
1강
이번 강의에서는 데이터 분석과 데이터 시각화가 무엇인지 알아보고 이를 통해 얻을 수 있는 결과물에 대해 이해해봅니다. 또한, 더 나아가 데이터 사이언스에 대한 시야를 확장해봅니다.
데이터 사이언스 지식을 바탕으로 어떤 프로덕트를 만들고 싶으신가요?
해당 프로덕트를 위해 어떤 조직에서 어떤 역할을 담당하고 싶은가요?
데이터 업계에서 궁극적인 목표는 무엇인가요?
2.1 데이터 문해력
데이터를 건전한 목적과 윤리적인 방법으로 사용한다는 전제 하에
2.2 좋은 질문과 EDA
시작은 언제나 좋은 질문이 중요하다 (Why? How? What?)
다만, 일반적으로 대회나 업무에서는 미리 주어지는 경우도 다수
이미 문제가 정해져 있다면, 디테일한 질문으로 계속 파고 들기 위한 탐색을 해야한다.
1. Input Data, 전처리 방법론, 모델 후보군 고려
- 데이터 유형
- 모델과 학습 방법론
- 외부 유사 데이터
- Target Data와 Metric에 대한 (대략적인) 정보 파악
- 기본 모델 / 단일값 결과물에 대해 베이스라인 점수 파악
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)는 벨연구소의 수학자 '존 튜키'가 개발한 데이터분석 과정에 대한 개념
2.3 데이터 선별
데이터 선별에 대한 질문 예시
2.4 모델과 분석 방법 결정
과정 내에 모델에 대한 선택은 "결과" 중심이 될 수 있겠지만
이후 배포를 고려한다면 다음과 같은 항목에 대해 후보군이 제시되어야 함
- 학습 시간
- 예측 시간
- 비용
- 안정도와 보완
또한
2강
2.2 Stacked Bar Plot
- 2개 이상의 그룹을 쌓아서(stack) 표현하는 bar plot
- 각 bar에서 나타나는 그룹의 순서는 항상 유지
- 맨 밑의 bar의 분포는 파악하기 쉽지만
- 그 외의 분포들은 파악하기 어려움 (파란색, 핑크색 간의 비교에는 적합하지 않음)
- 2개의 그룹이 positive/negative라면 축 조정 가능
- .bar()에서는 bottom 파라미터를 사용
- .barh()에서는 left 파라미터를 사용
2.3 Overlapped Bar Plot
- 2개 그룹만 비교한다면 겹쳐서 만드는 것도 하나의 선택지
- 3개 이상에서는 파악이 어렵기 때문
- 같은 축을 사용하니 비교하기 쉬움
- 투명도를 조정하여 겹치는 부분 파악(alpha)
- Bar plot보다는 Area plot에서 더 효과적
- 후에 seaborn에서 다룰 예정
2.4 Grouped Bar Plot
- 그룹별 범주에 따른 bar를 이웃되게 배치하는 방법
- Matplotlib으로는 비교적 구현이 까다로움(후에 seaborn에서 다룰 예정)
- 적당한 테크닉(.set_xticks(), set_xticklabels())
- 앞서 소개한 내용 모두 그룹이 5개~7개 이하일 때 효과적
- 그룹이 많다면 적은 그룹은 ETC로 처리
3. 정확한 Bar Plot
3.1 Priniciple of Proportion Ink
-
실제 값과 그에 표현되는 그래픽으로 표현되는 잉크 양은 비례해야 함
-
반드시 x축의 시작은 zero(0)!!
- 만약 차이를 나타내고 싶다면 plot의 세로 비율을 늘리기
-
막대 그래프에만 한정되는 원칙은 아니다!
- Area plot, Donut Chart 등등 다수의 시각화에서 적용됨
3.2 데이터 정렬하기
- 더 정확한 정보를 전달하기 위해서는 정렬이 필수
- Pandas에서는 sort_values(), sort_index()를 사용하여 정렬
- 데이터의 종류에 따라 다음 기준으로
- 시계열 | 시간순
- 수치형 | 크기순
- 순서형 | 범주의 순서대로
- 명목형 | 범주의 값 따라 정렬
- 여러 가지 기준으로 정렬을 하여 패턴을 발견
- 대시보드에서는 Interactive로 제공하는 것이 유용
3.4 복잡함과 단순함
- 필요 없는 복잡함은 NO!!
- 무의미한 3D X
- 직사각형이 아닌 다른 형태의 bar는 지양
- 무엇을 보고 싶은가? (시각화를 보는 대상이 누구인가)
3.5 ETC
- 오차 막대를 추가하여 Uncertainty 정보를 추가 가능 (errorbar)
- Bar 사이 Gap이 0 이라면->Histogram
2-3. 선 그래프
1.1 Line plot
- 연속적으로 변화하는 값을 순서대로 점으로 나타내고, 이를 선으로 연결한 그래프
- 꺾은선 그래프, 선 그래프, line chart, line graph 등의 이름으로 사용됨
- 시간/순서에 대한 변화에 적합하여 추세를 살피기 위해 사용
-> 시계열 분석에 대해 특화 (그 외에는 오히려 적합하지 않은 경우 다수) - matplotlib에서는 .line이 아니라 .plot()
1.2 Line Plot의 요소
-
5개 이하의 선을 사용하는 것을 추천
- 더 많은 선은 중첩으로 인한 가독성 하락
-
그렇다면 이를 구별하는 요소는 어떤 것이 있을까?
- 색상(color)
- 마커(marker, markersize)
- 선의 종류(linestyle, linewidth)
2.4 이중 축 사용
- 한 plot에 대해 2개의 축을(dual axis)라고 함
2-4. 산점도
1.1 Scatter plot이란?
- 점을 사용하여 두 feature 간의 관계를 알기 위해 사용하는 그래프
1.3 Scatter plot의 목적
- 상관 관계 확인 (양의 상관관계 / 음의 상관관계 / 없음)
- 세 가지를 확인하는 것이 가장 기본 (군집, 값 사이의 차이, 이상치)
2. 정확한 scatter plot
2.1 Overplotting
- 점이 많아질수록 점의 분포를 파악하기 힘들다!
- 투명도 조절
- 지터링 (jittering) 점의 위치를 약간씩 변경
- 2차원 히스토그램
- Contour plot : 분포를 등고선을 사용하여 표현
3강
3-1. 범주형 데이터
1.1 범주형 데이터
명목형 데이터란 순서가 상관없이 항목으로 구분되는 데이터
성별, 국가, 과일 종류 등
순서형 데이터란 각 값이 우위 등의 순서가 존재하는 데이터
리커드 척도, 영화 별점표 등
순서형인지 수치형인지가 고민된다면 산술연산의 의미를 두면 된다. (별점 4점은 별점 2점보다 2배 좋은건가? 아님 -> 순서형) 경우에 따라 순서형도 수치형처럼 치환하여 계산해볼 수 있다.(평군 별점)
- 집단 간의 분석이 용이함
- 분류 기준을 통해 범주 별 통계 지표 확인
국가별 평균 임금, 지하철 노선별 사용자 연령층 분호, 식료품별 가격 증감 - 범주 별 관계 분석에도 용이(추천 알고리즘)
성별에 따른 구매품목 통계 비교, 영화 카테고리 추천
그룹 별 어떤 값을 뽑아볼 수 있을까?
1.2 대푯값
데이터 집단의 비교를 위해 추출하는 대표 값
- 평균/총합: 이산적인 합산을 통해, 그리고 전체 개수로 나눠서 얻는 값
- 기댓값 (가중평균) : 각 값이 나올 확률에 대해 또는 중요도에 대해 계산하여 구한 값
- 최빈값: 가장 많이 관측되는 값
- 중앙값: 정렬된 데이터의 가운데 값. 홀수개면 중간, 짝수개면 n/2th, n/2-1th의 평균으로 계산한다.
- 사분위값: 중앙값을 포함하여 1/4 위치의 값 3/4 위치의 값
- 절사평균:관측값의 양끝의 일부를 제외한 값에 대한 평균
1.3 대푯값 예시
2.1 명목형 데이터
일반적으로 값이 텍스트로 구분됨
국가 혈액형 MBTI 과일 성별
어떤 식으로 Pandas에서는 진행할 수 있을까?
df.groupby(['col1','col2']).sum()그룹으로 묶는 과정은 텍스트 괜찮지만
모델 연산 을 위해서 값으로 변화해야
2.2 명목형 데이터 전처리 - Label Encoding✨
주의점1) 없는 레이블에 대해서 미리 전처리 필요(기본 값 -1)
sklearn.preprocessing.OrdinalEncoder(encoded_missing_value=-1)
주의점2) 다음의 2개 이상에서 [0, 1, 2] 등으로 레이블링을 한다면 자체적인 순서 존재
2개는 [0, 1], [-1, 1]로 치환하는 것이 상관이 없음. 수식 입장에서는 치환하는 것 쉬움. 모델 자체 계수와 상수 등으로 같은 기능으로 사용됨
0, 1, 2, 3, 4, 5 실제 수식에 들어갈 때는 순서가 존재함 -> 실제로 모델에 bias가 생기면서 모델에 안 좋은 결과.
선형적인 연산에서 bias가 생길 수 있음
순서형 데이터에서는 오히려 적합할 수 있으나, 일반적으로 선형적인 연산이 들어가는 대부분 모델에서는 모델에 좋지 않은 영향
One-Hot Encoding
- 순서 정보를 모델에 주입하지 않기 위한 방법 : 컬럼 개수 늘리기
- 0과 1로서 구분하는 건 상관없
- 각각 데이터를 0과 1로 표현
- 한국 일본 중국 미국
=> [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]
남자 [0,1]
여자 [1, 0]
무응답 [0,0]
각각을 리스트로 표현했지만 실제 판다스모델(테이블 모델)에 들어갈 때는 그냥 몇 개의 나열된 값으로 표현된다. 1개가 표현된다. -> one-hot encoding
다른 장점: 여러 개의 범주가 동시에 포함되는 경우, 효과적으로 인코딩
- 다만 범주가 늘어나는 경우 그만큼 컬럼 개수가 늘어나기 때문에
학습 알고리즘에 따라 훨씬 속도가 느려지거나 퀄리티가 안 좋을 수 있음
범주가 많아진다는 거는, 이 각각의 범주에 따라서 데이터가 분산된다는 거고, 어떤 특정한 범주에 대해서 정보가 많아진다면 거기에 bias가 생기는 경우가 많다.
그렇기 때문에 원핫인코딩은 범주가 많아지는 걸 방지하기 위해서, 범주를 그냥 줄여버리는 경우도 있음. 한국 중국 그외..
아시아 유럽 아메리카..
데이터 증강(data augmentation)으로서 이런 빈도들을 각각 높여주는 방법도 있겠지만, 데이터 증강을 하는 동시에 어떤 데이터에 대한 정보들이 bias 되는 경우가 많기 때문에 오히려 데이터 증강하는 방법보다는 빈도 기반으로 범주를 줄이는 것을 더 추천드립니다.
범주가 너무 많음 -> 모델 학습 어려움(메모리 문제)
-> 범주를 줄이는 인코딩 작업
1) Binary encoding
- Label encoding (레이블링을 우선한다. 0, 1, 2, 3 ...)
- 이를 이진수로 변환한다(000, 001, 010, ..., 111)
- 이를 컬럼 데이터로 변환한다 [0,0,0][0,0,1]
- 범주의 개수가 k개일 때 k,2^N을 만족하는 최소 N만큼의 컬럼 생성
[Pros] 순서 정보를 없애며, 개수가 많은 범주에 대해 효과적
[Cons] 범주의 의미가 거의사라짐
2) Embedding/Hashing
- Embedding : 자연어 N개에 대해서 코사인 거리를 유지하는 방법 자연어들을 리스트로 변환. 적절한 임베딩 모델을 사용하여 치환
- Hashing : 랜덤 해시 값으로 순서 정보를 없앨 수도 있음
랜덤한 숫자로 설정해줌. 비슷한 정렬 방법을 사용함. 값들 간격에 랜덤성을 준다는 특징. 오히려 바이어스가 강해질 수도 있음
캐글/머신러닝성능높일 때
- 특정 값에 따른 인코딩 : 해당 범주가 가진 통계값의 사용
예시로 빈도수로 한다면 여자가 30명, 남자가 70명이라면 => [여자, 남자] => [30, 70]
더알아보기
해시함수 : 임의의 길이를 갖는 임의의 데이터를 고정된 길이의 데이터로 매핑하는 단방향 함수. 임의 길이의 입력값을 받아 고정된 길이의 출력값을 내는 함수.
[자료구조] 해시란? 고정된 길이의 데이터(해시 값)로 매핑하는 함수
[해시테이블] 컴퓨팅에서 키를 값에 매핑할 수 있는 구조인, 연관 배열 추가에 사용되는 자료 구조이다. 해시 테이블은 해시 함수를 사용하여 색인(index)을 버킷(bucket)이나 슬롯(slot)의 배열로 계산한다. 데이터를 다루는 기법 중에 하나로 데이터의 검색과 저장이 아주 빠르게 진행된다.파이썬: hash() 함수. 무작위의 긴 숫자가 나올 것. 딕셔너리.
표본집단의 데이터가 모집단의 데이터와 다른 결과. 결과에 나쁜 영향. 특정 값을 위해 하나의 테크닉을 만들 수 있지만 범용적인 모델을 만들 때 주의해야 한다.
🤔..?
3.1 순서형 데이터
순서형 데이터는 명목형에 순서 정보 추가
앞선 인코딩 방법이 모두 사용가능
레이블링, 원핫, 바이너리, 임베딩, 해싱 등
범주 또한 그룹별로 묶는 것도 훨씬 용이
[매우 나쁨, 나쁨, 중간, 좋음, 매우 좋음] => [-1, 0, 1]
3.2 순환형 데이터(Cyclical Data)
순서는 있지만 해당 값이 순환되는 경우 존재(범주형/수치형 모두 포함)
- 월, 요일, 각도
삼각함수 등 값의 크기에 따라 순환되는 값을 사용할 수도 있음(시계열 등에서도 사용 가능)
=> sin(2pii/n), cos(2pii/n)등
*NeRF에서는 각도 값의 표현력을 넓히기 위해 한 값을 여러 개의 Sin, Cos 값으로 치환해서 사용
-- 범주형 데이터
3-2. 수치형 데이터
1.1 이산형 데이터와 연속형 데이터
일반적으로 정수 형태를 띄고 있는 이산형 데이터(Discrete)와 실수 형태를 띄고 있는 연속형(Continuous) 데이터
이산형 데이터 예시
-인구 수, 제품 수, 횟수 등
연속형 데이터 예시
-키, 몸무게, 온도
1.2 다양한 전처리
2.1 정규화와 표준화
가장 쉬운 전처리
정규화 방법 : 0에서 1 사이 값으로 만든다.
표준화 방법 : 전체 평균을 0으로 만든다. 표준편차를 1로 만든다.
2.2 대칭성을 위한 방법들
2.3 Negative Skewness
2.4 Positve Skewness
4강
정형데이터 피쳐엔지니어링
4-1. 결측치와 이상치
1.1 결측치
1.2 결측치를 위한 EDA
2.1 이상치
- 과하게 벗어난 값
- 사분위수: 1/4 지점의 수 IQR
- 표준편차
- z-score
- DBSCAN
- Isolation Forest
2.2 IQR/표준편차
- IQR(Inter Quantile Range)
- IQR = 3분위 수와 1분위수의 차이
- 1분위수 - 1.5 * IQR 이상
- 3분위수 - 1.5 * IQR 이상
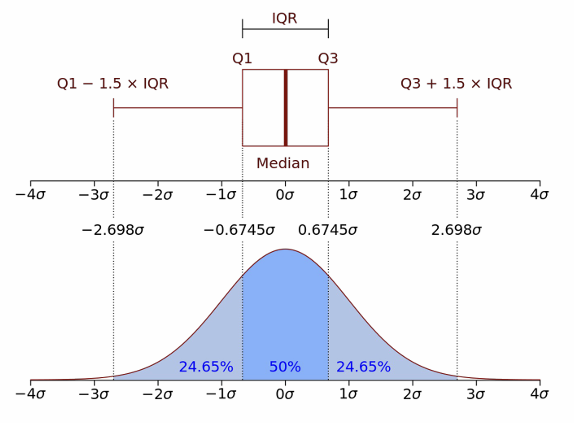
- 표준편차
- 평균 +- [2,3] * 표준편차
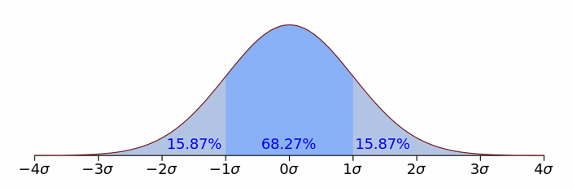
- 평균 +- [2,3] * 표준편차
IQR-Boxplot
- seaborn

2.3 DBSCAN
-
밀도 기반 clustering
-
집단을 묶는 알고리즘
-
포인트의 개수, 경계, 노이즈를 바탕으로 각각의 포인트들을 구분함
- 어떤 밀도를 벗어난 데이터 -> 자동으로 이상치
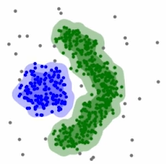
- 어떤 밀도를 벗어난 데이터 -> 자동으로 이상치
-
단 밀도가 어느정도 균일한 데이터에 대해서만 시행할 수 있음
2.4 Isolated Forest
- 기준에 따라 그룹 분리 결정트리
- 루트 노드와 거리를 통해 이상치 탐지
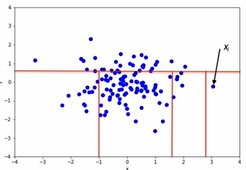
- 루트 노드와 거리를 통해 이상치 탐지
4-2. 클러스터링과 차원축소
1.1 피처 엔지니어링
- 보다나은 특성을 통해 좋은 모델을 만들고, 해석에 용이하게 만드는 과정
1.2 특성 추출 및 생성
- 다양한 결합 방법을 사용할 수 있는 경우
- 사칙 연산을 통해 값을 연산
- 도메인 지식에 따라 다양한 결합이 가능하며, 이 외에 여러 가능성을 염두하여 다양한 실험을 진행해볼 수 있음
피처의 개수를 무한대로 만드는 것이 가능
2.1 클러스터링
유사항 성격을 가진 데이터를 그룹으로 분류하는 것
- 데이터 전 과정에서 유의미
2.2 클러스터링 방법론
2.3 클러스터링 주의점
- 거리 정의방식
- 대부분은 유클리드 거리를 사용하며 스케일링 관련 전처리 중요
- 클러스터 결과 기록과 해석
- 개수가 정해진 것과 정해지지 않은 것
- 예외치에 대한 해석
- 시각화
3.1 차원축소
다차원 데이터 이해하기 위한 방법론
- 특성 선택과 특성 추출
- 선택은 기존 특성 중 일부 선택 / 추출은 새롭게 특성 생성
3.2 차원 축소 방법
-
정보를 최대한 보유, 왜곡을 최소화
- 가까운 데이터는 최대한 가깝게, 먼 데이터는 최대한 멀개
-

3.3 차원축소와 시각화
- 왜곡 염두
- 차원 축소는 정답이 아님
5강~7강
https://kevinitcoding.tistory.com/entry/Data-Frame%EC%9D%98-%ED%96%89-%EC%97%B4-%EC%84%A0%ED%83%9D%ED%95%98%EA%B8%B0-iloc%EA%B3%BC-loc%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90
iloc, loc 차이
[Pandas] 강의 들어야 함..
iloc은 integer location의 약자로, 행과 열의 값
loc은 location. 해당 위치의 열의 레이블(이름). 예를 들어 'gender'열
- to_list()는 리스트로 반환하는 메서드인듯
