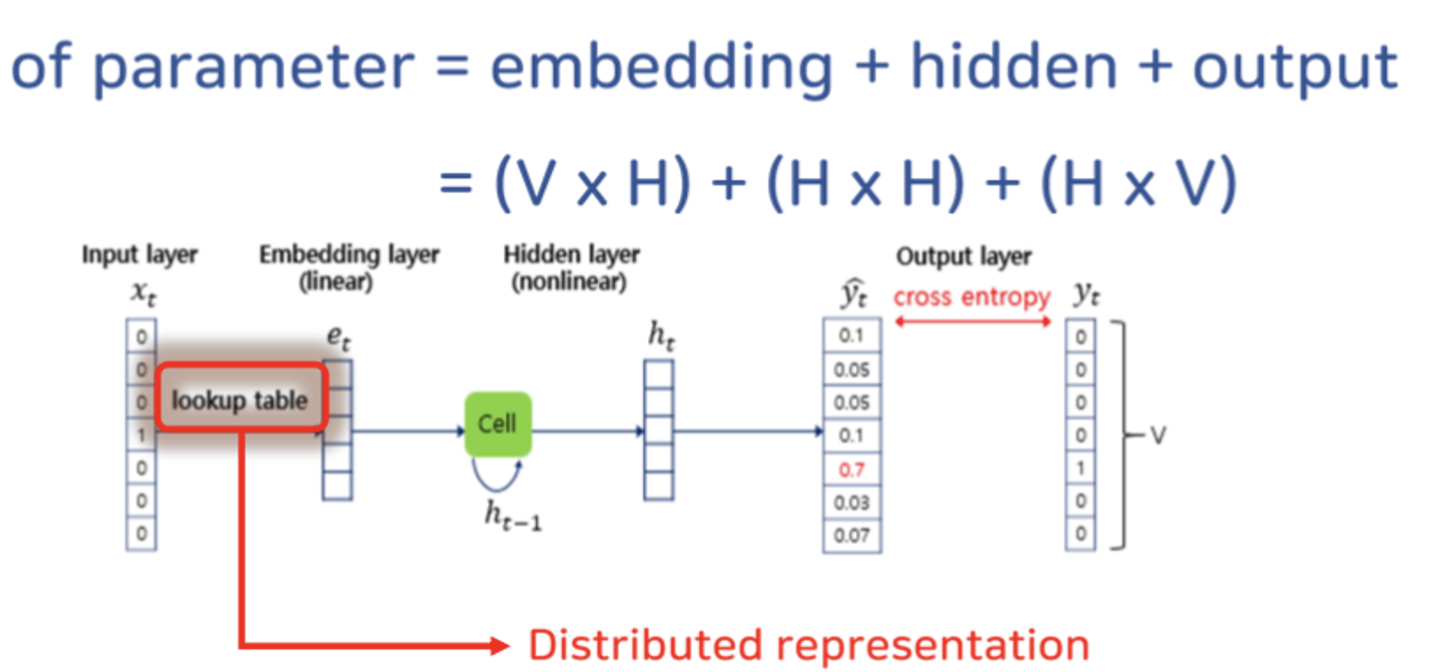
여전한 문제점! 파리미터 수가 많다!
📍 방법론
Word2Vec
-
NNLM(NPLM, RNNLM)에 기반한 임베딩 기법들 -> Parameter수가 너무 많다!
-
Word2Vec: 좀 더 효율적으로 임베딩을 해보자!
- CBOW
- Skip-gram
CBOW
- continuous bag of words
- 문맥을 기반으로 현재 단어를 예측한다.
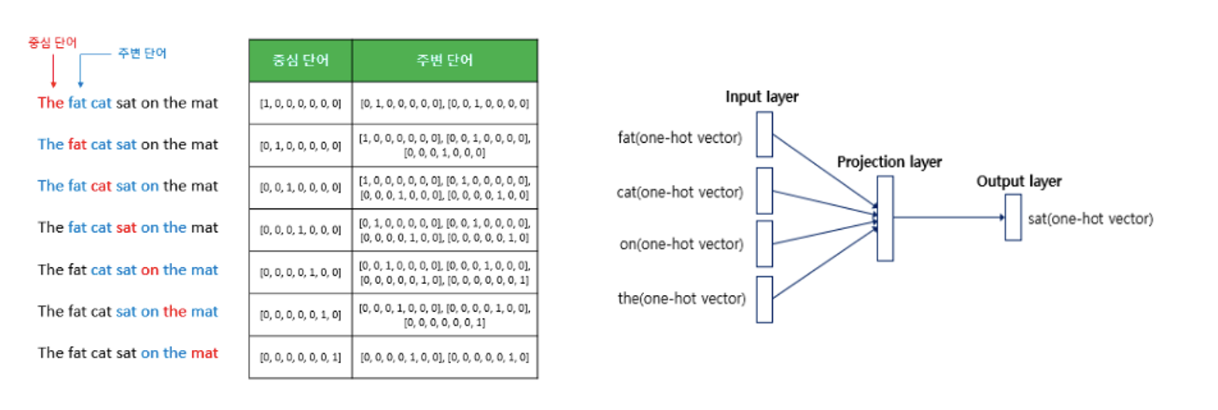
- shallow neural network
- 히든 레이어가 두개 이상이면 딥러닝
- 근데 하나밖에서 없어서 shallow라고 한다.
- projection layer 존재
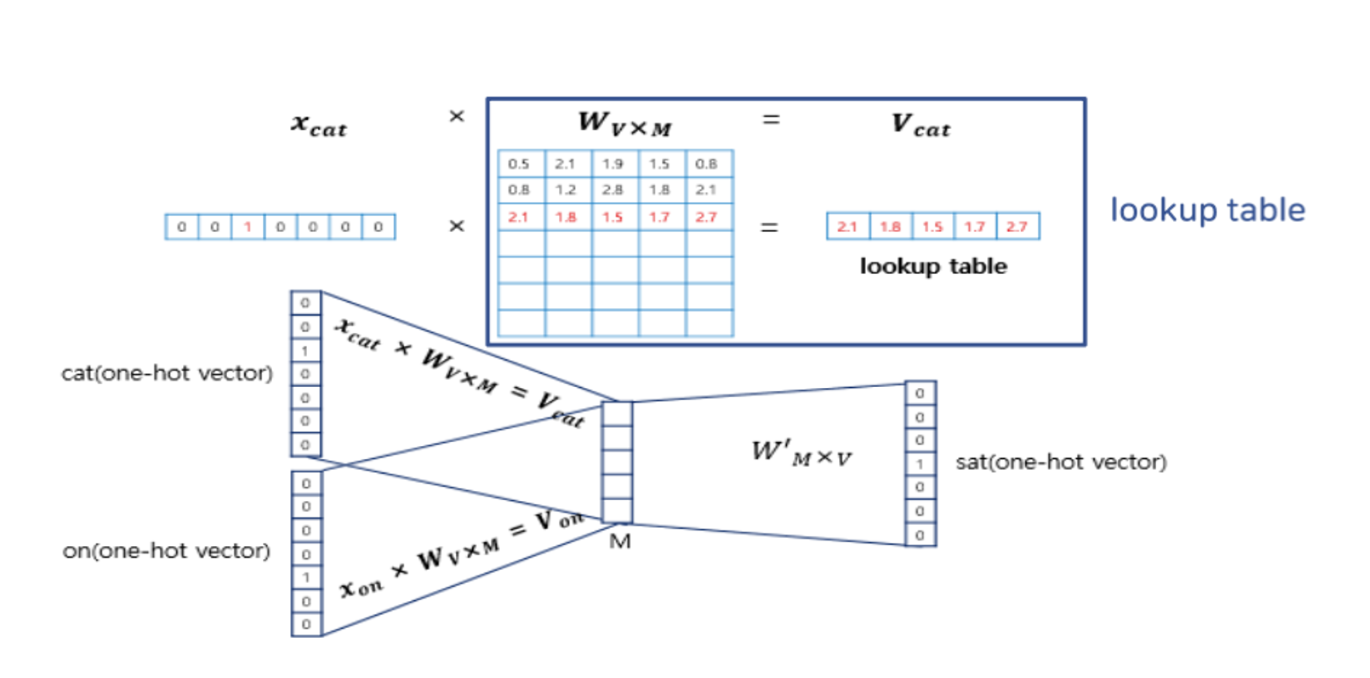
Skip-gram
- 현재 단어를 중심으로 주변 단어를 예측
- SBOW의 뒤집어진 버전
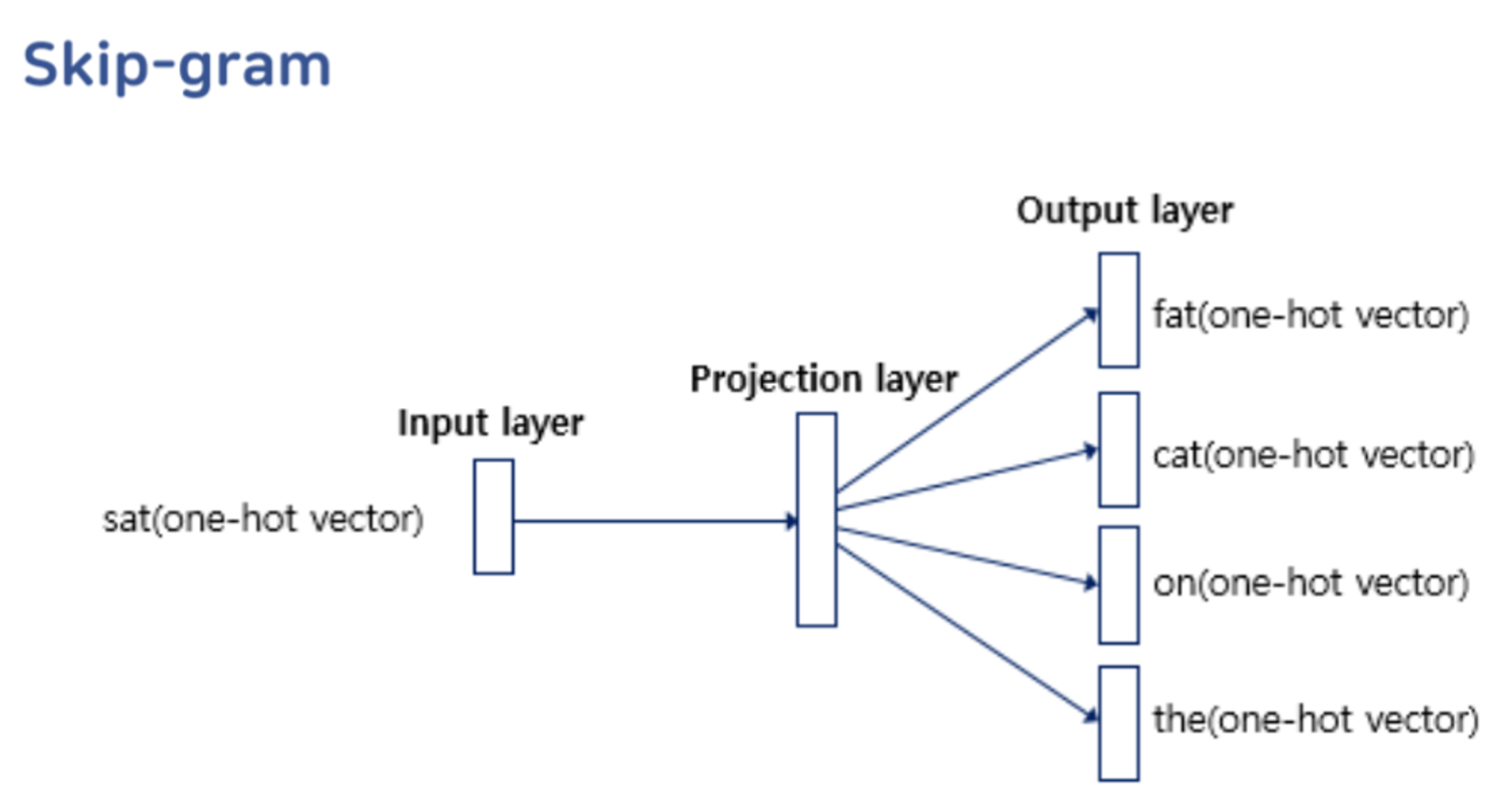
Q. SBOW VS Skip-gram 에서 스킵그램이 성능이 더 좋음
→ 스킵그램은 인풋이 하나여서 학습이 어렵지만,
학습이 되어서 나왔을때 output으로 여러개가 나와서 더 성능이 좋음
NNLM vs Word2Vec
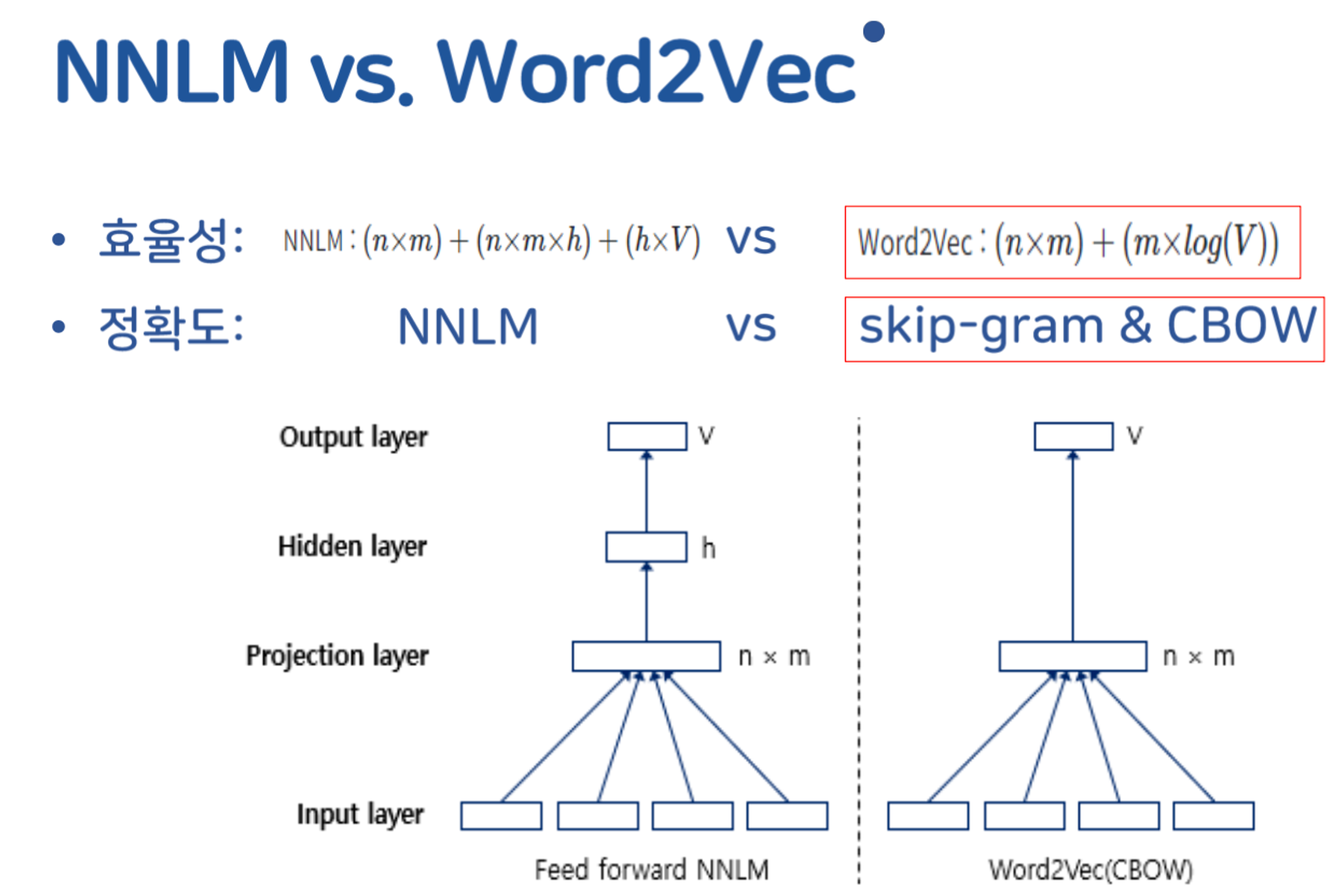
→ 과적합 가능성 더 낮음
📍 결론
- 기존 임베딩 기법(NNLM)들은 파라미터 수가 너무 많았다.
- Word2Vec은 CBOW, Skip-gram이라는 단순한 임베딩 기법을 제시함
- 두 기법 모두 NNLM보다 파라미터 수는 적지만, 성능은 더 좋다!- 특히, CBOW는 의미적 임베딩에서, Skip-gram은 형식적 임베딩에서 더 강점을 보여주었다.
- 의미적 관계) 대체될만하다 - syntactic
- 형식적 관계) 겹치는 범주가 있는 것 - semantic
CBOW, Skip-gram 용도
-
여러가지 output → skip-gram → 형식적 임베딩에 장점
-
한가지 output → CBOW → 의미적 임베딩에 장점

@fragrance_0의 개발로그