
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
이번 파트에 들어가기 전에 우선 입출력 장치의 개념에 대해 소개하고 어떻게 OS가 그것과 상호작용하는지에 대해 알아보자. I/O는 컴퓨터 시스템에서 핵심적인 역할을 한다. 흥미로운 컴퓨터 시스템이 되기 위해서는 입출력이 모두 필요하다.
입출력은 어떻게 시스템에 통합되어야 할까? 일반적인 메커니즘은 무엇이고, 이를 효율적으로 만드려면 어떻게 해야할까?
1. System Architecture
논의를 시작하기 전에, 전형적인 시스템의 클래식한 다이어그램을 살펴보자.
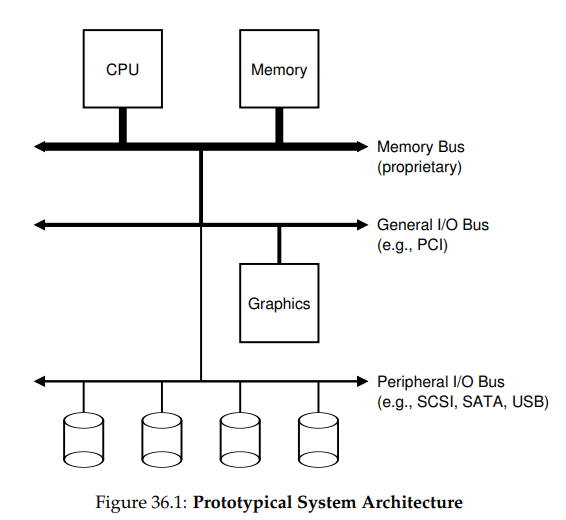
이 그림은 메모리 버스(memory bus)를 통해 메인 메모리에 연결된 단일 CPU를 보여주고 있다. 일부 장치들은 시스템에 범용 I/O 버스를 통해 연결되어있는데, 많은 현대 시스템에서는 PCI, 또는 그 파생형들 중 하나를 쓰고 있다. 그래픽이나 다른 고성능 I/O 장치들도 여기에 있다. 마지막으로 조금 더 아래에는 주변장치용 버스(peripheral bus)라 불리는 것이 있는데, 여기에는 SCSI, SATA, USB등이 있다. 이것들은 디스크, 마우스, 키보드와 같이 느린 장치들을 시스템에 연결시킨다.
이에 대해 제기될 수 있는 한 가지 물음은 다음과 같다. 왜 이런 계층적 구조가 필요할까? 간단히 말하자면 물리적인 이유와 비용 때문이다. 버스는 더 빨라질 수록 더 짧아져야 한다. 그렇기 때문에 고성능 메모리 버스는 장치 등을 꽂을 만한 충분한 공간을 가지지 못한다. 추가적으로 고성능 버스를 만드는 것은 꽤 비싸다. 그렇기 떄문에 시스템 디자이너들은 계층적 접근법을 도입해, 그래픽 카드와 같이 높은 성능을 필요로 하는 구성 요소들은 CPU에 가깝게, 그렇지 않은 것들은 좀 더 멀리에 둔 것이다. 디스크나 다른 느린 장치들을 주변장치 버스에 위치시킴으로써 얻을 수 있는 이득은 많다. 특히, 이렇게 하면 많은 수의 장치들을 위치시킬 수도 있다.
물론 현대 시스템들은 성능을 향상 시키기 위해, 점점 특화된 칩셋과 더 빠른 포인트-투-포인트 상호 연결을 사용하고 있다. 아래의 그림은 인텔의 Z270 칩셋의 대략적인 다이어그램이다. 최상위에서 CPU는 메인 메모리와 가장 가깝게 연결되어있고, 또한 게이밍 등 높은 그래픽 사양을 필요로 하는 애플리케이션을 사용할 수 있게, 그래픽 카드와도 고성능 연결을 맺고 있다.
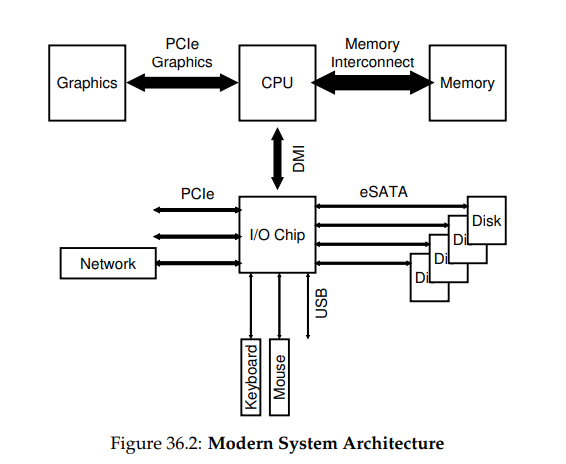
CPU는 인텔의 DMI(Direct Media Interface)를 통해 I/O칩에 연결되어 있고, 나머지 장치들은 여러 다른 종류의 interconnect를 이용해 이 칩에 연결되어 있다. 오른쪽에는 하나 이상의 하드 드라이브들이 eSATA 인터페이스로 시스템에 연결되어 있다. 이 인터페이스는 ATA(AT Attachment), SATA(Serial ATA, eSATA(external SATA)의 순으로, 현대 저장 장치의 발전에 발맞춰 발전되어 왔다.
I/O 칩 아래에는 여러 개의 USB(Universal Serial Bus) 연결이 있는데, 이 그림에서는 이를 통해 키보드 및 마우스 연결이 일어나고 있다. 많은 현대 시스템에서 USB는 이와 같은 저성능 장치들을 위해 사용되고 있다.
마지막으로 왼쪽에는 PCIe(Peripheral Component Interconnect Express)를 통해 다른 고성능 장치를 연결하고 있다. 이 다이어그램에서는 네트워크 인터페이스가 여기서 시스템에 붙어있다. 고성능 저장 장치들은 종종 여기에 연결된다.
2. A Canonical Device
이제는 가상의 표준 장치를 살펴보고, 이 장치를 통해 효율적인 장치 상호작용을 만들기 위해서 필요한 것은 무엇인지에 대해 살펴보자. 아래 그림에서는 장치가 두 중요한 구성요소를 가지고 있음을 볼 수 있다.
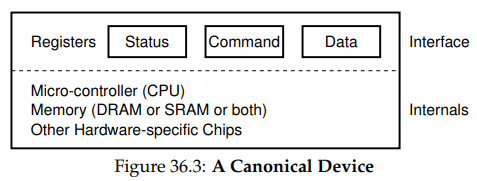
첫 번째는 이 장치가 시스템의 다른 구성 요소들에 제공하는 하드웨어 인터페이스다. 소프트웨어와 마찬가지로, 하드웨어는 시스템 소프트웨어가 그 연산을 제어할 수 있도록 어떤 종류의 인터페이스를 제공해야한다. 그러므로 모든 장치들은 대표적인 상호작용을 위한 명시적 인터페이스와 프로토콜을 가진다.
두 번째는 그 내부 구조다. 이는 장치가 시스템에 제공하는 추상화의 구현과 관련되어 있다. 아주 간단한 장치들은 그 기능을 구현하기 위해 하나나 적은 수의 하드웨어 칩만을 필요로 한다. 더 복잡한 장치들은 그 작업들을 수행하기 위해, 간단한 CPU, 범용 메모리, 그리고 그 외의 장치에 필요한 칩들을 필요로 한다. 예를 들어 현대 RAID 컨트롤러는 기능 구현을 위해 수 백개의, 수 천 줄로 이뤄진 펌웨어들을 포함한다.
3. The Canonical Protocol
위 그림에서, 단순화된 장치 인터페이스는 세 레지스터들로 구성된다.
- 상태(status) 레지스터
+ 장치의 현재 상태 - 명령(command) 레지스터
+ 장치가 수행해야할 작업을 알리기 위해 사용 - 데이터(data) 레지스터
+ 장치에 데이터를 전달하거나, 장치로부터 데이터를 가져오기 위해 사용
이제는 장치가 해야할 일을 할 수 있도록 OS가 장치와 맺어야 하는 대표적인 상호 작용들에 대해 설명해보자. 프로토콜은 다음과 같다.
While (STATUS == BUSY)
; // wait until device is not busy
Write data to DATA register
Write command to COMMAND register
(starts the device and executes the command)
While (STATUS == BUSY)
; // wait until device is done with your request프로토콜은 네 단계로 이루어져있다. 첫 단계에서 OS는 반복적으로 상태 레지스터를 읽음으로써 장치가 명령을 받을 준비가 될 때까지 대기한다. 이를 가리켜 장치를 폴링한다고 말한다. 두 번째로, OS는 데이터 레지스터에 어떤 데이터를 보낸다. 예를 들어 이 장치가 디스크라 가정한다면, 하나의 디스크 블럭을 장치로 전달하기 위해 여러 번의 쓰기 작업이 필요하다. 만약 메인 CPU가 데이터 이동에 관여한다면, 이를 가리켜 programmed I/O(PIO)라 부른다. 세 번째로, OS는 명령 레지스터에 명령을 쓴다. 이는 현재 데이터가 있고, 장치가 해당 명령을 수행해야 함을 장치에 알리는 역할을 한다. 마지막으로 OS는 다시 폴링을 반복하면서 장치의 작업 수행이 완료되기를 기다린다.
이 기본 프로토콜은 간단하면서도 잘 작동한다는 장점이 있다. 하지만 여기에는 비효율성과 불편함도 있다. 알아차릴 수 있을 만한 첫 번째 문제로는, 폴링이 비효율적으로 보인다는 것이다. 구체적으로, 이는 다른 대기 중인 프로세스로 전환해 CPU를 효율적으로 쓰기보다, 많은 양의 CPU 시간을 그저 장치가 그 활동을 완료하기를 기다리며 낭비하게 만든다.
어떻게 잦은 폴링을 사용하지 않고 장치의 상태를 확인할 수 있을까? 어떻게 장치 관리를 위한 CPU 오버헤드를 줄일 수 있을까?
4. Lowering CPU Overhead With Interrupts
이 상호 작용을 개선하기 위해 쓰여온 방법 중 하나는 인터럽트다. 장치를 반복적으로 폴링하지 않고, OS는 요청을 하나 만들고, 호출 프로세스를 재우고, 다른 작업으로 문맥 전환을 한다. 장치가 작업을 완료하면, 이는 하드웨어 인터럽트를 발생시키고 CPU가 OS에 미리 정해진 인터럽트 서비스 루틴(Interrupt Service Routine, ISR), 또는 간단히 인터럽트 핸들러에 따른 작업을 수행하게 한다. 이 핸들러는 OS 코드의 일부분으로, 요청을 마치고 I/O를 대기 중인 프로세스를 깨워 원하던 일을 계속 진행할 수 있게 한다.
인터럽트는 계산과 I/O의 오버랩을 가능하게 하며, 이것이 개선된 CPU 활용의 핵심이다. 아래의 타임라인이 문제를 보여준다.

다이어그램에서 1로 표시되는 프로세스 1은 CPU에서 잠시 돌아가다가, 디스크로에 데이터를 읽기 위한 I/O 요청을 보낸다. 인터럽트가 발생하지 않는 경우 시스템은 그냥 I/O 작업이 완료될 떄까지 장치 상태를 폴링하며 스핀하게 된다. 디스크가 요청을 서비스하면 프로세스 1은 다시 돌아간다.
만약 대신 인터럽트를 사용해 오버랩을 가능케 하면, OS는 그냥 디스크를 기다리는 일 외에 다른 일을 할 수 있게 된다.

이 예시에서, OS는 디스크가 프로세스 1의 요청을 서비스하는 동안 프로세스 2가 CPU에서 실행되기 한다. 디스크 요청이 완료되면 인터럽트가 발생하고, OS는 프로세스 1을 깨워 재실행한다. 중반에서 CPU와 디스크 모두가 제대로 활용되는 것이다.
다만 인터럽트를 쓰는 것이 항상 최선의 해결법은 아니라는 것에 유의하자. 예를 들어, 작업을 아주 빠르게 수행해, 보통 첫 번째 폴링에서 장치 작업이 끝났음을 알 수 있는, 그런 장치가 있다고 해보자. 이 경우에 인터럽트를 사용하는 것은 시스템을 느리게 만든다. 다른 프로세스로 전환하고, 인터럽트를 처리하고, 다시 이 프로세스로 돌아오는 일에는 비용이 많이 들기 때문이다. 따라서 만약 장치가 충분히 빠르다면, 그저 폴하는 것이 최선일 수 있고, 장치가 상당히 느리다면 오버랩을 가능하게 하는 인터럽트의 사용이 최선일 수 있다. 만약 장치의 속도가 알려져있지 않다면, 혹은 어떨 때는 느리고 어떨 때는 빠르다면, 잠시 동안은 폴링하다, 아직 장치 작업이 끝나지 않았음을 발견하면 인터럽트를 사용하는 혼합 방식을 사용하는 것이 최선일 수도 있다. 이 2-단계 접근법은 보통 두 모든 경우에 최선의 결과를 얻을 수 있다.
인터럽트를 사용하지 않아야 할 다른 이유는 네트워크 환경에서 찾을 수 있다. 대용량으로 들어오는 패킷 스트림이 있고, 이 각각이 인터럽트를 일으키는 경우, OS는 라이브락에 빠져, 계속되는 인터럽트만 처리하고 실질적인 유저 레벨에서의 요청은 처리하지 못하게 될 수도 있다. 예를 들면, 어떤 웹 서버에 작업량이 너무 몰리는 경우를 생각해보자. 이 경우에는 때때로 폴링을 사용해, 현재 시스템에서 일어나고 있는 일을 제어하고, 더 많은 패킷 도착을 확인하기 위해 장치로 돌아가기 전에 요청을 서비스하도록 할 수 있다.
다른 인터럽트 기반의 최적화에는 병합(coalescing)이 있다. 여기에서 인터럽트를 발생시킬 필요가있는 장치는 인터럽트를 CPU에 전달하기 전에 우선 잠시 동안 대기한다. 대기 중에 다른 요청들은 곧 완료될 것이고, 따라서 다수의 인터럽트들은 하나의 인터럽트로 병합되어 인터럽트 처리의 오버헤드를 줄이게 된다. 물론 너무 오래 기다리는 것은 요청의 지연 시간을 증가시킬 수도 있다.
5. More Efficient Data Movement With DMA
표준 프로토콜에 대해 주의해야할 다른 측면도 있다. 구체적으로, 장치에 대용량의 데이터를 전달하기 위해 PIO를 쓰는 경우, CPU는 다시 사소한 작업들에 힘을 쓰게 되고, 따라서 다른 프로세스들을 실행하기 위해 쓰일 수 있었을 시간과 노력들을 소모하게 된다. 다음의 타임라인이 이 문제를 보여준다.

이 타임라인에서는 프로세스 1이 실행되고 있고, 디스크에 어떤 데이터를 쓰려고 한다. 이는 명시적으로 데이터를 메모리로부터 장치로, 한 번에 한 워드 씩 복사하는 I/O 작업을 시작한다(표의 c). 데이터 복사가 완료되면 I/O가 디스크에서 시작되고, CPU는 다른 일들을 할 수 있게 된다.
이 문제에 대한 해결법을 직접 메모리 접근(Direct Memory Access)이라 부른다. DMA 엔진은 시스템 내에 있는 아주 특수한 장치로서, CPU의 많은 간섭 없이 장치와 메모리 사이의 데이터 전달을 조정하는 역할을 한다.
DMA는 다음과 같이 동작한다. 예를 들어, 장치로 데이터를 전달할 때, OS는 메모리의 어디에 데이터가 있고, 얼마나 많은 데이터를 복사해야하고, 어떤 장치에 이를 보낼지를 알림으로써 DMA 엔진을 프로그램한다. 이 지점에서 OS에서 일어나야 하는 데이터 전송 작업은 끝나고, OS는 다른 작업을 진행할 수 있게 된다. DMA 작업이 끝나면 DMA 컨트롤러는 인터럽트를 발생시키고, OS는 데이터 전송이 끝났음을 알게 된다. 수정된 타임라인은 다음과 같다.
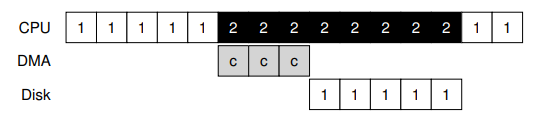
타임라인에서는 데이터 복사가 DMA 컨트롤러에 이뤄지고 있음을 볼 수 있다. CPU가 해당 시간에 사용 가능해지므로 OS는 다른 어떤 일을 할 수 있다. 표에서는 프로세스 2의 작업이 수행되고 있다. 프로세스 1이 다시 실행되기 전에 프로세스 2가 더 많은 CPU를 사용할 수 있게 되는 것이다.
6. Methods Of Device Interaction
이제 I/O 작업을 수행하기 위한 효율성 이슈들에 대해 알게 됐는데, 사실 장치를 현대 시스템에 통합시키기 위해 다뤄야 할 문제들이 조금 더 있다. 아직 OS가 어떻게 장치와 실제로 통신하는지를 보지 않았다.
하드웨어는 어떻게 장치와 통신할까? 다른 명시적인 명령이 있어야 할까? 아니면, 이를 위한 다른 방법이 있을까?
지금까지 장치 통신을 위한 두 기본 방법이 개발되었다. 그 첫 번째, 오래된 방법은 명시적인 I/O 명령어를 사용하는 방법이다. 이 명령어는 OS가 특정 장치 레지스터에 데이터를 보내는 방식을 명시함으로써 위 프로토콜의 구성을 가능케 한다. 예를 들어 x86에서는 in, out 명령어가 장치와의 통신을 위해 사용될 수 있다. 장치에 데이터를 보낼 때, 호출자는 데이터가 있는 레지스터와 장치의 가리키는 특정 포트를 지정한다. 명령어를 실행하면 바라던 동작이 수행된다.
이러한 명령어들은 보통 특권적이다. OS는 장치를 제어하고, 따라서 오직 OS만이 직접 장치와 통신할 수 있도록 허용된 유일한 주체다. 아무 프로그램이나 디스크를 읽고 쓸 수 있다고 생각해보자. 이 경우 사용자 프로그램은 이 허점을 이용해 기기에 대한 완전한 제어를 얻을 수 있게 된다.
두 번째 방법은 메모리 맵 I/O(memory mapped I/O)를 사용하는 것이다. 이 방식에서, 하드웨어는 장치 레지스터를 마치 메모리에 위치한 것처럼 사용할 수 있게 된다. 특정 레지스터에 접근하기 위해서 OS는 해당 주소에의 load, store 명령을 사용하고, 하드웨어가 이를 메인 메모리가 아닌 장치로 전달한다.
두 방식 각각이 다른 방식에 대해 특별히 큰 장점을 가지는 것은 아니다. 메모리 맵 방식의 경우 다른 새 명령어를 필요로 하지 않는다는 점에서는 좋지만, 두 방식은 모두 지금도 쓰이고 있다.
7. Fitting Into The OS: The Device Driver
마지막으로 다룰 문제는 다음과 같다. 서로 다른 인터페이스를 가지는 장치들을 OS에 맞게 만들, 되도록이면 일반적인 방법은 무엇일까? 예를 들어 파일 시스템을 생각해보자. 우리는 SCSI 디스크, IDE 디스크, USB 키체인 드라이브 등 여러 종류의 디스크에서 작동하는 파일 시스템을 만들고 싶다. 다만 이때 그 드라이브 종류 각각에서 어떻게 읽고 쓰기 요청이 이루어지는지에 대한 세부 내용에는 상대적으로 신경쓰지 않고서 말이다.
이 문제는 오래된 추상화(abstraction) 테크닉을 통해 해결된다. 가장 낮은 레벨에서 OS 내부의 소프트웨어는 장치가 어떻게 작동하는지를 자세하게 알아야 한다. 이 소프트웨어를 가리켜 장치 드라이버(device driver)라 부르며, 장치 상호 작용의 구체적인 내용은 여기에 캡슐화되어 있다.
리눅스 파일 시스템의 소프트웨어 스택을 살펴봄으로써, 이 추상화가 OS 디자인과 구현에 어떻게 도움을 주는지를 보자. 아래의 그림은 리눅스 소프트웨어 구조를 간략하게 보여주고 있다.
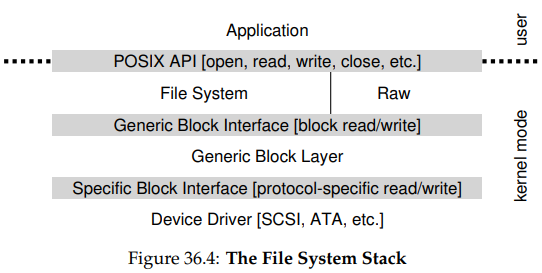
다이어그램에서 볼 수 있듯, 파일 시스템은 사용되고 있는 디스크 클래스와는 상관없이, 완전히 분리되어 있다. 이는 그저 블럭 읽기와 쓰기 요청을 범용 블럭 계층(generic block layer)에 전달할 뿐이다. 이 계층은 해당 요청을 적절한 장치 드라이버로 전달하고, 해당 드라이버는 특정 요청에 대한 세부적인 내용들을 처리한다. 단순화되기는 했지만, 이 다이어그램은 그런 세부 내용들이 OS의 대부분에게 어떻게 감춰지는지를 보여주고 있다.
다이어그램을 보면 raw interface도 있는데, 이는 특수한 애플리케이션들이 파일 추상화를 사용하지 않고 직접 블럭을 읽고 쓸 수 있게 한다. 대부분의 시스템은 저수준 장치 관리 애플리케이션을 지원하기 위해, 이러한 종류의 인터페이스를 제공한다.
위의 캡슐화가 또한 단점도 가질 수 있다는 점에 유의하자. 예를 들어 만약 특수한 기능들을 많이 가지고 있는 장치가 있는데, 커널은 범용적인 인터페이스만을 사용한다면, 그 특수 기능들은 사용되지 못할 것이다. 이러한 상황은, 예를 들면, SCSI 장치를 사용하는 리눅스에서 나타나곤 한다. SCSI는 훨씬 풍부한 에러 리포팅을 제공한다. 이와 달리 ATA나 IDE 같은 다른 블럭 장치들은 훨씬 간단한 에러 처리만을 지원하고, 소프트웨어 상위 계층에서도 범용 EIO 에러 코드 밖에 받을 수 없다. SCSI가 제공하는 추가 세부 정보들은 파일 시스템에서 사라지게 된다.
흥미롭게도, 어떤 장치를 시스템에 꽂든 장치 드라이버가 필요하기 때문에, 시간에 지남에 따라 그것들은 커널 코드의 대부분을 차지하게 됐다. 리눅스 커널에 대한 연구는 OS 코드의 70% 이상이 장치 드라이버를 위한 것임을 보였고, 그 정도는 윈도우 기반의 시스템에서도 비슷하게 높다. 그러므로 사람들이 OS가 수백만 줄의 코드로 이루어져있다고 말하는 것은, 사실 OS가 수백만 줄의 장치 드라이버 코드를 가지고 있다는 것과 마찬가지다. 물론 어떤 설치 환경에서든 대부분의 코드는 활성화된 상태가 아니다. 더 슬프게도, 드라이버들은 종종 아마추어들에 의해 작성되므로, 많은 버그를 가지는 경우가 많고, 커널 크래시를 일으키는 주범이 되기도 한다.
8. Case Study: A Simple IDE Disk Driver
조금 더 깊이 탐구하기 위해, 실제 장치(IDE 디스크 드라이브)에 대해 빠르게 한 번 살펴보자.
Control Register:
Address 0x3F6 = 0x08 (0000 1RE0): R=reset,
E=0 means "enable interrupt"
Command Block Registers:
Address 0x1F0 = Data Port
Address 0x1F1 = Error
Address 0x1F2 = Sector Count
Address 0x1F3 = LBA low byte
Address 0x1F4 = LBA mid byte
Address 0x1F5 = LBA hi byte
Address 0x1F6 = 1B1D TOP4LBA: B=LBA, D=drive
Address 0x1F7 = Command/status
Status Register (Address 0x1F7):
7 6 5 4 3 2 1 0
BUSY READY FAULT SEEK DRQ CORR IDDEX ERROR
Error Register (Address 0x1F1): (check when ERROR==1)
7 6 5 4 3 2 1 0
BBK UNC MC IDNF MCR ABRT T0NF AMNF
BBK = Bad Block
UNC = Uncorrectable data error
MC = Media Changed
IDNF = ID mark Not Found
MCR = Media Change Requested
ABRT = Command aborted
T0NF = Track 0 Not Found
AMNF = Address Mark Not FoundIDE 디스크는 위와 같은 간단한 인터페이스를 시스템에 제공한다. 여기에는 control, command block, status, error의 네 레지스터가 있고, 이 레지스터들은 특정 I/O 주소에 in, out I/O 명령어를 사용해 읽고 쓰기를 함으로써 사용할 수 있다.
장치와 상호작용하기 위한 기본 프로토콜은 다음과 같다.
- 드라이브가 준비될 때까지 대기
+ Status 레지스터를 드라이브가 BUSY가 아니고 READY가 될 때까지 읽는다. - command 레지스터에 파라미터를 씀
+ 섹터의 수, 접근할 섹터의 논리 블럭 주소, 드라이브 번호를 command 레지스터에 씀 - I/O 시작
+ command 레지스터에 READ 또는 WRITE 명령을 씀 - 데이터 전송(쓰기 작업의 경우)
+ 드라이브 상태가 READY이고 DRQ일 때까지 대기한다. 데이터를 데이터 포트에 쓴다. - 인터럽트 처리
+ 가장 간단하게는 각 섹터에 전송될 때마다 인터럽트를 처리한다. 더 복잡한 방식으로는 배치 처리로 전체 전송이 완료됐을 때 마지막 한 인터럽트만 처리할 수도 있다. - 에러 처리
+ 각 연산마다 status 레지스터를 읽는다. 만약 ERROR 비트가 1이면, 세부 내용을 위해 error 레지스터를 읽는다.
이 프로토콜의 대부분은 xv6 IDE 드라이버에서 찾을 수 있으며, 초기화 이후 네 기본 함수들을 통해 동작한다.
ide_rw()
+ 요청을 큐에 넣거나, 바로 디스크에 발생시킨다.
+ 두 경우 모두에서, 루틴은 요청이 완료되기를 대기하고 호출 프로세스를 잠들게 한다.ide_start_request()
+ 요청을 디스크에 보낸다.
+ x86의in,out명령어가 각각 장치 레지스터를 읽고 쓰는 데에 쓰인다.ide_wait_ready()
+ 드라이브에 요청을 만들기 전에 드라이브가 준비된 상태인지 확인하기 위해 쓰인다.ide_intr()
+ 인터럽트가 발생했을 때 불린다.
+ 장치의 데이터를 읽고, I/O 작업이 완료되기를 기다리는 프로세스를 깨운다. 이후에는ide_start_request()로 다음 I/O를 시작한다.
10. Summary
OS가 장치와 어떻게 상호작용하는지에 대한 아주 기본적인 내용들에 대해서는 이해했을 것이다. 인터럽트와 DMA라는 두 테크닉은 장치의 효율성을 높이기 위해 도입되었으며, 명시적 I/O 명령어와 메모리 맵 I/O의 두 방식은 장치 레지스터에 접근하기 위해 도입됐다. 마지막으로 장치 드라이버에 대해 얘기하면서, 어떻게 OS가 저수준의 세부 내용을 캡슐화하고 나머지 OS를 장치-중립적인 방식으로 만들 수 있게 하는지에 대해 다뤘다.
