parquet?
일단, parquet 가 무엇인가.
(발음은 '파-케e' 이런 느낌으로 읽는 것 같다. 끝에 'e이'를 소리내는 듯 마는 듯 하게.)
간단하게 위키에 누군가 적어놓은 걸 보면
Apache Parquet is a free and open-source column-oriented data storage format in the Apache Hadoop ecosystem. It is similar to RCFile and ORC, the other columnar-storage file formats in Hadoop, and is compatible with most of the data processing frameworks around Hadoop. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Aparche Parquet, Wikipedia, (accessed at 2022.07.09)
parquet의 상세한 특징이 많지만, 중요한 것 하나만 뽑자면,
- 컬럼-정렬기준의 데이터 스토리지 포멧
이라는 것이다.
Column-oriented (컬럼기반, 컬럼 정렬기준)?
데이터로 자주 쓰는 csv 포멧은, 우리가 익숙하게 생각하는 데이터 구조(Tabular data) 모양 그대로 저장한다.(아래 그림처럼)
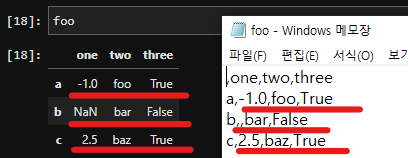
이런 csv의 경우는 row-oriented, 즉 데이터를 기술하는 기준이 행(row) 기준이 된다. ("a라는 녀석은, 'one'=-1, 'two'="foo", 'three'=True 이고, b라는 녀석은 ...")
parquet는 이와 달리, 데이터를 저장하는 기준이 열(columns)인 것이다.
(" 'one'은 [-1, Nan, 2.5 ] 가 있고, 'two'는 ....")
이렇게 열-기준의 데이터 저장방식을 사용할 경우, 대용량 데이터를 처리하는데 행-기준의 방식보다 여러 이점이 있다고 한다. 몇 가지만 뽑자면,
- 먼저, 압축률이 좋다고 한다. 보통, 하나의 행(row)에는 하나의 단위가 되는 엔티티(예: 철수, 영희, 동수...)가 기준으로 두고, 하나의 열(columns)에는 같은 속성(feature)의 데이터(예: {키: 175, 168, 180...}, {거주지: "서울", "부산", "제주"...}, ...) 를 사용하기 때문에, 컬럼-기반의 저장 방식은, 컬럼 별 데이터 타입 처리가 용이하기 때문에 파일 크기도 보통 작다고 한다.
- 컬럼별 처리, 인코딩이 용이하고, 디스크IO가 적다고 한다. 위 보충설명에서 소개한 것 처럼, 컬럼 단위 접근이 바로 가능하기 때문이다.
csv, parquet 파일 불러오기 테스트
csv보다 parquet이 쓰기 좋은 경우
이번에 parquet 포멧을 접하면서, '이런 걸 이제야 알게되다니, 역시 그동안 우물에 있었군' 싶었다.
위와 같은 특징들 때문에, parquet 포멧은 데이터 분석시에 유용하게 활용되왔다고 한다. (version 1.0이 2013년에 나왔다고... 곧 10주년이다...)
이번에 parquet 포멧에 데이터를 다룰 기회가 생겨서 알아보다가, 가장 먼저 궁금했던 부분은 역시 데이터 불러오기 성능 이었다. 사실, 보통의 데이터 분석 작업에 80% 이상을 pandas로 쓰는 나의 경우, 꽤 큰 records를 갖는 tabular data를 로컬에 단순무식하게 저장해야 하는 때도 있었고, 이걸 다시 pd.read_csv()할 때 정말 무거운 pandas를 5분 이상 기다려야 했던 경우도 다반사였다.
특히나, 특정 컬럼만 불러와도 되는 경우, pd.read_csv(..., usecols=\['컬럼1', '컬럼2',...]) 이렇게도 하지만, (위에서 본 csv 형태에서 알 수 있듯이, 아마도) 거의 전체 records를 읽고, 그 중 지정한 column을 추려내는 방식으로 동작했을(것 이라고 생각되는) 작업 때문에, 불필요한 시간 낭비가 컸던게 아닌가 싶었다.
온갖 큰 데이터를, 전체/일부 불러올 때
로컬에 큰, 하나의 데이터 파일이 있는데, 분석하기 위해 이걸 불러와야하는 경우를 생각해보자.
데이터 파일은 1,000,000 rows x 30 columns 크기다.
(임시 데이터를 만들고)
(저장한다.)
이제 csv 대비 parquet 파일이, 정말 빠른지 테스트 해보자.
먼저, 이 데이터를 '전부 불러오기' 할 경우
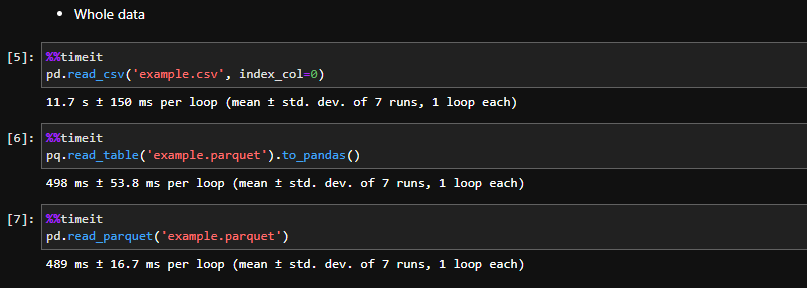
ln[5]: pd.read_csv('example.csv', index_col=0)
11.7 s ± 150 ms
ln[6]: pq.read_table('example.parquet').to_pandas()
498 ms ± 53.8 ms >>> 0.498 s ± 53.8 ms
ln[7]: pd.read_parquet('example.parquet')
489 ms ± 16.7 ms >>> 0.489 ms ± 16.7 ms
- csv로 불러올 경우 (내림해도) 약 11초
- parquet 형식으로 불러올 경우 약 0.5초
대략, 22배 빠르다.
(정말 드라마틱한 성능차이다. "ㅁ";;)
'일부 컬럼만 불러오기' 할 경우는 어떨까.
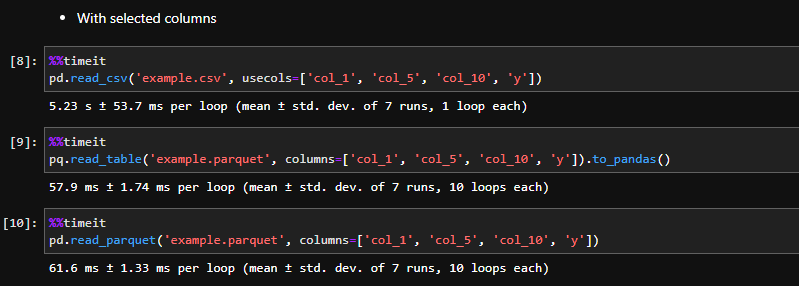
ln[8]: pd.read_csv('example.csv', usecols=['col_1', 'col_5', 'col_10', 'y'])
5.23 s ± 53.7 ms
ln[9]: pq.read_table('example.parquet', columns=['col_1', 'col_5', 'col_10', 'y']).to_pandas()
57.9 ms ± 1.74 ms >>> 0.057 s ± 1.74 ms
ln[10]: pd.read_parquet('example.parquet', columns=['col_1', 'col_5', 'col_10', 'y'])
61.6 ms ± 1.33 ms >>> 0.061 s ± 1.33 ms
- csv로 불러올 경우 약 5초
- parquet 형식으로 불러올 경우 약 0.06초
대략, 83배 빠르다.
다른 관점에서 주목해볼 부분은, 줄어든 시간의 효율 이다.
전체 데이터에서 행(row) 갯수는 그대로에, 열(columns) 갯수는 30개 4개로 줄었다. (1/10보다 약간 더 큰)
그런데, csv의 경우, 11초 5초로, 약 절반 정도 줄었고,
parquet의 경우, 0.5초 0.06초로, 약 1/10 줄었다.
parquet이 컬럼-기준의 데이터 처리로, 효율적으로 데이터를 불러온 걸 알 수 있다.
장점은 속도뿐만은 아니다.
위 간단한 실험에서 볼 수 있듯, parquet의 column-oriented 방식은 대용량의 데이터 IO에 탁월한 성능을 보인다. 하지만, parquet은 단순 속도뿐 아니라, 여러 측면에서도 데이터 취급과 처리에 용이한 특징을 지닌다고 한다.
간단하게는, 컬럼 단위에 메타데이터를 같이 보관하기 때문에, 데이터 유형이 엉키지 않게 관리하는 것에도 좋다. 가령, 'ID' = "001234" 와 같은 데이터가 있다면, csv로 저장할 때 ..., 001234, .. 이렇게 저장은 되지만, " 'ID'컬럼은 str 포멧이야" 라고 반영할 수 없다. 때문에, 다시 데이터를 불러올 때, 명시적으로 'ID': "object" 와 같은 arg를 꼭 넣어줘야만 'ID' = 1234 이렇게 숫자로 불러와지는 등의 의도하지 않은 실수가 발생하지 않는다. 하지만, parquet 포멧의 경우, file write 할 때 컬럼의 dtype을 자동으로 metadata로 저장하고, 또 특정해서 기록할 수 있다.
그 외 좋은 특징들은, parquet에 대해 자세히 설명해주신 다른 블로거분들의 글을 참조하면 좋을 것이다. (아래 글들 정말 좋아요 :) )
(위 코드는 저자의 github에서 받을 수 있다. :) )
(references:
1. [Parquet]아파치 파케이란? (Revelope님 블로그)
2. Parquet(파케이)란? 컬럼기반 포맷 장점/구조/파일생성 및 열기 (데엔잘하고싶은데엔님 블로그))
3. Reading and Writing the Apache Parquet Format(Aparch Arrow Documentation|)
