
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
베이스-바운드 방식을 사용했을 때 프로세스에 할당된 힙과 스택 메모리 사이에 사용되지 않는 공간이 있음을 보았다. 이처럼 메모리를 가상화하기 위해 단순히 베이스-바운드 레지스터 쌍을 쓰는 것은 비효율적이다. 이는 또한 전체 주소 공간이 메모리에 맞아 떨어가지 않을 경우 프로그램을 실행하기 어렵게 만들기도 한다.
1. Segmentation: Generalized Base / Bounds
이와 같은 문제를 해결하기 위해 만들어진 기법이 세그먼테이션(segmentation) 이다. 아이디어는 간단하다. MMU에서 단 한 쌍의 베이스-바운드를 쓰는 게 아니라, 주소 공간의 논리적인 세그먼트마다 베이스-바운드 쌍을 주는 것이다. 세그먼트는 일정한 길이를 가지는, 주소 공간의 연속적인 부분이다. 이 예제에서는 세 개의 논리적으로 구분되는 세그먼트들이 있는데 바로 코드, 스택, 힙이다.
세그먼트를 사용함으로써 OS는 각 세그먼트를 물리 메모리의 다른 부분들에 배치시켜 사용되지 않는 가상 주소 공간으로 물리 메모리를 채우는 일이 일어나지 않게 한다.
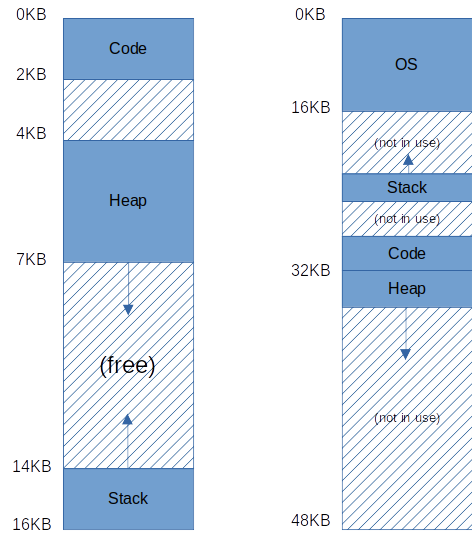
프로세스는 여전히 왼쪽과 같은 환상을 가지고 있겠지만, 오른쪽에서는 세그먼트 별로 베이스-바운드 쌍을 사용함으로써 각 세그먼트를 물리 메모리에 독립적으로 위치시킨다. 위에서 볼 수 있듯 오직 사용 중인 메모리만이 물리 메모리에 공간을 할당받으며, 사용되지 않는 큰 주소 공간을 가지는 주소 공간(희소 주소 공간, sparse address space)이 가능해진다.
세그먼테이션을 위해 필요한 MMU의 하드웨어 구조는 예상하기 쉽다. 이 경우에는 세 쌍의 베이스-바운드 레지스터가 된다.
| Segment | Base | Size |
|---|---|---|
| Code | 32K | 2K |
| Heap | 34K | 3K |
| Stack | 28K | 2K |
2. Which Segment Are We Referring To?
하드웨어는 주소 변환 시 세그먼트 레지스터들을 사용한다. 그렇다면 이 하드웨어는 세그먼트의 오프셋을 어떻게 알고, 해당 세그먼트가 참조하고 있는 주소는 어떻게 알까?
Explicit Approach
한 가지의 접근법은, 명시적 접근법으로, 주소 공간을 가상 주소의 상위 몇 개의 비트를 기반으로 세그먼트로 나누는 것이다.
위의 예시에서 우리는 세 개의 세그먼트를 가지고 있으므로, 각 세그먼트를 구분하기 위해서는 2비트를 사용하면 될 것이다. 만약 14비트의 가상 주소를 사용한다고 하면 다음과 같이 될 것이다.

만약 상위 2비트가 00이면 하드웨어는 가상 주소가 코드 세그먼트에 있음을 알고 코드의 베이스-바운드 쌍을 사용할 것이다. 마찬가지로 상위 2비트가 01이면 힙의 베이스-바운드 쌍을 쓴다.
그런데 문제는 상위 2비트로는 네 종류의 세그먼트를 표현할 수 있음에도, 우리가 현재 쓰고 있는 세그먼트에는 세 종류 밖에 없다는 것이다. 한 세그먼트에 해당하는 주소 공간은 사용되지 않는다. 가상 주소 공간을 완전히 활용하기 위해 몇몇 시스템들은 코드를 힙 세그먼트와 같은 곳에 넣고, 세그먼트 선택을 위해서는 한 비트만 사용하기도 한다.
또 다른 이슈는 세그먼트를 선택하기 위해서 너무 많은 상위 비트들을 사용하면 가상 주소 공간의 사용을 제한하게 될 수도 있다는 것이다. 각 세그먼트는 최대 사이즈를 가진다. 상위 2비트를 세그먼트 구분을 위해 사용하는 경우, 14비트 주소 체계에서 세그먼트는 최대 4KB의 주소 공간을 가질 수 있다. 만약 실행 중인 프로그램이 세그먼트를 최대값을 넘게 키우고 싶어하는 경우가 있다면 실패할 것이다.
Implicit Approach
하드웨어가 특정 주소가 어떤 세그먼트에 있는지를 결정하는 다른 여러 방식들도 있다. 암묵적 접근법에서 하드웨어는 주소가 어떻게 구성되었는지를 통해서 세그먼트를 결정한다. 만약 주소가 PC에 의해 만들어졌다면 이는 코드 세그먼트에 있다. 만약 주소가 스택 또는 베이스 포인터를 기반으로 한다면, 이는 스택 세그먼트에 있다. 이외의 경우는 힙에 있다.
3. What About The Stack?
스택의 경우는 거꾸로, 즉 낮은 주소의 방향으로 자란다. 위 예제에서 스택은 물리 메모리에서는 28KB에서 시작해서 26KB로 자라고, 상응하는 가상 메모리에서는 16KB에서 14KB로 자란다. 따라서 주소 변환도 조금 다르게 이뤄져야 한다.
이를 위해서는 하드웨어의 지원을 조금 받아야 한다. 하드웨어는 그냥 베이스-바운드 값을 쓰지 않고, 이 세그먼트가 자라는 방식에 대해서도 알아야 하며, 세그먼트가 반대 방향으로 자란다는 것을 알면, 가상 주소도 조금 다른 방식으로 변환해야 함.
| Segment | Base | Size (max 4K) | Grows Positive? |
|---|---|---|---|
| Code 00 | 32K | 2K | 1 |
| Heap 01 | 34K | 3K | 1 |
| Stack 11 | 28K | 2K | 0 |
예제에서 가상 주소 15KB에 접근하려고 한다고 하자. 이 주소는 물리 주소 27KB에 매핑되어 있다. 이는 이진법으로는 11 1100 0000 0000이 된다. 하드웨어는 앞의 두 비트 11을 이용해 어떤 세그먼트인지를 밝힌다.
이후 남은 3KB의 오프셋을 이용해 물리 메모리에서의 오프셋을 얻는다. 스택은 거꾸로 자라므로 오프셋도 음수가 돼야 한다. 이 음의 오프셋을 얻으려면 가상 주소의 오프셋에서 최대 사이즈를 뺀다. 세그먼트의 최대 사이즈는 4KB이므로 3 - 4= -1KB가 원하는 오프셋이다. 이 음의 오프셋을 베이스에 더해 실제 물리 주소를 얻는다. 바운드는 음의 오프셋의 절댓값이 세그먼트의 현재 사이즈보다 작거나 같은지를 봄으로써 확인할 수 있다.
4. Support for Sharing
하드웨어의 지원을 조금 더 받으면 효율성을 향상 시킬 수 있다. 메모리를 절약하기 위해서 특정 메모리 세그먼트를 주소 공간에서 공유하는 것이 유용할 때가 있다. 특히 코드 공유가 대표적인데, 이는 오늘날의 시스템에서도 계속 쓰이고 있다.
공유를 위해서는 추가적인 하드웨어의 지원이 필요한데, 이를 위해서는 보호 비트(protection bit) 가 필요하다. 이 보호 비트는 각 세그먼트 뒤에 붙어 프로그램이 해당 세그먼트를 읽거나 쓸 수있는지, 혹은 해당 세그먼트의 코드를 실행할 수 있는지의 여부를 가리킨다. 만약 코드 세그먼트를 읽기 전용으로 둔다면, 이 세그먼트는 프로세스 간 고립을 해치지 않으면서도 같은 코드를 가지는 여러 프로세스들 사이에서 공유될 수 있을 것이다.
이렇게 코드 세그먼트를 공유하더라도 여전히 각 프로세스는 자신이 자신만의 메모리에 접근하고 있다고 생각할 것인데, 이러한 환상은 OS가 프로세스에 의해 수정될 수 없는 메모리들을 비밀스럽게 공유하도록 하고 있기 때문에 유지되는 것이다.
보호 비트를 이용하면 앞서 말한 하드웨어 알고리즘도 변해야 한다. 원래는 가상 주소가 바운드에 있는지만을 확인했지만, 이제 하드웨어는 거기에 더해 특정한 접근이 허용 가능한지도 확인해야 한다. 만약 유저 프로세스가 읽기 전용인 세그먼트에 쓰려고 하거나, 실행할 수 없는 세그먼트를 실행하려고 하면 하드웨어는 예외를 일으켜 OS가 이를 처리할 수 있게 해야 한다.
5. Fine-grained vs. Coarse-grained Segmentation
지금까지의 예시들은 몇 개의 세그먼트를 가지는 시스템에만 초점을 맞췄다. 이러한 세그멘테이션을 coarse-grained라고 한다. 왜냐하면 이는 주소 공간을 비교적 크고 거친 덩어리로 나누기 때문이다. 하지만 몇몇의 초기 시스템들은 주소 공간을 더 융통성 있고 많은 수의 작은 세그먼트들로 이루어지게 했다. 이를 fine-grained 세그멘테이션이라 부른다.
여러 개의 세그먼트들을 이용하기 위해서는 일종의 세그먼트 테이블들을 메모리에 저장하는 등의 더 많은 하드웨어 지원이 필요하다. 그런 세그먼트 테이블들은 보통 아주 많은 수의 세그먼트 생성을 지원해 시스템이 세그먼트들을 더 융통성있게 사용할 수 있게 한다.
6. OS Support
세그먼테이션에서는 프로세스 별로 한 쌍의 베이스-바운드를 사용할 때보다 많은 물리 메모리를 절약할 수 있게 됐다. 구체적으로 스택과 힙 사이의 사용되지 않는 공간들은 물리 메모리에 할당되지 않게 해, 더 많은 주소 공간들을 물리 메모리에 집어 넣어, 프로세스마다의 크고 성긴 가상 주소 공간을 가능하게 한다. 하지만 세그먼테이션은 OS에 많은 새 이슈들을 만든다.
문맥 전환
우선 문맥 전환이 일어날 때 OS는 세그멘테이션 레지스터를 저장되고 복원해야 한다. 각 프로세스는 자신만의 가상 주소 공간을 가지고, OS는 프로세스를 재실행하기 전에 이 레지스터들을 제대로 복원해야 한다.
세그먼트의 크기 변화
다음으로 세그먼트가 자라거나 줄어들 때 OS는 무엇을 해야할까? 예를 들어 프로그램이 malloc()을 한다고 해보자. 어떤 경우에는 지금 있는 힙만으로 해당 요청을 처리할 수 있어, malloc()은 필요한 가용 공간을 찾아 해당 주소의 포인터를 반환할 것이다. 하지만 그렇지 못하는 경우 힙 세그먼트는 자라야 한다. 이 경우, 메모리 할당 라이브러리는 힙의 크기를 증가시키는 시스템 콜을 수행하고 OS는 세그먼트 사이즈를 업데이트해 더 많은 공간을 제공한다. 만약 더 많은 물리 메모리를 사용할 수 없게 되면 OS는 요청을 거부한다.
가용 공간 관리
가장 중요한 마지막 이슈는 물리 메모리에서 가용 공간을 관리하는 것이다. 새 주소 공간이 만들어지면 OS는 그 세그먼트를 위한 공간을 물리 메모리에서 찾을 수 있어야 한다. 예전에는 각 주소 공간이 같은 크기를 가진다고 가정하고 물리 메모리는 프로세스가 들어갈 수 있는 슬롯의 배열 정도로 생각됐다. 하지만 지금은 프로세스마다 많은 세그먼트들을 가지고 있고, 각 세그먼트들은 서로 다른 크기를 가진다.
가장 일반적인 문제는 물리 메모리가 가용 공간의 홀들로 가득차게 되는 것이다. 이는 새 세그먼트의 할당을 어렵게 만들고 이미 있는 세그먼트의 크기를 늘리는 것도 어렵게 만든다. 이를 외부 단편화(external fragmentation) 이라 부른다.
이 문제에 대한 한 해결법은 물리 메모리에 존재하는 세그먼트들을 압축(compact) 하는 것이다. 예를 들어 OS는 실행 중인 모든 프로세스를 정지한 후 그 데이터를 메모리의 연속적인 영역에 복사하고, 세그먼트 레지스터의 값을 새로운 물리적 위치로 바꿔 사용할 수 있는 더 큰 가용 메모리 공간을 만들어 낸다. 이후 OS는 그 큰 가용 메모리 공간을 이용해 새로운 할당 요청을 성공시킬 수 있다.
하지만 압축은 비싼 작업이다. 세그먼트를 복사하는 것은 많은 메모리와 많은 프로세서 시간을 사용하기 때문이다. 압축은 또한 이미 있는 세그먼트의 크기를 늘리는 일을 어렵게 만들기 때문에, 이후의 요청에 따라 더 많은 재배치를 필요해질 수도 있다.
가용 공간 관리 문제를 해결하기 위해서는 가용-리스트 관리 알고리즘을 이용하는 더 간단한 접근법을 사용할 수도 있다. 이 접근법에는 고전적인 best-fit, worst-fit, first-fit, 혹은 더 어려운 buddy 알고리즘을 포함한 수 백 가지가 있다. 하지만 아무리 똑똑한 알고리즘을 쓰더라도 외부 단편화는 근본적으로 없앨 수 없다. 좋은 알고리즘은 이를 최소화할 뿐이다.
7. Summary
세그먼테이션은 많은 문제들을 해결하고, 더 효과적인 메모리 가상화를 설계할 수 있게 한다. 세그먼테이션은 주소 공간의 논리적 세그먼트 사이에 있을 수 있는 메모리 낭비를 피하며 성긴 주소 공간을 가능하게 한다.
세그먼테이션은 빠르기도 하다. 왜냐하면 세그먼테이션이 필요로 하는 산술은 쉽고 하드웨어에도 잘 맞기 때문에 변환의 오버헤드가 최소가 되기 때문이다. 세그먼테이션에는 코드 공유와 같은 부가적인 이점도 있다. 별개의 세그먼트에 위치하는 코드는 여러 실행 중인 프로그램 사이에서 잠재적으로 공유될 수 있다.
하지만 다양한 사이즈의 세그먼트들을 메모리에 할당하는 것은 문제를 일으키기도 한다. 그 첫 번째는 앞서 얘기된 외부 단편화 문제다. 세그먼트들은 다양한 사이즈를 가지고 있기 때문에 가용 공간들은 잘못된 사이즈로 잘려 메모리 할당을 어렵게 만들 수 있다. 좋은 알고리즘을 사용하거나 주기적으로 메모리를 압축함으로써 이를 해결하려 할 수는 있겠지만, 이 문제는 근본적이고 해결되기 어렵다.
두 번째 문제는 세그먼트가 여전히 완전히 일반화된 성긴 주소 공간을 위한 충분한 융통성을 가지지는 못하고 있다는 것이다. 예를 들어 만약 우리가 한 논리적 세그먼트에 크지만 드문드문 쓰이는 힙을 쓴다면, 전체 힙은 여전히 접근되기 위해 계속해서 메모리에 있어야 한다. 다시 말해 주소 공간이 어떻게 사용되는지에 대한 모델과 설계된 세그먼테이션과 맞지 않으면 세그먼테이션은 제대로 잘 작동하지 않는다.
