* 추천 시스템에 관한 고찰 - '어떻게' 추천 할 것인가? chapter에 첫 번째 주제로
1. 연관규칙분석(Association Rule Learning) 에 관해 이야기 해볼까 합니다.
- 연관규칙분석에 관한 고민거리와 시사점을 주로 다루고자 한다.🤔
- 각 분석론별 기본 개념 및 구체적인 수행 방법론 등은 앞으로도 가급적 뒤에 보충설명(과 훌륭한 분들의 포스트🙄..)로 간략하게 대신하려한다.
📌 Contents of the article
* 연관규칙분석, 잘 쓰고 있는걸까?
└ 1.) 간단한 소개
└ 2.) 강력한 장점
└ 3.) 분석시 유의할 점
└ 4.) (TBD)어디에 활용할 수 있을까* (TBD)연관규칙분석 수행 (다음 글)
└ 1.) (TBD)간단한 예시
└ 2.) (TBD)기본 개념과 해석
└ 3.) (TBD)유의사항
1. 연관규칙분석, 잘 쓰고 있는걸까?
1.) 간단한 소개
연관규칙(Association Rule) 분석은, 흔히 '장바구니 분석'이라는 이름과 '전설적인(?) 스토리'로 더 유명하다.
간단히 소개하자면, 어느 한 쇼핑센터에서 '기저귀와 맥주를 함께' 사는 사람이 많은 것을 보고, 두 상품 진열대를 더 가까이 위치하도록 바꿔보는 결정을 내렸다는 스토리. (* 이 이야기의 정확한 출처를 찾기 어려워 독자분들의 믿거나 말거나.. 로 두고자 한다🙄)
이 이야기에 중요한 시사점은,
"외적으로 서로 관계가 없어보이는 물건 간에도, 어떤 연관성(Association)이 있을 수 있다" 는 발상에 있다고 생각한다.
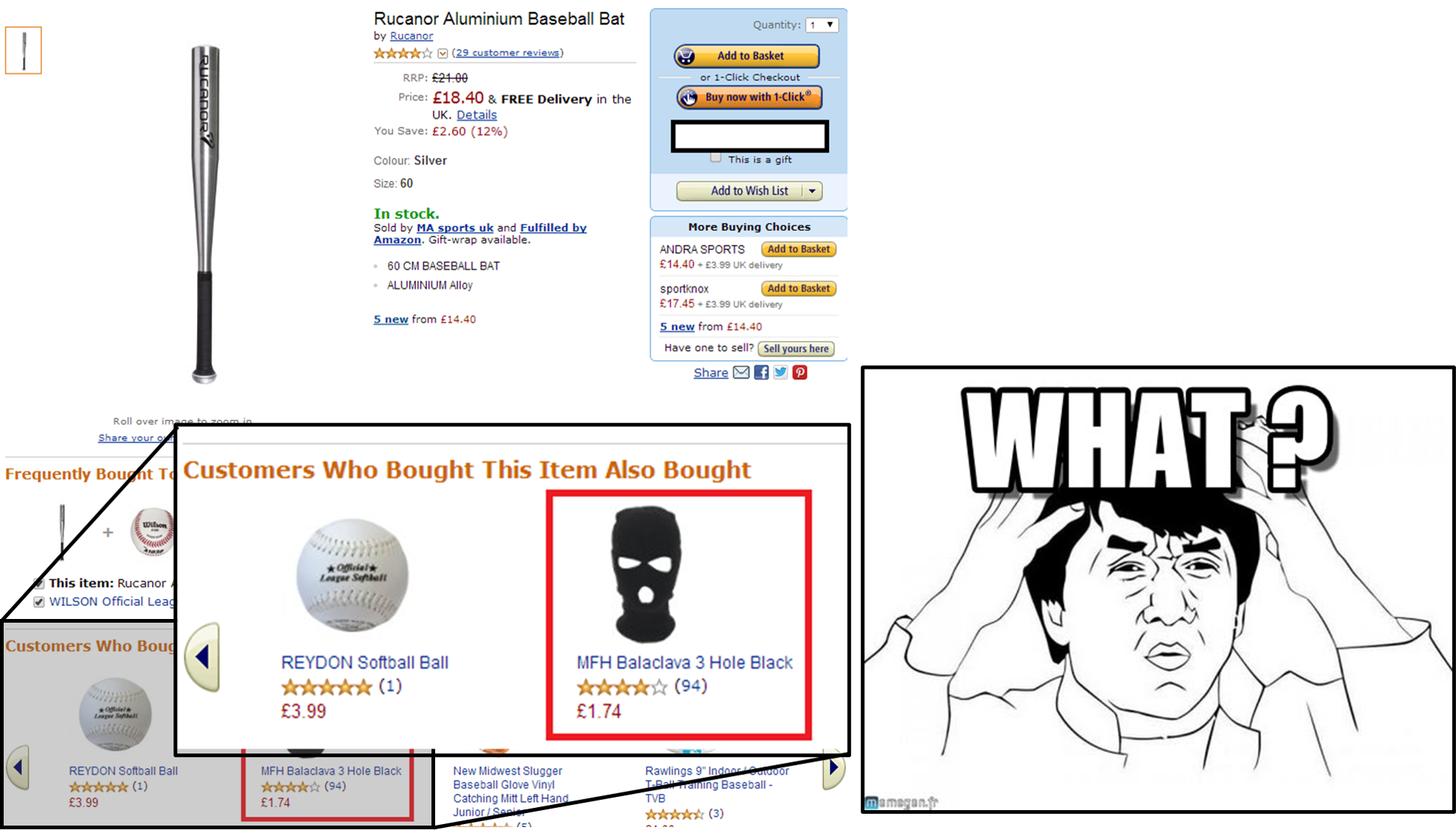
(이거만큼 기막힌 예가 있을까🤯)
덕분에 연관규칙분석은, 방법론이 비교적 간단(?)한데 비해 상품(item)간 예상치 못한 관계나 패턴을 빠르고 쉽게 발굴할 수 있어, 데이터 분석 과정 다방면에 쓰일 수 있다.
2.) 강력한 장점
그럼 먼저, '신속하면서 다방면에 유용한' 연관규칙분석에 💡강력한 장점을 보자.
- 해당 영역에 대한 특별한 사전 지식(domain Knowledge)이 없어도 수행할 수 있다.
연관규칙분석을 수행하기 위해서는, '장바구니 데이터' 단 하나만 있으면 된다. (분석에 필요한 데이터 가공 및 분석 방법은 뒤에 더 자세히 설명하고자 한다.)
이 장바구니 데이터에,
- '장바구니' 로 정의되는 하나의 entity(예: 'BASKET_ID: B1001')와
- 그 장바구니에 기록된 품목 이름만 (예: {사과, 참외, 수건})있다면,
바로 분석이 가능하다. 즉, 상품 자체의 특징이나 기타 외부 조건 등이 데이터로 반영되지 않더라도 바로 분석할 수 있다.
물론, 깊은 분석으로 들어가고 세부적인 필터링 등 비즈니스에 필요한 수준까지 개발하기 위해서는, 해당 영역에 사전 지식이 당연히 필요할 것이다. 하지만,
'사전 지식이 분석의 선행 조건은 아니'기 때문에,
1) 많은 조건을 고려하느라 소요되는 시간을 벌 수 있고,
2) 특정 domain 전문가가 아니라도, 유의미한 여러 패턴을 식별 할 수 있다-
는 점은, 분명히 많은 실무영역에서 큰 장점으로 작용할 만 하다.
- 다른 목적의 분석, 또는 분석 과정 중에도 유연하게 활용할 수 있다.
연관규칙분석이라는 이름 자체를 곱씹어 보면, 이 분석 방법론은 꼭 추천이 아니더라도
'특정 사건(event)에 관해, 연관된 -또는 빈번한- 규칙(pattern)' 을 찾고자 하는 경우라면 언제든지 활용을 고려해볼 수 있겠다.
예컨데, 이번에 새로 런칭한 프로덕트의 구매 전환율을 높이기 위해 pain-point를 식별하는 task를 가정해보자. 그러면 해당 프로덕트를 구매 하기까지 핵심 단계들을 정의하고 이를 정리하여 funnel로 정의하는 과정이 필요하다.
이제 생각을 확장해볼 기회다. 우리에겐 -
'해당 프로덕트를 구매 한 고객의 해당 세션 앱 로그 데이터' 가 있고, 이를 바탕으로 -
'구매 전환(event)을 위한 핵심 화면(pattern)' 을 발굴해볼 수 있겠다. (해당 세션 1회는 '장바구니'가 되고, 각 세션별로 거쳐간 모든 화면번호는 '장바구니 안에 상품명'이 된다.)
그러면, 서비스를 기획하면서 핵심 단계로 여겼던 부분 중에서 그렇지 못한 부분이 식별될 수도 있고, 기획 단계에서는 전혀 파악하지 못했던 부분에서 핵심 단계 혹은 이탈 지점(pain-point)이 발견 될 수도 있다. (상세한 활용 방안은 아래에서 다시 구체적으로 논의하고자 한다.)
💡 정리하면, 연관규칙분석의 큰 장점은 :
1. 분석을 위한 복잡한 가정이 필요없다. 그만큼 빠르게 접근할 수 있고, 상대적으로 사전 지식이 부족해도 다양한 패턴을 먼저 도출해볼 수 있다.
2. 다양한 목적에 맞게 분석을 응용하여 쓸 수 있다. 추천 시스템이 아니더라도 유용하게 쓸 수 있는 경우가 무척 많다.
3.) 분석시 유의할 점
그럼 반대로, 연관규칙분석 수행 전에 ❗염두해야 할 부분은 무엇이 있을까.
- 상품(item) 간의 선/후(, 또는 인과)관계는 알 수 없다.
'기저귀를 산() 고객들은, 맥주도 산() 경우가 많았다' 는 말은, 자칫 -
'기저귀를 사면, 맥주도 산다'() 와 같이 인과관계로 해석할 수 있다.
하지만 이는 분명히 다르다.
우리가 장을 보러갈 때는 보통, -
'이번에 기저귀, 분유... 아 그리고 맥주도 사야지' 라고 생각한다
(너무 무리한 일반화..는 아닐...🤔).
'기저귀를 사지 못한다면 맥주는 근처에 얼씬도 못 할 줄 알아라🤬' 고
생각하는 고객도 어쩌면 있을 '수'는 있지만🙄,
그것이 여전히 '상품 간 인과관계'를 의미하는 것은 아니다.
(장보기-맥주-사수 미션에 '먼저 완수해야하는 선제 조건'🐱👤이라는 '제 3의 요인'이 있던 것이지, 상품 간 인과에 해당하지 않는다.)
이는 구체적으로는 -
'상관관계가 인과관계를 암시하진 않기 때문'(Correalation does not imply causation)(링크📎)이다.
'기저귀를 담은 고객()은 맥주도 담을() 확률(=)이 높다'고는 할 수 있으나, 그렇다고
'기저귀를 담지 않으면() 맥주도 담지 않을() 확률이 높다'가 성립할 수는 없는 것이다.
이제 '장 보는 상품 간 인과가 있냐 없냐'(현실 영역)에서 관심을 조금 돌려, 분석 자체를 고려해보자. 연관규칙분석에서는, 하나의 장바구니 안에 담긴 모든 품목이 순서(: 실제 장바구니에 담은 순서, 계산 순서 등.) 와 상관없이 반영된다. 분석을 통해서 파악하고자 하는 정보는 -
'해당 장바구니에 어떤 품목들이 함께 포함되었는가'이다.
'A상품이 B상품보다 먼저 담겼냐 나중에 담겼냐'와 같은 -
선행여부 등은 아예 반영될 수 없는 데이터 형태에서 출발한다.
그렇기 때문에, 선/후관계 등이 중요한 경우에는 연관규칙분석 사용과 해석에 주의가 필요하다.
- 상품별 수량은 고려되지 않는다.
어떤 경우에는, 특정 품목의 담긴 수량에 따라 상황이 다를 수도 있다.
예컨데, 삼겹살을 10인분 이상 구매한 고객은 가스버너용 부탄가스도 함께 구매하는 경우가 많지만, 10인분 미만으로 구매한 고객은 그렇지 않다거나, (좋은 예시를 구하고 싶은데 잘 떠오르지가 않습니다!! 아아ㅏ아악아ㅏㅏ😱) 하는 등, 이와 같이 특정 품목도 그 수량에 따라 함께 구매하는 품목이 달라질 수 있다.
하지만 연관규칙분석에서는 '수량'의 차이에 따른 영향은 구분할 수 없*다. 단순히 이 품목이 포함되었는가(binary)만 반영할 뿐, '어느 정도(scale)'인가는 반영할 수 없다.
(* 구체적으로는, 각각 다른 수량을 구매한 여러 상황들이 하나의 품목으로 흡수되어 여러 다양한 케이스가 혼합되어 반영될 것이다.)
이런 이유로, 품목과 해당 품목에 대한 수치값 또한 중요한 경우라면, 연관규칙분석 사용에 주의가 필요하다. 예컨데, Netflix와 같이 컨텐츠를 시청하고 이 컨텐츠가 '좋았는지, 나빴는지'에 대한 평가 역시 중요하다면, 단순히 시청기록만을 고려해 추천을 줄 수 없는 것과 같다.
(다음 포스트에도 자주 언급하겠지만, 품목에 대한 수치 변수는 추천에서 상당히 중요하다. YouTube는, 특정 컨텐츠에 유입 후 '얼마나 오래 체류'했는가를 활용하는 것으로 알려져있다. )
- '상품명' 그 이외에는, 어떤 외생변수도 고려되지 않는다.
'컵라면을 산 사람은 김치도 같이 산 경우가 많았다'고 가정해보자. 이런 경우, 라면먹을 때 김치도 같이 먹으려고 구매한 경우라고 생각해볼 수 있겠다. (국룰아닙니까 국룰!) 즉, 라면과 김치가 서로 보완관계(complementary)를 갖는 경우로 해석할 수 있고, 이를 바탕으로 어떤 마케팅 의사결정을 내릴 수도 있을 것이다.
이번엔 다른 예로, 최근 코로나-19 팬데믹으로 생긴 상황을 바탕으로 가정해보자. 고객의 장바구니를 분석한 결과 라면을 산 사람 중에서 마스크도 함께 산 경우가 많았다.(링크📎) 이때, 라면과 마스크가 서로 보완성을 갖는다고 해석할 수는 없다. 라면과 마스크를 함께 산 이유는 코로나-19 팬데믹이라는 제 3의 요인에서 기인한, 개인 방역과 격리 대비라는 상황적 원인이 따로 있었기 때문이다.
이렇게 연관규칙분석 만으로는, '상품명' 그 자체를 제외한 모든 복잡다단한 요인을 알기 어렵다. 요인을 파악하기 위해서는, 분석의 결과를 바탕으로 '해석을 위한 고도의 탐색과 실험'이 수반되야만 한다.
이런 노력이 충분히 뒤따르지 못한다면, 사려깊지 못한 해석으로 비즈니스에 좋지 못한 영향을 주는 의사결정이 내려질 가능성이 더 높아진다고 생각한다. 예를 들어, 라면을 사면 마스크를 끼워주는'(링크📎) 등의 마케팅과 같은... (그런데, 그 일이 실제로 벌어졌습니다...😑)
4.) 어디에 활용할 수 있을까
TBD (좋은 컨텐츠로 곧 업데이트 할 예정입니다! :D )
