
-본인 공부 목적의 글입니다-
※ 본 글은 전반적인 CS를 공부하고 있는 비전공자의 글로써 지적은 언제나 환영입니다!
필자가 예비 개발자로서 알아야 할 것 같은 기본적인, 아니 기초적인 CS 내용을 한 번 더 간단하게 정리한 본인 공부 목적의 글이지만 이 글을 보고 있는 누군가에게 어떠한 방식으로든 도움이 됐으면 하는 마음으로 작성하였습니다.
※ inflearn의 홍정모 강사님의 따배씨 강의를 참고하였으며, 다른 서적과 구글링을 통해 따로 필자가 알아보기 쉽게 정리한 공부 목적의 글입니다.
※ 다크 모드가 아닌 라이트 모드로 읽어주시길 바랍니다.
🤔 자료구조와 알고리즘을 배우기 전, 컴퓨터의 전반적인 역사, 그리고 이와 관련된 하드웨어의 종류, 역할 등과 더불어 컴퓨터의 구조와 원리 등에 대해서 간단하게 알아보고자 한다.
📝 배우기 앞서
우선 본격적인 공부하기에 앞서, 당장 나의 전재산인 컴퓨터의 구성 요소부터 간단하게 알아보자.
참고 자료: 위키백과
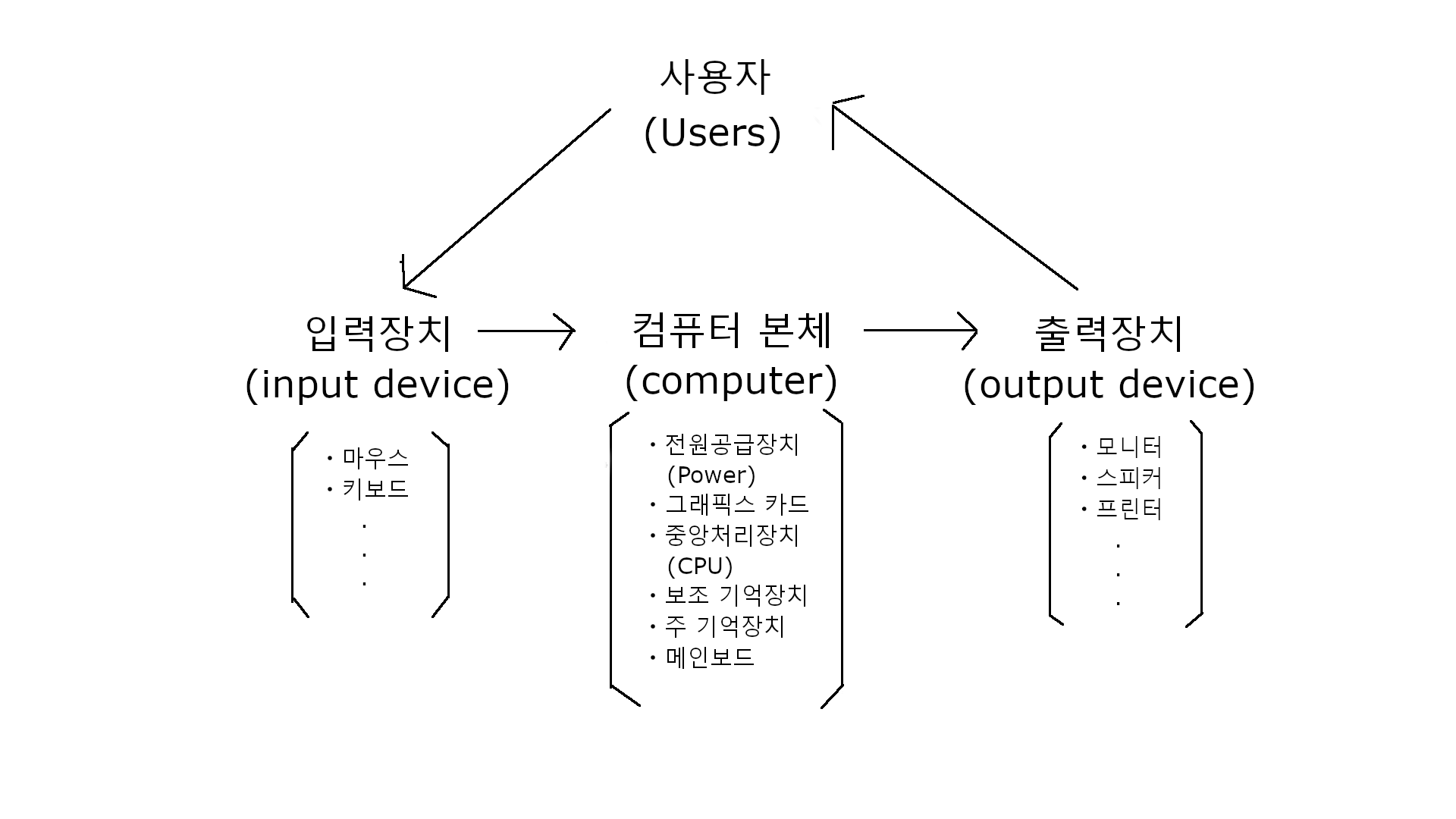 위 그림은 개구리라는
위 그림은 개구리라는 사용자가 쓰고 있는 컴퓨터의 본체 및 입출력 장치들을 간단하게 도식화 한 것이다. (현대로 와서는 입력장치와 출력장치 또한 다른 컴퓨터가 그 기능을 수행해줄 수도 있지만 지금은 간단하게 알아보기 위해 제외했다)
개구리가 현재 이 글을 쓰기 위해서 컴퓨터 본체의 전원공급장치와 연결된 전원버튼을 눌러서 출력장치인 모니터와 입력장치인 마우스를 통해 velog에 접속하여, 피시방에서 흔히 볼 수 있는 기계식 키보드라는 입력장치를 사용하여 이 글을 쓰고 있는 것이다. 여기서 컴퓨터 본체의 구성 요소들은 아래와 같다. (당장은 간단하게 알아보자!)
ㆍ중앙처리장치(Central Processing Uint): 컴퓨터의 두뇌 역할을 하는 실질적으로 모든 기능을 수행하는 요소이며, 예로는 intel과 AMD가 있다.
ㆍ주 기억장치(Primary Storage-Computer Memory): 중앙처리장치(CPU)와 함께 일해나가는 저장 공간을 담당하는 요소이며, 예로는 우리가 흔히 알고 있는 'RAM'이라고 불리는 메모리가 있다.
ㆍ그래픽스 카드(Graphics Card): 개구리 같은 겜돌이에게는 '그래픽 카드'라는 명칭이 더 익숙하나 공식 명칭은 그래픽스 카드이다. 말 그대로 그래픽 작업을 전문적으로 처리하는 요소이며, 예로는 NVIDIA의 Geforce GTX 1080 등이 있다.
ㆍ보조 기억장치(Secondary Storage): 개구리가 사용하고 있는 'Window'나 누군가 쓰고 있는 'mac', 'linux'와 같은 운영체제를 저장하고, 사용자가 원하는 프로그램 등을 저장하는 공간이다. '보조'라는 이름과 달리 너무 중요한 요소이며, 예로는 'HDD', 'SSD' 등이 있다.
ㆍ전원공급장치(Power Supply): 구동에 필요한 전력을 컴퓨터에게 공급해주는 전원 장치이다. 요즘들어 그래픽스 카드 등 컴퓨터의 구성 요소의 성능이 높아짐과 동시에 이에 따른 전원공급장치의 고려 또한 예전과 다르게 중요하게 되었다. (물론 그렇다고 예전엔 안 중요했다는 게 아니다)
ㆍ메인보드(Main Board): 컴퓨터 본체 내부에 위치한, 주회로가 내장된 보드이다. 부팅을 도와주는 BIOS라는 프로그램을 실행해 줄 자체 CPU를 가지고 있다.
여담으로 예전엔 FDD(Floppy Disk Drive)라는, 흔히 플로피 디스크라고 불리는 컴퓨터 보조 기억 장치를 사용했는데, 이 때 이를 구분하기 위한 용도로 a와 b를 사용했었다. 그래서 시간이 흘러 일반적으로 로컬디스크라고 불리는, 우리가 사용하는 디스크의 이름이 'Local diskc', 'Local diskD'로 명칭이 붙은 것이다!
그럼 이제 위 설명을 바탕으로 구성 요소들의 역할을 컴퓨터의 부팅절차를 통해 조금 더 자세히 알아보자.
참고 자료: 기억장치의 계층구조, 순차접근 / 임의접근 이미지, 포인터 짤
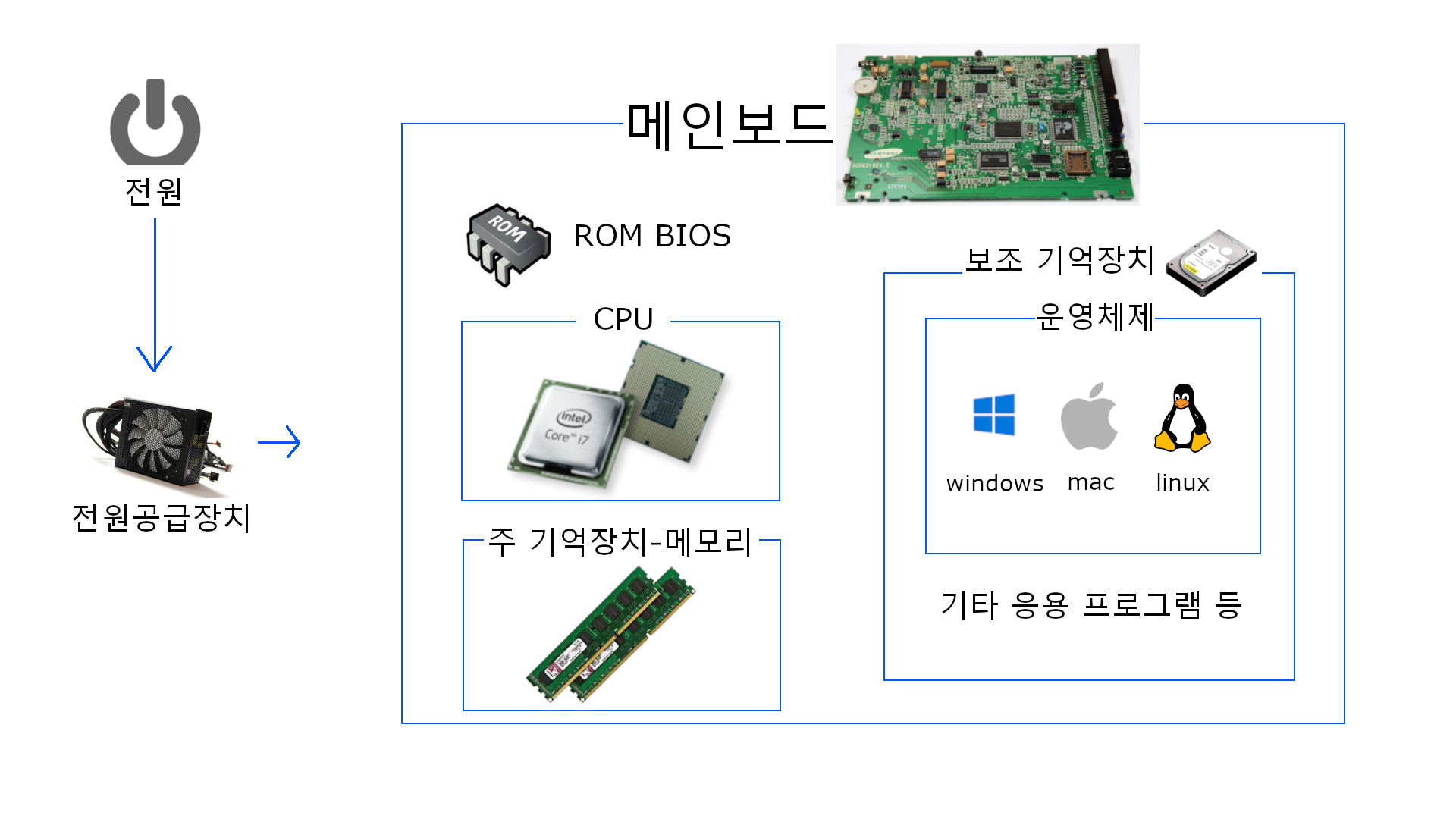 ① 개구리가 글을 쓰기 위해 컴퓨터의 전원을 켰다. 그럼 이 때,
① 개구리가 글을 쓰기 위해 컴퓨터의 전원을 켰다. 그럼 이 때, 전원공급장치를 통해 메인보드에 전력이 들어오게 된다.
② 메인보드에 장착된 CPU가 ROM(Read Only Memory)에 저장되어 있는 BIOS(Basic Input Output System)을 실행한다.
③ BIOS로 주변 하드웨어 장치들을 검사하는 POST(Power On Self Test) 과정을 거치고, 부팅할 보조 기억장치를 선택하고 내장된 부트로더(Boot Loader)를 실행한다.
④ 부트로더로 'Windows'라는 OS(Operating System)를 RAM(Random Access Memory)에 적재한다. (OS Loading)
⑤ 이 RAM을 가지고 CPU가 본격적으로 개구리라는 사용자의 명령에 따라 velog 사이트에 들어와서 글을 쓰고 있는 등의 일을 하게 되는 것이다.
위 과정은 상세한 부팅 절차를 아주 간략하게 축소시킨 것이다. 여기서 알아야 할 중요한 특징이 있다.
🔎 CPU는 보조 기억장치(ex. HDD, SSD 등)에 직접 접근하지 않고, 주 기억장치(ex. RAM, ROM 등)와 항상 가까이에서 일한다. 그 이유는 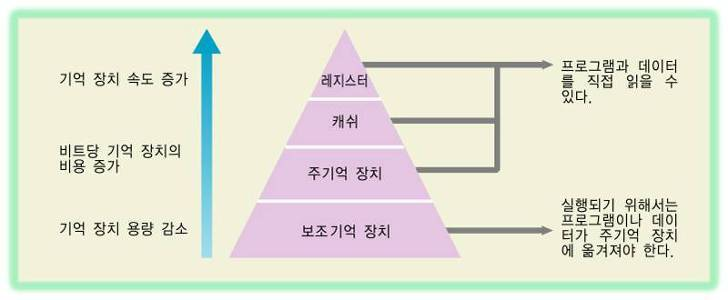 위 그림과 같이 기억 장치의 용량, 속도, 비용 때문이다. 이는 속도가 느리고, 용량이 큰 기억장치(==
위 그림과 같이 기억 장치의 용량, 속도, 비용 때문이다. 이는 속도가 느리고, 용량이 큰 기억장치(==보조 기억장치)의 내용 중에서 중앙처리장치(CPU)가 자주 사용하는 데이터를 속도가 빠른 기억장치(==주 기억장치)로 옮겨 놓고 사용함으로써, 전체적인 기억장치 엑세스 속도를 개선하기 위해서이다.
(캐시와 레지스터에 대해서는 뒤에서 더 자세히 알아보도록 하자)
🔎 주 기억장치는 ROM(Read Only Memory)과 RAM(Random Access Memory)으로 구성되어있다.
ROM은 내용을 읽을 순 있어도 바꿀 수는 없는 기억장치이며, 컴퓨터의 전원이 꺼져도 그 내용이 변함없이 유지가 된다는 특징을 지니고 있다. 주로 BIOS와 같이 한 번 설정해놓고 변경하지 않아도 되는 프로그램이 내제되어 있다.
RAM은 컴퓨터의 전원이 꺼짐과 동시에 저장된 데이터들이 모두 삭제되는 '휘발성'이라는 성질을 지니고 있으며, 보조 기억장치보다 용량은 적은 대신 속도는 훨씬 빠르다. 이름에서 알 수 있듯이 '임의 접근' 기억장치이다.
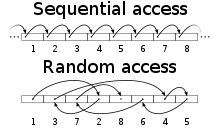
🔎 순차 접근(Sequential Access): 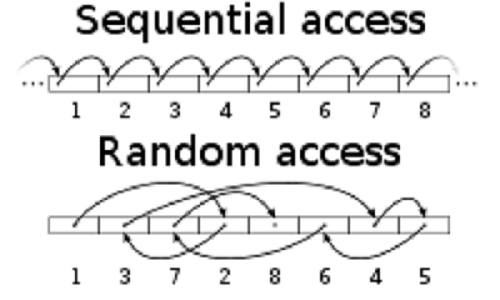 위 그림과 같이 일렬로 저장된 데이터를 차례대로 엑세스 하는 방식이다. 필요한 데이터가 저장된 위치에 따라 엑세스 시간이 달라진다.
위 그림과 같이 일렬로 저장된 데이터를 차례대로 엑세스 하는 방식이다. 필요한 데이터가 저장된 위치에 따라 엑세스 시간이 달라진다. 자기 테이프(Magnatic Tape)로 정보를 저장하던 시절, 주로 사용되었다. 속도가 느릴 것 같지만, 지금에 비해서 느린 것이지 그 때 당시엔 이런 방식이 인간이 하는 것보다는 훨씬 빨랐다.
임의 접근(Random Access): 주소에 의하여 데이터를 엑세스하는 방식이다. 그래서 어떤 데이터를 기억 장소에 기록하거나 거기에서 읽어 낼 때에, 기억 장소에 관계없이 동일한 시간이 걸린다. 그리고 각 기억장치의 위치마다 고유의 주소가 할당되어 있다. 그렇다, 절차지향 프로그래밍 언어 중 하나인 C언어를 배울 때 일반적으로 어렵다고 느끼는 그 포인터라는 개념을 이 때문에 배우는 것이다.
🔎 운영체제(Operating System): 여기에 적기엔 다른 것들보다 특히나 더 방대하고 양도 많지만, 간단하게 말하자면 사용자(혹은 소프트웨어 엔지니어)가 컴퓨터 하드웨어를 쉽게 사용할 수 있도록 인터페이스를 제공해주는 소프트웨어이다. 이 덕분에 현대의 프로그래머들의 피로는 많이 줄어들게 되었다. 만일 이 운영체제가 없었다면, 현대의 프로그래머들은 초기 프로그래머들처럼 프로그램을 만들 때마다 이 하드웨어를 어떻게 사용하는지, 이 하드웨어를 조작하는 프로그램을 전부 따로따로 만들어야 했을 것이다. (실제로 옛날엔 Plug Board 혹은 Punched Card와 같은 컴퓨터 외부의 프로그램에 직접 물리적 작업을 통해 입력하여 개발을 했었다)
대표적인 운영체제로는 UNIX Linux Windows Mac OS Android IOS 등이 있다. (모두 각각의 개성이 존재하지만, 핵심적인 기능은 서로 비슷하다)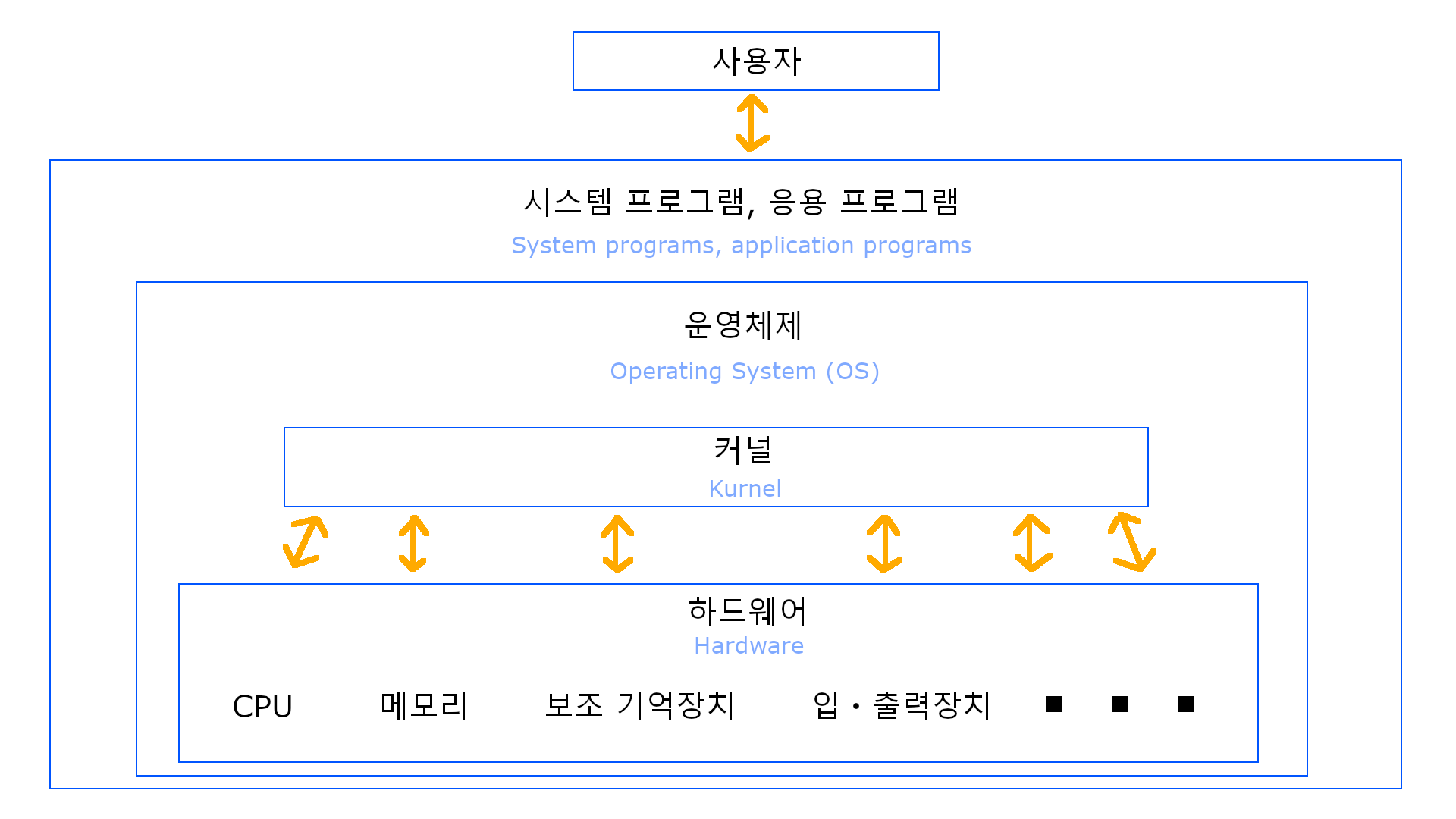 위 그림으로 예시를 하나 들자면, 개구리라는 사용자가 게임을 한다고 했을 때, 'Windows'라는
위 그림으로 예시를 하나 들자면, 개구리라는 사용자가 게임을 한다고 했을 때, 'Windows'라는 운영체제가 필자의 마우스와 키보드 및 스피커(헤드셋)라는 입출력장치와 라이엇 게임즈의 'Valorant'라는 응용 프로그램을 커널이라는 운영체제의 핵심 요소를 통해 원활하게 실행시켜 준다는 것이다.
또한, 개구리가 발로란트를 하는 도중에 로딩시간이 지루해서 Google이 서비스하는 동영상 공유 플랫폼인 'Youtube'를 틀어놓고 지인과 소통하기 위해 'KaKaoTalk'라는 프로그램을 켜놓을 수 있는 것도 마찬가지로 운영체제의 도움 덕분이다. 이 때, 그 응용프로그램들이 CPU나 메모리 같은 하드웨어의 자원(Resource)들을 누가 먼저, 얼마나 쓸 지에 대해 효율적으로 관리해주는 역할 또한 해준다.
📇 컴퓨터의 역사
현재 우리는 일상생활을 하면서 10을 기수로 하는 '십진법'을 사용하고 있다. 이유는 간단하다. 사람의 손가락이 10개이기 때문에 그렇게 정착된 것이다. 만약에 사람의 손가락 개수가 '리그오브레전드'라는 게임의 '잭스'라는 챔피언마냥 6개였다면 우린 6진수를 사용하는 육진법을 채택했을 것이다.🙄
하지만 코딩을 하는 사람이라면, 아니 컴퓨터에 대해 조금이라도 아는 사람은 컴퓨터는 10진수가 아닌 2진수를 택한 것을 알 수 있다. 그렇다면 왜 컴퓨터는 이진법을 채택하게 되었을까?
참고 자료: Samsung Semiconductor Newsroom, 위키백과, 진공관의 원리(네이버 블로그), 애니악 이미지, 트랜지스터 이미지
바로 세계 최초 컴퓨터인 애니악(ENIAC) 개발의 토대이기도 한 진공관 덕분이다. 이것에 대해 얘기하기 앞서 에디슨 효과에 대해 먼저 알아보자.
에디슨 효과(리처드슨 효과ㆍ열전자방출): 1883년 토마스 에디슨(Thomas Edison)이 백열전구 내부에 검은 그을음이 생기는 것에 대해 의문을 가지고 실험하던 중 전류가 전등의 필라멘트와 양전하로 입혀진 금속판 사이의 진공 속으로 흐른다는 것을 발견한 것을 의미한다.
(보다 자세한 원리는 아래의 유튜브 영상을 참고해주세요)
이러한 에디슨 효과를 1904년 영국의 전기공학자인 '존 엠브로즈 플레밍(John Ambrose Felming)'이 연구하고 응용하여 진공관을 발명하게 된다.
진공관: 진공 속에서 전자의 움직임을 제어함으로써 전기 신호를 증폭시키거나 교류를 직류로 정류하는 데 사용하는 전기 장비이다. 현대에서는 아직도 이 진공관의 높은 주파와 큰 전력을 사용하는 장비 또는 오디오 앰프 등에 일부 사용되고 있다.

위 영상에서 알 수 있듯이 이 진공관은 상측의 플레이트(양극)와 하측의 캐소드(음극)의 한 쌍으로 이루어져있다. 그리고 캐소드 바로 아래에 히터(필라멘트)라고 불리는 전열선이 있다.
히터에 전압을 걸어 전류를 흘려보내면 바로 옆의 음극판이 가열되어 음극에 존재하던 수많은 자유 전자들은 활발하게 움직이게 된다. 이 때, 같은 음극에 대해 양극에 플러스의 전압을 가하면, 음극 내의 전자가 양극의 플러스 전위에 이끌려 음극판에서 공간 중으로 날아올라 양극으로 끌려간다. 이렇게 하여 일정량의 전자가 음극에서 플레이트(양극)로 향하여 진공을 통해 날아가서 전자의 흐름이 이루어져 결국 플레이트에서 캐소드로 전류가 흐르게 되는 것이다. 전자와 전류는 방향이 반대이므로 양극에서 캐소드를 향해 전류가 흐른다고 하는 것이다. 이 때, 양극의 전압을 올리면 그 만큼의 많은 전자가 방출되어서 많은 전류가 흐르게 된다.
하지만, 만약 양극의 전위를 음극에 대해 마이너스로 한다면 음극의 전자는 양극에 반발하므로 공간 중으로 방출되지 못해 전류는 흐르지 않는다.
전류가 흐른다 == 켰다(1)
전류가 흐르지 않는다 == 껐다(0)
그렇다, 컴퓨터는 단순히 '전류가 흐른다(1)'와 '흐르지 않는다(0)'를 구분하는 것에서 시작되어 더 발전하여 산술ㆍ논리연산을 하게 되었고, 더 발전되어 그 두 가지의 경우를 가지고서 지금 현재 필자가 입력중인 '한글'이라는 인간의 언어를 이렇게 실시간으로 컴퓨터의 언어로 변환(Compile) 해주고 있는 것이다!

진공관의 발명 이후, 1946년 앞서 소개했던 ENIAC이라는 세계 최초의 컴퓨터가 발명되었다. 하지만 부피도 너무 컸을 뿐더러 사용 시 항상 고온 상태였던 진공관의 특성 때문에 이를 사용한 컴퓨터 역시 열에 의한 고장의 위험 또한 컸었다. 이를 보완하기 위해 등장한 것이 바로 트랜지스터이다.

트랜지스터: 1948년 미국 벨 연구소에서 근무하던 쇼클리, 바딘, 브래튼이 발명한 것으로 전지 전자회로에서 없어서는 안 될 매우 중요한 부품이다.
바로 이 트랜지스터 덕분에 작은 전기 신호로도 큰 전기 신호를 제어할 수 있게 되었고, 이를 기점으로 정보기술이 현저하게 빨라지게 되었다. 우리가 흔히 쓰고 있는 컴퓨터 내부에 있는 CPU가 바로 이런 트랜지스터들을 몇 천개, 아니 몇 십억개 혹은 더 넘어서까지 그 작은 부품 안에 들어가 있는 것이다.
이러한 과정을 거친 현대 컴퓨터의 기본 구조는 어떻게 이루어져있을까?
참고 자료: Plugboard 이미지, 위키백과, WIKIPEDIA


앞서 소개했지만 예전엔 프로그래밍이 지금처럼 고성능의 하드웨어와 더불어 다양한 프레임워크와 라이브러리가 제공되지도 않았기 때문에 프로그래머가 직접 Plugboard(맨 위 그림)라는 곳의 전기배선을 직접 바꾸거나 Punched Card(그 아래 그림)의 적정한 위치에 구멍을 뚫어가면서 코딩을 하는 어려움을 겪었어야 했다.
하지만 이 후, 폰 노이만 구조의 등장으로 프로그래밍 방식은 전과 확연히 달라지게 되었다.
폰 노이만 구조(내장형 프로그램 방식의 컴퓨터, Stored-program Computer): 에드박의 보고서 최초 초안에서 수학자이자 물리학자인 존 폰 노이만과 다른 사람들이 서술한 1945년 설명에 기반한 컴퓨터 아키텍쳐(== 설계도)이다.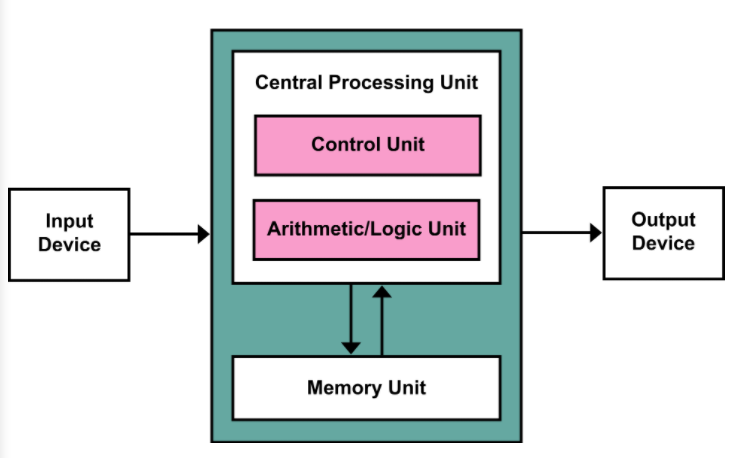
내장 메모리 순차 처리 방식으로서, 데이터 메모리와 프로그램 메모리가 구분되어 있지 않고 하나의 버스(Bus, Omnibus에서 기원)를 가지고 있는 구조를 말한다. 쉽게 말해 원래 프로그램은 외부에 존재했지만, 이 구조로 인하여 내부에 있게 되었다는 것이다. 후에 폰 노이만 구조가 발전하여 현대 컴퓨터는
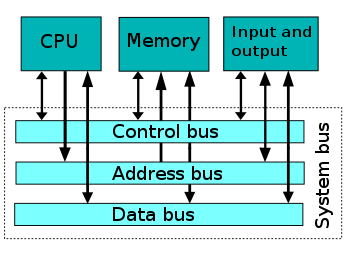 위와 같은 구조를 갖게 되었다. 이로 인해 CPU와 Memory는 더 이상 직접 움직이는 것이 아닌, System bus를 통해 움직이게 된다.
위와 같은 구조를 갖게 되었다. 이로 인해 CPU와 Memory는 더 이상 직접 움직이는 것이 아닌, System bus를 통해 움직이게 된다.System bus는 컴퓨터의 구성요소를 서로 연결하고 데이터 전달을 위한 경로이며 Control bus, Address bus, Data bus로 구성되어 있다. 자세한 내용은 아래에서 더 알아보자.
🎯 CPU와 Memory
사실 여태 알아본 내용들은 전부 이 CPU와 Memory를 알기 위해서 필요했던 일종의 빌드업이었다. 프로그래머로서, 아니 예비 프로그래머로서 꼭 알아야 할 컴퓨터의 CPU 및 Memory의 구조와 작동 원리를 알아보자!
참고 자료: CPU와 메모리 이미지, DRAM 저장 유닛 구조도
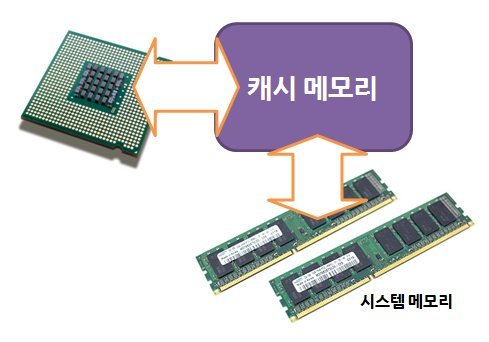
CPU와 Memory는 함께 일을 해나간다. 연산은 CPU에서, 정보 저장은 Memory에서 한다. 근데 여기 캐시 메모리라는 것은 뭘까? Memory에 대해 알아보기 전에 이에 대해 간단히 알아보자.
메모리에서 정보를 CPU에 보낼 때, 똑같은 데이터 혹은 프로그램과 같이 자주 보내는 것들을 매번 새롭게 보낸다면 그 자체로 성능이 저하될 것이다. 하지만 이 캐시 메모리 덕분에 그러한 일을 방지해준다. 이 요소는 앞서 말한 자주 쓰이는 데이터(프로그램)를 따로 저장해놨다가 CPU가 같은 일을 처리할 때 메모리에서 또 이를 보내는 것이 아닌 캐시 메모리에서 이를 대신 보냄으로써 연산 속도를 더 빨라지게 도와주는 역할을 해주는 것이다. 이쯤에서 각설하고 Memory에 대해 알아보자.
요즘 들어 Memory를 이야기 할 때, 흔히들 RAM(Random Access Memory)으로 얘기한다. 이 때, 여기서 눈여겨봐야할 것은 임의 접근(Random Access)이다.
시스템이 파일에 접근하는 방식은 크게 순차 접근(Sequential Access)과 임의 접근(Random Access), 직접 접근(Direct Access)으로 나뉘는데, 여기 예시를 보면 📝 배우기 앞서 에서 설명했었던 순차 접근과 임의 접근에 대한 이해가 곧바로 이해가 될 것이다.
ex. 1) 개구리가 집에서 리모컨을 찾고 싶은데, 리모컨이 거실에 있는지 주방에 있는지, 화장실에 있는지 등 잘 모르기 때문에 모든 장소들을 하나하나 순차적으로 다 뒤져보는 것 => 순차 접근
(물론, 순차 접근 시엔 단순히 모든 방을 뒤져보기 보다는 현관과 가장 가까운 방부터 먼 방 '순서대로' 뒤져본다는 의미)
ex. 2) 개구리가 집에서 리모컨을 찾고 싶은데, 가족 구성원 중 한 명이 "어 그거 주방 식탁 아래에 있던데?" 라고 알려줘서 굳이 모든 방을 다 뒤져보지 않고 주방에서 찾아내는 것 => 임의 접근
이를 통해 우리는 임의 접근이 굉장이 효율적임을 알 수 있다.
다음으로 메모리의 구조 또한 알아보자.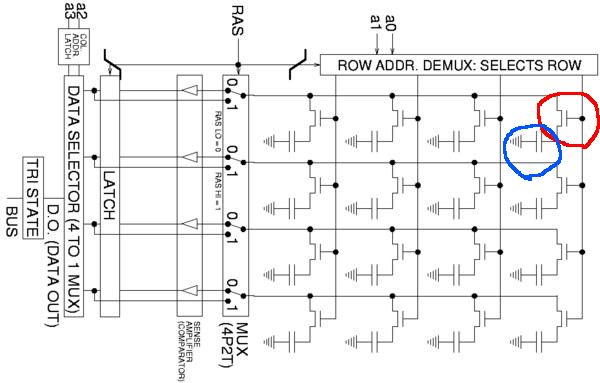 위 그림으로 알아볼 것은 딱 하나이다. 더 자세한 내용은 생략하고
위 그림으로 알아볼 것은 딱 하나이다. 더 자세한 내용은 생략하고 트랜지스터(Transistor)와 커패시터(Capacitor)로 하나의 Cell(==방)이 이루어지고, 이 Cell은 0이냐 1이냐인 하나의 비트(Binary digit)를 가진다는 것만 꼭 기억해두자. (*비트는 메모리의 가장 작은 단위이다)
# 커패시터를 나타내는 파란색 원에 삼각형 모양으로 이루어진 부분은 일종의 전기의 기준점인 그라운드(Ground)인데, 여기선 간단하게 그라운드가 흐르던 전류를 사라지게 하는 역할을 한다고 보면 된다.
이제 이러한 RAM이 CPU와 어떻게 일을 하는지 알아보자. 앞서 임의접근에 대해 알아봤었는데, 바로 그 임의접근을 위해 현대의 메인보드는 위 그림과 같이 주소가 오가는 통로와 데이터가 오가는 통로가 분리되어 있도록 설계되어 있음을 볼 수 있다. 그렇다면 이제 RAM socket에 RAM이 장착되어있다는 가정하에 그 과정을 알아보자.
앞서 임의접근에 대해 알아봤었는데, 바로 그 임의접근을 위해 현대의 메인보드는 위 그림과 같이 주소가 오가는 통로와 데이터가 오가는 통로가 분리되어 있도록 설계되어 있음을 볼 수 있다. 그렇다면 이제 RAM socket에 RAM이 장착되어있다는 가정하에 그 과정을 알아보자.
(더 자세한 내용이 궁금하다면 [YouTube] "How a CPU Works" 를 참고해주세요)
① address bus를 통해 어느 주소에 있는
② 데이터를 control bus를 통해 RAM으로부터 받을 것인지 RAM에 보낼 것인지를 제어한 후
③ data bus를 통해 데이터를 받는(보내는) 것이다.
그리고 복습 차원에서 말하지만, 위 과정을 통해 RAM의 기능은 딱 두 가지 뿐임을 알 수 있다.
⑴ CPU에게 데이터를 보내주는 것
⑵ CPU로부터 데이터를 받아서 저장하는 것
추가적으로, 그 address bus 때문에 포인터라는 개념이 있는 것이다. 대표적으로 C언어라는 절차지향 프로그래밍 언어가 포인터를 사용한다는 것은 다들 알지만, Java와 같은 특정 객체지향 프로그래밍 언어에서는 이를 듣도 보지도 못했으니 간혹 어떤 이들은 포인터가 없는 줄 안다. (필자가 그랬다) 하지만 그 언어가 포인터를 숨겨놨을 뿐, 아예 포인터가 존재하지 않는 것이 아니다. (프로그래머가 data bus를 통해 보내는/받는 데이터만 신경쓸 수 있도록 숨겨놓은 것이다)
위 내용을 숙지한 뒤, 아래에서 구체적인 예시와 더불어 더 자세하게 알아보자.
프로그램이 시작되는 과정을 간단하게 알아보고 CPU의 기본 구조와 구성 요소들을 알아보자.
참고 자료: 위키백과, CPU 명령어 구성, CPU 명령어 설명, [YouTube] CPU 동작원리 - 코딩애플)
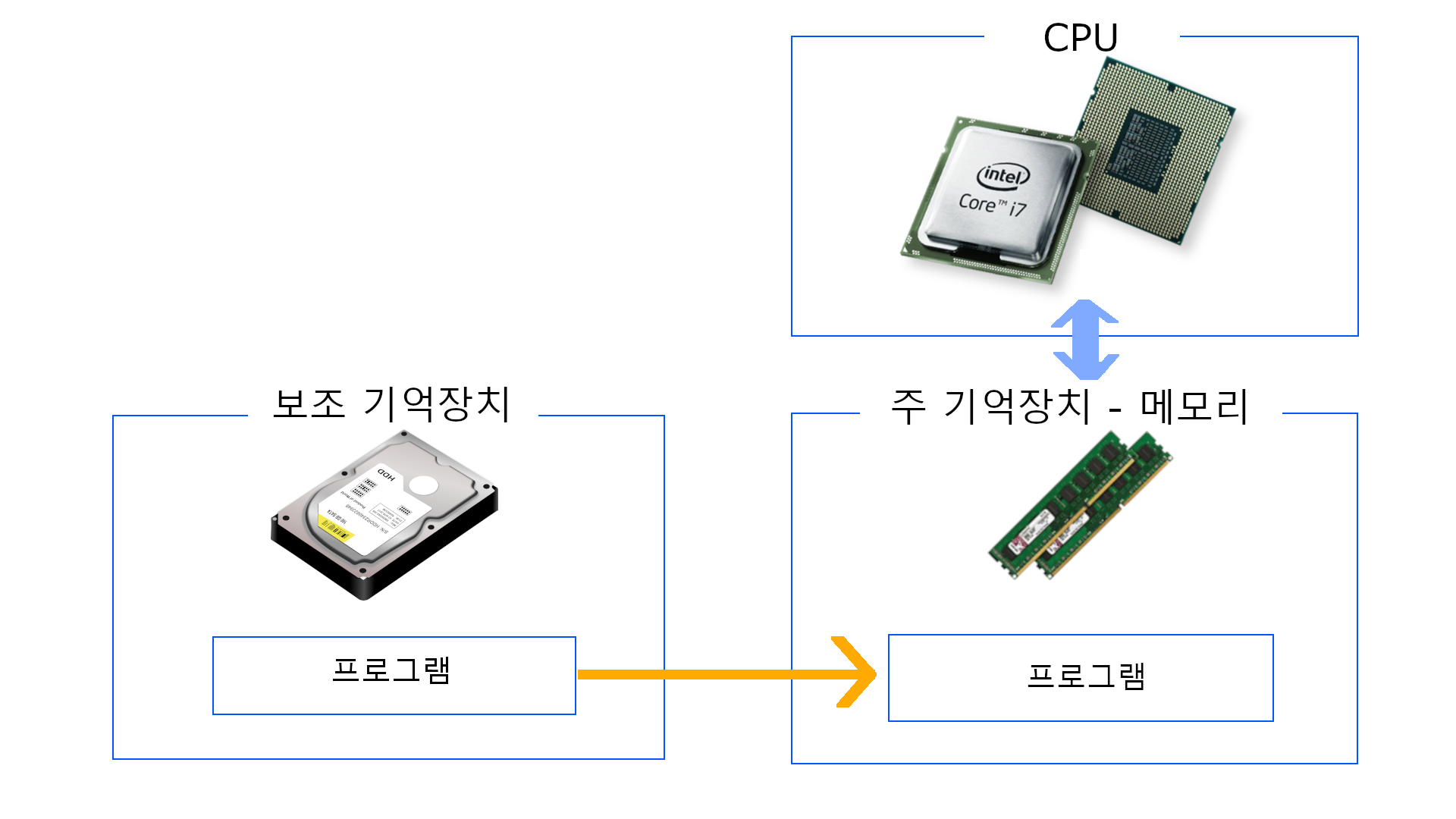 ① 우리가 만든
① 우리가 만든 프로그램은 보조 기억장치에 먼저 저장이 되고
② 이 프로그램을 실행시키기 위해서 내부적으로 운영체제에게 부탁해서 바로 CPU가 아닌 주 기억장치 메모리로 복사해서 옮기고 ( 보조 기억장치가 CPU와 일하지 않는 이유 )
③ CPU가 그제서야 주 기억장치와 통신하며 프로그램을 실행하게 되는 것이다
앞서 설명했던 운영체제가 실행되는 과정과 동일하게 프로그램 또한 실행된다는 점을 알 수 있다.
여기서 더 나아가서 CPU의 언어와 구성요소에 대해서 알아보자.
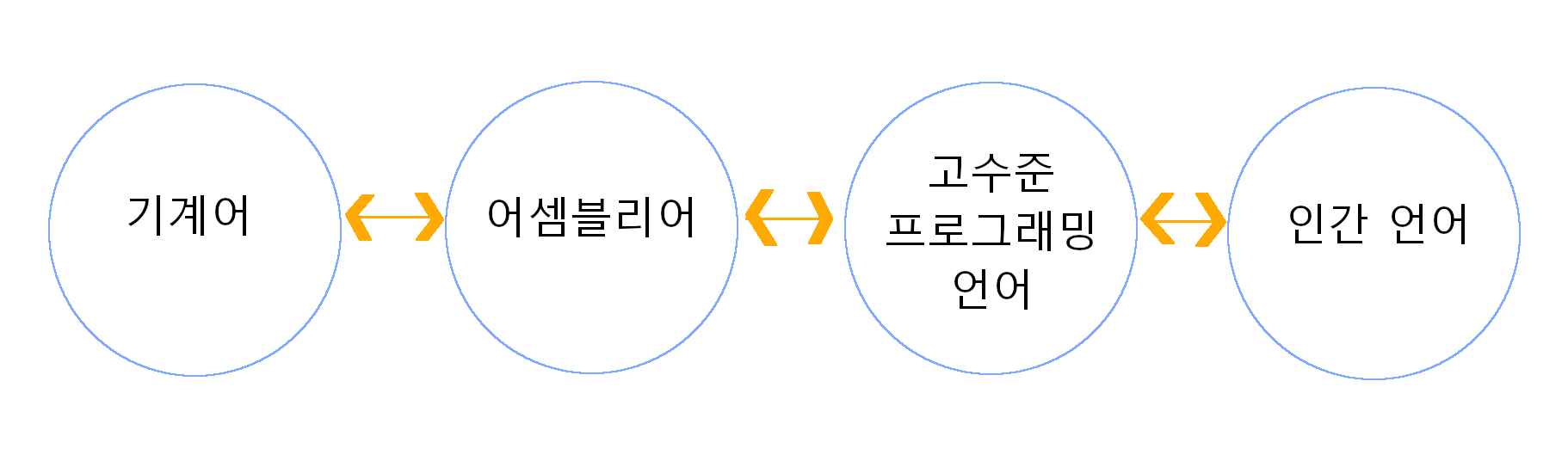
기계어(Machine Code, Machine Language): CPU가 직접 해독하고 실행할 수 있는 비트 단위로 쓰인 컴퓨터 언어로 컴퓨터가 이해할 수 있는 유일한 언어이다.
(ex. 1001, 01011100, 0010110010110010)
어셈블리 언어(Assembly Language): 기계어와 일대일 대응이 되는 컴퓨터 프로그래밍의 저급 언어로 컴퓨터 프로세서를 다루기 위한 가장 기본적인 언어이다. 기계어로 되어있는 언어를 인간이 인식할 수 있는 것으로 바꾸어 주는 '니모닉'이라는 과정을 거친다.
(ex. LOAD X, ADD Y, STORE Z)
고수준 프로그래밍 언어(High-level Programming Language): 사람이 이해하기 쉽게 작성된 프로그래밍 언어로서, 저급 프로그래밍 언어보다 가독성이 높고 다루기 간단하다.
(ex. A = 1, B = 2, C = A + B)
# CPU의 언어는 기계어라는 것 외에 다른 언어들에 대한 설명을 적어놓은 것은 아래의 CPU 명령어 처리 과정에서의 이해를 위해 기술하였습니다.
아래는 CPU의 구성요소이다.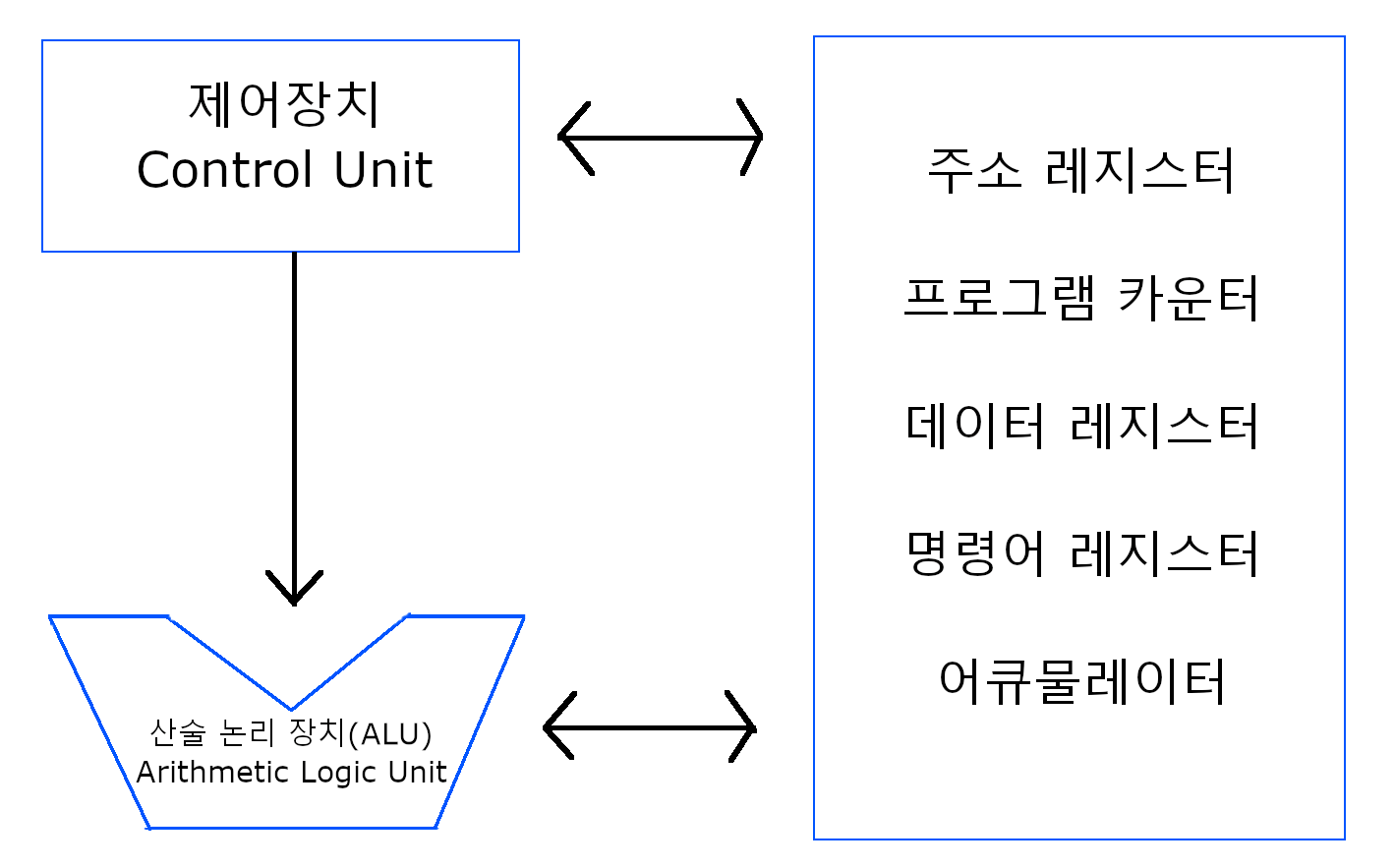
제어 장치: 프로세서의 조작을 지시하는 역할을 해준다
산술 논리 장치: 우리가 생각하는 연산 작업을 하고 논리를 따지는 부분, 즉 계산을 하는 역할을 해준다
레지스터: CPU가 요청을 처리하는 데 필요한 데이터를 일시적으로 저장하는 기억장치를 말한다.
여기서 레지스터의 구성요소는 다음과 같다.
ㆍ주소 레지스터: 주소 버스에 주소를 출력하기 전에 임시 저장하는 레지스터
ㆍ프로그램 카운터: 다음 인출할 명령어 주소를 임시 저장하는 레지스터
ㆍ데이터 레지스터: 데이터 버스에 데이터를 읽고 쓰기 위해 잠시 저장해두는 버퍼 레지스터
ㆍ명령어 레지스터: 가장 최근에 인출된 명령어를 임시 저장하는 레지스터
ㆍ어큐물레이터: 중간 산술 논리 장치 결과를 임시 저장하는 레지스터
여기서 의문이 생긴다.
"어? 근데 말이 레지스터지 그냥 메모리랑 같은 저장공간 아닌가? 그럼 CPU 내부에 있는 레지스터들은 메모리와 같은 거 아닌가?"
결론부터 말하자면, 저장 공간이라는 기능을 수행한다는 점에선 같지만, 레지스터와 메모리는 같지 않다. 레지스터는 단지 '휘발성'으로 데이터를 저장하는 공간이며, CPU가 이러한 레지스터를 갖게 된 이유는 바로 버스때문이다. ( 버스란? )
CPU가 메모리에 접근할 때 버스를 통해 접근을 하기 때문에 이동 시간이 별도로 발생하게 된다. 이는 곧 연산 속도를 늦추어서 컴퓨터의 성능 저하를 초래하므로, 이동할 필요가 없는 CPU만의 전용 저장 공간을 만들어서 CPU랑 가까이 두게 된 것이다. 그리고 바로 그것이 레지스터이다.
이러한 CPU가 기본적으로 수행하는 명령은 그렇게 많지 않다. 하지만 숫자를 더하고, 비교하고 저장하고 받아오는 등의 기본적인 작업들을 조합해서 복잡한 기능을 수행할 수 있는 것이다. 앞서 얘기했듯이 CPU는 수많은 트랜지스터의 조합으로 이루어져있다. 그럼 이와 관련하여 실제 CPU가, 아니 정확히는 ALU가 트랜지스터로 어떻게 논리연산을 하는지에 대해 자세히 알아보기 앞서 기본적인 예시로
앞서 얘기했듯이 CPU는 수많은 트랜지스터의 조합으로 이루어져있다. 그럼 이와 관련하여 실제 CPU가, 아니 정확히는 ALU가 트랜지스터로 어떻게 논리연산을 하는지에 대해 자세히 알아보기 앞서 기본적인 예시로 NOT과 AND, OR 그리고 XOR 에 대해 알아보자.
(ALU는 실제 회로로 구성되어있는데, 이를 논리회로(Logic Gate) 라고 하며 위 예시들은 각각 NOT Gate, AND Gate, OR Gate, XOR Gate 라고 불린다)
# 이를 얘기하기 앞서, 진공관의 원리를 안다면 이해하기 수월해집니다. 이에 대해서 기억이 안 나시는 분은 여기 를 참고해주세요. 편의상 거짓(0), 참(1) 이란 표현은 여기서 이 한 줄로 대체하고 넘어가겠습니다.
1. NOT Gate (숫자를 넣으면 반대로 출력해주는 부품)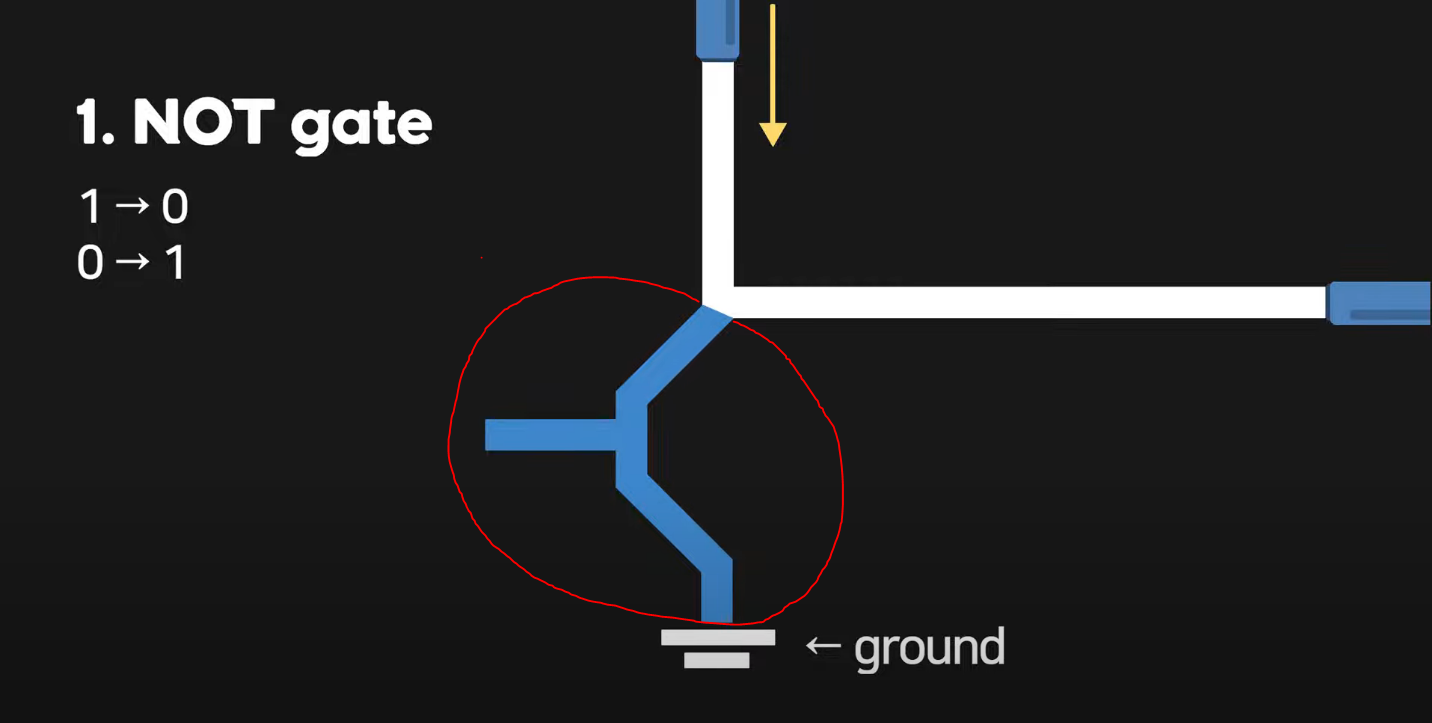 노란색 방향으로 전류가 흐르는 전선이 있다고 가정했을 때, 이 위에 위와 같이 빨간색으로 표시된 곳에 트랜지스터를 놓으면 NOT Gate 완성이다. 작동원리는 트랜지스터에 0을 넣었을 때(== 전류를 차단했을 때), 1이라는 값이 출력된다. 반대로 1이라는 값을 넣었을 때(== 전류를 흘려보낼 때), 전류는 트랜지스터를 통과하여 그라운드(Ground)를 만나 사라지며 동시에 0이라는 값이 출력된다.
노란색 방향으로 전류가 흐르는 전선이 있다고 가정했을 때, 이 위에 위와 같이 빨간색으로 표시된 곳에 트랜지스터를 놓으면 NOT Gate 완성이다. 작동원리는 트랜지스터에 0을 넣었을 때(== 전류를 차단했을 때), 1이라는 값이 출력된다. 반대로 1이라는 값을 넣었을 때(== 전류를 흘려보낼 때), 전류는 트랜지스터를 통과하여 그라운드(Ground)를 만나 사라지며 동시에 0이라는 값이 출력된다.
정리하자면,
[입력] 1 -> 0 [출력]
[입력] 0 -> 1 [출력]
2. AND Gate (숫자 2개가 1일 때만 1을 출력해주는 부품)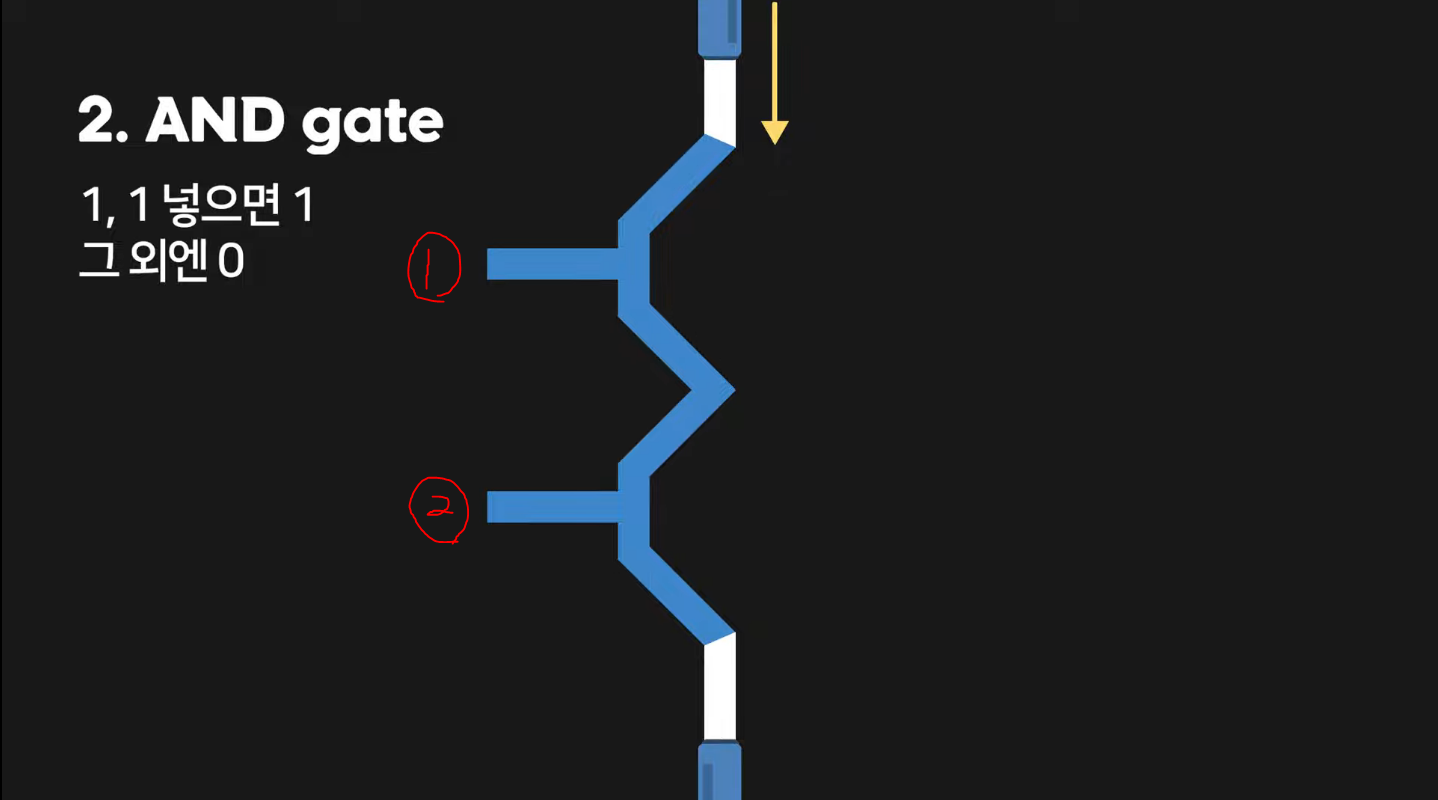
①과 ②인 두 개의 트랜지스터가 있다. 이 때, ①에 0의 값(== 전류 차단)을 주고 ②에 1의 값(== 전류 흐름)을 준다면 전류는 ①에서 막혀서 결국 목표 지점까지 도달하지 못하게 되어 0의 값을 출력하게 된다. 반대는 이와 동일하므로 생략하고, 만약 둘 다 0의 값을 준다면 이 또한 0의 값을 출력할 것이다. 하지만 둘 다 1의 값을 준다면, 전류는 위 그림의 하단에 해당하는 지점까지 정상적으로 전류가 흘러 1의 값을 출력해주게 된다.
정리하자면,
[입력] 0, 0 -> 0 [출력]
[입력] 1, 0 -> 0 [출력]
[입력] 0, 1 -> 0 [출력]
[입력] 1, 1 -> 1 [출력]
3. OR Gate (숫자 2개 중 하나라도 1일 때 1을 출력해주는 부품)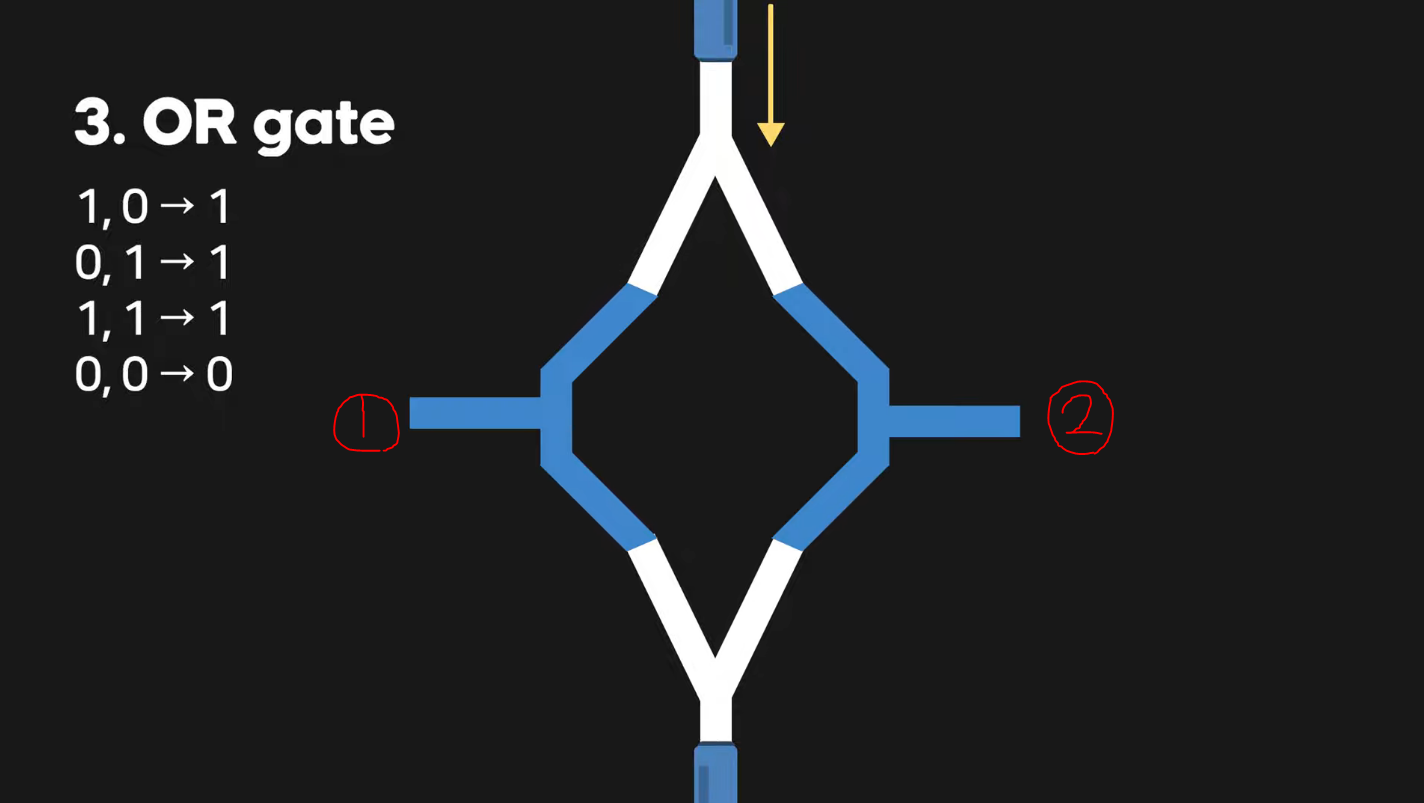 이번에는 트랜지스터를 병렬로 연결하여 부품을 완성하였다. 이 때, ①과 ② 둘 중에 하나라도 1(== 전류 흐름)의 값이면 위 그림의 하단에 해당하는 지점까지 전류가 흘러 1의 값을 출력해주게 된다.
이번에는 트랜지스터를 병렬로 연결하여 부품을 완성하였다. 이 때, ①과 ② 둘 중에 하나라도 1(== 전류 흐름)의 값이면 위 그림의 하단에 해당하는 지점까지 전류가 흘러 1의 값을 출력해주게 된다.
정리하자면,
[입력] 0, 0 -> 0 [출력]
[입력] 1, 0 -> 1 [출력]
[입력] 0, 1 -> 1 [출력]
[입력] 1, 1 -> 1 [출력]
4. XOR Gate (숫자 2개가 서로 다를 때 1을 출력해주는 부품)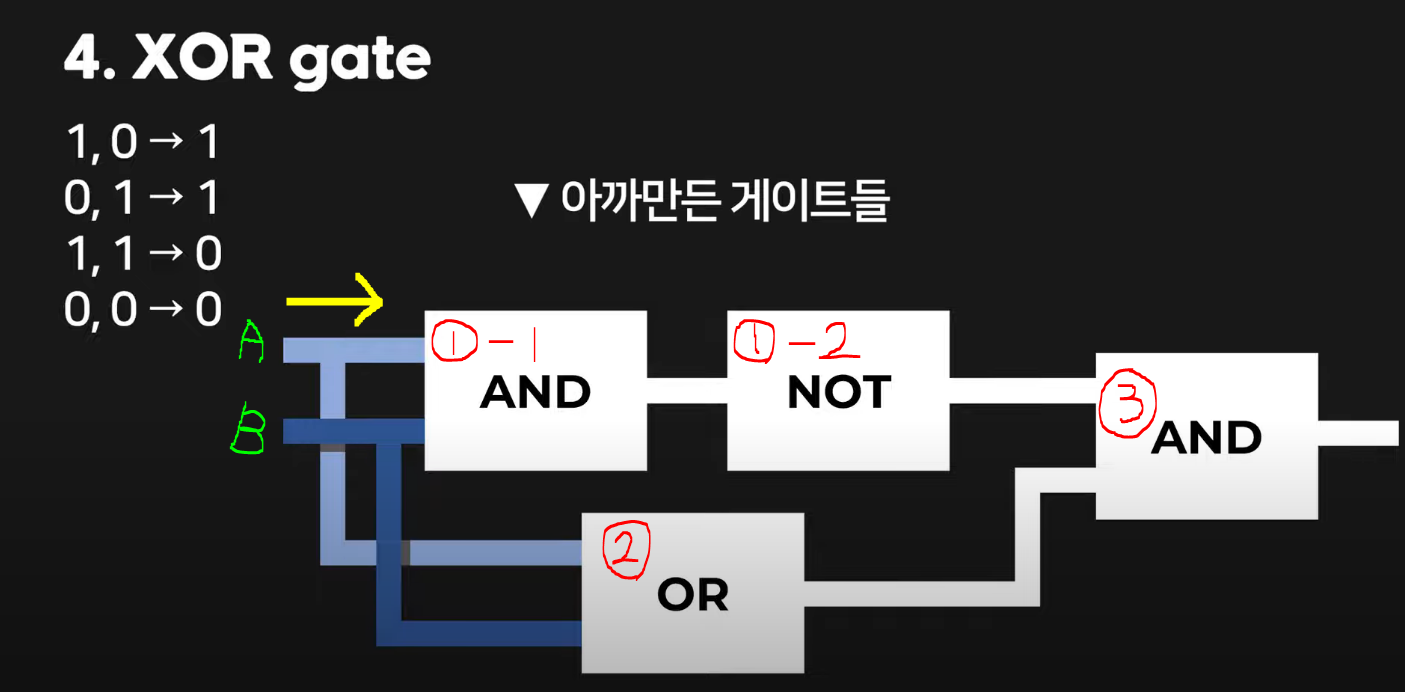 왼쪽이 input(== 입력) 오른쪽이 output(== 출력)이고, 왼쪽에 A라는 전선과 B라는 전선이 있다. 여기서 만약 A에 0을 넣고 B에 0을 넣는다면? 당연히 전류가 흐르지 않음으로 최종적으로 출력 값은 0이 될 것이다. 그럼 A에 1, B에 1을 넣는다면, ①-1에서 1이라는 값이 나오고 이는 ①-2를 통해 0이라는 값이 나오게 된다. 이 때, ②에서는 1의 값이 나오니 최종적으로 1과 0이란 값이 ③을 통해 0이란 값이 나오게 된다. 같은 원리로 A에 1, B에 0을 넣어보자. 그럼 ①-1에서 0이란 값이 나오고 이는 ①-2를 통해 1이라는 값이 나오게 된다. 이 때, ②에서는 1의 값이 나오니 최종적으로 1과 1이라는 값이 ③을 통해 1의 값을 출력하게 되는 것이다. A에 0, B에 1을 넣는 경우 또한 이와 동일한 과정이니 생략하겠다.
왼쪽이 input(== 입력) 오른쪽이 output(== 출력)이고, 왼쪽에 A라는 전선과 B라는 전선이 있다. 여기서 만약 A에 0을 넣고 B에 0을 넣는다면? 당연히 전류가 흐르지 않음으로 최종적으로 출력 값은 0이 될 것이다. 그럼 A에 1, B에 1을 넣는다면, ①-1에서 1이라는 값이 나오고 이는 ①-2를 통해 0이라는 값이 나오게 된다. 이 때, ②에서는 1의 값이 나오니 최종적으로 1과 0이란 값이 ③을 통해 0이란 값이 나오게 된다. 같은 원리로 A에 1, B에 0을 넣어보자. 그럼 ①-1에서 0이란 값이 나오고 이는 ①-2를 통해 1이라는 값이 나오게 된다. 이 때, ②에서는 1의 값이 나오니 최종적으로 1과 1이라는 값이 ③을 통해 1의 값을 출력하게 되는 것이다. A에 0, B에 1을 넣는 경우 또한 이와 동일한 과정이니 생략하겠다.
정리하자면,
[입력] 0, 0 -> 0 [출력]
[입력] 1, 0 -> 1 [출력]
[입력] 0, 1 -> 1 [출력]
[입력] 1, 1 -> 0 [출력]
위의 설명을 통해 연산이 이루어지는 기본 원리도 알았으니, 이제 이 글을 쓰게 된 가장 중요한 이유이자 이 글의 핵심인 CPU가 어떻게 일하는지에 대해 예시를 통해 알아보자.
참고 자료: CPU 명령어 처리 과정, 따배씨 녹화 강의 中 캡쳐본 (문제 시 삭제)
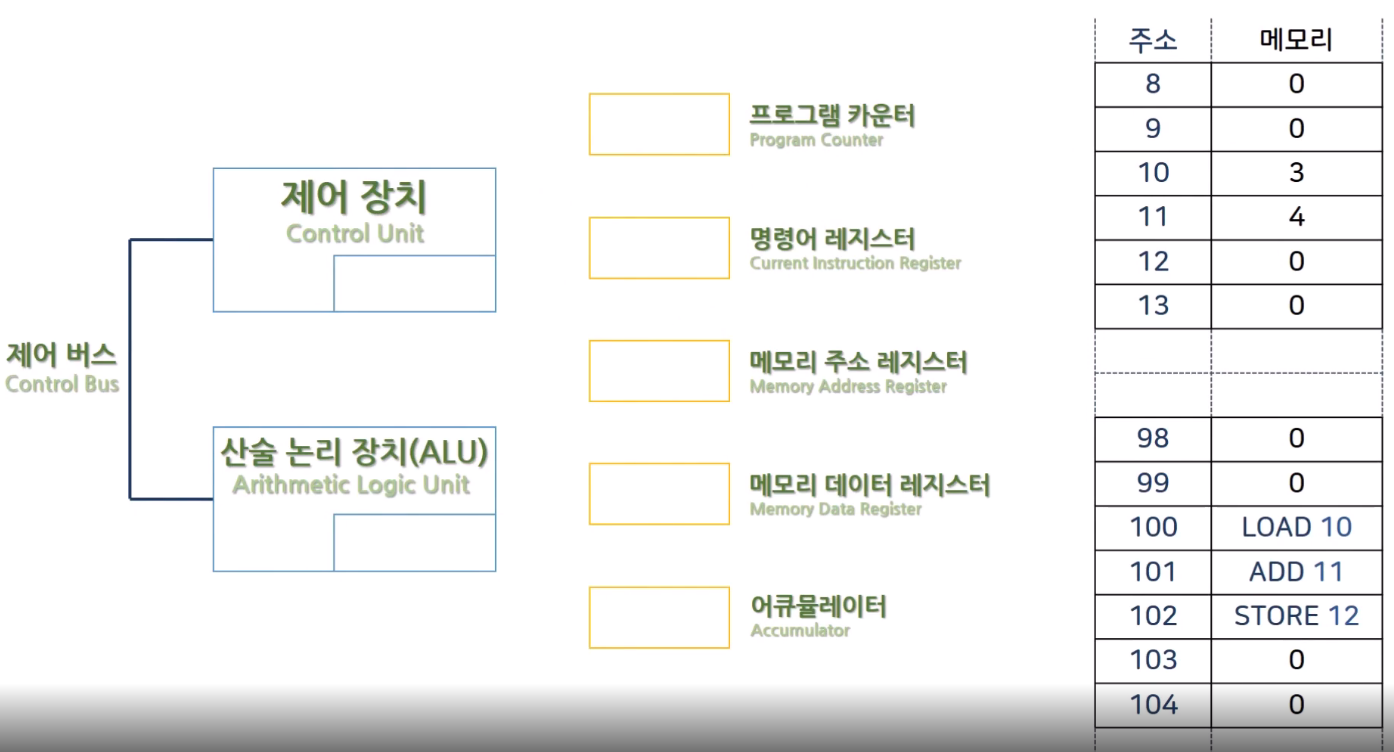 # LOAD 10, ADD 11과 같은 형태를 처음보신다면, 어셈블리어란? 을 참고해주세요.
# LOAD 10, ADD 11과 같은 형태를 처음보신다면, 어셈블리어란? 을 참고해주세요.
# 실제로 모든 메모리에 0이 들어가 있는 것은 아닙니다. (운영체제나 하드웨어의 특성에 따라 다름)
# 주소도 편의상 내림차순으로 정리하였으며, 레지스터들의 위치도 편의상 위와 같이 구성하였습니다.
# 위 그림은 현재 특정 프로그램을 실행시켜 100번과 101번, 그리고 102번 주소에 보조 기억장치에서 받아온 각각의 프로그램들이 메모리에 올라온 것입니다. 또한 10번과 11번 주소에는 각각 3과 4라는 데이터가 할당되어 있는 상황입니다. (위에서 설명했듯이, 이 과정을 도와준 건 모두 운영체제 덕분입니다)
# 아래에 나와있는 과정은 모두 CPU의 제어장치(Control Unit)가 총괄합니다. 따라서 암묵적으로 처리되는 과정은 생략되었을 수 있습니다.
# 설명이 길어서 헷갈릴 수 있으므로 주소에 해당하는 숫자는 강조 처리해놨습니다..
CPU가 이 프로그램을 처리하는 과정은 아래 Ⅰ~Ⅲ과 같다.
Ⅰ. LOAD 10 처리
① CPU가 실행을 시켜야 할 다음 번(이 경우엔 최초) 명령어의 주소를 가리키는 프로그램 카운터라는 레지스터에 100이란 값을 넣는다.
② 메모리 주소 레지스터에 100이란 값이 옮겨진다.
③ 그 100이란 주소에 접근을 하여 LOAD 10을 가져와서 메모리 데이터 레지스터에 집어넣는다.
④ LOAD 10은 명령어이므로 명령어 레지스터에 옮겨진다.
⑤ 이 때, 프로그램 카운터에 100이란 값에서 하나 올라간 101이란 값이 들어간다.
(프로그램 카운터는 항상 다음 번에 읽어올 메모리 주소, 즉 다음 번에 읽어와야 하는 명령어가 존재하는 메모리 주소를 가지고 있어야 하기 때문)
⑥ 명령어 레지스터에 있는 명령어가 제어 장치로 들어간다. 이 때, 제어 장치는 이 명령어를 Decode(해독) 한다.
⑦ 이에 CPU는 LOAD 10을 수행하기 위해 메모리 주소 레지스터에 10이라는 주소를 넣어준다.
⑧ 그로 인해 10번 주소에 해당하는 3이라는 데이터를 메모리 데이터 레지스터에 가져온다.
⑨ 이 때, LOAD 10을 해독한 CPU가 3이라는 데이터가 연산에 쓰일 것임을 알고, 이 값을 산술 논리 장치(ALU)에서 계산을 할 때를 대비해 어큐물레이터로 옮긴다. 이로써 LOAD 10이란 명령어는 끝이 난다.
Ⅱ. ADD 11 처리
① 이미 프로그램 카운터에 들어와 있는 101이란 값을 메모리 주소 레지스터에 옮긴다.
② 101이란 주소에 접근하여 ADD 11이란 명령어를 메모리 데이터 레지스터로 가져온다.
③ 이는 명령어이므로 Ⅰ-④와 같이 명령어 레지스터가 ADD 11을 가져온다.
④ 이 때, 프로그램 카운터는 다음으로 가리키는 위치인, 101에서 하나 증가한 값인 102로 늘어나게 된다.
⑤ ADD 11이란 명령어가 제어 장치로 들어가서, CPU는 이를 Decode를 한다.
⑥ 그 다음 CPU는 이 ADD라는 명령어를 처리하기 위해서, 앞에서 읽어왔던 어큐물레이터에 들어있는 3이라는 데이터를 산술 논리 장치(ALU)에 옮긴다.
(여기서, ADD에 해당하는 주소가 11밖에 없으므로, 즉 하나이므로 CPU는 어큐물레이터에 더해질 값이 있을 거란 추측 하에 3이라는 데이터를 옮긴 것이다)
⑦ 11번 주소에 있는 값을 읽어야 하니까 메모리 주소 레지스터에 11이라는 주소를 넣어준다.
⑧ 해당 주소에 있는 4라는 데이터를 읽어와서, 메모리 데이터 레지스터에 넣어준다.
⑨ 이 때, 4라는 데이터는 산술 작업에 사용할 숫자이므로 어큐물레이터로 옮겨진다.
⑩ 그 데이터는 곧 산술 논리 장치(ALU)에 들어가서 이미 들어있는 3이라는 데이터와 더해져서 7이 된다.
⑪ 계산 결과인 7이 어큐물레이터로 이동한다. 이로써 ADD 11이란 명령어는 끝이 난다.
Ⅲ. STORE 12 처리
① 프로그램 카운터에 들어와 있는 102이란 값을 메모리 주소 레지스터에 옮긴다.
② 102란 주소에 접근하여 STORE 12란 명령어가 메모리 데이터 레지스터로 들어오게 된다.
③ 이는 명령어이므로 명령어 레지스터에 들어가게 된다.
④ 앞서 계속 언급했듯, 프로그램 카운터는 다음을 가리키는 위치인, 102에서 하나 증가한 값인 103으로 증가하게 된다. 하지만 103에 해당하는 값은 존재하지 않으므로(== 0 이므로), 이는 곧 이 프로그램이 종료가 될 예정이라는 것을 알려준다.
⑤ 이 때, STORE 12는 명령어이므로 제어 장치로 들어간다.
⑥ 제어 장치는 이 명령어를 곧 12번 주소에 결과 값을 저장하라고 기계어로 해독을 한 후, 해당 주소에 있는 데이터에 접근을 하도록 12란 주소를 메모리 주소 레지스터에 옮긴다.
⑦ 저장의 의미인 STORE의 명령어를 처리하기 위해, 이번에는 메모리로부터 CPU로 데이터를 갖고 오는 것이 아닌(== 읽어오는 것이 아닌) 어큐물레이터에 있던 7이라는 데이터를 메모리 데이터 레지스터로 옮긴다.
⑧ 앞서 옮겨진, 메모리 주소 레지스터에 들어있는 12번 주소에 메모리 데이터 레지스터에 들어있는 7이란 값이 저장된다. 이로써 STORE 12라는 명령어는 끝이 난다.
위의 예시는 3이라는 값와 4라는 값을 더해서 7이라는 결과를 출력하는 과정인데(편의상 메모리 주소는 제외), 이를 보아 CPU의 명령어 처리 과정은 굉장히 복잡하다는 것을 알 수 있다. 실제 프로그램은 고급 언어로 작성한 논리조차도 인간이 보기에 복잡한 경우가 있는데, 이를 수행하는 CPU가 얼마나 많은 일을 처리하는지 와닿게 되고, 또한 이를 토대로 하나의 함수에서 왜 출력 값이 같은 코드인데도 왜 실행 속도가 더 빠른 코드로 구현해야 하는지를 깨닫게 된다.
이렇게 복잡한 과정인데, 과연 인간은 CPU에게 어떻게 명령을 내렸을까?
//Dart 기준
int A = 3;
int B = 4;
int C = A + B;
// print(C);
// 출력 값: 7
#Python 기준
A = 3
B = 4
C = A + B
# print(C)
# 출력 값: 7
//Java 기준
A = 3;
B = 4;
C = A + B;
// System.out.println(C);
// 출력 값: 7
//JS 기준
var A = 3;
var B = 4;
var C = A + B;
// console.log(c);
// 출력 값: 7


미래에서 왜 기계가 인간을 죽이려고 하는지 알 것 같다
🧮 비트와 2진수에 대하여
프로그래머가 하는 일은 본질적으로 데이터와 정보를 다루는 것이다. 정보(데이터)의 단위, 정보의 기본 단위인 비트에 대하여, 이와 더불어 2진수에 대해 알아보자.
참고 자료: 바이트 이미지
데이터와 정보는 무엇일까?
데이터: 현실로부터 측정ㆍ관측을 통해 얻은 사실 혹은 값들
정보: 그러한 데이터를 쓸모있는, 유용한 형태로 변환하는 처리 과정을 거쳐 데이터에 의미를 부여한 것
그렇다, 데이터 분석이 바로 이 위와 같이 원시적인 사실인 데이터를 일반적으로 인간에게 유용한 정보로 가공하여 우리가 흔히 하는 통계(시각자료) 등을 만드는 것이다.
아래는 이해하기 쉽도록 필자가 주식 공부하면서 독학했던 R언어로 예시를 든 것이다.
개구리의 소득과 스팀에서의 게임 구매량이라는 데이터를 수집하고 가공하여, R이라는 데이터 분석 언어를 사용하여 R studio라는 개발 환경에서 시각화 라이브러리인 ggplot2라는 패키지 등으로 시각화하여 간단하게 분석해보자.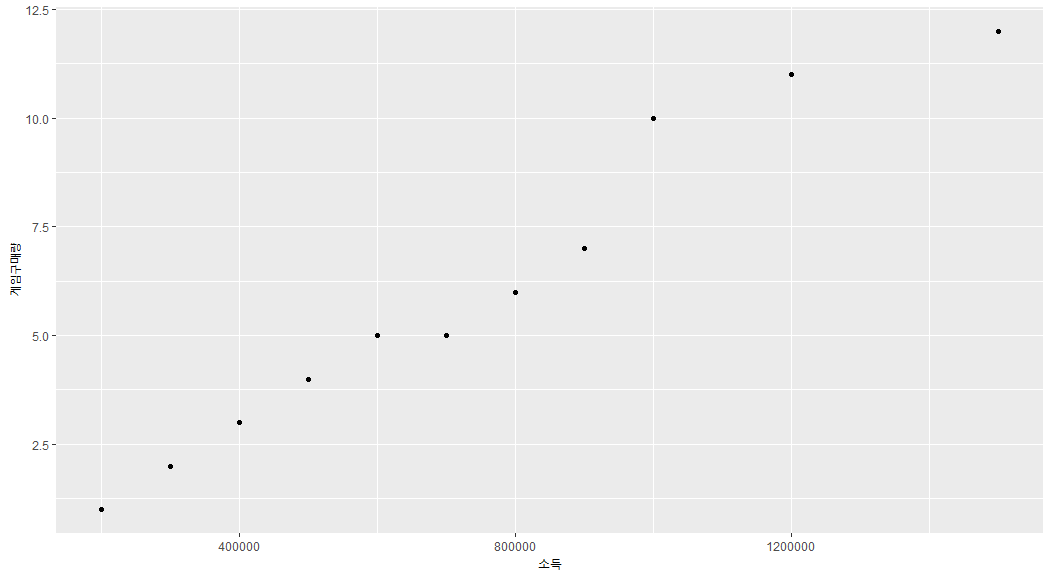 이를 통해 우리는 이 산점도 그래프를 통해
이를 통해 우리는 이 산점도 그래프를 통해 개구리의 소득에 따른 스팀에서의 게임 구매량이라는, 소득이 증가함에 따라 게임의 구매량이 증가한다는 유용한 데이터인 정보를 알 수 있다.
(물론 어느 기간에 할인 판매를 하고, 그로 인해서 게임 구매량이 달라지는 등의 사항은 간단한 설명을 위해 제외하였다)
위의 경우도 마찬가지이지만, 이러한 데이터(정보)를 프로그래머는 디지털 데이터와 디지털 정보라고 부르며 다룬다. 이는 단순히 프로그래머가 다루는 데이터(정보)가 인간을 위한 데이터(정보)가 아닌 기계가 이해하는 언어로 바뀌어진 데이터(정보)를 다루기 때문에 붙여진 이름이다. (즉, 핵심은 같다)
그렇다면 그 디지털 정보(데이터)의 단위인 비트는 어떻게 이루어져있을까?
비트(binary digit): 정보이론의 아버지인 Claude Elwood Shannon에 의해 공식화된 이름으로, binary에서 알 수 있듯이, 하나의 비트는 0이나 1의 값을 가질 수 있고, 각각은 참, 거짓 혹은 서로 배타적인 상태를 나타낸다.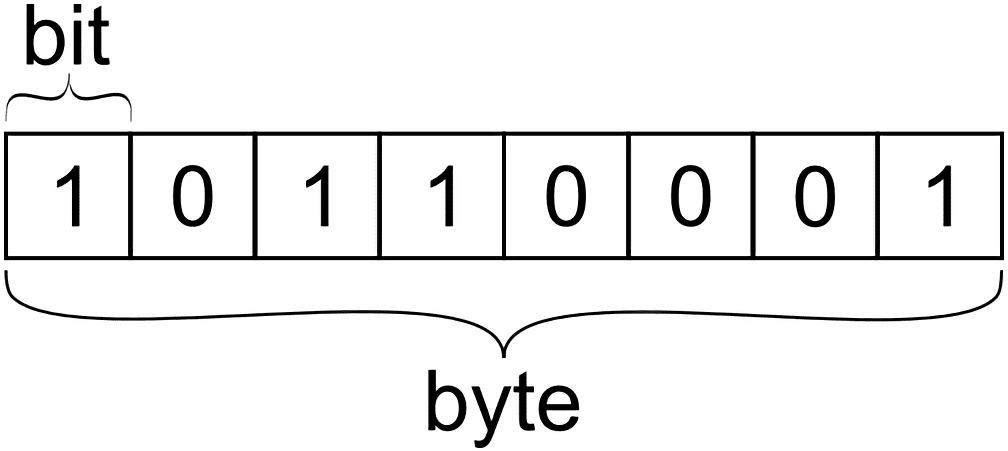 위 그림에서 알 수 있듯, 8개의 비트가 모여 1개의
위 그림에서 알 수 있듯, 8개의 비트가 모여 1개의 바이트(byte)를 형성하는데, 그 이유는 컴퓨터가 발달하게 되면서 관습적으로 정해진 것이기 때문이다. 그리고 이 바이트는 앞서 배웠던 메모리 주소의 기본 단위이다.
또한, 이러한 바이트 2개(== 16비트)가 모여 하나의 워드(Word)를 형성하는데, 이는 CPU가 데이터를 다루는 기본 단위, 즉 레지스터의 크기를 의미한다.
물론 현대 컴퓨터는 대부분 64비트의 CPU를 사용하는데 이것이 하나의 워드이다. 즉, CPU 혹은 시스템에 따라서 워드는 달라지게 되는 것이다.
그렇다면 이러한 비트를 2진수로 어떻게 표현할까?
매우 쉽다, 우선 256이 어떻게 10진수로 표현되는지 알아보자.
256
= 200 + 50 + 6
= ㆍㆍㆍ
= ㆍㆍㆍ
= 2 × 10² + 5 × 10¹ + 6 × 10⁰
강조 처리한 부분은 밑(Base)이다. 모든 10진수는 이 밑이란 곳에 10의 제곱이 들어가 있는 형태로 표현할 수 있다. 그렇다면 이번엔 11이라는 10진수를 2진수로 표현해보겠다.
11
= 8 + 0 + 2 + 1
= 1 × 8 + 0 × 4 + 1 × 2 + 1 × 1
= 1 × 2³ + 0 × 2² + 1 × 2¹ + 1 × 2⁰
강조 처리한 부분은 2진수이기 때문에 2의 제곱 형태로 표현되어 있는 것이다. 여기서 알아볼 건 그 외에 인라인 블록 처리한 부분이다. 보면 1과 0으로 표현되어있다. 그렇다, 아래 그림처럼 비트에 이 값들이 들어가게 되는 것이다.
다른 방법으로 이번에는 148이라는 10진수를 2진수로 나타내는 과정을 알아보자.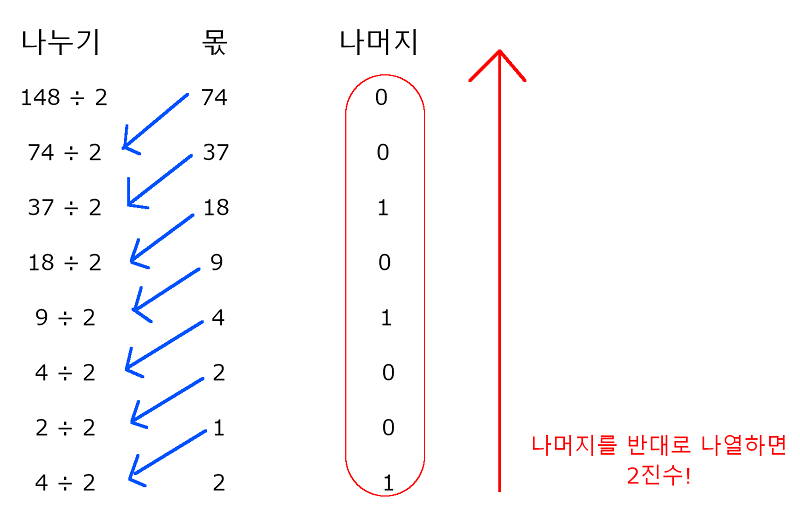 위 그림을 통해 148이란 10진수는 10010100인 2진수로 표현됨을 알 수 있다.
위 그림을 통해 148이란 10진수는 10010100인 2진수로 표현됨을 알 수 있다.
그럼 이에 더 나아가서 2진수의 덧셈을 해보자.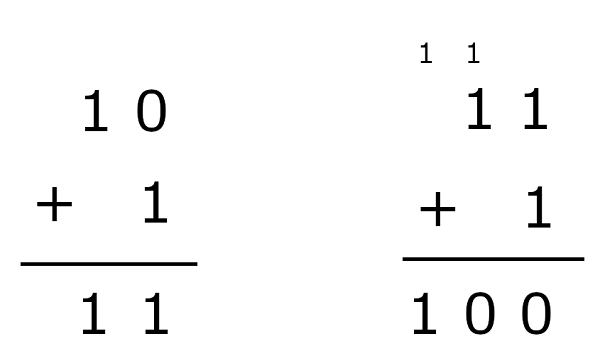
10 + 1 은 위 그림과 같이 11임을 알 수 있다. 하지만 11 + 1은 우리가 흔히 알던 십진법이 아닌, 이진법으로 표현해야하므로 100의 값이 나오는 것을 확인할 수 있다. 8비트의 덧셈 또한 자릿수만 늘어난 채로 원리는 같으니 생략하겠다.
마지막으로 부호가 있는(Signed) 비트의 정수에 대해 알아보자. 여기서 부호가 있는 비트는 첫 비트가 1이면 음수, 0이면 양수를 나타낸다. 앞서 얘기했듯, 8비트, 16비트 혹은 32비트와 64비트 등으로 예시를 들 수 있겠지만 간단하게 8비트를 예시로 하겠다.
(편의상 4비트 단위로 띄어서 썼지만, 실제로는 둘이 붙어있어야합니다)
우선 이를 이해하려면 2의 보수 방법에 대해서 알아야 한다. 방법은 간단하다. 비트에 1이 들어있다면 이를 반대인 0으로 바꿔주고, 0이 들어있다면 이의 반대인 1을 넣어준 뒤, 마지막으로 이 값에 1을 더하면 된다.
그럼 만약 -5라는 10진수가 있다면 이를 8비트로 어떻게 표현할까?
5를 2진수로 나타내면 0000 0101
2의 보수를 적용하면 1111 1010 에 1을 더한 값인
1111 1011이 될 것이다.
이 수에 5를 2진수로 나타낸 값인 0000 0101과 더했을 때 0이 되므로
1111 1011은 10진수로 -5임을 알 수 있다.
위를 토대로 8비트를 기준으로 정수의 범위를 알아보며 마치겠다.
부호가 있는 정수:
1000 0000 ~ 0111 1111 <2진수>
-128 ~ 127 <10진수>
부호가 없는 정수:
0000 0000 ~ 1111 1111 <2진수>
0 ~ 255 <10진수>
🚩 마무리하며

사실 이 글은 필자와 같이 전체적인 구조(숲)를 먼저 파악한 뒤, 세부적인 것들(나무)을 알고자 하는 사람들을 위해 다 같이 효율적으로 공부하자는 차원에서 썼다. 이를 바탕으로 자료구조, 알고리즘 그리고 운영체제 등을 공부한다면 그에 대해 이해하는 속도가 빨라지지 않을까 싶다.(물론 나의 희망사항이다)
필자는 지난 4월 말부터 11월 초까지 약 6개월의 시간동안 CS 뿐만 아니라 프로그래밍에 대한 기본적인 지식과 더불어 가장 중요한 해당 언어의 문법조차도 무시하고 맨 땅에 헤딩하듯 개발에 몰두했었다. (비전공자에 무식한 내가 뭘 알겠는가?)
Dart라는 언어를 사용하는 크로스 플랫폼 개발 프레임워크인 Flutter를 사용하여 플레이스토어와 앱스토어에 어플을 출시까지 해보니 그 과정이 너무나 값진 경험이었지만 되돌아보니 내가 얼마나 바보 같았고 먼 길을 돌아왔으며 얼마나 하찮았고 지금도 그러한 지를 깨닫게 되는 계기 또한 되었다. 하지만 후회는 없다. 역설적이게도 그렇게 아무런 기본 지식없이 돌파해보니 오히려 더더욱 기초적인 프로그래밍(+CS) 지식과 언어의 문법이 얼마나 중요한지에 대해 단순히 알게되는 것이 아닌 정말 온몸으로 체감을 하게 되었으니 말이다.
"아 Flutter가 크로스 플랫폼 개발 프레임워크인데 이러한 이점을 개발자들에게 널리 알려서 차후에 지르콘이라는 마이크로 커널을 기반으로 하는 구글의 신세대 OS인 Fuchsia로의 유입을 유도하는 거였구나 (Flutter에서 만든 어플리케이션은 Fuchsia에서도 그대로 동작, 곧 여러 플랫폼으로의 확장성을 의미함. Flutter로 앱 뿐만 아니라 웹도 만들 수 있음, 물론 웹은 아직 불안정)"
"아 컴퓨터가 이런 계기로 이진법을 채택했고 산술논리연산을 그래서 항상 두 가지 경우로 복잡하게 해왔던거구나, 내가 만든 And Or Equal 같은 비교 연산자들이 다 트랜지스터들이 이렇게 나뉘어서 연산을 했던 거구나"
"아 내 컴퓨터가 64비트인데, 단순히 숫자도 크고 전보다는 최신이니까 좋은 줄 알았는데 CPU가 데이터를 다루는 양이 그만큼 더 커져서 연산이 빨라져서 좋은 거였구나"
"아 이런 것들을 안다고 해서 코딩 실력이 확연히 늘지 않는다고 했던 말도 이런 의미였구나"
Flutter 덕분에 앱의 전반적인 구조와 기능 등의 기본적인 내용들을 알게 되었고, 오히려 백엔드라는 분야에 호기심과 도전을 불러일으키게 된 계기가 되었다.
(개발 당시 Firebase라는 백엔드 플랫폼을 사용했었는데, 그러면서도 미래엔 내가 그렇게 전체를 맡기는 것이 아닌 스스로 서버도 구축하고 로직도 짜보고 싶다는 생각을 많이 했다. 단순히 궁금해서가 아니라 진짜 공부해서 그 원리를 파악하고 응용하고, 씹고 뜯고 맛보고 즐기고 싶다. Firebase에 들어가는 돈도 아끼고)
2022.11.15.(화) 기준,
이 글이 실시간 트렌딩 TOP 4에 올라왔습니다. 1000명 이상의 사람들이 이 글을 봐주셨네요! 읽어주셔서 감사합니다😄



{kind=link}
대단해요..