
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
메모리가 거의 남아 있지 않은 경우, 이 메모리 압력(memory pressure)은 OS가 실행될 페이지를 위한 공간을 만들도록 페이지들을 디스크로 쫓아내게 만든다. 이때 어떤 페이지를 쫓아낼지는 OS의 페이지 교체 정책에 들어가있다.
1. Cache Management
메인 메모리가 시스템 내 모든 페이지의 부분집합을 가지고 있다고 할 때, 이는 시스템의 가상 메모리 페이지의 캐시와 같은 것으로 생각할 수 있다. 그러므로 교체 정책의 목표는 캐시 미스의 수를 최소화하는 것이라고 할 수 있다.
캐시 히트와 미스의 수를 아는 것은 프로그램의 평균 메모리 접근 시간(average memory access time, AMAT)을 계산할 수 있게 한다. 구체적으로는, 이 값들이 주어질 때 프로그램의 AMAT은 다음과 같이 계산된다.
여기서 은 메모리에 접근하는데 걸리는 비용, 는 디스크에 접근하는 비용, 는 캐시 미스의 확률이다.
예를 들어 256 바이트의 페이지를 쓰는 4KB 주소 공간을 생각해보자. 가상 주소는 4비트의 VPN과 8비트의 오프셋으로 이루어져있다. 따라서 프로세스는 총 16개의 가상 페이지들에 접근할 수 있다. 프로세스가 다음의 0x000, 0x100, ..., 0x900의 메모리 참조를 만들어 냈다고 해보자. 이 가상 주소들은 주소 공간 내의 열 개 페이지의 첫 번째 바이트를 말한다. 가상 페이지 3을 제외한 나머지의 페이지들은 이미 메모리에 있다고 해보자. 이 경우 히트율은 90%가 되고 미스율은 10%가 된다.
AMAT를 계산하려면 메모리에 접근하는 비용과 디스크에 접근하는 비용을 알아야 한다. 메모리 접근 시간을 100ns, 디스크 접근 시간을 10ms라 가정한다면, AMAT은 가 된다. 만약 히트율이 99.9%로 오르게 된다고 가정한다면 AMAT은 가 된다. 이전에 비해 약 100배 정도 빨라진 것이다.
2. The Optimal Replacement Policy
특정 교체 정책이 잘 작동하는지를 이해하기 위해서는 이를 최적 교체 정책과 비교해보는 것이 좋을 것이다. 최적의 교체 정책은 전체적으로 최소의 미스를 만든다. Belady는 가장 먼 미래에 접근될 페이지를 교체하는 것이 가장 적은 캐시 미스를 내는 최적의 정책임을 보였다. 간단한 예제를 통해 이 정책에 대해 알아보자.
프로그램이 다음의 가상 페이지들에 순서대로 접근한다고 해보자.
당연히 첫 번째 세 접근은 미스가 나는데, 캐시가 비어있는 상태로 시작하기 때문이다. 이러한 미스를 cold-start miss 또는 compulsory miss라고 부른다. 이후 페이지 0, 1을 참조하면 캐시 히트가 일어난다. 만약 3번 페이지에 접근하려 하면 미스가 뜨지만, 지금은 캐시가 꽉 차 있어서 교체가 일어나야 한다. 최적 정책에 따르면 가장 먼 미래에 참조될 페이지를 교체해야 하므로 2번이 교체된다.
캐시의 히트율을 계산해보면 54.5%가 되는데, 필연적으로 일어나는 compulsory miss를 무시하고 계산한다면 85.7%가 된다. 문제는 미래에 어떤 페이지가 어떻게 접근될지에 대해 알 수 있는 방법이 없다는 것이다. 최적 정책은 실제 개발될 정책에 대한 상한선을 제공하는 역할만을 수행할 수 있다.
3. Simple Policies
FIFO
FIFO에서 페이지들은 큐로 들어가고, 교체가 일어날 때는 가장 먼저 들어간 페이지가 쫓겨난다. FIFO는 구현이 간단하다는 점에서 큰 강점을 가지지만, 큐에 들어있는 각 페이지들이 가지는 중요성의 차이를 판단하지 않는다는 단점을 가진다. 교체가 일어날 때 쫓겨나게 될 페이지가 다른 페이지들에 비해 자주 사용되는 것이라 하더라도, FIFO를 사용하는 경우 해당 페이지는 그냥 쫓겨난다.
Belady's Anomaly
일반적으로는 캐시의 크기가 늘어나면 히트율은 증가할 것으로 기대되지만, 특정한 입력에 대해서는 반대로 히트율이 내려가는 결과가 나타날 수 있다. 예를 들어 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5의 순서로 메모리 참조 스트림이 있고, FIFO를 사용한다고 해보자. 캐시 사이즈가 3일 때와 4일 때를 비교해보면 히트율이 오히려 내려감을 확인할 수 있다.
Random
이 접근법은 메모리 압력이 있을 때 임의의 페이지를 뽑아 쫓아낸다. 구현하기에는 간단하지만, 사실 어떤 블럭을 쫓아낼 것인지에 대한 고려를 하지 않는 것이라고도 할 수 있다. 이 접근법이 어떻게 동작하는지는 순전히 운에 기대야하고, 따라서 최적에 가까워질 수도, FIFO보다 안좋아질 수도 있다.
4. Using History: LRU
위와 같은 간단한 접근법들은 곧 다시 참조될 중요한 페이지들을 쫓아낼 수 있다는 공통적인 문제점을 가진다. 스케줄링 정책을 다룰 때와 마찬가지로, 과거의 이력을 바탕으로 미래의 동작을 예측해보도록 하자.
쓸 수 있는 과거의 정보에는 다음과 같은 것들이 있다.
- 빈도: 자주 접근되는 페이지가 있다면 교체되지 않아야할 것.
- 최신성 : 가장 최근에 접근된 페이지는 곧 다시 접근될 것
이는 프로그램이 특정 코드 시퀀스와 자료구조에 자주 접근하는 경향이 있다는 지역성 원리에 바탕하고 있다.
Least-Frequently-Used(LFU)
페이지 교체가 일어날 때를 기준으로, 가장 적게 참조된 페이지를 쫓아낸다.
Least-Recently-Used(LRU)
페이지 교체가 일어날 때, 사용된 지 가장 오래된 페이지를 쫓아낸다.
위와 반대되는 MFU(Most-Frequently-Used), MRU(Most-Recently-Used) 알고리즘들도 있다. 하지만 이들은 지역성을 무시하기 때문에 대부분의 경우 잘 작동하지 않는다.
6. Workload Examples
(1) Workload With No Locality
100개의 서로 다른 페이지들에 지역성 없이 랜덤하게, 총 10000번 접근해야 한다고 하자.
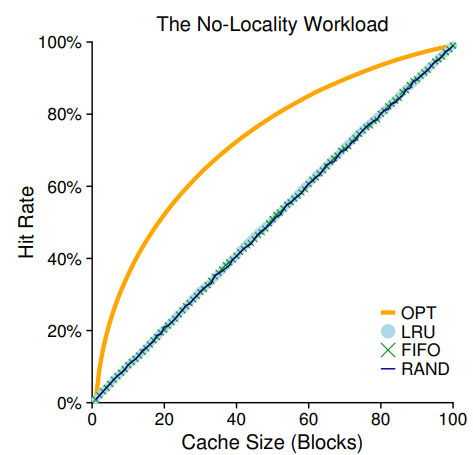
지역성이 없는 경우, LRU, FIFO, Random이 모두 똑같이 작동하며, 히트율은 캐시의 사이즈에 의해 정해지고, 캐시가 전체 워크로드를 담을 수 있을 만큼 커지면, 어떤 정책을 사용하든지 100%의 히트율이 나온다. 최적 정책은 다른 모든 정책들보다 눈에 띄게 잘 작동함을 알 수 있다.
(2) 80-20 Workload
80%의 참조는 페이지 중 20%에 대한 것이고, 나머지 20%의 참조는 80%의 페이지들에 대한 것이라 하자.
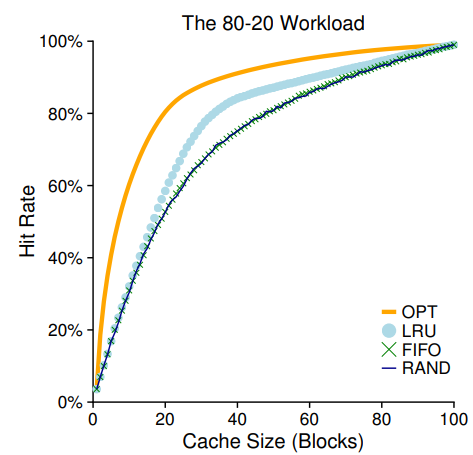
FIFO, Random도 잘 되지만 LRU는 그보다는 더 잘 작동한다. 그런데 LRU를 사용함으로써 얻은 개선 효과가 그렇게 신경 쓸만한 것일까? 미스의 비용이 높은 경우, 히트율이 조금 증가해도 성능에는 큰 차이가 생긴다. 한편 미스 비용이 그렇게 높지 않으면, LRU를 사용함으로써 얻는 성능 향상은 그렇게 크지 않다.
(3) Looping-Sequential Workload
50개의 페이지를 순차적으로 참조하고 총 접근이 10,000회가 될 때까지 이 루프를 반복한다고 해보자.
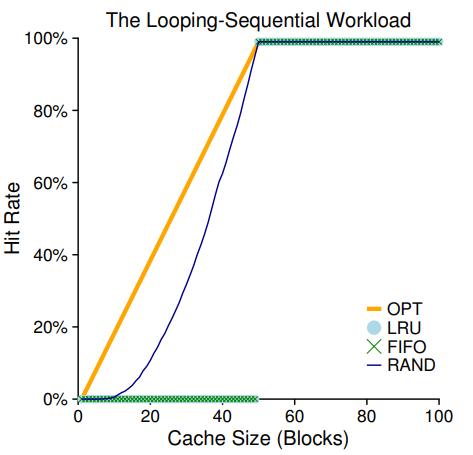
이 경우는 LRU와 FIFO에게 최악의 경우가 된다. 캐시 사이즈가 49가 될 때까지 히트율은 0%가 되고, 오히려 Random 접근이 더 잘 작동함을 볼 수 있다.
7. Implementing Historical Algorithms
과거 이력을 활용하는 알고리즘을 사용하려면 각 페이지 접근마다 해당 페이지를 리스트의 맨 앞으로 가져오기 위한 자료 구조의 갱신이 필요하다. 어떤 페이지가 제일 최근에, 혹은 가장 오래전에 사용됐는지를 추적하려면, 시스템은 매 메모리 참조마다 정산 작업을 해야한다.
이를 빠르게 할 수 있는 한 방법은 하드웨어를 이용하는 것이다. 예를 들어 페이지 접근마다 메모리의 시간 필드를 현재 시간으로 업데이트하고, 페이지를 교체할 때 OS는 해당 필드를 스캔함으로써 LRU 페이지를 찾을 수 있다.
하지만 시스템 내의 페이지 수가 커지면, 실제 LRU 페이지를 찾기 위해 그 큰 시간 필드 배열을 탐색하는 데에 드는 비용 또한 너무 커질 수 있다. 교체하기 위해서 실제로 오래된 페이지를 찾을 필요가 있을까? LRU를 근사적으로 사용할 수는 없을까?
8. Approximating LRU
근사 LRU를 구현하기 위해서는 참조 비트(use bit, reference bit)라 불리는 하드웨어적 장치가 필요하다. 각 페이지는 하나의 참조 비트를 가지고 있고, 이는 메모리 어딘가에 저장된다. 하드웨어는 페이지가 참조될 때마다 참조 비트를 0에서 1로 바꾼다. 다만 비트를 0으로 바꾸는 일은 하드웨어가 아니라 OS가 맡는다.
그럼 어떻게 근사 LRU를 위해 참조 비트를 사용할 수 있을까? 많은 방법들이 있지만, 대표적으로는 클럭 알고리즘(clock algorithm)이 있다. 모든 페이지가 원형 리스트를 이루고 있고, 시곗바늘은 시작할 특정 페이지를 가리키고 있다. 페이지 교체가 일어나야 할 때, OS는 현재 시곗바늘이 가리키고 있는 페이지 가 사용하고 있는 참조 비트를 체크한다. 만약 참조 비트가 1이면, 이는 가 최근에 사용됐다는 것을 의미한다. 이 경우 참조 비트는 0으로 클리어되고, 시곗바늘은 다음 페이지로 넘어간다. 이 알고리즘은 참조 비트가 0인 페이지, 즉 가장 오랫동한 쓰이지 않은 페이지를 찾을 때까지 계속 된다.
이 접근법이 근사 LRU를 위해 참조 비트를 사용하는 유일한 접근법은 아니다. 사실 어떤 접근법이든지 참조 비트를 주기적으로 클리어하고, 참조 비트 1을 가진 페이지와 0을 가진 페이지를 구분해서 어떤 비트를 가진 페이지를 교체할지를 정해줄 수만 있으면 된다.
80-20 워크로드에 대해 클럭 알고리즘을 쓸 경우의 결과는 다음과 같다. 완전히 LRU와 같지는 않지만, 과거 이력을 전혀 쓰지 않는 접근법들에 비해서는 확실히 좋다.
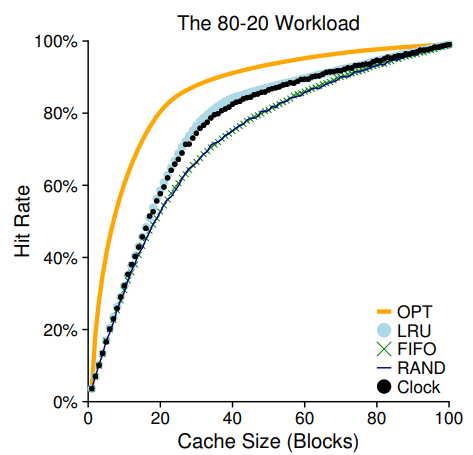
9. Considering Dirty Pages
클럭 알고리즘은 페이지가 메모리에 올라온 이후 수정된 적이 있는지 아닌지를 확인할 수 있게 수정되기도 한다. 그 이유는 수정된 페이지를 디스크로 쫓아내기 위해서는 이를 페이지에 다시 써야 하는데, 이러한 과정의 비용이 크기 때문이다. 만약 수정된 적이 없다면 해당 물리 프레임은 추가적인 I/O 작업 없이 재사용될 수 있으므로, 수정되지 않은 페이지를 쫓아내는 게 수정된 페이지를 쫓아내는 것보다는 낫다.
이 작업을 위해 하드웨어는 수정 비트(modified bit, dirty bit)를 사용한다. 이 비트는 페이지의 데이터가 수정될 때마다 1로 바뀐다. 수정된 클럭 알고리즘은 최근에 사용되지 않았으며, 수정되지도 않은 페이지가 있다면 우선적으로 쫓아내고, 그렇지 않으면 최근에 사용되지 않은, 수정된 페이지를 쫓아내는 식으로 동작한다.
10. Other VM Policies
페이지 교체가 가상 메모리 서브 시스템에서 쓰는 유일한 정책인 것은 아니다. 예를 들어 OS는 언제 페이지를 메모리로 가져올지도 결정해야 하는데, 이 정책은 페이지 선택 정책(page selection policy)이라고 불린다.
대부분의 페이지에 대해서, OS는 간단하게 요구 페이징(demand paging)을 사용하는데, 이는 해당 페이지가 접근될 때 메모리로 가져오는 방법이다. 물론 OS는 어떤 페이지가 곧 사용될지를 예측해서 미리 가져오는 방법을 사용할 수도 있다. 이를 프리페칭(prefetching)이라 부르는데, 이는 성공할 합리적인 가능성이 있는 경우에만 사용되어야 한다. 예를 들어 몇몇 시스템들은 코드 페이지 가 메모리로 들어오면, 코드 페이지 도 곧 접근될 거라 생각해, 해당 페이지도 미리 메모리로 불러들인다.
다른 정책으로는 OS가 페이지를 디스크로 어떻게 써야 하는지를 결정하는 것도 있다. 물론 한 번에 하나씩 쓰는 방식을 사용할 수도 있지만, 많은 시스템들은 여러 쓰기 작업들을 보류해 모아두고 한 번에 디스크에 쓴다. 이를 쓰기 클러스터링(clustering) 또는 쓰기 그룹핑(grouping)이라 하는데, 디스크 드라이브의 특성상 이는 더 효율적으로 동작한다. 하나의 큰 쓰기 작업이 많은 작은 쓰기 작업보다 효율적이기 때문이다.
11. Thrashing
메모리가 과도하게 할당되어 현재 실행 중인 프로세스들이 요구하는 메모리가 사용가능한 물리 메모리의 양을 초과하는 경우, 시스템은 끊임없이 페이징을 하게 된다. 이렇게 메모리에 충분한 공간이 없어 계속해서 페이징을 하게 되는 것을 가리켜 쓰레싱(thrashing)이라고 한다.
몇몇 초기 OS들은 쓰레싱을 감지하고 처리하기 위한 메커니즘들을 가지고 있었다. 예를 들어 프로세스들의 집합이 주어졌을 때, 시스템은 그 일부는 실행하지 않도록 결정한다. 이렇게 줄어든 프로세스들의 working set은 메모리에 들어가 진행될 수 있게 된다. 이 접근법은 admission control이라고 불린다. 때로는 모든 일들을 한 번에 어설프게 하는 것보다, 적은 일들을 하는 것이 더 나을 수 있다.
몇몇 현대 시스템들은 메모리 오버로드에 대해 더 엄격한 접근법을 사용한다. 예를 들어 리눅스의 몇 버전들은 메모리 초과 킬러를 사용해 메모리가 과도하게 할당된 경우 메모리를 많이 쓰는 프로세스를 찾아 종료시킨다. 이 접근법은 메모리 압력을 줄일 수는 있지만, 중요한 프로세스를 종료시켜버릴 수도 있다는 문제점을 가지고 있기도 하다.
11. Summary
여러 페이지 교체 정책들에 대해 알아봤다. 현대 시스템들은 클럭과 같은 직관적인 LRU 근사 알고리즘을 조금씩 수정해 사용하는데, 스캔 저항성(scan resistance, 전체 메모리를 조회하지 않는 성질)은 많은 현대 알고리즘들에 있어 중요하게 생각되는 부분이다. 스캔-저항 알고리즘은 LRU와 비슷하게 작동하지만, looping-sequential workload의 예에서 본 것과 같은, LRU의 최악의 경우에서의 동작은 피하려 한다.
최근 몇 년 동안 교체 알고리즘의 중요성은 줄어들고 있었다. 메모리 접근 시간에 비해 디스크 접근 시간이 압도적으로 느리기 때문에 디스크로 페이징하는 비용이 너무 컸기 컸기 떄문이다. 이러한 환경에서는 아무리 좋은 교체 알고리즘을 사용하더라도 교체가 잦아지면 시스템이 너무 느려지기 때문에, 가장 좋은 해법은 결국 메모리를 더 구입하는 방법이 될 수 밖에 없었다.
하지만 지금은 SSD와 같이 더 빠른 스토리지 장치들이 쓰이게 되면서 성능비가 바뀌고 있고, 페이지 교체 알고리즘의 부흥도 다시 일어나고 있다.
