
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
락에 대한 내용을 끝내기 전에, 흔히 사용하는 자료 구조들에서 락을 어떻게 사용하는지에 대해 알아보자. 자료 구조에 락을 추가해 여러 스레드들이 쓸 수 있도록 하는 것을 가리켜 해당 구조를 스레드-안전(thread safe)하게 만든다고 말한다. 당연히 이러한 락들이 어떻게 추가되는지는 자료 구조의 정확성과 성능을 결정한다.
특정한 자료 구조가 주어졌을 때, 어떻게 정확하게 동작하게 하면서 락을 추가할 수 있을까? 나아가, 어떻게 자료 구조에 높은 성능을 내게 하면서(여러 스레드가 락에 동시에, 즉 병행적으로 접근할 수 있게 하면서) 락을 추가할 수 있을까?
물론 모든 자료 구조나 메서드들에 병행성을 추가하는 것은 어려운 일이다. 그러므로 여기서는 생각해볼 필요가 있는 것들에는 무엇이 있는지, 추후에 스스로 탐구해볼 때 볼 만한 좋은 소스들에는 무엇이 있는지를 소개하고자 한다.
1. Concurrent Counters
카운터는 가장 간단한 자료 구조 중 하나다. 이는 자주 쓰이는 자료 구조로, 간단한 인터페이스를 가지고 있다. 락을 추가하지 않은 카운터는 다음과 같다.
typedef struc __counter_t {
int value;
} counter_t;
void init(counter_t *c){
c->value = 0;
}
void increment(counter_t *c){
c->value++;
}
void decrement(counter_t *c){
c->value--;
}
int get(counter_t *c){
return c->value;
}동기화되지 않는 카운터는 이와 같이 간단하다. 이 카운터를 스레드-안전하게 만드려면 어떻게 해야할까?
Simple But Not Scalable
typedef struct __counter_t {
int value;
pthread_mutex_t lock;
} counter_t;
void init(counter_t *c) {
c->value = 0;
Pthread_mutex_init(&c->lock, NULL);
}
void increment(counter_t *c) {
Pthread_mutex_lock(&c->lock);
c->value++;
Pthread_mutex_unlock(&c->lock);
}
void decrement(counter_t *c) {
Pthread_mutex_lock(&c->lock);
c->value--;
Pthread_mutex_unlock(&c->lock);
}
int get(counter_t *c) {
Pthread_mutex_lock(&c->lock);
int rc = c->value;
Pthread_mutex_unlock(&c->lock);
return rc;
}이 병행적인 카운터는 간단하고, 잘 작동한다. 사실 이 구현은 가장 간단하고 기본적인 병행적 자료 구조들에 흔한 디자인 패턴을 따르고 있다. 간단하게, 자료 구조를 조작하는 루틴을 호출할 때 획득되고, 콜로부터 리턴할 때 풀리는 락 하나를 추가하는 것이다. 이러한 방식은 모니터(monitor)와 함께 만들어지는 자료 구조와 비슷하다. 모니터를 이용한 자료 구조에서 락은 객체의 메서드를 호출하거나 해당 메서드로부터 리턴할 때 자동으로 획득되고 해제된다.
이제 동작하는 병행적 자료 구조가 만들어지기는 했다. 다음 문제는 성능이다. 만약 이 자료 구조가 너무 느리면, 단순히 락 하나를 추가하는 것 이상의 일들을 해야 한다. 이러한 최적화는 (만약 필요하다면) 이 장의 나머지 토픽으로 다뤄질 것이다. 만약에 자료 구조가 너무 느리지 않다면, 할 일은 끝이다. 단순한데 잘 작동한다면, 더 무언갈 추가할 필요는 없다.
이 간단한 접근법의 성능 대가를 이해하기 위해서는 각 스레드들이 하나의 공유 카운터를 고정된 시간동안 업데이트하는 벤치마크를 실행해보고, 이후에는 스레드의 수도 달리 해본다. 아래의 표는 하나부터 네 개의 스레드가 활성화된 상태일 때, 그리고 각 스레드들이 카운터를 100만회 업데이트 할 때의 전체 시간을 보여준다.
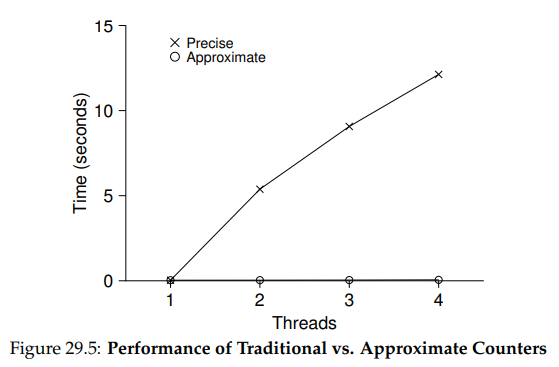
표에서 Precise로 표시된 것들을 보면, 이 동기화된 카운터의 성능이 스레드의 수가 확장됨에 따라 낮아짐을 볼 수 있다. 하나의 스레드를 이용할 때에는 카운터를 100만 번 올리는데에 약 0.03초라는, 아주 적은 시간이 걸렸지만, 두 스레드가 각각 병행적으로 카운터를 100만 번 업데이트할 때에는 5초가 넘는 시간이 걸린다. 이는 스레드가 더 많아짐에 따라 더 나빠진다.
이상적으로는 여러 스레드들이 여러 프로세서에서 돌아가더라도, 하나의 스레드가 한 프로세서에서 작업을 마칠 때 필요한 시간만큼이 소모되는 게 좋을 것이다. 이러한 목표의 달성을 가리켜 완벽한 확장성(perfect scaling)이라 부른다. 더 많은 작업을 해야하더라도, 이 작업을 병렬적으로 수행함으로써 전체 작업을 마치는 데에 걸리는 시간이 증가하지 않는 것이다.
Scalable Counting
연구자들은 확장 가능한 카운터를 어떻게 만들지에 대해 오랫동안 연구해왔다. 확장 가능한 카운터는 큰 의미를 갖는데, 만약 확장 가능한 카운터가 없다면, 리눅스에서 돌아가는 몇몇 작업들은 멀티코어 기기에서 심각한 확장성 문제를 겪을 수 있기 때문이다.
이러한 문제를 해결하기 위해 여러 기법들이 있는데, 근사 카운터(approximate counter)로 알려져있는 한 접근법에 대해 알아보자.
근사 카운터는 하나의 논리적 카운터로 생각되는데, 이는 여러 물리적 카운터(CPU 코어 하나당 하나)와 하나의 전역 카운터로 이루어져있다. 구체적으로, 네 개의 CPU가 있는 기기의 경우에는 네 개의 로컬 카운터가 있고 하나의 전역 카운터가 있다. 이 카운터들에는 추가적으로 락도 있다. (각 로컬 카운터마다 하나, 전역 카운터에 하나)
근사 카운팅의 기본 아이디어는 다음과 같다. 주어진 코어에서 실행되는 스레드가 카운터를 증가시키려 할 때, 이는 그 로컬 카운터를 증가시킨다. 각 CPU는 자신의 로컬 카운터를 가지고 있기 때문에, CPU에 퍼져있는 스레드들은 경쟁 없이 카운터를 업데이트 할 수 있고, 따라서 이 카운터들의 업데이트는 확장 가능하다.
하지만 전역 카운터를 최신으로 유지하기 위해서, 로컬 값들은 주기적으로 전역 락을 얻고 전역 카운터를 로컬 카운터의 값만큼 증가시키는 방식으로, 전역 카운터에 전달되어야 한다. 이렇게 값이 전다로디고 나면 로컬 카운터는 0으로 리셋된다.
이 로컬-전역의 값 이동이 얼마나 자주 발생하는지는 임계값 에 의해 결정된다. 가 작으면, 카운터는 더욱 더 확장 불가능한 카운터와 같이 동작할 것이고, 가 커지면 카운터는 더 확장 가능해지지만 전역 카운터의 값은 실제 카운트와 더 멀어진다. 단순하게 모든 로컬 락과 전역 락을 얻어 실제 값을 얻을 수도 있겠지만, 이는 확장성이 떨어진다.
문제를 더 명확히 하기 위해 다음의 예시를 보자. 이 예시에서 임계값 는 5로 설정되어 있고, 4개의 CPU마다 하나씩, 총 4개의 스레드가 자신의 로컬 카운터 를 업데이트한다. 전역 카운터 값()도 나타나 있고, 시간은 아래로 갈수록 증가한다. 각 스텝마다 로컬 카운터는 증가하는데, 로컬 값이 임계값 에 도달하면 로컬 값은 전역 카운터로 전달되고, 로컬 카운터는 리셋된다.
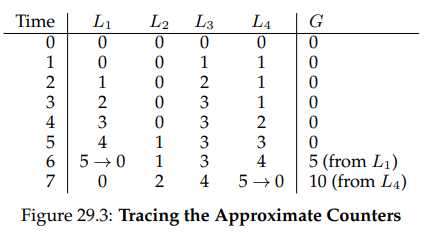
Figure 29.5 그래프의, 'Approximate'로 라벨링된 아래쪽 선은 임계값 가 1024일 때의 근사 카운터의 성능을 보여준다. 성능은 아주 좋다. 네 프로세서에서 일어나는 총 400만 번의 카운터 업데이트는 한 프로세서에서 일어나는 100만 번의 업데이트와 거의 차이가 나지 않는다.
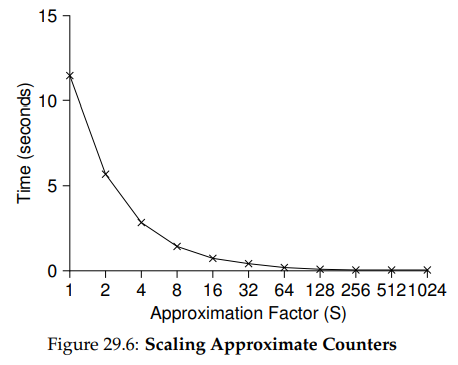
Figure 29.6은 네 CPU에 있는 각 스레드들이 카운터를 100만 번 증가 시킬 때의 임계값 의 중요성을 보여준다. 가 낮으면 성능은 떨어지지만 전역 카운트는 항상 거의 정확하다. 가 높으면 성능은 좋아지지만, 전역 카운트는 실제값보다 최대 CPU수 * 만큼 뒤쳐진다. 이 정확성과 성능 사이의 교환이 근사 카운터가 제공하는 것이다.
근사 카운터의 코드는 대강 다음과 같다. 이게 어떻게 작동하는지를 더 잘 이해하려면 이 코드를 읽고 직접 실행해서 실험해보자.
typedef struct __counter_t {
int global; //global count
pthread_mutex_t glock; //global lock
int local[NUMCPUS]; //local counts per-CPU
pthread_mutex_t llock[NUMCPUS];// per-CPU locks
int threshold; //update freq
} counter_t;
// init: record threshold, init locks, init values
// of all local counts and global count
void init(counter_t *c, int threshold) {
c->threshold = threshold;
c->global = 0;
pthread_mutex_init(&c->glock, NULL);
int i;
for (i = 0; i < NUMCPUS; i++) {
c->local[i] = 0;
pthread_mutex_init(&c->llock[i], NULL);
}
}
// update: usually, just grab local lock and update
// local amount; once it has risen ’threshold’,
// grab global lock and transfer local values to it
void update(counter_t *c, int threadID, int amt) {
int cpu = threadID % NUMCPUS;
pthread_mutex_lock(&c->llock[cpu]);
c->local[cpu] += amt;
if (c->local[cpu] >= c->threshold) {
// transfer to global (assumes amt>0)
pthread_mutex_lock(&c->glock);
c->global += c->local[cpu];
pthread_mutex_unlock(&c->glock);
c->local[cpu] = 0;
}
pthread_mutex_unlock(&c->llock[cpu]);
}
int get(counter_t *c) {
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val; // only approximate!
}2. Concurrent Linked Lists
다음으로는 좀 더 복잡한 자료 구조인 연결 리스트에 대해 알아본다. 이번에도 간단한 접근법부터 시작해보자. 단순함을 위해, 이러한 리스트들이 가져야 하는 몇 가지 루틴들은 제외하고, 병행적인 삽입 및 조회에만 집중하도록 한다.
// basic node structure
typedef struct __node_t {
int key;
struct __node_t *next;
} node_t;
// basic list structure (one used per list)
typedef struct __list_t {
node_t *head;
pthread_mutex_t lock;
} list_t;
void List_Init(list_t *L) {
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
int List_Insert(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
pthread_mutex_unlock(&L->lock);
return -1; // fail
}
new->key = key;
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
return 0; // success
}
int List_Lookup(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
pthread_mutex_unlock(&L->lock);
return 0; // success
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return -1; // failure
}코드에서 볼 수 있듯, 이 코드는 삽입 루틴에 들어갈 때 락을 얻고, 루틴에서 나갈 때 락을 놓아준다. 한 가지 까다로운 이슈는 malloc()이 실패해버리는 경우다. 이 경우 코드는 삽입에 실패하기 전에 락을 풀어줘야 한다.
이런 예외적인 제어 흐름은 상당히 오류에 취약한 것으로 알려져 있다. 리눅스 커널 패치에 대한 최근 연구에 따르면 거의 40%의 버그가 이렇게 자주 사용되지 않는 코드에서 발생한다.
그렇다면 병행 삽입 시의 정확성을 잃지 않으면서도 언락 호출을 추가로 요구하는 실패 경로를 갖지 않게 삽입과 조회 연산을 수정할 수 있을까? 그렇다. 구체적으로는 락과 락 해제가 삽입 코드의 실제 임계 영역만을 둘러 싸고, 조회 코드에서는 공통의 종료 경로를 사용하게 할 수 있다. 전자는 삽입 코드의 일부에는 락이 필요하지 않기 때문에 작동한다. malloc()이 그 자체로 스레드-안전하다고 가정하면, 각 스레드는 경쟁 조건, 혹은 다른 병행성 버그들을 신경 쓸 필요없이 이를 호출할 수 있다. 오직 공유되고 있는 리스트를 업데이트 할 때만 락의 소유가 필요하다. 삽입 코드는 다음과 같이 수정될 수 있다.
int List_Insert(list_t *L, int key) {
// synchronization not needed
node_t *new = malloc(sizeof(node_t));
if (new == NULL) {
perror("malloc");
return -1;
}
new->key = key;
// just lock critical section
pthread_mutex_lock(&L->lock);
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
return 0; // success
}조회 루틴의 경우에는 주 검색 루프에서 해당 키를 찾으면 break를 걸도록 해서, 모든 경우에 하나의 반환 경로를 사용하게 한다. 이렇게 하면 코드 내의 락 획득/해제 지점의 수가 줄어들기에, 의도치 않게 버그가 코드에 들어오는 경우도 줄일 수 있게 된다.
int List_Lookup(list_t *L, int key) {
int rv = -1;
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
rv = 0;
break;
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return rv; // now both success and failure
}Scaling Linked Lists
기본적인 병행적 연결리스트를 얻기는 했지만, 또 확장성에 문제가 있다. 연구자들이 리스트에서 더 많은 병행성을 가능하게 하기 위해 만든 기법 중에는 hand-over-hand locking(또는 lock coupling)이라 불리는 게 있다.
아이디어는 간단하다. 전체 리스트에 대해 하나의 락만을 사용하기보다, 리스트의 각 노드에 락을 추가하는 것이다. 리스트를 순회할 때, 코드는 우선 다음 노드의 락을 얻고 나서 현재 노드의 락을 풀어준다.
개념적으로, hand-over-hand 연결 리스트는 리스트 연산들에 높은 수준의 병행성을 가능케 하기 때문에 괜찮아 보인다. 하지만 실제로는 단순한 단일 락 접근법보다 빠른 구조를 만들기는 어렵다. 왜냐하면 리스트를 순회하면서 각 노드의 락을 얻고 해제하는 경우의 오버헤드는 너무 크기 때문이다. 아주 큰 리스트를 더 많은 스레드를 이용하는 경우에도, 여러 순회가 동시에 이뤄지게 하는 것의 병행성이 단일 락을 얻고 연산을 수행하고 풀어주는 경우보다 빨라지지는 않는다. 아마도 많은 노드들에 하나의 락을 주고 사용하는 하이브리드 방식이 좀 더 연구해볼 만해 보인다.
3. Concurrent Queue
이제는 알겠지만, 자료 구조를 만드는 데에는 한 가지 표준적인 방법이 있다. 큰 락 하나를 추가하는 것이다. 큐에 대한 논의에서는 이러한 접근법은 제외한다.
대신 여기에서는 Michael과 Scott이 설계한, 병행성이 조금 더 높은 큐에 대해 살펴볼 것이다. 이 큐를 위한 자료 구조와 코드는 다음과 같다.
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t head_lock, tail_lock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->head_lock, NULL);
pthread_mutex_init(&q->tail_lock, NULL);
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tail_lock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tail_lock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->head_lock);
node_t *tmp = q->head;
node_t *new_head = tmp->next;
if (new_head == NULL) {
pthread_mutex_unlock(&q->head_lock);
return -1; // queue was empty
}
*value = new_head->value;
q->head = new_head;
pthread_mutex_unlock(&q->head_lock);
free(tmp);
return 0;
}코드를 면밀히 살펴보면 큐의 헤드를 위한 락, 큐의 테일을 위한 락, 총 두 개의 락을 사용하고 있음을 볼 수 있다. 이 두 락을 사용하는 이유는 큐의 삽입 및 제거 연산의 병행성을 가능케 하기 위함이다. 보통의 경우 삽입 루틴은 테일 락에만 접근하고, 제거 루틴은 헤드 락에만 접근한다.
Michael과 Scott이 사용한 한 트릭은 더미 노드를 추가하는 것이다. 이 더미 노드는 헤드와 테일 연산의 분리를 가능케 한다. 더 깊게 공부하려면 코드를 직접 공부하고, 써보고, 실행해보고, 성능을 측정해보라.
큐는 멀티-스레드 응용프로그램에서 흔히 쓰인다. 하지만 락만이 있는 이런 종류의 큐들은 그런 프로그램들이 필요로 하는 것들을 완전히 충족시켜주지 못한다. 더 개발된 큐에는 큐가 비어있거나 꽉 차있는 경우 스레드를 대기시키는 기능이 있어야 한다. 이와 관련한 내용은 다음 장의 조건 변수에서 더 깊이 있게 다루게 될 것이다.
4. Concurrent Hash Table
간단하고, 널리 응용할 수 있는 병행적 자료 구조인 해시 테이블를 끝으로 논의를 마친다. 해시 테이블에서의 크기 재조정에 대해서는 다루지 않는다. 크기 재조정의 경우에는 조금의 작업이 더 필요하다.
#define BUCKETS (101)
typedef struct __hash_t {
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H) {
int i;
for (i = 0; i < BUCKETS; i++)
List_Init(&H->lists[i]);
}
int Hash_Insert(hash_t *H, int key) {
return List_Insert(&H->lists[key % BUCKETS], key);
}
int Hash_Lookup(hash_t *H, int key) {
return List_Lookup(&H->lists[key % BUCKETS], key]);
}이 병행적 해시 테이블은 직관적이다. 이는 이전에 만들었던 병행적 리스트를 사용하고, 놀라울 정도로 잘 작동한다. 이 해시 테이블이 높은 성능을 가지는 이유는, 전체 구조를 위한 단일 락 대신 해시 버킷마다 락들을 사용함으로써, 많은 병행 연산이 일어날 수 있게 하기 때문이다.
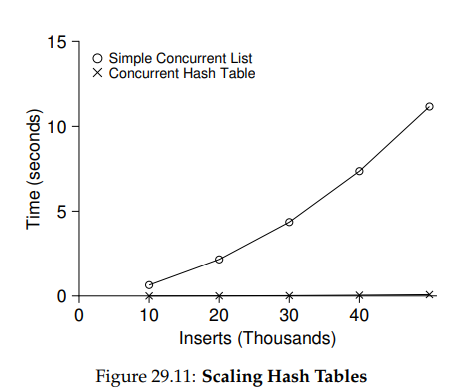
아래의 그래프는 병행 업데이트가 일어나는 경우의 해시 테이블 성능을 보여주며, 비교를 위해서 단일 락을 사용하는 연결 리스트의 성능도 나타나있다. 그래프에서 볼 수 있듯 해시 테이블의 확장성은 매우 높지만, 연결 리스트의 경우에는 그렇지 않다.
5. Summary
지금까지 카운터에서 시작해, 리스트, 큐, 해시 테이블에 이르는 병행적 자료 구조들의 샘플들을 소개했다. 다음의 교훈을 잊지 말자.
- 제어 흐름의 변할 때의 락 획득 및 해제에 주의하자.
- 병행성이 증가가 반드시 성능 증가로 이어지는 것은 아니다.
- 성능은 문제가 발생하지 않으면 굳이 개선시키려 하지 말라.
- 응용 프로그램의 전반적인 성능을 증대시키는 것이 아니라면 뭔가를 더 빠르게 만드는 것에는 아무런 의미가 없다.

똑띠네 똑띠야