Entropy가 뭐야
Cross Entropy를 이야기하려면 아무래도 Entropy에 대해서 이야기를 먼저 해야할 것 같습니다. 물론 Cross에 대해서도 나중에 이야기합니다.
Entropy에 대해 이야기하려면 Information Theory라는 분야를 이야기해야합니다. 불행히도 Information Theory는 수많은 수학적 정의와 수식들로 이루어져있습니다. 오늘 이 글은 Cross Entropy에 대한 개념을 소개하는 것이 목적이기 때문에 가능한 수식은 피하려고 합니다. 최대한 개념 위주로 이야기를 진행해보겠지만 필수적인 부분에서는 수식이 등장하기도 합니다.
Information
Entropy를 이야기하려면 먼저 Information Theory에서 말하는 Information 이라는 개념을 이야기해야합니다.Information Theory에서 말하는 Information은 어떤 사건을 표현하기 위해 필요한 Bit 수입니다. 예를 들어보겠습니다.
Information을 통해 알 수 있는 것은 필요한 Bit 수 외에도 Surprise라는 개념이 있습니다. 특정 사건이 실제로 일어났을 때 얼마나 놀라울까를 표현한 것입니다.
예를 들어 상대방이 이 가상의 언어로 이야기를 하고 있다고 생각해보겠습니다. 상대방이 "A"라고 말하면 별로 놀라지 않을 겁니다. 많이 듣던 말이니까요. 그런데 갑자기 이 사람이 "D"라고 합니다. 오호?하고 잠이 깨면서 상대방의 말에 집중하게 될 것입니다. 자주 듣지 않던 말이니까요. 즉, A는 Suprise하지 않지만 D는 Surprise합니다.
왜 우리는 D라는 단어를 들으면 더 관심이 가고 Surprise할까요? 바로 자주 일어나지 않는 일이고 무엇인가 새로운 정보(Information)을 담고 있을 가능성이 높기 때문입니다. 바로 아래와 같이 말할 수 있습니다.
높은 확률 -> 뻔하다 -> Information이 적다/낮다
낮은 확률 -> 신선하다 -> Information이 많다/높다
Entropy
Entropy의 정의는 어떤 확률 분포를 표현하는데 필요한 Bit 수입니다. Information이 특정 사건을 표현하기 위한 Bit 수였다면, Entropy는 확률 분포 전체를 표현하기 위한 Bit 수입니다.
다른 설명 방법도 있습니다. Entropy는 어떤 일이 일어날 가능성이 확실한지, 불확실한지를 수치로 표현한 것입니다. 오늘 하루 동안 저는 밥을 먹을까요 안 먹을까요? 아마도 높은 확률로 밥을 먹을 겁니다. 제가 오늘 밥을 먹을 것은 확실하죠. 그래서 제가 오늘 밥을 먹는 사건은 낮은 Entropy를 가집니다.
확률 vs Entropy
이렇게 되면 확률과 Entropy가 헷갈릴 수 있습니다. 확률은 특정 사건이 일어날지 안 일어날지를 수치로 표현한 것입니다. Entropy 그 사건의 불확실성을 수치로 표현한 것입니다. 말이 복잡하네요. 예를 들어 살펴보겠습니다.
추첨을 통해 경품을 주는 행사가 있습니다. 1등은 최신형 핸드폰, 2등은 스마트 워치, 3등은 커피 쿠폰입니다.
상자 A에는 1등 종이가 1개, 2등 종이가 2개, 3등 종이가 7개 들어있습니다. 상자 B에는 1등 종이 3개, 2등 종이 3개, 3등 종이 4개가 들어있습니다. 두 상자 모두 총 10개의 종이가 들어있습니다.
-
상자 A의 경우,
1등 당첨 확률은 1/10
2등 당첨 확률은 2/10
3등 당첨 확률은 7/10
입니다. -
상자 B의 경우,
1등 당첨 확률은 3/10
2등 당첨 확률은 3/10
3등 당첨 확률은 4/10
입니다.
상자 A에서 1등이 될 확률(1/10)보다 상자 B에서 1등이 될 확률(3/10)이 훨씬 높습니다.
Entropy는 어떨까요? 어떤 상자가 더 불확실한가요? 다르게 말하면 첫 추첨을 했을 때 1등이 나올지, 2등이 나올지, 3등이 나올지 어떤 상자가 더 예측하기 어렵나요? B일 것입니다. 상자 A는 3등이 나올 확률이 7/10으로 1등(1/10)이나 2등(2/10)보다 압도적으로 높습니다. 상자 A에서 뽑는다면 대부분 사람들은 첫 뽑기 결과가 3등일 것이라고 예상할 겁니다. 불확실성이 낮습니다. 낮은 Entropy죠.
반면 B는 어떨까요? 1등, 2등, 3등이 모두 비슷한 확률을 가지고 있습니다. 첫 뽑기 결과를 예측하기가 어렵죠. 스릴이 넘칩니다. 불확싱설이 높습니다. 높은 Entropy죠.
정리해보면 확률은 특정 사건에 대한 수치(1등을 뽑을 확률)입니다. Entropy는 전체 사건에 대한 수치(얼마나 예측이 어렵느냐)입니다.

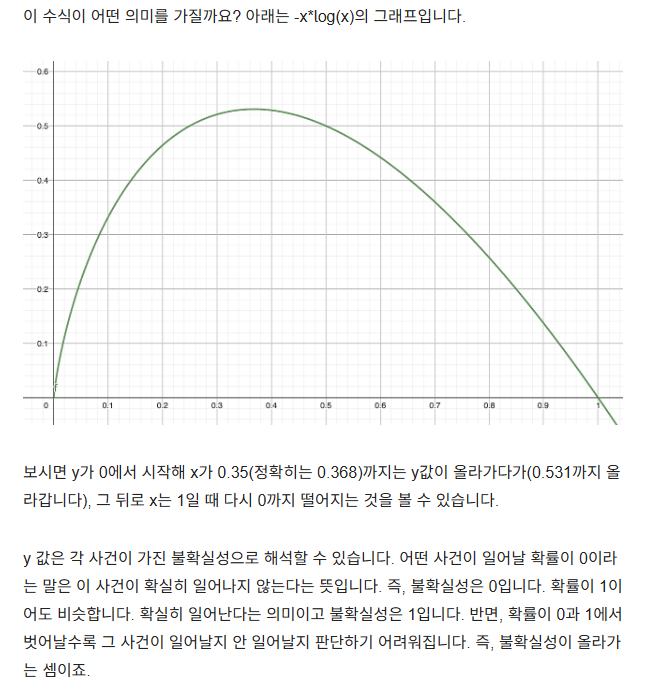
앞의 A 상자에서 1등이 될 확률 p(1등)은 0.1입니다. -p(1등)log(p(1등)) = - 0.1 * p(log0.1) = 0.332입니다.
Entropy 계산
Entropy는 모든 사건에 해당하는 -p(x)log(p(x))를 더한 값입니다. 개념적으로보면 각 사건이 일어날 불확실성을 다 더한 값이 Entropy입니다.

Cross Entropy
Entropy가 무엇인지는 알았습니다. 그럼 이제 Cross 에 대해서 이야기해보겠습니다.
Cross Entropy 역시 Information Theory에서 나온 개념입니다. 실제 데이터는 확률 분포 P(x)에서 나오는데 우리는 이 데이터를 표현하기 위해서 Q(x)라는 다른 확률 분포를 사용한다고 가정해보겠습니다. Q(x)를 통해서 예측한 확률 값은 진짜 확률 값 P(x)와 다르겠죠. Cross Entropy는 실제 P(x)인 데이터를 Q(x)를 사용해서 표현한다면 얼마나 많은 Bit가 필요하느냐를 나타냅니다.
역시 말이 어렵습니다. 조금 더 살펴보죠.

Entropy와 Cross Entropy
Cross Entropy는 항상 Entropy보다 큽니다. 수학적으로 증명 가능하지만 이 글에서 그 부분은 다루지 않겠습니다. 대신 https://stats.stackexchange.com/questions/370428/why-is-the-cross-entropy-always-more-than-the-entropy 을 참고하시기 바랍니다.
이 글에서는 조금 더 직관적인 해석을 해보려고 합니다.
Cross Entropy (P, Q)는 실제 데이터는 P(x) 분포인데 이를 Q(x) 분포로 표현할 때 얼마나 많은 Bit가 필요한지를 나타내는 값이라고 했습니다. Entropy(P)는 P 분포를 가장 효율적으로 표현할 수 있는 Bit 수입니다. P가 아닌 어떤 분포를 사용하더라도 P보다 더 적은 Bit를 사용할 수는 없습니다. 정의상 이미 P가 가장 효율적인 분포이니까요. 즉, Cross Entropy (P, Q)는 Entropy (P)보다 클 수 밖에 없습니다.
Cross Entorpy (P, Q)가 가장 작아질 때는 언제일까요? 바로 Q가 P와 같을 때 입니다. 그 외에는 항상 Cross Entropy (P, Q) > Entorpy (P) 입니다. 또다른 유용한 특징은 P와 Q가 비슷할 수록 값은 Entropy(P)에 가까워지고, P와 Q가 다를수록 값이 Entropy(P)와 멀어진다는 점입니다.
Loss Function 으로써 Cross Entropy
이런 Cross Entropy의 특성은 Loss Function으로 쓰기에 아주 좋습니다. P는 정답 데이터라고 하고 Q를 우리 모델이 현재 예측하는 데이터라고 해보겠습니다. 모델이 점점 더 정확한 예측을 할 수록 Cross Entropy(P, Q)는 작아질 것입니다. 즉, 우리는 Cross Entropy(정답 데이터, 모델의 예측 값)이 줄어들도록 모델을 훈련시키면 됩니다.

..예시(중략)..
정리

단순히 두 데이터(확률 분포) 사이의 차리를 측정하는 값으로 사용하던 Cross Entropy에는 여러가지 이론적인 배경이 있습니다. Cross Entropy에는 Information Theory의 많은 이론이 담겨있지만 솔직히 Machine Learning 관점에서 크게 중요하지는 않을 수 있습니다.우리는 Cross Entropy를 두 데이터 사이의 차이(거리)를 측정하는 도구로 활용하니까요.
하지만 언제나 도구 뒤에 숨은 원리를 아는 것은 좋은 일이라고 생각합니다. 그래야 더 좋은 기술을 개발할 수도 있고, 문제가 생겼을 때 효과적으로 대처를 할 수도 있으니까요.
앞으로 더 읽어볼 글: An introduction to entropy, cross entropy and KL divergence in machine learning
