
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
OS는 공간 할당 문제를 해결하기 위해 두 가지의 접근법을 사용한다. 첫 번째 접근법은 세그먼테이션에서 사용했던 것과 같이 공간을 다양한 사이즈의 조각들로 나누는 것이다. 하지만 이 접근법은 내재적으로, 공간이 단편화되어 할당이 시간이 지남에 어려워지는 문제를 가진다.
다른 접근 방법은 공간을 고정된 크기의 조각들로 나누는 것이다. 이를 페이징(paging) 이라 부른다. 페이징은 프로세스의 주소 공간을 여러 개의 다양한 사이즈의 조각들로 나누지 않고, 페이지(page) 라 부르는 고정된 사이즈의 단위로 나눈다. 가상 메모리의 페이지에 대응하는 물리 메모리의 슬롯들을 페이지 프레임(page frame) 이라 부른다.
어떻게 메모리를 페이지들로 가상화할 수 있을까? 그 기본 테크닉들에는 어떤 것들이 있고 어떻게 최소한의 공간적, 시간적 오버헤드만으로 그 테크닉들이 잘 작동하게 할 수 있을까?
1. A Simple Example And Overview
실제 주소 공간은 훨씬 더 크겠지만, 여기에서는 아래와 같이 작은 주소 공간을 사용한다고 하자. 이 주소 공간은 총 64 바이트로, 4개의 16바이트 페이지들로 구성되어 있다.

물리 메모리 또한 여러 개의 고정된 사이즈의 스롯들로 이루어져 있는데, 여기에서는 8개의 페이지 프레임들로 이루어져 있다. 여기에서 볼 수 있듯 가상 주소 공간의 페이지들은 물리 메모리의 서로 다른 곳에 위치해있다. OS 또한 자신을 위해 물리 메모리의 일부를 사용하고 있다.
페이징은 앞서 다뤄온 접근법들에 비해 많은 이점들을 가지고 있는데, 그 중 가장 큰 것은 융통성(flexibility) 이라 할 수 있을 것이다. 제대로 개발된 페이징 접근법을 이용하면 시스템은 프로세스가 주소 공간을 어떻게 쓰는지와는 상관 없이 주소 공간의 추상화를 효과적으로 지원할 수 있다.
페이징의 다른 이점은 가용 공간 관리가 간단하다는 것이다. 예를 들어 위와 같이 8개의 페이지 프레임을 가지는 물리 메모리에 64 바이트 주소 공간을 위치시키려면, OS는 간단히 4개의 가용 페이지들을 찾아내기만 하면된다. OS는 모든 가용 페이지들에 대한 가용 리스트를 가지고 있을 것이고, 이 중에서 최초의 4개를 꺼내서 제공하기만 하면 된다.
주소 공간의 각 가상 페이지들이 물리 메모리의 어디에 위치하고 있는지를 기록하기 위해, OS는 페이지 테이블(page table) 이라 불리는 프로세스 별 자료 구조를 사용한다. 페이지 테이블의 주된 역할은 주소 공간의 각 가상 페이지의 주소 변환을 저장해, 각 페이지들이 물리 메모리의 어디에 위치하고 있는지를 알려 주는 것이다.
이 페이지 테이블이 프로세스 별로 만들어지는 자료 구조라는 것은 중요하다. 만약 위 예시에서 다른 프로세스도 실행된다면, OS는 이를 위해 다른 페이지 테이블을 관리해야 할 것이고, 그 가상 페이지들 또한 다른 물리적 페이지에 매핑될 것이다.
주소 변환
프로세스가 생성한 가상 주소를 변환하기 위해서는, 우선 이를 가상 주소 번호(virtual address number, VPN) 와 페이지 내의 오프셋(offset) 의 두 구성 요소로 분할해야 한다. 위 예시에서는 가상 주소 공간이 64 바이트이기 때문에, 가상 주소는 6 비트를 사용하면 된다. 우리는 이미 페이지의 크기가 16 바이트라는 것을 알고 있으므로, 페이지 내의 오프셋을 나타내기 위해서는 4비트를 사용하며, 총 4개의 페이지를 서로 구별하기 위해서는 상위의 2비트를 사용한다.
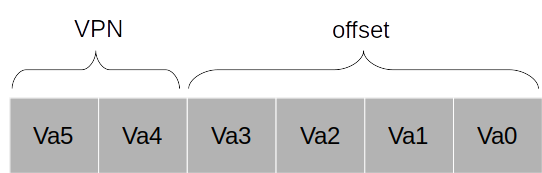
프로세스의 가상 주소 21이 가리키는 위치에 저장된 값을 레지스터에 복사한다고 해보자. 21을 이진수로 바꾸면 010101이 된다.
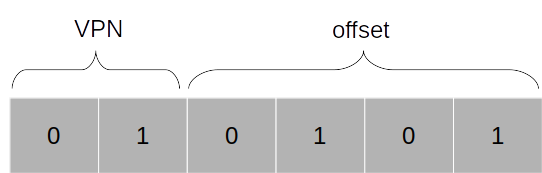
앞의 두 비트는 페이지의 번호, 뒤의 네 비트는 페이지 내의 오프셋이므로, 우리는 첫 번째 가상 페이지에 상응하는 물리 프레임의 5번째 오프셋에서 해당 값을 불러 와야 한다. 각 가상 페이지 번호에 해당하는 물리 프레임의 번호는 페이지 테이블에 저장되어 있다. 그 번호가 7이라고 한다면, 가상 주소는 다음과 같이 실제 주소로 변환된다. 가상 주소에서나 물리 주소에서나 오프셋은 동일하다는 점에 주목하자.
2. Where Are Page Table Stored?
문제는 페이지 테이블은 앞서 논의했던 세그먼트 테이블이나 베이스-바운드 쌍보다도 훨씬 더 크다는 점이다. 예를 들어 전형적인 32 비트의 주소 공간과 4KB의 페이지를 사용한다고 해보자. 페이지의 크기가 4KB이므로 하위 12비트는 오프셋을, 나머지 20 비트는 페이지의 번호를 나타내기 위해 사용한다.
20비트의 VPN을 사용한다는 것은 OS가 각 프로세스 별로 개의 주소 변환을 관리해야한다는 것이다. 만약 각 페이지 테이블 엔트리(page table entry, PTE) 에 물리 주소와 여러 정보들을 저장하기 위해 4바이트를 써야 한다면, 이는 각 페이지 테이블마다 4MB의 메모리를 사용해야 한다는 것이다. 만약 100개의 프로세스가 돌아가고 있다면 OS는 주소 변환을 위해 400MB의 메모리를 필요로 한다는 말이다.
이처럼 페이지 테이블은 너무나 크기 때문에, 우리는 현재 실행 중인 프로세스의 페이지 테이브들을 MMU와 같은 곳에 저장하지 않고, 메모리의 어딘가에 저장한다. 지금은 페이지 테이블이 OS가 관리하는 물리 메모리에 저장된다고 가정하자.
3. What's Actually In The Page Table?
페이지 테이블은 그저 가상 주소를 물리 주소를 매핑하기 위해 사용되는 자료 구조일 뿐이다. 가장 간단한 형식은 선형 페이지 테이블(linear page table) 로, 그냥 배열이다. OS는 이 배열을 VPN으로 인덱싱하고 이 인덱스를 이용해 접근하는 PTE에 담긴 PFN을 찾는다. 지금은 이 간단한 자료 구조를 사용하도록 하자. 나중에는 페이징과 관련한 문제들을 해결하기 위해 좀 더 발전한 자료 구조들을 사용하게 될 것이다.
Valid Bit
PTE 안에는 물리 프레임 주소를 포함해 여러 가지 정보를 담은 비트들이 있다. 그 중 유효 비트(valid bit) 는 특정 주소 변환이 유효한지를 나타내기 위해 사용된다. 예를 들어 프로그램이 실행되기 시작할 때, 이는 코드와 힙을 주소 공간의 한 쪽 끝에 가지고, 스택은 다른 한 쪽에 가지고 있을 것이다. 그 사이의 사용되지 않은 모든 공간은 invalid로 마크되며, 만약 프로세스가 그 메모리에 접근하려고 한다면 이는 OS에 트랩을 발생시키게 될 것이다.
그러므로 유효 비트는 성긴 주소 공간(sparse address space) 을 지원하기 위한 중요한 요소다. 주소 공간 내의 사용되지 않는 모든 페이지들을 간단히 invalid로 마크함으로써, 우리는 해당 페이지들에 대해 물리 프레임을 할당할 필요가 없어지고, 따라서 많은 메모리를 절약할 수 있다.
Protection Bit
보호 비트는 페이지가 읽을 있는지, 쓸 수 있는지, 실행될 수 있는지를 나타낸다. 만약 페이지에 이 비트들에 의해 허용되지 않은 방식으로 접근하려 한다면 이 또한 OS에 트랩을 발생시킬 것이다.
이외에도 여러 비트들이 있다.
- Present Bit : 해당하는 페이지가 물리 메모리에 있는지 디스크에 있는지를 나타낸다.
+ 이후에 배울 스왑(swap) 에서 중요하게 사용된다. - Dirty Bit : 해당하는 페이지가 메모리에 올라온 후 수정된 적이 있는지를 나타낸다.
- Reference Bit : 해당 페이지가 접근된 적이 있는지를 추적하기 위해 사용된다.
+ 이후에 배울 페이지 교체(page replacement) 에서 사용된다
4. Paging: Also Too Slow
메모리 안의 페이블은 너무 클 수 있고, 따라서 이와 관련된 작업들도 너무 느려질 수 있다. 가상 주소(21)를 통해 물리 주소의 데이터(117)를 가져오는 예를 다시 살펴보자.
VPN = (VirtualAddress & VPN_MASK) >>SHIFT
PTEAddr = PageTableBaseRegister + (VPN * sizeof(PTE))여기서 VPN_MASK는 0x30(110000)이고, SHIFT는 4다. 가상 주소 010101은 마스킹되어 010000이 되고, 네 자리 오른쪽으로 시프트된다. 이렇게 얻은 01, 즉 가상 페이지 번호 1을 페이지 테이블의 인덱스로 이용해, 페이지 테이블의 물리 주소에서의 시작 위치를 알려주는 페이지 테이블 베이스 레지스터(page table base register) 에 더해 해당 PTE의 값을 불러온다.
물리 주소가 알려지면 하드웨어는 PTE를 메모리로부터 가져와 PFN을 추출한 후, 여기에 가상 주소에서 얻은 오프셋을 더해 원하는 물리 주소를 만든다. 구체적으로, PFN은 SHIFT만큼 시프트되고 여기에 오프셋을 OR 연산해 얻어진다.
offset = VirtualAddress & OFFSET_MASK
PhysAddr = (PFN << SHIFT) | offset이로써 하드웨어는 원하던 데이터를 가져올 수 있게 된다.
문제는 지금 페이지 테이블이 메모리 안에 위치하고 있기 때문에, 페이징을 사용하는 경우, 원하는 데이터를 가져오기 전에 해당 데이터가 담긴 물리 주소로 변환하기 위해 한 번, 실제로 그 데이터를 가져오기 위해 한 번, 총 두 번의 메모리 접근이 이루어져야 한다는 것이다. 추가적인 메모리 접근은 비용이 많이드는 작업이기 때문에, 프로세스를 두 배, 혹은 그 이상으로 느리게 만든다.
하드웨어와 소프트웨어 양쪽에 대한 세심한 설계 없이는, 페이지 테이블은 시스템을 너무 느리게 돌아가게 하며, 메모리도 너무 많이 쓰게 한다.
5. Summary
페이징은 이전의 접근법들과 비교해, 많은 이점들을 가지고 있다.
1. 페이징은 메모리를 고정된 단위로 나누기 때문에 외부 단편화를 일으키지 않는다.
2. 가상 주소 공간을 sparse하게 사용하기 때문에 좀 더 융통성이 있다.
하지만 페이징을 사려 깊지 않게 구현하는 것은 시스템을 느리게 만들고 메모리도 낭비하게 만든다. 이 문제들을 어떻게 해결할지는 다음 장에서 다룬다.
