JVM
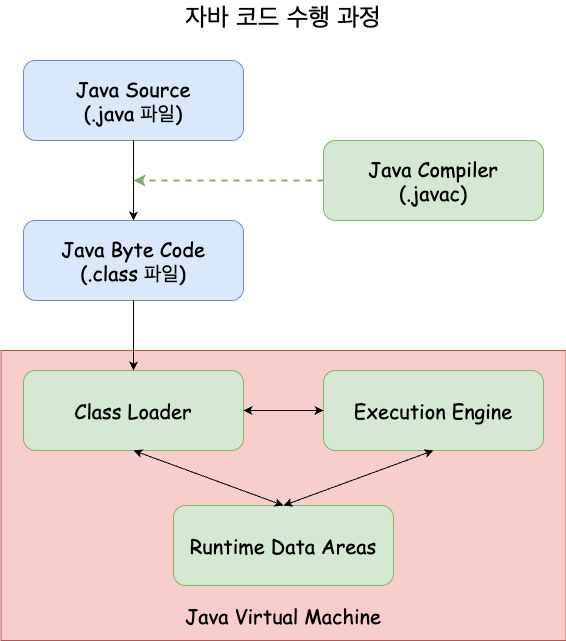
프로그래머가 Java 로 작성한 코드(.java) 는 위와 같은 과정을 통해 작동한다.
위의 그림에서 Java Virtual Machine 이라고 명명된 것이 JVM 이다.
자바 1.3 버전 부터 HotSpot 을 기본 VM 으로 사용해왔기 때문에 지금 운영되고 있는 대부분의 시스템들은 모두 HotSpot 기반의 VM 이라고 생각하면 된다.
JVM의 주요 역할은 아래와 같다.
💡 클래스 로더(Class Loader)가 컴파일된 자바 바이트코드(.class)를 런타임 데이터 영역(Runtime Data Areas)에 로드하고, 실행 엔진(Execution Engine)이 자바 바이트 코드를 실행한다.
위의 그림에서 보이는 것과 같이 JVM(이하 HotSpot VM) 은 크게 3가지 주요 컴포넌트로 구성되어 있다.
- Class Loader(클래스 로더)
- Execution Engine(실행 엔진)
- Runtime Data Areas(런타임 데이터 영역)
이 3가지 주요 컴포넌트를 좀 더 세세하게 그려보면 아래 그림과 같다.
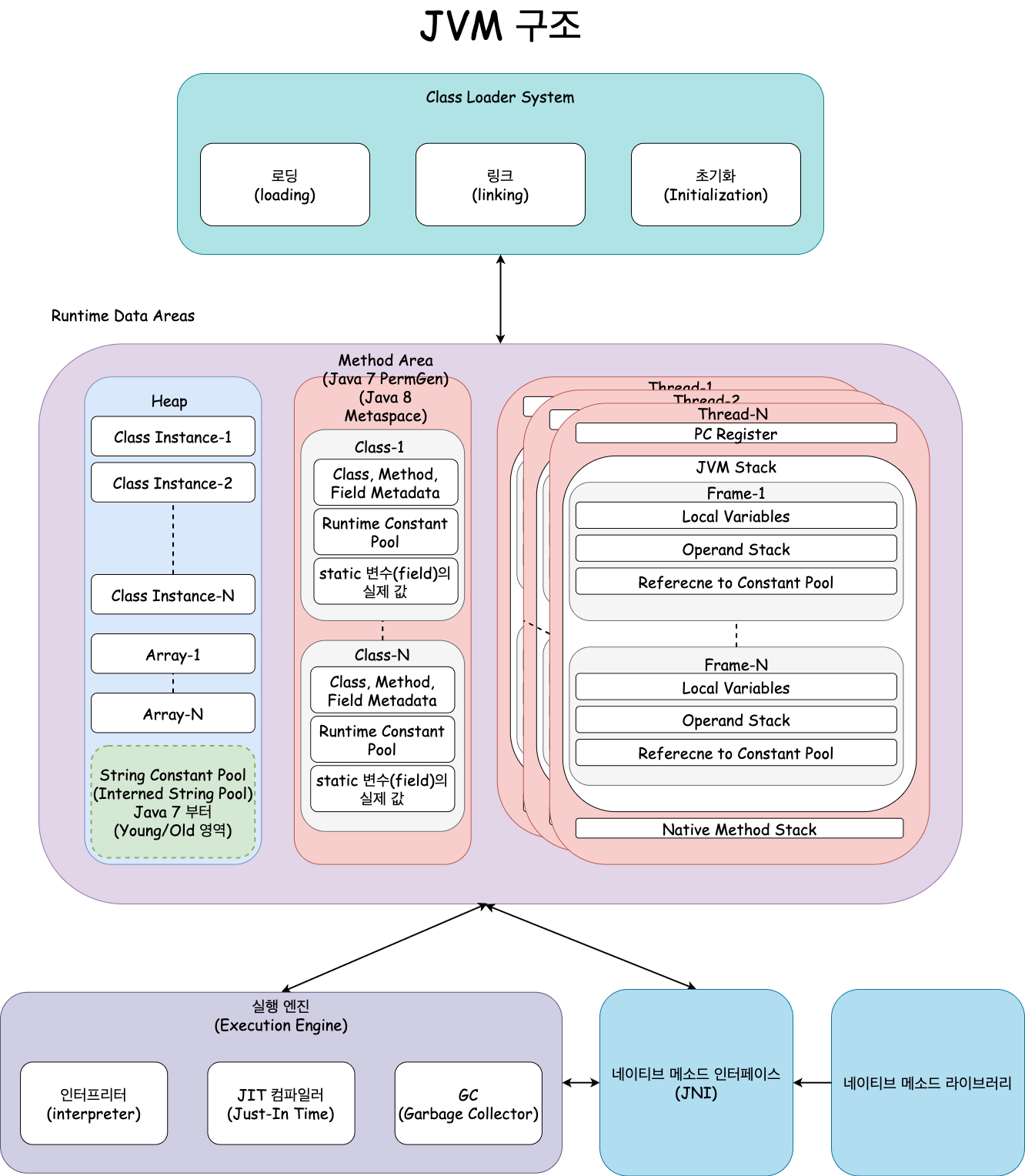
Class Loader, Runtime Data Areas, Execution Engine 순서대로 자세히 설명해보겠다.
Class Loader
클래스 로더 특징
// 소스코드
import java.util.Map;
class A {
Map<String,String> m;
}
// ↓ 컴파일 후 바이트코드 내부(의사 예시)
// Fieldref #1 = java/util/Map클래스 로더(Class Loader)란?
💡 Java는 동적 로드, 즉 컴파일타임이 아니라 런타임에 클래스를 처음으로 참조할 때 해당 클래스를 로드하고 링크하는 특징이 있다. 이 동적 로드를 담당하는 부분이 JVM의 클래스 로더이다.
각 클래스 로더는 로드된 클래스들을 보관하는 네임스페이스(namespace)를 갖는다.
- 클래스를 로드할 때 이미 로드된 클래스인지 확인하기 위해서 네임스페이스에 보관된 FQCN(Fully Qualified Class Name)을 기준으로 클래스를 찾는다.
- 비록 FQCN이 같더라도 네임스페이스가 다르면, 즉 다른 클래스 로더가 로드한 클래스이면 다른 클래스로 간주된다.
- 클래스 로더가 클래스 로드를 요청받으면,
클래스 로더 캐시 → 상위 클래스 로더 → 자기 자신의 순서로 해당 클래스가 있는지 확인한다. - 부트스트랩 클래스 로더까지 확인해도 없으면 요청받은 클래스 로더가 파일 시스템에서 해당 클래스를 찾는다.
클래스 로더 종류
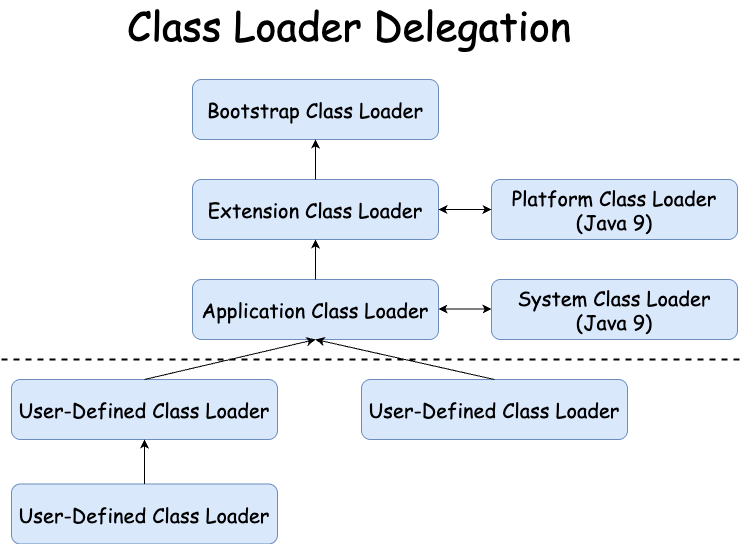
- 부트스트랩 클래스 로더(Bootstrap Class Loader): JVM을 기동할 때 생성되며, Object 클래스들을 비롯하여 자바 API들을 로드한다. 다른 클래스 로더와 달리 자바가 아니라 네이티브 코드(C/C++)로 구현되어 있다.
java.lang.Object,java.lang.String,java.util.Map,java.net.Socket
- 익스텐션 클래스 로더(Extension Class Loader) -> Java 9 이상: 플랫폼 클래스 로더(Platform Class Loader): 기본 자바 API를 제외한 확장 클래스들을 로드한다. 다양한 보안 확장 기능 등을 여기에서 로드하게 된다.
javax.crypto.Cipher,com.sun.crypto.provider.SunJCE,org.w3c.dom.Document
- 애플리케이션 클래스 로더(Application Class Loader) -> Java 9 이상: 시스템 클래스 로더(System Class Loader): 부트스트랩 클래스 로더와 익스텐션 클래스 로더가 JVM 자체의 구성 요소들을 로드하는 것이라 한다면, 시스템 클래스 로더는 애플리케이션의 클래스들을 로드한다고 할 수 있다. 사용자가 지정한 $CLASSPATH 내의 클래스들을 로드한다.
- 애플리케이션 코드 및 Gradle/Maven 의존성
com.mycompany.app.MainApplication,org.springframework.boot.SpringApplication,ch.qos.logback.classic.Logger
- 사용자 정의 클래스 로더(User-Defined Class Loader): 애플리케이션 사용자가 직접 코드 상에서 생성해서 사용하는 클래스 로더이다.
- 개발자가
extends ClassLoader또는new URLClassLoader(...)로 직접 만들어 쓰는 로더
- 개발자가
웹 애플리케이션 서버(WAS)와 같은 프레임워크는 웹 애플리케이션들, 엔터프라이즈 애플리케이션들이 서로 독립적으로 동작하게 하기 위해 사용자 정의 클래스 로더를 사용한다.
- WAS의
WebappClassLoader,ModuleClassLoader등은 이 시스템 클래스 로더를 부모(Parent) 로 삼아 직접java.lang.ClassLoader를 확장·구현한 커스텀 로더입니다.
클래스 로딩 과정
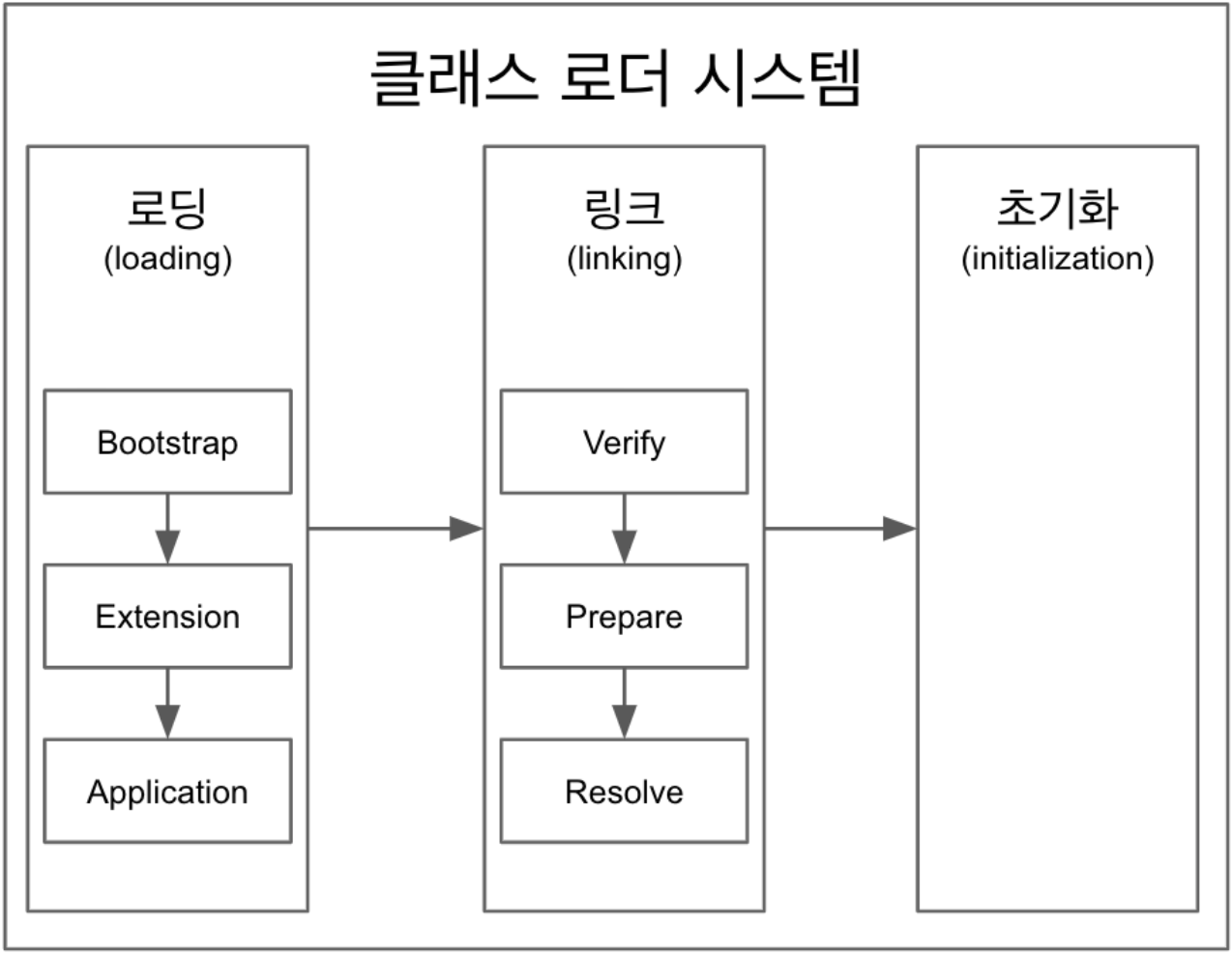
💡 .class 에서 바이트코드를 읽고 메모리(Method Area, Heap Area)에 저장
- 로딩: 클래스 읽어오는 과정
- 링크: 레퍼런스들을 연결한다
- 초기화: static 값들 초기화 및 변수에 할당
로딩(loading)
클래스를 파일에서 가져와서 JVM의 메모리(Method Area, Heap Area)에 로드한다.
메소드 영역에 저장되는 데이터
- FQCN(Fully Qualified Class Name)
- 풀패키지 경로
- class, interface, enum 인지 구분을 한다.
- 메소드와 변수
로드가 끝나면 해당 클래스의 Class객체를 생성하여 힙 영역에 저장한다.
링크(linking)
- 검증(Verifying): 읽어 들인 클래스가 자바 언어 명세(Java Language Specification) 및 JVM 명세에 명시된 대로 잘 구성되어 있는지 검사한다. 클래스 로드의 전 과정 중에서 가장 까다로운 검사를 수행하는 과정으로서 가장 복잡하고 시간이 많이 걸린다. JVM TCK의 테스트 케이스 중에서 가장 많은 부분이 잘못된 클래스를 로드하여 정상적으로 검증 오류를 발생시키는지 테스트하는 부분이다.
- 준비(Preparing): 클래스가 필요로 하는 메모리를 할당하고, 클래스에서 정의된 필드, 메서드, 인터페이스들을 나타내는 데이터 구조를 준비한다.
- 분석(Resolving): 클래스의 상수 풀 내 모든 심볼릭 렌퍼런스를 메소드 영역에 존재하는 실제 레퍼런스로 교체한다.
초기화(Initializing)
클래스 변수들을 적절한 값으로 초기화한다. 즉, static initializer들을 수행하고, static 필드들을 설정된 값으로 초기화한다.
런타임 데이터 영역(Runtime Data Areas)
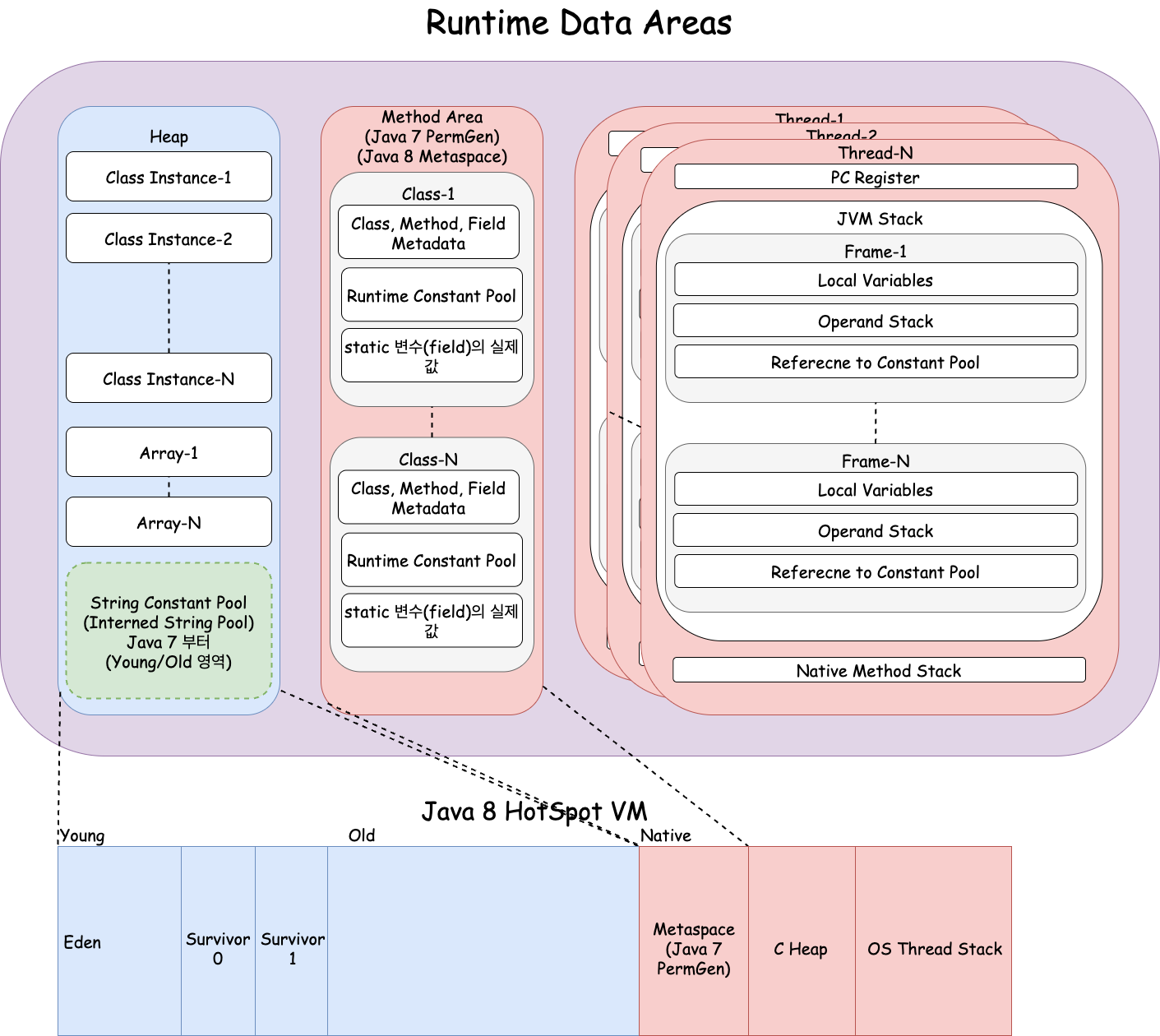
💡 런타임 데이터 영역은 JVM이라는 프로그램이 운영체제 위에서 실행되면서 할당받는 메모리 영역이다.
스레드 고유 영역
- PC 레지스터: PC(Program Counter) 레지스터는 각 스레드마다 하나씩 존재하며 스레드가 시작될 때 생성된다. PC 레지스터는 현재 수행 중인 JVM 명령의 주소를 갖는다.
- 네이티브 메서드 스택: 자바 외의 언어로 작성된 네이티브 코드를 위한 스택이다. 즉, JNI(Java Native Interface)를 통해 호출하는 C/C++ 등의 코드를 수행하기 위한 스택으로, 언어에 맞게 C 스택이나 C++ 스택이 생성된다.
- JVM 스택: JVM 스택은 각 스레드마다 하나씩 존재하며 스레드가 시작될 때 생성된다. 스택 프레임(Stack Frame)이라는 구조체를 저장하는 스택으로, JVM은 오직 JVM 스택에 스택 프레임을 추가하고(push) 제거하는(pop) 동작만 수행한다. 예외 발생 시 printStackTrace() 등의 메서드로 보여주는 Stack Trace의 각 라인은 하나의 스택 프레임을 표현한다.
- Stack Frame: JVM 내에서 메서드가 수행될 때마다 하나의 스택 프레임이 생성되어 해당 스레드의 JVM 스택에 추가되고 메서드가 종료되면 스택 프레임이 제거된다. 각 스택 프레임은 지역 변수 배열(Local Variable Array), 피연산자 스택(Operand Stack), 현재 실행 중인 메서드가 속한 클래스의 런타임 상수 풀에 대한 레퍼런스를 갖는다. 지역 변수 배열, 피연산자 스택의 크기는 컴파일 시에 결정되기 때문에 스택 프레임의 크기도 메서드에 따라 크기가 고정된다.
- Local Variables: 0부터 시작하는 인덱스를 가진 배열이다. 0은 메서드가 속한 클래스 인스턴스의 this 레퍼런스이고, 1부터는 메서드에 전달된 파라미터들이 저장되며, 메서드 파라미터 이후에는 메서드의 지역 변수들이 저장된다.
- Operand Stack: 메서드의 실제 작업 공간이다. 각 메서드는 피연산자 스택과 지역 변수 배열 사이에서 데이터를 교환하고, 다른 메서드 호출 결과를 추가하거나(push) 꺼낸다(pop). 피연산자 스택 공간이 얼마나 필요한지는 컴파일할 때 결정할 수 있으므로, 피연산자 스택의 크기도 컴파일 시에 결정된다.
스레드 공유 영역
메서드 영역은 JVM 벤더마다 다양한 형태로 구현할 수 있으며, 오라클 핫스팟 JVM(HotSpot JVM)에서는 흔히 PermGen이라고 불린다. Java 8 부터는 Metaspace 로 분리되어 Native Memory 영역에 포함된다. String Constant Pool 은 Java 7 부터 Heap 의 Young/Old 영역으로 이동했다. 그래서 사용되지 않는 intern된 문자열도 Heap GC 의 대상이 되어서 수거 가능해졌다. 메서드 영역에 대한 가비지 컬렉션은 JVM 벤더의 선택 사항이다.
- Method Area: 메서드 영역은 모든 스레드가 공유하는 영역으로 JVM이 시작될 때 생성된다. JVM이 읽어 들인 클래스/메서드/필드 메타데이터, 런타임 상수 풀, Static 변수 등을 보관한다.
- Runtime Constant Pool: 클래스 파일 포맷에서 constant_pool 테이블에 해당하는 영역이다. 메서드 영역에 포함되는 영역이긴 하지만, JVM 동작에서 가장 핵심적인 역할을 수행하는 곳이기 때문에 JVM 명세에서도 따로 중요하게 기술한다. 각 클래스와 인터페이스의 상수뿐만 아니라, 메서드와 필드에 대한 모든 레퍼런스까지 담고 있는 테이블이다. 즉, 어떤 메서드나 필드를 참조할 때 JVM은 런타임 상수 풀을 통해 해당 메서드나 필드의 실제 메모리상 주소를 찾아서 참조한다.
- Heap Area: 인스턴스 또는 객체를 저장하는 공간으로 가비지 컬렉션 대상이다. JVM 성능 등의 이슈에서 가장 많이 언급되는 공간이다. 힙 구성 방식이나 가비지 컬렉션 방법 등은 JVM 벤더의 재량이다.
- String Constant Pool(Java 7 부터):
실행 엔진(Execution Engine)
💡 실행 엔진은 자바 바이트코드를 명령어 단위로 읽어서 실행한다.
바이트코드의 각 명령어는 1바이트짜리 OpCode와 추가 피연산자로 이루어져 있으며, 실행 엔진은 하나의 OpCode를 가져와서 피연산자와 함께 작업을 수행한 다음, 다음 OpCode를 수행하는 식으로 동작한다.
- 인터프리터(interpreter): 바이트코드 명령어를 하나씩 읽어서 해석하고 실행한다. 하나씩 해석하고 실행하기 때문에 바이트코드 하나하나의 해석은 빠른 대신 인터프리팅 결과의 실행은 느리다는 단점을 가지고 있다. 흔히 얘기하는 인터프리터 언어의 단점을 그대로 가지는 것이다. 즉, 바이트코드라는 '언어'는 기본적으로 인터프리터 방식으로 동작한다.
- JIT(Just-In-Time) 컴파일러: 인터프리터의 단점을 보완하기 위해 도입된 것이 JIT 컴파일러이다. 인터프리터 방식으로 실행하다가 적절한 시점에 바이트코드 전체를 컴파일하여 네이티브 코드로 변경하고, 이후에는 해당 메서드를 더 이상 인터프리팅하지 않고 네이티브 코드로 직접 실행하는 방식이다. 네이티브 코드를 실행하는 것이 하나씩 인터프리팅하는 것보다 빠르고, 네이티브 코드는 캐시에 보관하기 때문에 한 번 컴파일된 코드는 계속 빠르게 수행되게 된다.
모든 코드는 초기에 인터프리터에 의해서 시작되고, 수행 카운터(invocation counter) 또는 백에지 카운터(backedge counter)가 한계치에 도달했을 경우에 JIT 컴파일러의 컴파일 대상이 된다.
- 수행 카운터(invocation counter) : 메서드를 시작할 때 마다 증가
- 백에지 카운터(backedge counter) : 높은 바이트 코드 인덱스에서 낮은 인덱스로 컨트롤 흐름이 변경될 때 마다 증가
- 메서드가 루프가 존재하는지를 확인할 때 사용된다.
- 수행 카운터 보다 우선순위가 높다.
실행 엔진에는 인터프리터, JIT 컴파일러 외에도 GC(Garbage Collector)가 있다. 이 내용은 꽤나 방대하기 때문에 아래에서 자세히 다뤄보겠다.
GC(Garbage Collector)
💡 Java에서는 개발자가 프로그램 코드로 메모리를 명시적으로 해제하지 않기 때문에 가비지 컬렉터(Garbage Collector)가 더 이상 필요 없는 (쓰레기) 객체를 찾아 지우는 작업을 한다.
Garbage Collector 의 역할
- 메모리 할당
- 사용 중인 메모리 인식
- 사용하지 않는 메모리 인식
C/C++ 와 같은 언어와 다르게 프로그래머가 메모리를 명시적으로 해제하지 않기 때문에, Garbage Collector 는 사용하지 않는 메모리를 인식해서 메모리를 해제시켜줘야 한다.
이 작업을 하지 않으면 할당한 메모리 영역이 꽉 차서 JVM 에 행(Hang)이 걸리거나 더 많은 메모리를 할당하려 한다. 최대 메모리를 사용하고 있는데도 계속해서 메모리를 할당하려고 한다면 OutOfMemoryError(OOM) 가 발생하여 JVM 이 다운될 수도 있다.
❗️ 행(Hang): 서버가 요청을 처리하지 못하고 있는 상태
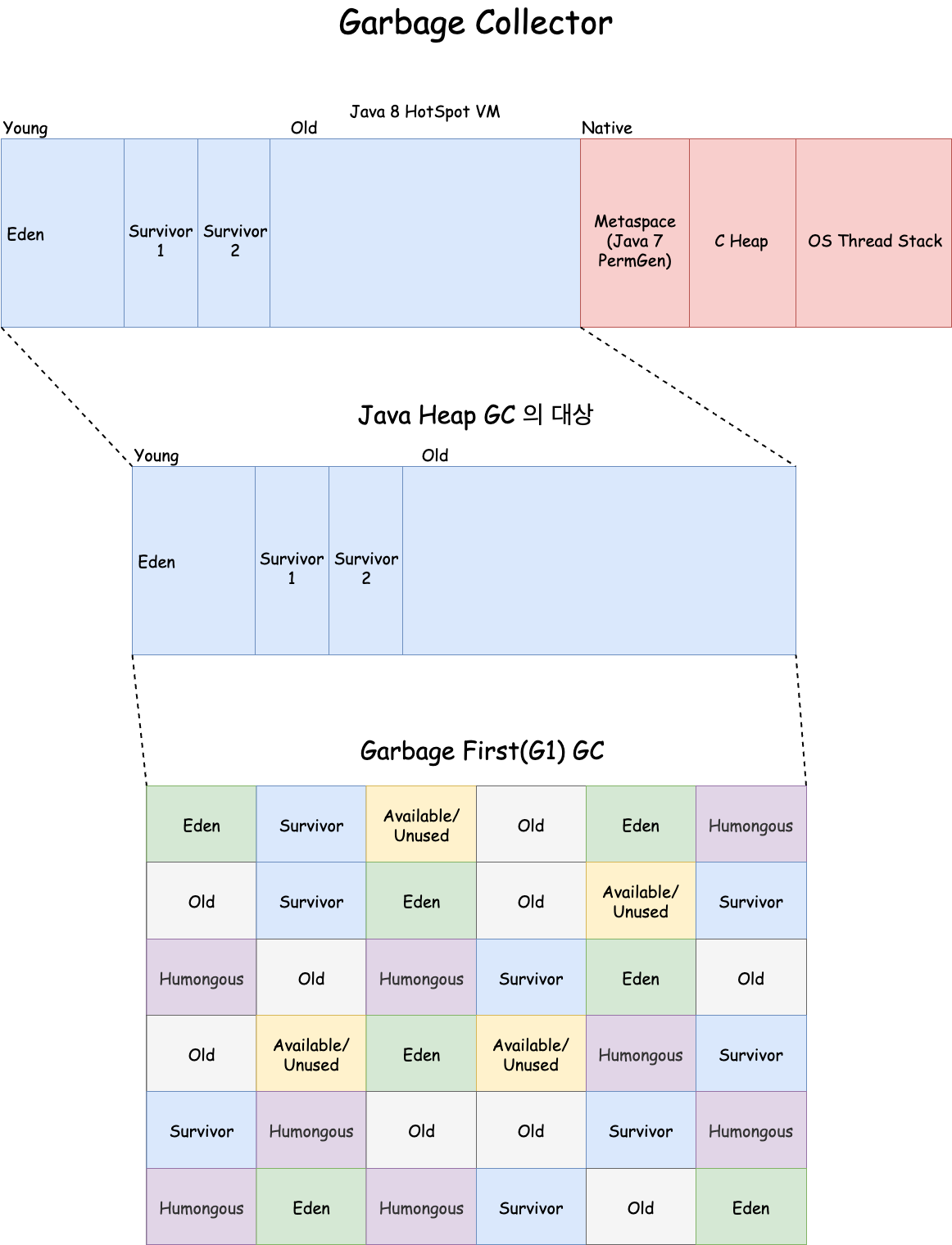
GC가 메모리를 인식, 할당, 해제하는 대상은 Heap 영역이다.
Heap 영역은 크게 2개로 나뉜다.
Heap 영역

- Young 영역(Yong Generation 영역): 새롭게 생성한 객체의 대부분이 여기에 위치한다. 대부분의 객체가 금방 접근 불가능 상태가 되기 때문에 매우 많은 객체가 Young 영역에 생성되었다가 사라진다. 이 영역에서 객체가 사라질때 Minor GC가 발생한다고 말한다.
- Old 영역(Old Generation 영역): 접근 불가능 상태로 되지 않아 Young 영역에서 살아남은 객체가 여기로 복사된다. 대부분 Young 영역보다 크게 할당하며, 크기가 큰 만큼 Young 영역보다 GC는 적게 발생한다. 이 영역에서 객체가 사라질 때 Major GC(혹은 Full GC)가 발생한다고 말한다.
Young 영역은 Eden 영역, 2개의 Survivor 영역으로 나뉜다.
메모리에 객체가 처음 생성되면, Eden 영역에 객체가 지정된다.
Eden 영역이 꽉 차면 Survivor 영역 2개 중 한 곳으로 이동한다. Survivor 2개 영역 중 우선순위는 없다. 다만, 2개 중 1곳은 반드시 비어있어야 한다. 비어있는 Survivor 영역에 Eden 영역의 GC 후에 살아남은 객체들이 이동한다.
Survivor 영역 중 한 곳이 꽉 차면, GC 가 되면서 Eden 영역과 꽉 찬 Survivor 영역에 있는 객체가 비어있는 다른 Survivor 영역으로 이동한다.
이 과정을 반복하다가 Survivor 1, 2를 왔다 갔다 하던 객체들이 Old 영역으로 이동한다.
Young 영역에서 객체가 생성된 후에 Survivor 를 거치지 않고 바로 Old 영역으로 이동하는 객체도 있을 수 있는데, 객체의 크기가 Survivor 영역 한 곳의 크기 보다 큰 경우이다.
GC의 종류
- Minor GC: Young 영역에서 발생하는 GC
- Major GC(혹은 Full GC): Old 영역에서 발생하는 GC
- Perm 영역은 Java 7 까지는 Java Heap GC의 대상이었지만, Java 8 부터는 구현체가 Metaspace 로 바뀌고, Native Memory 영역에 포함되어 Java Heap GC의 대상이 아니다.
GC의 종류는 크게 2가지이다.
이 2가지 GC가 어떻게 상호작용 하느냐에 따라 GC 방식에 차이가 나며, 성능에도 영향을 끼친다.
GC 가 발생하거나 객체들이 한 영역에서 다른 영역으로 이동할 때 애플리케이션 병목이 발생하면서 성능에 영향을 끼친다.
요즘의 대부분의 WAS 는 멀티 쓰레드로 동작한다. Thread-Safe하기 위해서 만약 여러 스레드에서 사용하는 객체를 Eden 영역에 저장하려면 락(lock)이 발생할 수 밖에 없고, lock-contention 때문에 성능은 매우 떨어지게 될 것이다. 그래서 HotSpot VM 에서는 이를 해결하기 위해, 스레드 로컬 할당 버퍼(Thread-Local Allocation Buffers)라는 것을 사용한다.
❗️ 스레드 로컬 할당 버퍼(Thread-Local Allocation Buffers) :
- 각 Java 스레드별로 Eden 영역에서 미리 작은 덩어리(Buffer)를 가질 수 있도록 하는 것
new할 때 대부분 이 버퍼 안에서 빠르게bump-pointer할당만 해서 동기화 오버헤드를 없애는 구조- HotSpot의 메모리 할당 최적화 기법 중 하나
⛔️ 주의! ThreadLocal API 와 스레드 로컬 할당 버퍼(Thread-Local Allocation Buffers)는 서로 다른 개념이다!
여러가지 GC 방식
JDK 7 이상에서는 크게 7가지의 GC 방식이 있다.
- Serial GC
- Parallel GC
- Parallel Old GC(Parallel Compacting GC)
- Concurrent Mark Sweep GC(이하 CMS)
- G1(Garbage First) GC (Java 7)
- Shenandoah GC (Java 12)
- ZGC (Z Garbage Collector) (Java 15)
Stop-The-World(STW): GC을 실행하기 위해 JVM이 애플리케이션 실행을 멈추는 것
Serial GC (-XX:+UseSerialGC)
- 하나의 CPU 사용
- 운영서버에서 사용하면 절대 안된다. 성능이 아주 많이 떨어진다.
- Young 영역과 OId 영역이 serial하게(연속적으로) 처리된다. Thread 1개로 처리하기 때문에 가장 STW가 길다.
- Minor GC:
Mark-Sweep알고리즘을 사용 - Major GC:
Mark-Sweep-Compact알고리즘을 사용- Old 영역으로 이동된 객체들 중 살아 있는 객체를 식별(Mark)
- Old 영역의 객체들을 훑는 작업을 수행하여 쓰레기 객체를 식별(Sweep)
- 쓰레기 객체들을 지우고 살아 있는 객체들을 한 곳으로 모은다.(Compact)
Parallel GC (-XX:+UseParallelGC)
Java 8의 디폴트 GC- 스루풋 콜렉터(throughput collector)
- 다른 CPU 가 대기 상태로 남는 것 최소화
- Minor GC: 똑같이 Mark-Sweep 알고리즘,
멀티 쓰레드로 병렬(Parallel)로 처리- Serial GC 에 비해 STW 시간 감소
- Major GC: 똑같이 Mark-Sweep-Compact 알고리즘
Parallel Old GC(-XX:+UseParallelOldGC)
- Minor GC: 똑같이 Mark-Sweep 알고리즘, 멀티 쓰레드로 병렬(Parallel)로 처리
- Major GC:
Mark-Summary-Compact알고리즘,멀티 쓰레드로 병렬(Parallel)로 처리- 살아있는 객체를 식별하여 표시(Mark)
- 이전에 수행된 GC에서 컴팩션된 영역에 살아 있는 객체도 위치를 함께 조사(Summary)
- 컴팩션 단계, 컴팩션 된 영역과 비어있는 영역으로 나뉨(Compact)
Concurrent Mark Sweep(CMS) GC (-XX:+UseConcMarkSweepGC)
- 로우 레이턴시 콜렉터(low-latency collector)
- 어플리케이션의 쓰레드와 GC 쓰레드가 동시에 실행되어 STW 시간을 최대한 줄이기 위해 고안된 GC
- CMS GC는 Java9 버젼부터 deprecated 되었고 결국 Java14에서는 사용이 중지
- Minor GC: 똑같이 Mark-Sweep 알고리즘, 멀티 쓰레드로 병렬(Parallel)로 처리
- Major GC:
Mark-Concurrent Mark-Remark-Concurrent Sweep알고리즘- 아주 짧은 대기 시간으로 살아 있는 객체를 찾는 단계(Mark)
- 방금 살아있다고 확인한 객체에서 참조하고 있는 객체들을 따라가면서 확인, 다른 스레드가 실행 중인 상태에서 동시에 진행(Concurrent Mark)
- Concurrent Mark 에서 새로 추가되거나 참조가 끊긴 객체를 확인(Remark)
- 표시된 쓰레기 객체들을 정리(Sweep)
- 단점:
- 다른 GC 방식보다 메모리와 CPU를 더 많이 사용한다.
- Compaction 단계가 기본적으로 제공되지 않는다.
- 조각난 메모리가 많아 Compaction 과정을 수행할 경우 다른 GC 방식 보다 STW 시간이 더 길기 때문에, Compaction 작업을 얼마나 자주, 오랫동안 수행 되는지 확인 필요
Garbage First(G1) GC
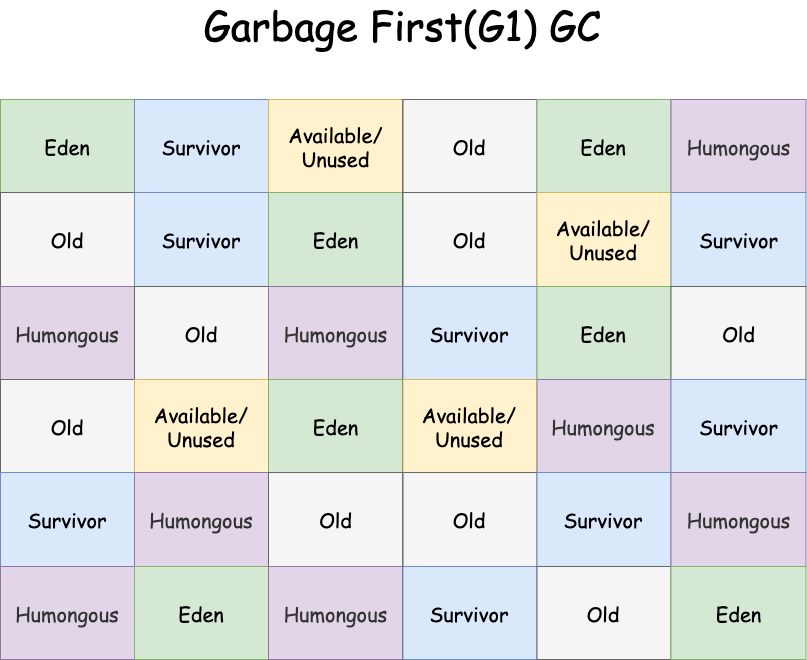
- 바둑판 모양
- 각 바둑판의 사각형을
Region으로 지정 - Young/Old 영역이 물리적으로 나뉘어 있지 않고, 각 구역의 크기는 모두 동일, 각 구역의 개수는 약 2000개
- 각 Region 이 동적으로 각각
Eden, Survivor, Old영역의 역할을 번경해가면서 수행 Humongous라는 영역도 포함
- 각 바둑판의 사각형을
Java 9+버전의 디폴트 GC로 지정- 메모리가 많이 차있는 영역(region)을 인식하는 기능을 통해 메모리가 많이 차있는 영역을 우선적으로 GC 한다.
- G1 GC는 Heap Memory 전체를 탐색하는 것이 아닌 영역(region)을 나눠 탐색하고 영역(region)별로 GC가 일어난다.
- Minor GC:
- 몇개의 구역을 Eden 영역으로 지정
- Eden 영역에 데이터가 꽉 차면, GC 수행
- GC 수행 후 살아있는 객체들을 이동.
- 살아남은 객체들이 이동한 영역이 동적으로 새로운 Survivor 영역으로 된다.
- 몇번의 GC 및 aging 작업 후, Old 영역으로 승격된다.
- Major GC:
- 초기 표시 단계 (STW): Old 영역에 있는 객체에서 Survivor 영역의 객체를 참조하고 있는 객체들을 표시한다.
- 기본 구역 스캔 단계: Old 영역 참조를 위해서 Survivor 영역을 훑는다. 참고로 이 작업은 Young GC 발생 이전에 수행된다.
- 컨커런트 표시 단계: 전체 힙 영역에 살아있는 객체를 찾는다. 만약 이때 Young GC 가 발생하면 잠시 멈춘다.
- 재표시 단계 (STW): 힙에 살이있는 객체들의 표시 작업을 완려한다. 이때 snapshot-at-the-beginning(SATB) 라는 알고리즘을 사용하며, 이는 CMS GC 에서 사용하는 방식보다 빠르다.
- 청소 단계 (STW): 살아 있는 객체와 비어있는 구역을 식별하고, 필요없는 객체들을 지운다. 그리고나서 비어있는 구역을 초기화 한다.
- 복사 단계 (STW): 살아있는 객체들을 비어있는 구역으로 모은다.
Shenandoah GC
Java 12에 release- 레드 햇에서 개발한 GC
- 기존 CMS가 가진 단편화, G1이 가진 pause의 이슈를 해결
- 강력한 Concurrency와 가벼운 GC 로직으로 heap 사이즈에 영향을 받지 않고 일정한 pause 시간이 소요가 특징
ZGC (Z Garbage Collector)
Java 15에 release- 대량의 메모리(8MB ~ 16TB)를 low-latency로 잘 처리하기 위해 디자인 된 GC
- G1의 Region 처럼, ZGC는 ZPage라는 영역을 사용하며, G1의 Region은 크기가 고정인데 비해, ZPage는 2mb 배수로 동적으로 운영됨. (큰 객체가 들어오면 2^ 로 영역을 구성해서 처리)
- ZGC가 내세우는 최대 장점 중 하나는 힙 크기가 증가하더도 'stop-the-world'의 시간이 절대 10ms를 넘지 않는다는 것
ZGC의 핵심 특징
- 동시성(Concurrency): 모든 주요 GC 작업(마킹, 재배치, 참조 업데이트)을 애플리케이션 실행과 동시에 수행한다.
- 규모 독립적 중지 시간(Pause Times): 힙 크기나 라이브 객체 수에 관계없이 일정한 중지 시간(기본적으로 <10ms)을 유지한다.
- 컬러드 포인터(Colored Pointers): 객체 참조의 몇 비트를 활용하여 GC 상태 정보를 저장한다.
- 로드 배리어(Load Barriers): 객체 참조 접근 시 참조의 유효성을 확인하고 필요하면 수정한다.
참고
- https://d2.naver.com/helloworld/1230
- https://d2.naver.com/helloworld/1329
- https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.4
- https://inpa.tistory.com/entry/JAVA-%E2%98%95-%EA%B0%80%EB%B9%84%EC%A7%80-%EC%BB%AC%EB%A0%89%EC%85%98GC-%EB%8F%99%EC%9E%91-%EC%9B%90%EB%A6%AC-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%F0%9F%92%AF-%EC%B4%9D%EC%A0%95%EB%A6%AC
- https://velog.io/@chae0738/%EC%A0%80%EC%A7%80%EC%97%B0-GC-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%EC%9D%84-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
- https://smileostrich.tistory.com/entry/Inside-Garbage-CollectionShenandoah-ZGC
