
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
3. Solution #2: Journaling (or Write-Ahead Logging)
Batching Log Updates
지금까지의 기본 프로토콜을 이용하는 경우 추가적인 디스크 트래픽이 발생할 수 있다. 예를 들어, file1, file2 두 파일을 같은 디렉토리에 연이어 만든다고 해보자. 하나의 파일을 만들기 위해서는, 적어도 아이노드 비트맵, 새롭게 만들어지는 파일의 아이노드, 새 디렉토리 엔트리를 포함하는 부모 디렉토리의 데이터 블럭, 부모 디렉토리 아이노드를 포함해, 많은 디스크 상 구조들을 업데이트해야 한다. 저널링을 이용하는 경우 새로운 두 파일 생성 각각에 대해, 이 정보들 모두를 논리적으로 저널에 커밋해야한다. 이 파일들이 같은 디렉토리에 있고, 그 아이노드들이 같은 아이노드 블럭에 있다 한다면, 같은 블럭을 계속해서 쓰게 될 수도 있다.
이 문제를 해결하기 위해, 일부 파일 시스템들은 디스크로의 업데이트가 일어날 때마다 커밋을 하지 않고, 이것들을 모두 전역 트랜잭션에 버퍼 처리한다. 위의 예로 보면 두 파일이 만들어졌을 때, 파일 시스템은 메모리 내의 아이노드 비트맵, 파일 아이노드, 디렉토리 데이터, 디렉토리 아이노드를 dirty로 표시하고, 현재 트랜잭션을 이루는 블럭 리스트에 추가한다. 이후 이 블럭들을 디스크에 써야할 때가 오면, 이 하나의 전역 트랜잭션이 커밋된다. 업데이트를 버퍼링함으로써 파일 시스템은 과도한 디스크 쓰기 트래픽 문제를 피할 수 있게 된다.
Making The Log Finite
파일 시스템은 업데이트들을 메모리에 얼마간 버퍼 처리한다. 이후 언젠가 디스크에 쓸 시간이 오면, 파일 시스템은 트랜잭션의 세부 사항들을 저널에 쓴다. 트랜잭션이 끝나면 파일 시스템은 해당 블럭들을 디스크 상 최종 위치로 체크포인팅한다.
하지만 문제는 로그의 크기가 유한하다는 것이다. 만약 계속해서 트랜잭션들을 로그에 추가한다면 로그에 할당된 공간은 곧 꽉 차 버릴 것이다. 로그가 차게 됨에 따라 일어날 수 있는 문제에는 두 가지가 있다.
첫 번째는 간단하고, 덜 치명적인 문제다. 복구 과정은 로그 내의 모든 트랜잭션들을 순서대로 재생해야하므로, 로그가 커질수록 복구에 걸리는 시간을 길어진다는 것이다. 두 번째는 좀 더 중요하다. 로그가 꽉차면 트랜잭션은 더 이상 디스크에 커밋될 수 없어 파일 시스템 자체가 쓸모 없어지게 된다.
이 문제들을 해결하기 위해 저널링 파일 시스템은 로그를 환형 자료 구조로 다루며, 계속해서 재사용한다. 이것이 저널이 때때로 환형 로그(circular log)라 불리는 이유다. 이렇게 하기 위해 파일 시스템은 체크포인트 이후 어떤 액션을 취해야 한다. 구체적으로, 트랜잭션이 체크포인팅되면 파일 시스템은 그것이 저널에서 차지하던 공간의 할당을 해제함으로써 로그 공간을 재사용할 수 있게 만들어야 한다. 이를 달성하는 데에는 많은 방법이 있따. 예를 들면 단순히 로그 내에 있는, 체크포인팅 되지 않은 가장 오래된 트랜잭션과 최신의 트랜잭션을 저널 슈퍼블럭에 표시하고 나머지 공간은 할당 해제 한다.
저널링 시스템은 저널 슈퍼블럭에 어떤 트랜잭션이 아직 체크포인팅 되지 않았는지에 대한 충분한 정보들을 기록함으로써, 복구 시간을 줄이고 환형 방식으로 로그를 재사용할 수 있도록 한다. 따라서 기본 프로토콜에는 다음과 같은 단계가 추가되어야 한다.
- 저널 쓰기: 트랜잭션의 내용을 로그에 쓰고, 해당 쓰기가 완료될 때까지 기다린다.
- 저널 커밋: 트랜잭션 커밋 블럭을 로그에 쓴다. 쓰기가 완료되기를 기다린다.
- 체크포인트: 업데이트 내용을 파일 시스템 내 최종 위치에 쓴다.
- 해제: 저널 슈퍼블럭을 업데이트 함으로써 트랜잭션이 저널 내에서 할당 해제되었음을 표시한다.
이렇게 데이터 저널링 프로토콜의 최종본을 얻었다. 하지만 아직도 여전히 문제가 있다. 각 데이터 블럭을 디스크에 두 번 써야하게 됨으로써 비용 낭비가 발생한다는 것이다(저널에 1번, 최종 위치에 1번). 어떻게 데이터를 두 번 쓰지 않으면서도 일관성을 유지할 수 있을까?
Metadata Journaling
이제 복구 작업 자체는 빨라졌지만, 파일 시스템의 일반적인 작업들은 더 느려졌다. 매 디스크 쓰기 작업이 일어나기 전에 저널에도 써야하고, 따라서 쓰기 트래픽은 두 배가 되기 때문이다. 순차 쓰기 워크로드의 경우에는 더 뼈아프다. 드라이브의 최대 쓰기 대역폭의 절반에 밖에 도달하지 못하기 떄문이다. 또한 저널 쓰기와 메인 파일 시스템에 쓰기 사이에는 많은 탐색 시간이 필요하다. 이는 일부 워크로드에 상당한 추가 오버헤드를 발생시킨다.
데이터 블럭을 디스크에 두 번 쓰는 일의 높은 비용으로 인해, 사람들은 성능 향상을 위한 다른 방법들을 시도해봤다. 위에서 설명한 저널링의 모드는 보통 데이터 저널링이라 부르는데, 모든 사용자 데이터를 저널링하기 떄문이다. 더 간단한, 그리고 더 흔한 저널링의 한 형태는 정렬된 저널링(ordered journaling), 혹은 메타데이터 저널링이라 불리는 것으로, 데이터 저널링과 거의 비슷하지만 사용자 데이터를 저널에 쓰지는 않는다.

기존의 업데이트를 메타데이터 저널링을 통해 기록하면 위와 같다. 달라진 점은 기존에는 로그에 쓰여 있던 데이터 블럭 Db가 이번에는 쓰여있지 않다는 것이다. 이 데이터 블럭은 파일 시스템에 곧바로 쓰여 추가적인 쓰기가 일어나지 않게 된다. 디스크에 일어나는 I/O 트래픽의 대부분이 데이터 때문임을 생각한다면, 데이터를 두 번 쓰지 않는 것은 저널링의 I/O 부하를 상당히 줄일 수 있는 방법이다. 하지만 이런 방식은 다음의 물음을 낳는다. 언제 데이터 블럭을 디스크에 써야할까?
다시 위 예제를 살펴보자. 업데이트에는 I[v2], B[v2], Db의 세 블럭들이 있다. 첫 번째 두 개는 모두 로깅되고 체크포인팅될 메타데이터들이고, 나머지는 파일 시스템에만 한 번 쓰인다. 그렇다면 Db를 디스크에 써야할 시점은 언제일까?
데이터 쓰기의 순서를 정하는 일은 메타데이터 저널링에 있어 문제가 된다. 예를 들어 Db를 트랜잭션이 완료된 후에 디스크에 쓴다면 어떨까? 이 방식에는 문제가 있다. 파일 시스템은 일관적이지만, 쓰레기 값을 가리킬 수 있기 떄문이다. 구체적으로 I[v2], B[v2]는 디스크에 쓰였지만, Db는 쓰이지 않은 경우를 생각해보라. 로그를 통한 복구는 불가하다.
이 문제가 일어나지 않게 하기 위해, 어떤 파일 시스템들은 데이터 블럭을, 관련된 메타데이터보다 먼저 디스크에 먼저 쓴다. 구체적인 프로토콜은 아래와 같다.
- 데이터 쓰기: 데이터를 최종 위치에 쓴다.
- 저러 메타데이터 쓰기: 시작 블럭 맟 메타데이터를 로그에 쓴다
- 저널 커밋: 트랜잭션 커밋 블럭을 로그에 쓴다.
- 메타데이터 체크포인트: 메아데이터 업데이트의 내용을 파일 시스템 내 최종 위치에 쓴다.
- 해제: 해당 트랜잭션이 해제되었음을 저널 슈퍼블럭에 쓴다.
데이터 쓰기가 먼저 일어나도록 강제함으로써 파일 시스템은 포인터가 쓰레기 데이터를 가리키지 않음을 보장할 수 있다. 바로 이 "가리켜지는 객체를 가리키는 객체보다 먼저 써라."라는 규칙dl 충돌 일관성의 핵심이다.
대부분의 시스템에서 메타데이터 저널링은 전체 데이터 저널링보다 많이 쓰인다. 예를 들어 Windows NTFS, SGI의 XFS는 메타데이터 저널링의 한 형대를 사용한다. 리눅스 ext3는 데이터 저널링, 정렬 저널링, 비-정렬 저널링의 세 모드 옵션을 제공한다. 이 세 모드는 모두 메타데이터를 일관성 있게 관리한다.
마지막으로 저널 메타데이터 쓰기가 일어나기 위해 반드시 데이터 쓰기가 완료되기를 기다릴 필요는 없다는 점을 염두에 두자. 구체적으로 데이터 쓰기, 메타데이터-시작 블럭, 저널링되는 메타데이터 쓰기 요청은 동시에 이뤄져도 된다. 이 모든 것들은 위의 세 번째, 저널 커밋 블럭 쓰기 단계 이전에만 완료되면 된다.
Tricky Case: Block Reuse
저널링을 좀 더 까다롭게 만드는 케이스가 있는데, 블럭 재사용과 관련된 이슈다. 메타데이터 저널링을 사용한다. 사용자가 디렉토리 foo에 새로운 엔트리를 추가한다고 하자. 디렉토리는 메타데이터로 취급되므로, 이때 foo의 내용은 로그에 쓰인다. foo 디렉토리 데이터의 위치가 블럭 1000이라고 가정하자. 그러면 로그는 다음과 같이 생겼을 것이다.

이 지점에서 사용자가 디렉토리를 포함해 디렉토리의 모든 것을 삭제하고 블럭 1000을 재사용하기 위해 할당 해제했다고 하자. 사용자가 새로운 파일 bar를 만들고, 이전에는 foo가 사용했던 1000번 블럭을 재사용하려고 한다고 하자. bar의 아이노드와 데이터는 디스크에 커밋된다. 하지만 지금은 메타데이터 저널링이 사용되고 있으므로, bar의 아이노드만이 저널에 커밋되고, 블럭 1000에 새롭게 쓰인 bar의 데이터는 저널링되지 않는다.

이 정보가 모두 로그에 남아있는 상태에서 충돌이 일어났다고 해보자. 복구 프로세스는 로그에 있는 모든 것을 단순히 재생할 뿐이다. 그런데 디스크에는 이미 foo가 삭제되고 bar의 데이터가 들어있다. 그런데 위 로그를 그냥 재생하면 현재 파일 bar의 사용자 데이터를 오래된 디렉토리 내용으로 덮어쓰게 된다.
이 문제에 대한 해결법에는 많은 것들이 있다. 예를 들면 삭제된 블럭이 저널로부터 체크포인팅되기 전까지는 해당 블럭을 재사용하지 않는 방법이 있다. 리눅스 ext3은 다른 방식을 택하는데, revoke 레코드라 불리는 새로운 타입의 레코드를 저널에 추가하는 것이다. 위와 같은 경우, 디렉토리 삭제는 저널에 revoke 레코드를 쓴다. 저널을 재생할 때 시스템은 그런 revoke 레코드를 우선 스캔하고, 해당 데이터는 재생하지 않음으로써 위와 같은 문제를 피하게 된다.
Wrapping Up Journaling: A Timeline
저널링에 대한 논의를 마치기 전에, 지금까지 논의한 프로토콜들을 타임라인으로 그려 정리해보자. 아래의 타임라인(Figure 42.1)은 데이터와 메타데이터를 저널링하는 프로토콜을 나타내며, 그 아래(Figure 42.2)는 메타데이터만을 저널링할 떄의 프로토콜을 보여주고 있다.
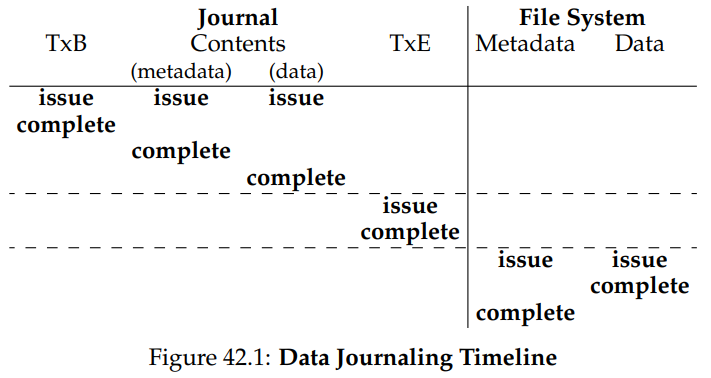

시간은 아래 방향으로 진행되며, 각 행은 쓰기 요청이 발생하거나 끝나는 논리적 시간을 나타낸다. 예를 들어 데이터 저널링 프로토콜에서 트랜잭션 시작 블럭의 쓰기와 트랜잭션의 내용은 논리적으로 같은 시간에 요청될 수 있고, 순서와 상관없이 완료될 수 있다. 하지만 트랜잭션 종료 블럭은 앞서의 쓰기들이 완료되기 전에는 요청되지 않아야 한다. 비슷하게 데이터와 메타데이터 블럭의 체크포인팅은 트랜잭션 종료 블럭이 커밋되기 전에는 시작하지 않아야 한다. 가로 점선은 따라야 할 쓰기 순서가 있는 경우를 구분하기 위해 쓰이고 있다.
메타데이터 저널링 프로토콜에서도 비슷한 타임라인이 나타난다. 데이터 쓰기와 트랜잭션 시작 + 저널 내용 쓰기는 논리적으로 동시에 요청될 수 있음에 유의하라. 다만 이것들은 트랜잭션 종료가 요청되기 전에는 완료되어야 한다.
마지막으로 타임라인 내의 각 쓰기에 대해 표시된 완료 시간은 임의적이라는 것에 유의하자. 실제 시스템에서 완료 시간은 I/O 서브시스템에 의해 결정되는데, 이때 쓰기는 성능을 향상시키도록 재정렬된다. 이러한 정렬에 대해 확신할 수 있는 것은, 이것들이 프로토콜의 정확성을 따르도록 되어있다는 것 뿐이다.
4. Solution #3: Other Approaches
지금까지 fsck과 저널링이라는, 파일 시스템의 메타데이터를 일관적으로 관리하기 위한 두 선택지에 대해 설명했다. 하지만 이 두 접근법들이 있는 것은 아니다. 다른 것으로는 Soft Update라 불리는 방식도 있다. 이 방식은 디스크 상 구조들이 비일관적 상태로 남아있지 않도록 모든 파일 시스템으로의 쓰기를 정렬한다. 예를 들면 가리켜지는 데이터 블럭을 그것을 가리키는 아이노드 이전에 씀으로써 아이노드가 쓰리게 데이터를 가리키지 않음을 보장할 수 있다. 파일 시스템 내 다른 모든 구조들에 대해서도 비슷한 규칙을 적용할 수 있다. 하지만 Soft Updates를 구현하는 일은 쉬운 일이 아니다. 위에서 설명된 저널링 레이어의 경우 실제 파일 시스템 구조에 대한 상대적으로 적은 지식으로도 구현될 수 있지만, Soft Updates는 각 파일 시스템의 자료 구조에 대한 복잡한 지식을 필요로 하고, 시스템에 상당한 복잡성을 추가하기 때문이다.
다른 방식은 copy-on-write(COW)라 불리는 것으로, 많은 유명 파일 시스템들에서 쓰인다. 이 테크닉은 절대 파일이나 디렉토리를 바로 덮어쓰지 않고, 새 업데이트들을 이전에 쓰이지 않던 디스크 상 위치에 둔다. 여러 업데이트들이 완료되면 COW 파일 시스템은 파일 시스템의 루트 구조에 새롭게 업데이트된 구조를 가리키는 포인터들이 포함되도록 수정한다. 이 테크닉에 대해서는 이후의 장에서 로그-기반 파일 시스템(LFS)에 대해 공부할 때 더 깊게 공부할 것이다. (LFS는 COW의 초기 예 중 하나다.)
다른 방식은 Wisconsin에서 개발한 것으로, backpointer-based consistency(BBC)라 불린다. 이 테크닉에서는 쓰기 작업들 사이의 정렬이 없다. 일관성을 달성하기 위해서는 추가적인 백 포인터(back pointer)가 시스템 내 모든 블럭에 추가된다. 예를 들어 각 데이터 블럭은 해당 블럭이 속하는 아이노드에 대한 참조를 가지고 있다. 파일에 접근할 때, 파일 시스템은 포워드 포인터(아이노드, 또는 직접 블럭에 있는 주소)가 거꾸로 자기 자신을 참조하는 블럭을 가리키고 있는지를 확인함으로써 파일이 일관적인지 결정한다.
마지막으로는 optimistic crash consistency이라 불리는 것으로, 저널 프로토콜에서 디스크 쓰기가 완료되기를 기다리기 위해 쓰이는 시간을 줄이기 위한 테크닉이다. 이 방식은 트랜잭션 체크섬(transaction checksum)의 일반화된 형태를 사용함으로써 최대한 많은 쓰기 요청을 발생시키며, 일어날 수 있는 비일관성을 탐지하기 위한 여러 다른 테크닉들을 포함한다. 어떤 워크로드에 대해, 이 테크닉은 상당한 성능 개선을 이뤄낼 수 있었다. 하지만 제대로 기능하기 위해서는 조금 다른 디스크 인터페이스를 필요로 한다.
