WIL keyword
- Alarm Clock: busy-wait, interrupt
- Priority Scheduling(1): thread waiting, list priority, semaphore waiting list
- Priority Scheduling(2): priority donation
⏰ Alarm Clock
스레드의 상태와 작동 (상태)
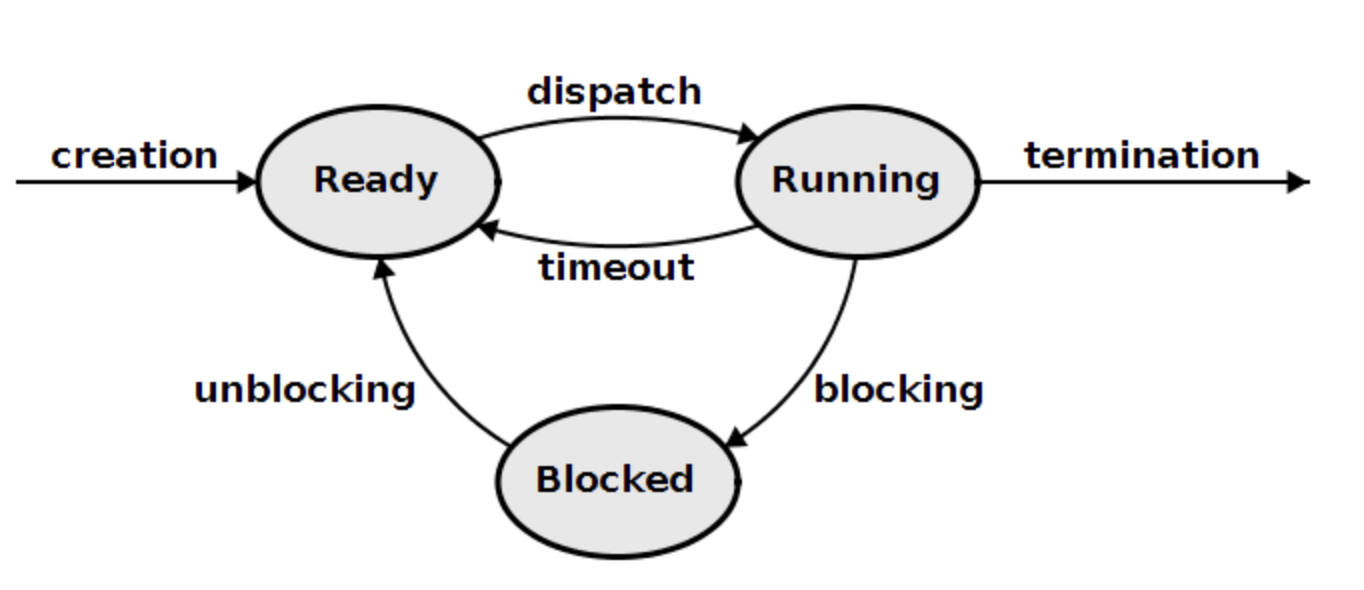
스레드는 프로세스처럼 생성부터 소멸까지 여러 상태를 거치는 Life cycle을 가지고 있다. 운영체제마다 조금씩 다르게 구현되어 있지만 일반적으로 준비(ready state), 실행(running state), 대기(bloked state), 종료(terminated state)의 4가지 상태를 가지며 이 정보는 TCB(Thread Control Block) 구조체에 저장된다.
준비 상태 (ready state)
- 스레드가 생성된 후 스케줄 되기를 기다리는 상태
- 실행 상태의 스레드의 할당된 시간이 경과되거나 스레드 스스로 CPU 사용을 양보하는 경우
- 대기 상태의 스레드가 입출력이 완료되거나 타임아웃을 통해 자원을 획득하는 경우
실행 상태 (running state)
- 준비 상태의 스레드가 스케줄링 되어 현재 CPU에 의해 실행된 경우
대기 상태 (blocked state)
- 스레드가 입출력을 요청하거나
sleep()과 같은 시스템 호출로 인해 커널에 의해 중단된 경우
종료 상태 (terminated state)
- 스레드가 스스로 종료하거나 또는 프로세스가 종료된 상태
🎯 과제 목표
https://velog.io/@fredkeemhaus/PintOS-Project-1-Alarm-Clock-%EC%9E%91%EC%84%B1%EC%A4%91
⚖️ Priority Scheduling
기본적으로 제공되는 pintos의 스케줄러는 Round-Robin(RR)으로 구현되어 있다. 우선순위를 고려하지 않기 때문에 스레드가 unblock 되거나 생성될 때 무조건 ready_list의 맨 뒤에 삽입하고 선점이 발생하지도 않는다. 이번 과제는 RR로 구현된 것을 우선순위를 고려하는 Preemptive Priority Scheduling으로 수정함으로써 새로운 스레드의 우선순위가 현재 실행 중인 스레드의 우선순위보다 높다면, 새로운 스레드가 실행 중인 스레드를 선점하도록 한다.
RR (Round Robin)
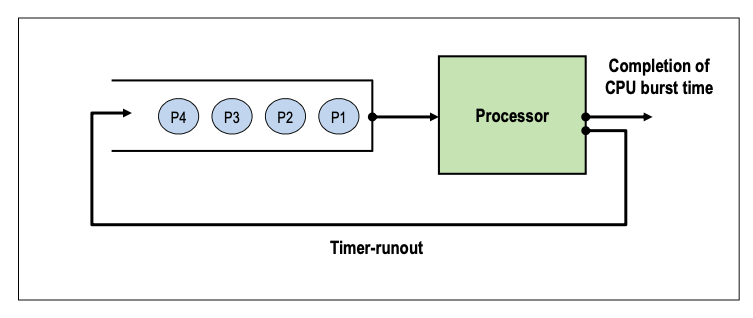
- 선점 (Preemptive scheduling)
- 스케줄링 기준 (Criteria)
도착 시간 (ready queue 기준)
먼저 도착한 프로세스를 먼저 처리
-
자원 사용 제한 시간(time quantum)이 있음
System parameter(δ)
프로세스는 할당된 시간이 지나면 자원 반납 (Timer runout)
특정 프로세스의 자원 독점 방지
Context switch overhead가 큼 -
대화형, 시분할 시스템(Time Sharing)에 적합
-
Time quantum(δ)이 시스템 성능을 결정하는 핵심 요소
Very large(infinite)δ -> FCFS
Very Small time quantum -> processor sharing
장점: 사용자는 모든 프로세스가 각각의 프로세서 위에서 실행되는 것처럼 느낌. (체감 프로세서 속도 = 실제 프로세서 성능의 1/n
단점: High context switch overhead
🎯 과제 목표
작성 예정
👬 Priority Scheduling and Synchronization
해당 과제에서는 동기화(Synchronization)에 대해서 알아보았다.
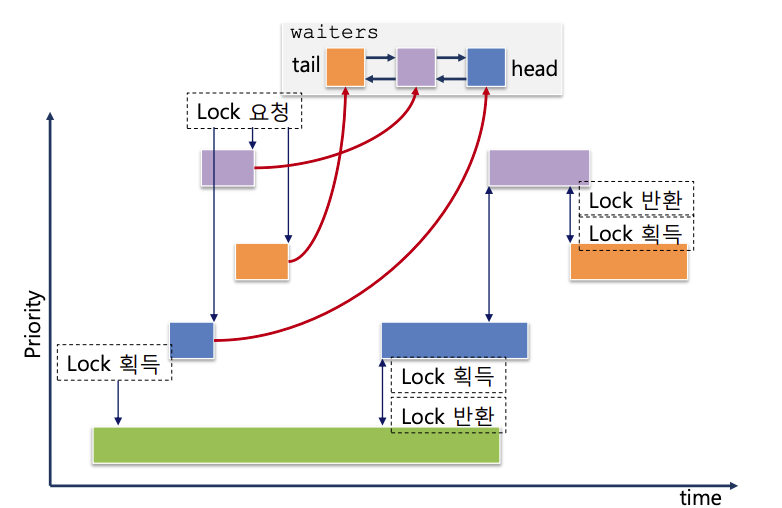
여러 스레드가 lock, semaphore, condition variable 을 얻기 위해 기다릴
경우 우선순위가 가장 높은 thread가 CPU를 점유 하도록 구현해야 한다. 현재 핀토스는 semaphore를 대기 하고 있는 스레드들의 list인 waiters가 FIFO로 구현되어있다.
다수의 작업을 동시에 실행시키는 멀티태스킹의 등장으로 병렬적으로 일을 처리함에 따라 응용프로그램의 실행 시간, 사용자에 대한 응답시간을 단축할 수 있게 되었다. 그러나 다수의 작업들이 공유 데이터에 동시에 접근하게 될 시에는 데이터가 훼손되는 문제가 발생할 수 있다. 즉, 여러 스레드가 공유 변수에 접근하려고 경쟁(race) 하는 상황에서 적절한 처리가 되지 않는다면 아래와 같이 의도치 않은, 잘못된 데이터가 저장될 가능성이 존재한다.
여러 thread가 lock, semaphore, condition variable을 얻기 위해 기다릴 경우 우선순위가 가장 높은 thread가 CPU를 점유하도록 해야 한다.
상호배제(Mutual Exclusion)
상호배제는 임계 구역에 먼저 진입한 스레드가 독점적으로 해당 구역의 실행을 끝낼 때까지 다른 스레드가 진입하지 못하도록 관리하여 공유 데이터의 훼손을 방지하는 알고리즘이다.
여기서 임계 구역(critical section 또는 critical region)은 공유 데이터에 접근하는 코드로, 하나의 스레드의 배타적인 사용이 보장되어야 한다. 진입 코드(entry code)와 출구 코드(exit code)를 두어 임계 구역에 대한 상호배제를 만든다.
진입 코드: 다른 스레드가 임계 구역에 있는지 체크하여 없으면 다른 스레드가 들어오지 못하도록 하고, 있으면 안에 있는 스레드가 임계 구역을 벗어나기를 기다림출구 코드: 임계 구역의 실행을 마치면 대기 중인 스레드나 다른 스레드가 임계 구역에 들어올 수 있도록 들어오지 못하게 조치를 취한 것을 해제함
멀티 스레드 동기화 기법
뮤텍스(Mutex), 스핀락(Spinlock), 세마포어(Semaphore) 등 다양한 방법으로 멀티 스레드를 동기화 할 수 있다. 과제와 크게 관련성은 없지만 세마포어가 언급되므로 어떤 기법들인지만 살펴보자.
1. 뮤텍스(Mutex)
lock을 이용하여 오직 한 스레드만이 자원을 독점적으로 사용하도록 하는 동기화 기법으로, 대기 큐가 존재하며 임계 구역의 실행 시간이 짧은 경우에는 lock이 잠겨있는 시간보다 스레드가 sleep 상태에서 깨어나는데 더 긴 시간이 낭비되어 비효율적이다. 따라서 임계 구역의 실행 시간이 긴 경우와 단일 CPU 시스템, 사용자 프로그램에 적합하다.
2. 스핀락(Spinlock)
뮤텍스와 마찬가지로 lock을 기반으로 하는 동기화 기법이지만 대기 큐가 없고 lock이 풀릴 때까지 무한 루프를 돌면서 lock을 검사하는 코드를 실행(busy-waiting) 하기 때문에 단일 CPU를 가진 운영체제에서는 의미 없이 기다리며 CPU를 낭비하면서도 다른 스레드의 실행 기회도 빼앗아 비효율적이다. 따라서 임계 구역의 코드가 짧은 경우와 멀티 코어를 가진 시스템, 커널 코드나 인터럽트 서비스 루틴에 효과적이다.
3. 세마포어(Semaphore)
동시에 사용할 수 있는 하나의 자원에 대해 스레드들이 공유하도록 관리하는 동기화 프로그래밍 기법이자 공유 자원의 개수를 나타내는 변수로, 하나의 자원은 여러 인스턴스를 포함한다. 자원에 대한 다중 스레드의 원활한 공유를 목적으로 하며, P(Proberen: try in Dutch)/V(Verhogen: increment in Dutch) 연산을 통해 대기 큐나 무한 루프 방식으로 자원을 얻을 때까지 대기(busy-waiting) 하다가 자원 사용을 마치면 대기 스레드에 알려 스레드 동기화를 이룬다.
🎯 과제 목표
작성 예정
Priority Inversion Problem
작성 예정
