
어무해(django)는 공식문서에서 많은 performance와 optimization에 관련된 정보를 제공한다.
HTTP, Template 혹은 caching까지 다양하게 문서가 정리되어 있다.
이 글에서는 DB쪽을 다루도록 하겠다.
사실 DB만 해도 분량이 어마어마하다.
추가로, Template 관련된 부분은 생략했다.
개인적으로 django template을 사용하지 않기 때문이다...
0. Profile first
성능 개선을 원한다면 가장 먼저 해야 할 것이 profiling이다.
참고 : 비단 django나 database 관련된 성능 개선이 아니더라도 그 어떠한 성능 개선이든 첫 단계로 profiling을 해야 한다.
그리고 마지막 단계에서도 profiling을 해야 한다.
그래야 실제로 성능 개선이 이루어졌는지 알 수 있고, 적용할지 말지 결정을 내릴 수 있다.
What is profiling?
분석이다.
범죄 프로파일링이 범죄자의 심리 및 행동 등을 분석하듯이,
코드에서의 프로파일링은 코드의 어떤 부분이 시간이 오래 걸리고, 자원을 많이 사용하고, bottleneck을 발생시키는지 등등을 알아낸다.
How to profile
django에서 DB 관련된 profiling은 크게 두 가지 방법이 있다.
QuerySet.explain()
django QuerySet API를 사용한다.
.explain 메서드는 해당 QuerySet의 실행이 어떻게 이루어질지 설명해준다.
단, 어떤 DB를 쓰느냐에 따라 output 양식이 많이 다르다.
- PostgreSQL

- sqlite3

자세한 내용은 django QuerySet API - explain()을 확인해보자.
django-debug-toolbar
써드파티 툴이다.
아래처럼 SQL 작업 정보를 확인할 수 있다.
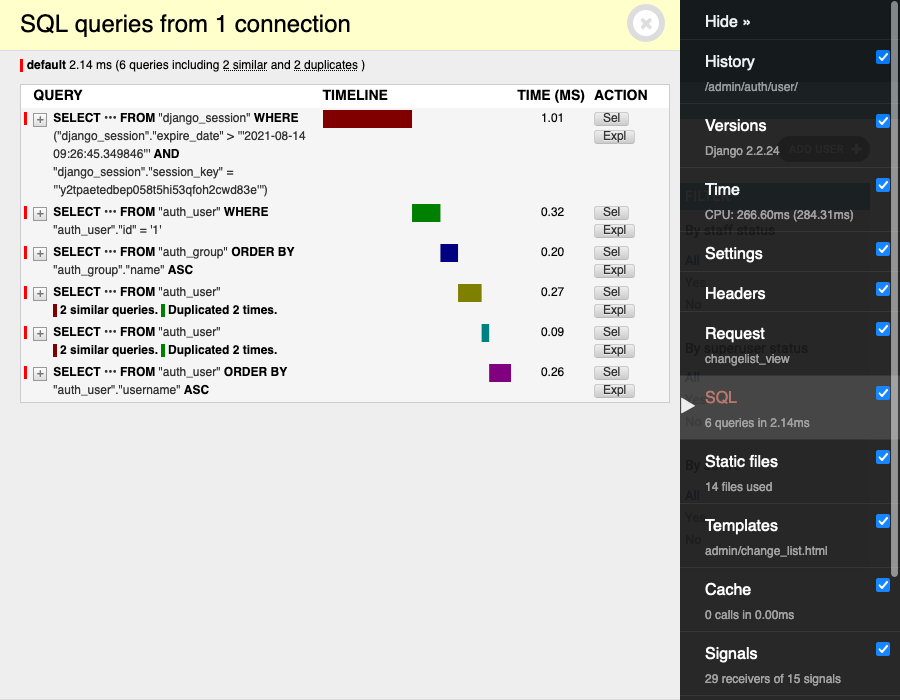
공식문서에서도 사용을 추천한다.
자세한 내용은 django-debug-toolbar를 확인해보자.
Standard Optimization technique
일반적인 DB 최적화 기법을 설명한다.
공식 문서에서는 이 부분이 django만의 특징이 아니기 때문에 자세히 다루지 않는다.
Indexing
DB table에서 특정 field로 원하는 데이터의 위치를 빠르게 알아내기 위한 기법이다.
자세한 내용은 링크를 확인하자.
공식 문서에서조차 여기를 링크로 걸었다.
django에서는 Meta.indexes나 Field.db_index로 index를 제공한다.
자주 query하는 field가 어떤 것인지 판단하고 index에 추가할 지 결정하자.
Appropriate type of field
제곧내.
예를 들어, 길이 제한이 없는 텍스트를 저장하는 field로는 TextField를 쓰고
길이 제한이 있는 field로는 CharField를 쓰자.
Understanding QuerySet
django에서 QuerySet이 어떤 것이고, 어떻게 동작하는지 이해해야 한다.
QuerySet은 이름 그대로 sql query의 집합이다.
실행하고자 하는 query의 묶음이라고 생각하자.
QuerySets are lazy
왜 query를 묶는 걸까?
DB 접근을 최소화하기 위해서다.
자세히 말하자면, query 마다 DB에 접근하는 대신, query를 최대한 묶어서 DB 접근을 줄이기 위함이다.
그래서 QuerySet은 query 결과를 요청하지 않는 한, 실제로 DB에 접근하지 않는다.
그래서 "QuerySets are lazy" 라고 한다.
>> engineers = Employee.objects.filter(title="Engineer")
>> backends = engineers.filter(detail="Backend")
>> senior_backends = backends.exclude(age__lt=30)
>> print(senior_backends) # DB hit위 코드를 예로 들자면,
마지막 print문에서만 실제 DB query가 발생한다.
When QuerySets are evaluated?
그럼 언제 실제 query가 요청되는 걸까?
QuerySet에 아래 작업을 실시할 때 DB에 실제로 접근하게 된다.
-
Slicing
-
Pickling/Caching
-
repr()
-
len()
Note: 단순히 set의 길이만 알고 싶다면 QuerySet API -count()를 사용하자. DB 레벨에서SELECT COUNT(*)를 사용하기 때문에 효율적이다. -
list()
-
bool()
Note: 단순히 query 결과가 존재하는지만 알고 싶다면 QuerySet API -exists()를 사용하자. 더 효율적이다.
How the data is held in memory
QuerySet은 DB 접근을 더 줄이기 위해 결과를 caching 한다.
QuerySet이 처음 evaluate 되면 django에서 결과를 caching하고 반환해준다.
그리고 caching된 QuerySet에서 이어지는 evaluation에서는 cache 정보를 사용한다.
하지만 QuerySet이 evaluate되는 모든 경우에 caching되진 않는다.
When QuerySets are not cached
아래와 같은 경우, 똑같은 query가 DB에서 두 번 실행하게 된다.
때문에 두 query 사이에 Entry가 수정되면 두 list 결과물이 다를 수 있다.
>>> print([e.headline for e in Entry.objects.all()])
>>> print([e.pub_date for e in Entry.objects.all()])이런 상황을 막고 싶다면 아래처럼 QuerySet 결과물을 어딘가에 저장해두면 된다.
>>> queryset = Entry.objects.all()
>>> print([p.headline for p in queryset]) # Evaluate the query set.
>>> print([p.pub_date for p in queryset]) # Re-use the cache from the evaluation.또 다른 caching되지 않는 경우로는 queryset을 제한하는 경우가 있다.
아래처럼 배열의 index 사용이나 slicing을 하게되면 caching이 되지 않는다.
>>> queryset = Entry.objects.all()
>>> print(queryset[5]) # Queries the database
>>> print(queryset[5]) # Queries the database again이런 경우, 아래처럼 queryset 전체를 evaluate하면 caching된다.
>>> queryset = Entry.objects.all()
>>> [entry for entry in queryset] # Queries the database
>>> print(queryset[5]) # Uses cache
>>> print(queryset[5]) # Uses cacheUnderstand cached attributes
QuerySet의 결과물이 caching되는 것처럼 ORM 객체의 attribute 결과물도 caching된다.
주의해야 할 것은, ORM 객체 자체가 아니라 attribute들이 caching된다는 점이다.
>>> entry = Entry.objects.get(id=1)
>>> entry.blog # Blog 객체가 반환된다. DB hit
>>> entry.blog # cache된 것. no DB hit아래처럼 callable attribute에 대해서는 매번 DB에 접근하게 된다.
>>> entry = Entry.objects.get(id=1)
>>> entry.authors.all() # query 실행
>>> entry.authors.all() # query 또 실행Use iterator()
객체가 너무 많은 경우, QuerySet을 caching하면 메모리를 그만큼 잡아먹기 때문에 오히려 독이 될 수 있다.
이럴 때는 .iterator()를 사용하자
모든 결과물을 반환하지 않고 Python iterator를 반환시켜준다.
단, .iterator()로 queryset을 evaluate하면 매번 DB 접근하게 된다.
Use explain()
이미 설명했으니 짧게...
QuerySet.explain()을 적극 활용하자.
Do database work in the database rather than in Python
DB 작업은 Python에서 하지 말고 DB 단에서 하자는 의미다.
-
F expression으로 model field에 대한 DB 작업을 DB 단에서 실행할 수 있도록 한다. Python 메모리까지 데이터를 가져오지 않게 해준다.
-
DB에서 aggregation을 한다.
이 정도로 원하는 SQL 문을 작성할 수 없다면, 아래 옵션이 있다.
Use RawSQL
RawSQL 표현식으로 SQL을 명시적으로 query에 추가할 수 있다.
만약 이것도 모자라다면...
Use raw SQL
직접 SQL을 작성하여 데이터를 가져오거나 모델을 생성할 수 있다.
Retrieve individual objects using a unique, indexed column
DB에서 index된 column값이나 유일한 값으로 데이터를 찾아내는 방식이 빠르다는 것은 일반적이다.
>>> entry = Entry.objects.get(id=10) # id는 index 되어있다.
>>> entry = Entry.objects.get(headline="News Item Title") # headline은 index되어있지 않다.이런 경우, 첫 번째 코드가 더 빠르다.
Retrieve everything at once if you know you will need it
DB에서 유명한 N+1 문제와 연관되어 있다.
N+1 문제란?
DB에서 연관 관계relation이 있는 엔티티를 읽어온 뒤, 각 엔티티 별로 연관 관계의 데이터를 또 읽어오는 쿼리를 실행해야 하는 문제.
처음 1번의 쿼리로 (n)개의 데이터를 가져오고, n개의 데이터마다 쿼리를 실행해야하는 문제다.
일반적으로 DB 단에서 LEFT JOIN으로 해결한다.
django에서는 select_related()와 prefetch_related()를 사용한다.
Don’t retrieve things you don’t need
정확히 필요한 정보만 가져오는 편이 좋다.
아래는 그 방법들이다.
Use QuerySet.values() and values_list()
QuerySet.values() 혹은 QuerySet.values_list()를 사용하여 ORM model 객체가 아닌 dict 혹은 list 타입의 value만 가져올 수 있다.
Use QuerySet.defer() and only()
defer()와 only()로 필요하지 않은 DB column을 제외하고 데이터를 가져올 수 있다.
defer()로 가져오고 싶지 않은 column을 제외할 수 있고, 반대로 only()는 가져올 column을 설정할 수 있다.
주로 큰 text data나 Python에서 데이터를 변환하는데 비싼 계산이 필요한 field만 제외시킬 때 유용하다.
Use QuerySet.count() and QuerySet.exists()
단순히, QuerySet의 길이만 알고 싶다면 QuerySet.count()를 사용하고
QuerySet이 존재하는지만 알고 싶다면 QuerySet.exists()를 사용하자.
하지만!
Do not overuse count() and exists()
단순히 queryset의 길이나 존재 여부만 판단하는 것이 아니라, QuerySet에서 직접 데이터를 사용해야 한다면 count()나 exists()를 사용하지 말자.
이 때는 바로 QuerySet의 evaluation을 해야하는데 count()나 exists()는 데이터를 모두 가져오지 않기 때문이다.
Use QuerySet.update() and delete()
모델 객체를 일일이 값 설정하고 저장하는 방식보다 bulk SQL UPDATE를 사용하도록 하자.
QuerySet.update()나 bulk delete를 사용할 수 있다.
위 메소드는 개별 instance의 save()나 delete() 메소드를 실행시키지 않는다.
Use foreign key values directly
foreign key 객체 전체가 필요한 것이 아니라 value 하나만 필요하다면 foreign key value만 사용하자.
>>> entry.blog_id # using foreign key value
>>> entry.blog.id # getting the whole related objectDon’t order results if you don’t care
ordering은 공짜가 아니다. QuerySet.order_by()
필요한 경우가 아니라면 ordering하지 말자.
참고로, order_by()에 아무 인자를 넘겨주지 않으면 모델 default ordering을 무시할 수 있다.
Use bulk methods
SQL 명령어 수를 줄일 수 있다.
bulk_create(), bulk_update(), add(), remove() 메소드들이 bulk 작업이 가능하다.
각각 create in bulk, update in bulk, insert in bulk, remove in bulk 항목이다.
주의! 모두 conflict 처리를 어떻게 해야할지 고민해야 한다.

정리 감사드립니다