
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
페이지 테이블은 너무 크고 메모리를 너무 많이 잡아 먹는다. 예를 들어 32비트 주소 공간, 4KB 페이지, 4바이트 페이지 테이블 엔트리의 선형 페이지 테이블을 사용한다고 해보자. 한 페이지 테이블은 4MB가 되고 페이지 테이블은 프로세스마다 할당되므로, 이 경우 한 프로세스마다 페이지 관리를 위해서만 4MB를 쓰게 된다. 오늘날의 시스템은 수 백 개의 프로세스들을 동시에 사용하기 때문에 페이지 테이블을 위해서만 수백 메가바이트를 쓰게 되는 것이다.
1. Simple Solution: Bigger Pages
페이지 테이블의 크기를 줄이기 위해서는 더 큰 페이지를 사용하는 방법을 사용할 수 있다. 이번에는 똑같이 32 비트의 주소 공간을 사용하되, 페이지의 크기는 16KB로 늘려보자. 한 페이지의 크기가 16KB=B이므로 오프셋을 위해서는 14비트를 사용하고, 나머지 18비트는 VPN을 위해 사용한다.
따라서 페이지 테이블에는 개의 엔트리가 생긴다. 각 PTE에 똑같이 4B를 사용하면 한 페이지 테이블은 총 1MB를 사용한다. 페이지의 크기를 늘려 페이지 테이블의 크기를 줄일 수 있는 것이다.
하지만 이 접근법에는 큰 페이지를 사용함으로써, 각 페이지에 낭비가 생길 수 있다는 것, 즉 내부 단편화가 발생할 수 있다는 문제가 있다.
2. Hybrid Approach: Paging and Segments
1KB 페이지 16개로 이루어진 16KB 주소 공간을 사용한다고 해보자. 이 중 코드 페이지 하나(VPN 0)은 물리 페이지 10, 힙 페이지 하나(VPN 4)는 물리 페이지 23, 두 개의 스택 페이지(VPN 10, 15)는 각각 물리 페이지 28, 4에 매핑되어 있다고 가정한다. 여기서 눈여겨 볼 점은 페이지 테이블의 대부분은 사용되지 않는다는 것이다.
이 접근법에서는 프로세스의 전체 주소 공간을 위해 하나의 페이지 테이블을 사용하지 않고, 논리적 세그먼트마다 하나의 페이지 테이블을 갖게 한다. 위 예시로 따지면 코드, 힙, 스택을 위해 총 3개의 페이지 테이블을 사용하게 되는 것이다.
세그먼테이션에서 베이스 레지스터와 바운드 레지스터를 썼던 것을 상기해보자. 지금의 접근법에서도 마찬가지의 구조를 사용하는데, 단 여기서 베이스는 세그먼트 그 자체가 아니라 세그먼트의 페이지 테이블의 물리 주소를 가지고 있으며, 바운드는 페이지 테이블의 끝을 가리키기 위해 사용된다.
32비트 가상 주소, 4KB 페이지를 사용하고 주소 공간은 네 개의 세그먼트로 나뉘어진다고 하자. 주소가 어떤 세그먼트를 가리키고 있는지를 결정하기 위해서는 주소의 상위 2비트를 사용하며, 00은 사용되지 않고, 01은 코드, 10은 힙, 11은 스택을 위해 사용된다고 가정한다.
하드웨어에는 코드, 힙, 스택을 위한 세 개의 베이스-바운드 쌍이 있다고 하자. 프로세스가 실행되면 각 세그먼트의 베이스 레지스터는 해당 세그먼트의 선형 페이지 테이블의 물리 주소를 가져야 하므로, 문맥 전환이 일어나면 이 레지스터들은 새로이 실행되는 프로세스의 페이지 테이블들의 위치를 반영하도록 바뀌어야 한다.
TLB 미스가 일어나면 하드웨어는 세그먼트 비트를 이용해 어떤 베이스-바운드 쌍을 쓸지를 결정하고, 이후에는 그 안의 물리 주소를 이용해 다음과 같이 VPN과 조합해서 PTE 의 주소를 만들어 낸다.
SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT
VPN = (VirtualAddress & VPN_MASK) >> VPN_SHIFT
AddressOfPTE = Base[SN] + (VPN * sizeof(PTE))각 세그먼트의 바운드 레지스터는 세그먼트에서 유효한 페이지의 최댓값을 가지고 있다. 예를 들어 만약 코드 세그먼트가 0, 1, 2페이지를 쓰고 있다면, 코드 세그먼트 페이지 테이블은 세 엔트리만을 가질 것이고, 바운드 레지스터는 3이 될 것이다. 만약 이 범위를 넘어선 메모리 접근이 일어난다면 예외가 발생하고 프로세스는 종료된다. 스택과 힙 사이의 할당되지 않은 페이지들은 페이지 테이블에서 공간을 차지하지 않으며, 따라서 많은 공간이 절약된다.
하지만 이 접근법은 다음과 같은 문제를 가지고 있다.
- 세그먼테이션을 써야 한다.
- 세그먼테이션은 융통성이 부족하다는 문제를 가지고 있다.
- 외부 단편화 문제가 발생한다.
- 메모리가 페이지 크기의 단위로 관리되고는 있지만 페이지 테이블 자체의 크기는 임의적이기에, 메모리에서 가용 공간을 찾는 일이 더 복잡해진다.
3. Multi-level Page Tables
페이지 테이블에서 사용되지 않는 공간들을 메모리에 담지 않고 버리는 다른 접근법은 없을까? 멀티 레벨 페이지 테이블(multi-level page table)은 선형 테이블을 트리와 같은 구조로 바꿈으로써 이를 효과적으로 달성하며, 때문에 현대의 많은 시스템들은 이 접근법을 사용하고 있다.
멀티 레벨 페이지 테이블은 페이지 테이블을 페이지 크기의 단위들로 나누되, 해당 페이지 테이블의 엔트리로 들어가있는 페이지 전체가 유효하지 않다면 해당 페이지 테이블에는 페이지를 할당하지 않는다. 페이지 테이블의 페이지들이 유효한지를 확인하기 위해서는 페이지 디렉토리(page directory)라 부르는 새로운 구조를 사용하는데, 페이지 디렉토리는 페이지 테이블의 페이지가 어디 있는지, 그리고 페이지 테이블의 전체 페이지가 유효하지 않은 페이지들을 포함하고 있는지의 여부를 담고 있다.
2-레벨 테이블에서 페이지 디렉토리는 페이지 테이블마다 하나의 엔트리를 가진다. 페이지 디렉토리는 페이지 디렉토리 엔트리(page directory entries, PDE)의 수를 포함하며, PDE는 유효 비트와 PFN 등을 포함한다. 다만 여기서 유효 비트는 해당 페이지 테이블의 적어도 한 페이지가 유효한지를 표현하는 데 쓰인다.
멀티 레벨 페이지 테이블은 다음과 같은 이점들을 가진다.
1. 멀티 레벨 페이지 테이블은 사용하고 있는 주소 공간의 양에 비례해 페이지 테이블 공간을 할당한다.
- 사용되지 않는 공간에 대해서는 페이지 테이블 공간이 할당되지 않으므로, 일반적으로 더 작은 공간을 사용하게 된다.
2. 제대로 만들어지면, 페이지 테이블의 각 부분이 페이지에 딱 맞아 떨어지기 때문에 메모리 관리가 더욱 쉽다.
- OS는 더 많은 공간을 할당해야 할 때, 단순히 다음 가용 페이지를 찾아 사용하기만 하면 된다.
- 간단한 선형 페이지 테이블을 사용하는 경우, 연속적인 가용 공간을 찾는 일은 메모리가 커짐에 따라 어려워진다.
다만 멀티 레벨 페이지 테이블에는 다음과 같은 비용이 발생하기도 한다.
1. TLB 미스가 일어났을 때, 정확한 주소 변환 테이블을 얻기 위해서는 메모리에 두 번 접근해야 한다.
- 공간적으로는 효율적이지만, TLB 미스가 일어났을 때에는 더 큰 시간적 비용을 가진다.
2. 복잡함
- 하드웨어에 의해 관리되든 소프트웨어에 의해 관리되든, 간단한 페이지 테이블을 사용할 때보다는 훨씬 복잡한 구조를 가진다.
A Detailed Multi-Level Example
16KB의 작은 주소 공간을 사용한다고 가정하자. 페이지는 64B를 사용한다. 따라서 가상 주소는 14 비트를 사용하며, 이중 6비트는 오프셋, 나머지 8비트는 VPN을 위해 사용된다. 만약 선형 페이지 테
이블을 사용한다면 총 엔트리의 개수는 개가 된다.
2-레벨 페이지 테이블을 만드려면 우선 선형 페이지 테이블을 페이지 사이즈의 단위로 나눠야 한다. 전체 테이블이 256 엔트리를 가지고 있고, 각 엔트리가 4B의 크기를 가진다고 한다면, 페이지 테이블은 1KB의 크기를 가진다. 우리는 64B의 크기를 갖는 페이지를 사용하므로 1KB의 페이지는 16개의 64B 페이지들로 나뉘어지며, 각 페이지는 16개의 PTE를 가진다.
그렇다면 어떻게 가상 주소를 이용해 페이지 디렉토리의 인덱스와 페이지 테이블의 인덱스를 찾도록 할 수 있을까? 페이지 디렉토리는 페이지 테이블마다 하나의 엔트리를 가지므로 총 16개의 엔트리를 가진다. 따라서 이를 구분하기 위한 상위 4비트는 페이지 디렉토리의 인덱스를 나타내는 데에 사용한다.
PDEAddr = PageDirBase + (PDIndex * sizeof(PDE))만약 페이지 디렉토리가 유효하지 않은 것으로 표시되어 있다면, 해당 접근은 유효하지 않은 것이므로 예외를 일으킨다. 반대로, 만약 PDE가 유효하면 나머지 4비트는 페이지 테이블 내에서 원하는 페이지를 찾는 데 사용한다.
PTE= (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))지금까지는 두 레벨을 가지는 멀티 레벨 페이지 테이블만을 사용해왔지만, 더 깊은 트리를 사용하는 것도 가능하다.
4. Inverted Page Tables
역 페이지 테이블(inverted page table)을 이용하면 공간을 더 줄일 수 있다. 여기서는 한 프로세스에 여러 개의 페이지 테이블을 할당하기보다는, 시스템의 각 물리 페이지를 엔트리로 가지는 하나의 페이지 테이블만을 사용한다. 이 엔트리는 어떤 프로세스가 이 페이지를 쓰고 있고, 프로세스의 어떤 가상 페이지가 물리 페이지에 매핑되어있는지를 알려준다.
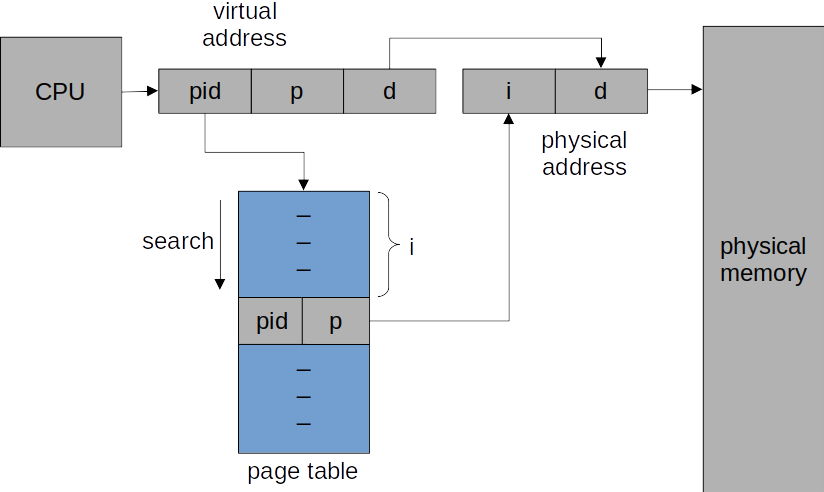
이제는 이 자료 구조에서 해당하는 엔트리를 찾는 게 문제가 되는데, 선형으로 스캔하는 건 너무 비용이 많이 들기 때문에, 보통은 해시 테이블을 사용한다.
5. Swapping the Page Tables to Disk
지금까지는 페이지 테이블이 커널 소유의 물리 메모리에 위치해있다고 가정했다. 물론 지금까지 페이지 테이블이 메모리에서 차지하는 공간의 크기를 줄이려고 하긴 했지만, 그 크키는 여전히 너무 클 수도 있다.
그래서 어떤 시스템들은 페이지 테이블을 커널의 가상 메모리에 위치시켜, 메모리에 여유가 부족해지면 페이지 테이블의 일부를 디스크로 스왑시킨다. 이와 관련한 내용은 이후의 장에서 다루게 될 것이다.
6. Summary
페이지 테이블을 구현하는 데에는 시간과 공간의 trade off가 있다. TLB 미스를 더 빠르게 처리하기 위해서는 페이지 테이블의 크기를 키울 수 있고, 페이지 테이블의 크기를 줄이면 TLB 미스를 처리하기 위한 시간이 오래 걸린다.
